





Before studying deep neural networks, we will cover the fundamental components of a simple (linear) neural network. We’ll begin with the topic of linear regression. Since linear regression can be modeled as a neural network, it provides an excellent example to introduce the essential components of neural networks.
Regression is a form of supervised learning which aims to model the relationship between one or more input variables (features) and a continuous (target) variable. We assume that the relationship between the input variables 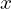 and the target variable
and the target variable 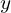 can be expressed as a weighted sum of the inputs (i.e., the model is linear in the parameters). In short, linear regression aims to learn a function that maps one or more input features to a single numerical target value.
can be expressed as a weighted sum of the inputs (i.e., the model is linear in the parameters). In short, linear regression aims to learn a function that maps one or more input features to a single numerical target value.
- Dataset Exploration
- Linear Regression Model
- Neural Network Perspective and Terminology
- Modeling a Neural Network in Keras
- Conclusion
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Activation
from tensorflow.keras.datasets import boston_housing
from tensorflow.keras import layers
import tensorflow as tf
import matplotlib.pyplot as plt
SEED_VALUE = 42
# Fix seed to make training deterministic.
np.random.seed(SEED_VALUE)
tf.random.set_seed(SEED_VALUE)
Dataset Exploration
Load the Boston Housing Dataset
In this post, we will be working with the Boston Housing dataset. This dataset contains information collected by the U.S. Census Service concerning housing in Boston, MA. The dataset contains 14 unique attributes, among which is the median value (price in $K) of a home for a given suburb. We will use this dataset as an example of how to develop a model that allows us to predict the median price of a home based on a single attribute in the dataset (average number of rooms in a house).
