



Hi! This post is part of our PyTorch series.
In the previous post, Pytorch Tutorial for beginners, we discussed PyTorch, it’s strengths and why you should learn it. We also had a brief look at Tensors – the core data structure used in PyTorch. In this article, we will jump into some hands-on examples of using pre-trained networks present in TorchVision module – pre trained models for Image Classification.
Torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. Basically, if you are into Computer Vision and using PyTorch, Torchvision will be of great help.!
1. Pre trained Models for Image Classification
Pre-trained models are Neural Network models trained on large benchmark datasets like ImageNet. The Deep Learning community has greatly benefitted from these open-source models. Also, the pre-trained models are a major factor for rapid advances in Computer Vision research. Other researchers and practitioners can use these state-of-the-art models instead of re-inventing everything from scratch.
Given below is a rough timeline of how the state-of-the-art models have improved over time. We have included only those models which are present in the Torchvision package.
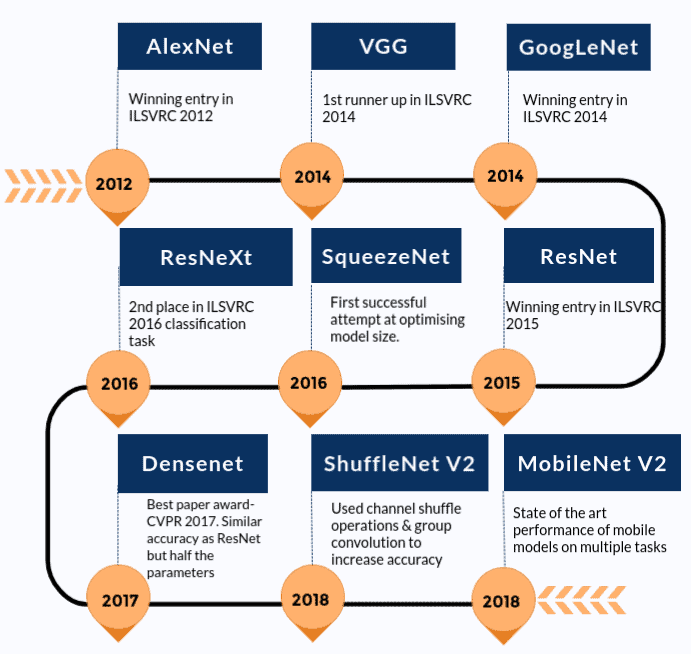
Before we jump into the details of how we can use pre-trained models for image classification, let’s see what the various pre-trained models available are. We will discuss AlexNet and ResNet101 as the two main examples here. Both the networks have been trained on ImageNet dataset.
ImageNet dataset has over 14 million images maintained by Stanford University. It is extensively used for a large variety of Image related deep learning projects. The images belong to various classes or labels. Even though we can use both terms interchangeably, we will stick to classes. The aim of the pre-trained models like AlexNet and ResNet101 is to take an image as an input and predict it’s class.
The word pre-trained here means that the deep learning architectures AlexNet and ResNet101, for instance, have been already trained on some (huge) dataset and thus carry the resultant weights and biases with them. This difference between architecture and weights and biases should be very clear because as we will see in the next section, TorchVision has both the architectures and the pre-trained models.
1.1. Model Inference Process
Since we will focus on how to use the pre-trained models for predicting the class (label) of input, let’s also discuss the process involved in this. This process is referred to as Model Inference. The entire process consists of the following main steps.
- Reading the input image
- Performing transformations on the image. For example – resize, center crop, normalization, etc.
- Forward Pass: Use the pre-trained weights to find out the output vector. Each element in this output vector describes the confidence with which the model predicts the input image belongs to a particular class.
- Based on the scores obtained (elements of the output vector mentioned in step 3), display the predictions.


1.2. Loading Pre-Trained Network using TorchVision
Now that we are equipped with the knowledge of model inference and know what a pre-trained model means, let’s see how we can use them with the help of TorchVision module.
First, let’s install the TorchVision module using the command given below.
pip install torchvision
Next, let’s import models from torchvision module and see the different models and architectures available to us.
from torchvision import models
import torch
dir(models)
Not so fast! Carefully observe the output that we got above.
['AlexNet',
'DenseNet',
'GoogLeNet',
'Inception3',
'MobileNetV2',
'ResNet',
'ShuffleNetV2',
'SqueezeNet',
'VGG',
...
'alexnet',
'densenet',
'densenet121',
'densenet161',
'densenet169',
'densenet201',
'detection',
'googlenet',
'inception',
'inception_v3',
...
]
Notice that there is one entry called AlexNet and one called alexnet. The capitalized name refers to the Python class (AlexNet) whereas alexnet is a convenience function that returns the model instantiated from the AlexNet class. It’s also possible for these convenience functions to have different parameter sets. For example, densenet121, densenet161, densenet169, densenet201, are all instances of DenseNet class but with a different number of layers – 121,161,169 and 201, respectively.
1.3. Using AlexNet for Image Classification
Let’s first start with AlexNet. It is one of the early breakthrough networks in Image Recognition. If you are interested in learning about AlexNet’s architecture, you can check out our post on Understanding AlexNet.

Step 1: Load the pre-trained model
In the first step, we will create an instance of the network. We’ll also pass an argument so the function download the weights of the model