Keras provides the load_data() function to load this dataset. Datasets are typically partitioned into train, and test components and the load_data() function returns a tuple for each. Each tuple contains a 2-dimensional array of features (e.g., X_train) and a vector that contains the associated target values for each sample in the dataset (e.g., y_train). So, for example, the rows in X_train represent the various samples in the dataset, and the columns represent the various features. We will only use the training data to demonstrate how to train a model. However, in practice, it is very important to use the test data to see how well the trained model performs on unseen data.
# Load the Boston housing dataset.
(X_train, y_train), (X_test, y_test) = boston_housing.load_data()
print(X_train.shape)
print("\n")
print("Input features: ", X_train[0])
print("\n")
print("Output target: ", y_train[0])
(404, 13) Input features: [ 1.23247 0. 8.14 0. 0.538 6.142 91.7 3.9769 4. 307. 21. 396.9 18.72 ] Output target: 15.2
Extract Features from the Dataset
For this example, we will only use a single feature from the dataset, so to keep things simple, we will store the feature data in a new variable.
boston_features = {
'Average Number of Rooms':5,
}
X_train_1d = X_train[:, boston_features['Average Number of Rooms']]
print(X_train_1d.shape)
X_test_1d = X_test[:, boston_features['Average Number of Rooms']]
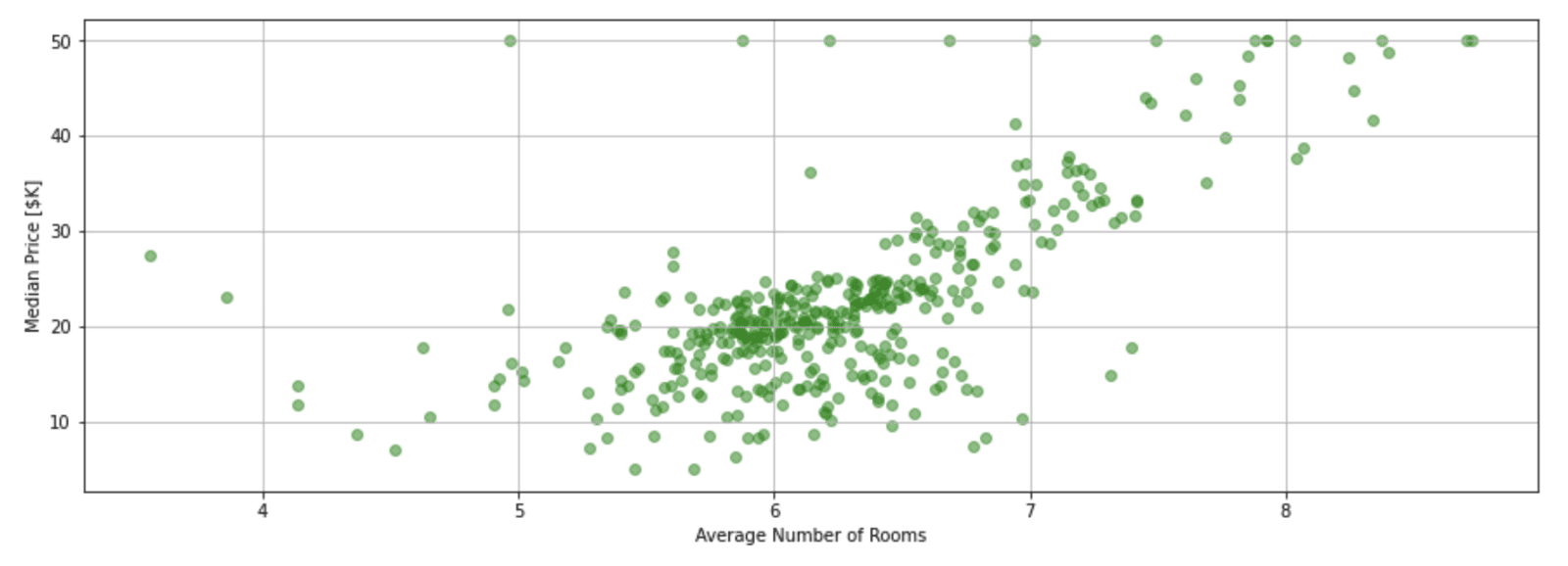
Plot the Features
Here we plot the median price of a home vs. the single feature (‘Average Number of Rooms’).
plt.figure(figsize=(15, 5))
plt.xlabel('Average Number of Rooms')
plt.ylabel('Median Price [$K]')
plt.grid("on")
plt.scatter(X_train_1d[:], y_train, color='green', alpha=0.5);
Linear Regression Model
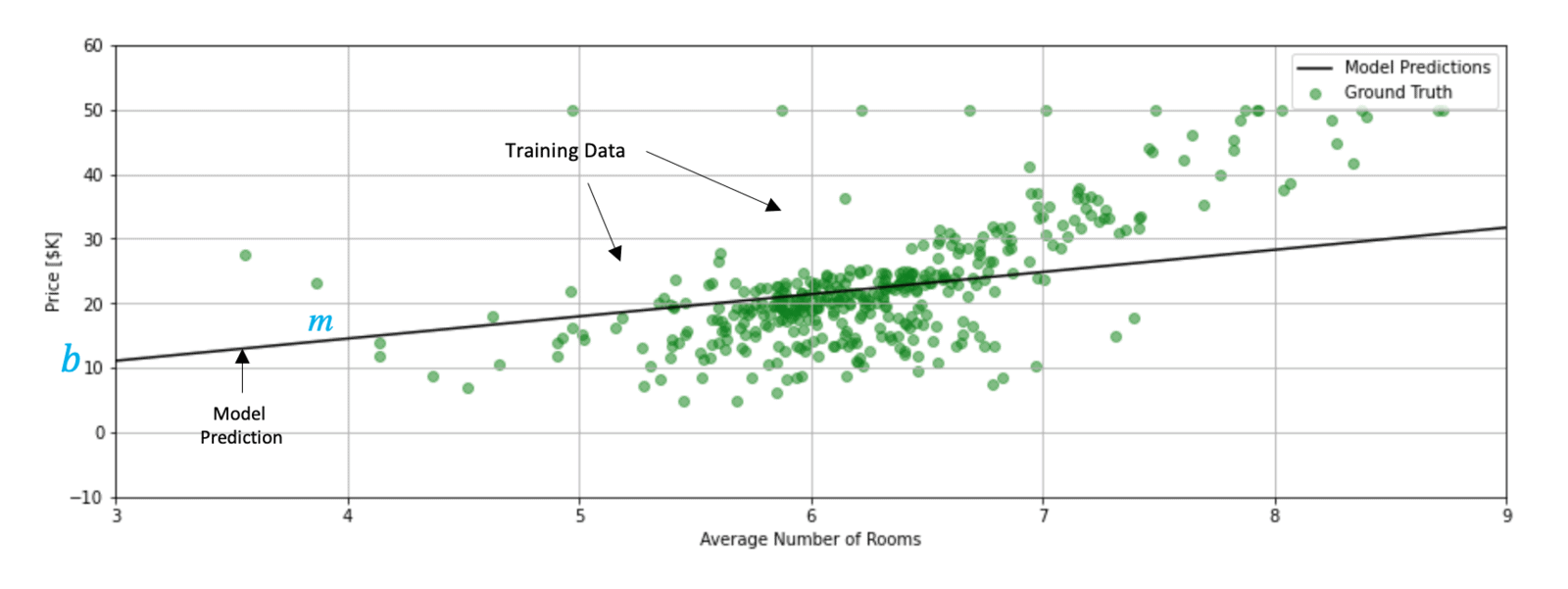
Let’s first start with a clear picture of what we are trying to accomplish. The plot below shows the training data for the single independent variable (number of rooms) and the dependent variable (the median price of a house). We would like to use linear regression to develop a reliable model for this data. In this example, the model is simply a straight line defined by its slope (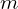 ) and y-intercept (
) and y-intercept (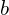 ).
).
Neural Network Perspective and Terminology
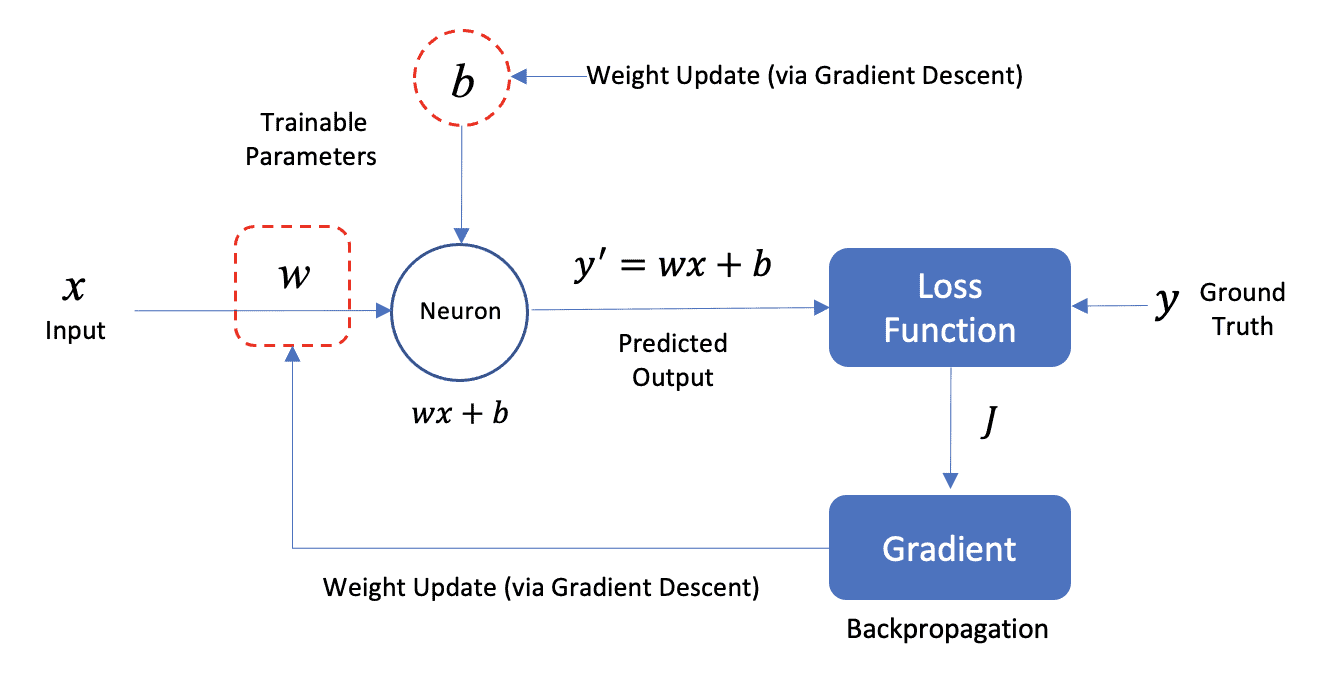
The figure below shows how this model can be represented as a neural network with a single neuron. We will use this simple example to introduce neural network components and terminology. The input data () consists of a single feature (average number of rooms), and the predicted output (‘) is a scalar (predicted median price of a home). Note that each data sample in the dataset represents the statistics for a Boston suburb.
The model parameters ( and ) are learned iteratively during the training process. As you may already know, the model parameters can be computed by the method of Ordinary Least Squares (OSL) in the closed form. However, we can also solve this problem iteratively using a numerical technique called Gradient Descent, which is the basis for how neural networks are trained. We will not cover the details of gradient descent here, but it’s important to understand that it’s an iterative technique that is used to tune the parameters of the model.
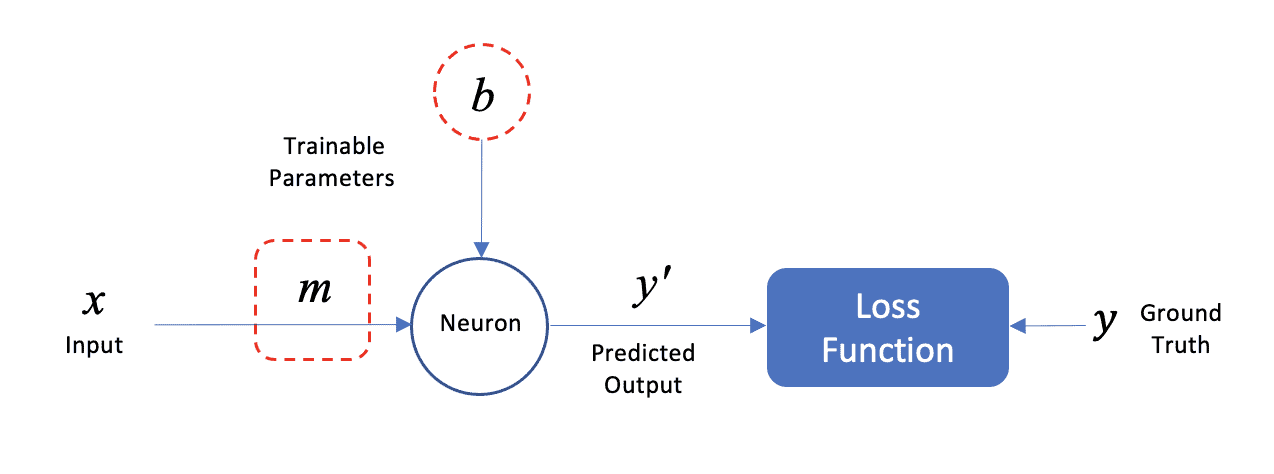
The network contains just a single neuron that takes a single input () and produces a single output (′), which is the predicted (average) price of a home. The single neuron has two trainable parameters, which are the slope () and y-intercept () of the linear model. These parameters are more generally known as weight and bias, respectively.
In regression problems, it is common for the model to have multiple input features, where each input has an associated weight (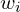 ). However, in this example, we will use just a single input feature to predict the output. So, in general, a neuron typically has multiple weights (
). However, in this example, we will use just a single input feature to predict the output. So, in general, a neuron typically has multiple weights (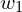 ,
, 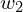 ,
, 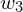 , etc.) and a single bias term (). In this example, you can think of the neuron as the mathematical computation of
, etc.) and a single bias term (). In this example, you can think of the neuron as the mathematical computation of 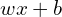 , which produces the predicted value ′.
, which produces the predicted value ′.


Neural Network Weight Update
A slightly more formal diagram is shown below that shows how the model parameters ( and ) are updated during the training process. The model parameters are initialized to small random values. During the training process, as training data is passed through the network, the predicted value of the model (′) is compared to the ground truth () for a given sample from the dataset. These values are used as the basis to compute a loss which is then used as feedback in the network to adjust the model parameters in a way that improves the prediction.
and ) are updated during the training process. The model parameters are initialized to small random values. During the training process, as training data is passed through the network, the predicted value of the model (′) is compared to the ground truth () for a given sample from the dataset. These values are used as the basis to compute a loss which is then used as feedback in the network to adjust the model parameters in a way that improves the prediction.
This weight update process involves two steps called Gradient Descent and Backpropagation. It’s not important at this stage to understand the mathematical details of how these algorithms work, but it is important to understand that there is an iterative process to train the model.
The Loss Function we use can take many forms. In this case, we will use Mean Squared Error (MSE) which is a very common loss function used in regression problems.
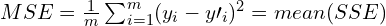
The basic idea is that we want to minimize the value of this function which is a representation of the error between our model and the training dataset. In the equation above, is the number of training samples.
Modeling a Neural Network in Keras
The network diagram in the previous section represents the simplest possible neural network. The network has a single layer consisting of a single neuron that outputs . For every training sample, the predicted output ′ is compared to the actual value from the training data, and the loss is computed. The loss can then be used to fine-tune (update) the model parameters.
All of the details associated with training a neural network are taken care of by Keras, as summarized in the following workflow:
- Build/Define a network model using predefined layers in Keras.
- Compile the model with
model.compile() - Train the model with
model.fit() - Predict the output
model.predict()
Define the Keras Model
model = Sequential()
# Define the model consisting of a single neuron.
model.add(Dense(units=1, input_shape=(1,)))
# Display a summary of the model architecture.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1) 2
=================================================================
Total params: 2
Trainable params: 2
Non-trainable params: 0
_________________________________________________________________ Compile the Model
model.compile(optimizer=tf.keras.optimizers.RMSprop(lr=.005),
loss='mse')
Train the Model
history = model.fit(X_train_1d,
y_train,
batch_size=16,
epochs=101,
validation_split=0.3)
Epoch 1/101 18/18 [==============================] - 0s 12ms/step - loss: 389.6121 - val_loss: 451.1128 Epoch 2/101 18/18 [==============================] - 0s 2ms/step - loss: 363.3520 - val_loss: 425.8087 Epoch 3/101 18/18 [==============================] - 0s 2ms/step - loss: 341.0866 - val_loss: 402.4225 : : Epoch 100/101 18/18 [==============================] - 0s 1ms/step - loss: 54.5784 - val_loss: 75.0670 Epoch 101/101 18/18 [==============================] - 0s 1ms/step - loss: 54.5562 - val_loss: 75.0213
Plot the Training Results
def plot_loss(history):
plt.figure(figsize=(20,5))
plt.plot(history.history['loss'], 'g', label='Training Loss')
plt.plot(history.history['val_loss'], 'b', label='Validation Loss')
plt.xlim([0, 100])
plt.ylim([0, 300])
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plot_loss(history)
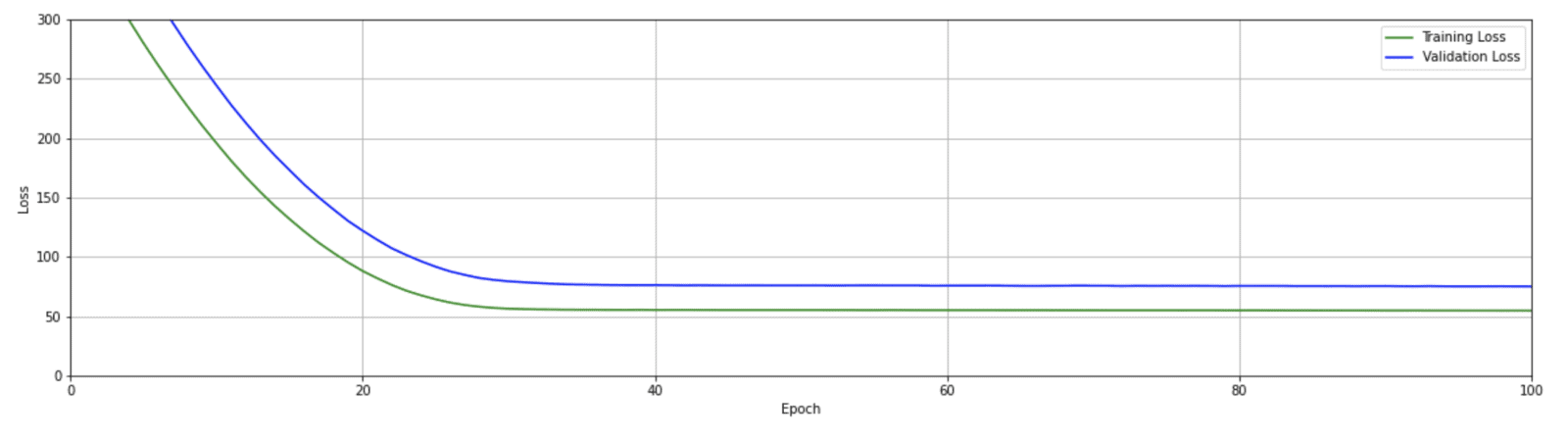
The loss curves above are fairly typical. First, notice that there are two curves, one for the training loss and one for the validation loss. Both losses are large initially, then steadily decrease and eventually level off with no further improvement after about 30 epochs. Since the model is only trained on the training data, it is also fairly typical that the training loss is lower than the validation loss.
Make Predictions using the Model
We can now use the predict() method in Keras to make a single prediction. We pass a list of values to the model (representing the average number of rooms), and the model returns the predicted value for the price of a home for each input.
# Predict the median price of a home with [3, 4, 5, 6, 7] rooms.
x = [3, 4, 5, 6, 7]
y_pred = model.predict(x)
for idx in range(len(x)):
print("Predicted price of a home with {} rooms: ${}K".format(x[idx], int(y_pred[idx]*10)/10))
Predicted price of a home with 3 rooms: $11.4K Predicted price of a home with 4 rooms: $14.7K Predicted price of a home with 5 rooms: $18.0K Predicted price of a home with 6 rooms: $21.4K Predicted price of a home with 7 rooms: $24.7K
Plot the Model and the Data
# Generate feature data that spans the range of interest for the independent variable.
x = tf.linspace(3, 9, 10)
# Use the model to predict the dependent variable.
y = model.predict(x)
def plot_data(x_data, y_data, x, y, title=None):
plt.figure(figsize=(15,5))
plt.scatter(x_data, y_data, label='Ground Truth', color='green', alpha=0.5)
plt.plot(x, y, color='k', label='Model Predictions')
plt.xlim([3,9])
plt.ylim([0,60])
plt.xlabel('Average Number of Rooms')
plt.ylabel('Price [$K]')
plt.title(title)
plt.grid(True)
plt.legend()
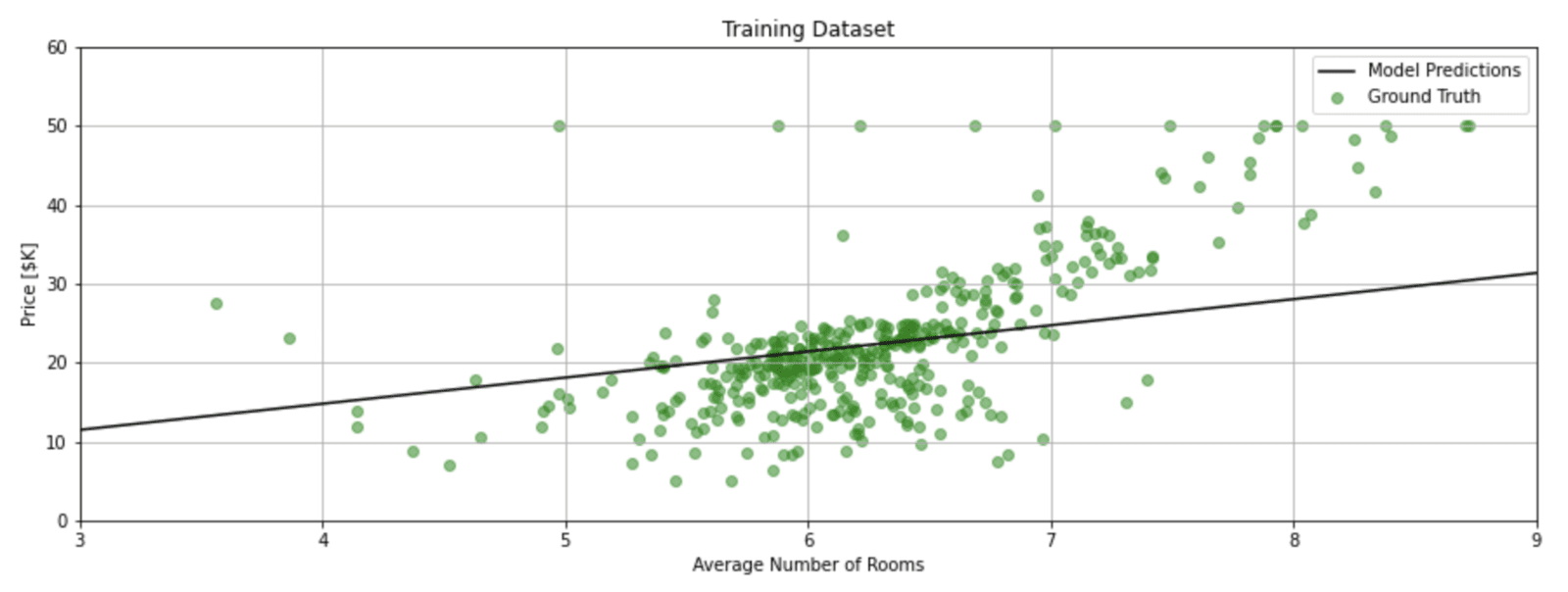
plot_data(X_train_1d, y_train, x, y, title='Training Dataset')
plot_data(X_test_1d, y_test, x, y, title='Test Dataset')
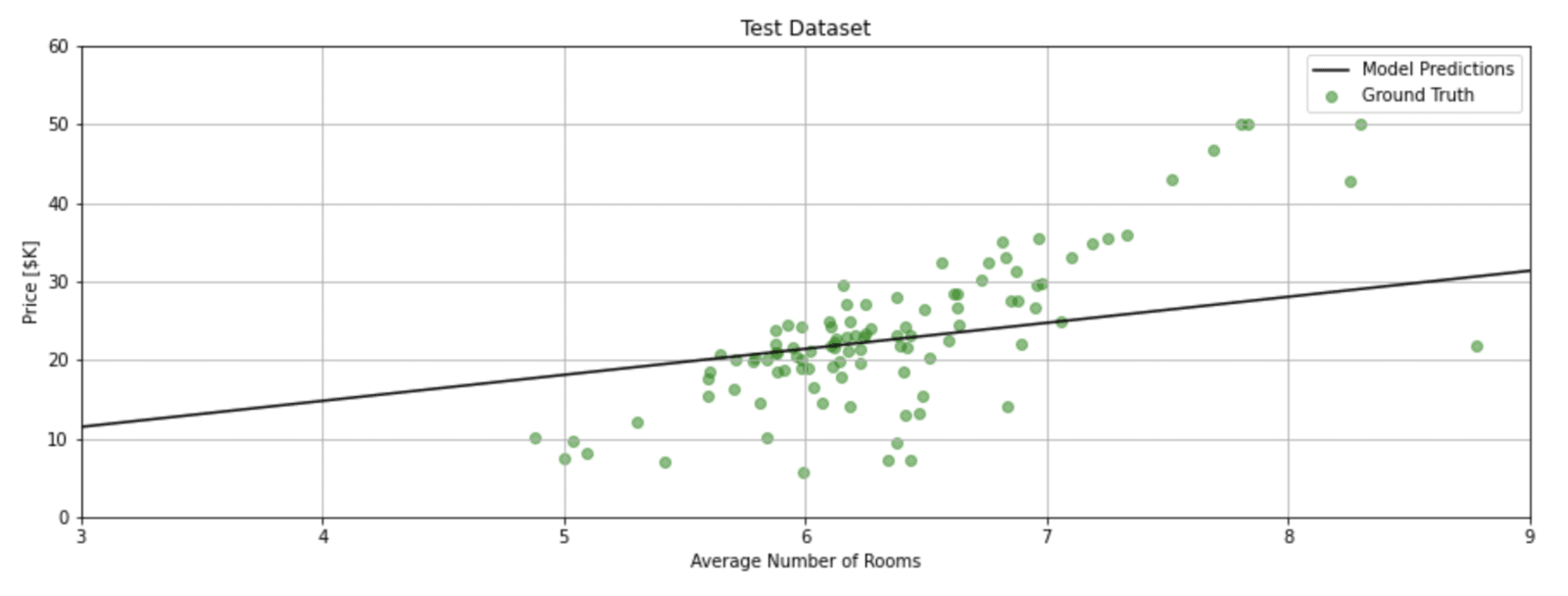
Conclusion
In this post, we introduced the topic of linear regression in the context of a simple neural network. We showed how Keras can be used to model and train the network to learn the parameters of the linear model and how to visualize the model predictions.


100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning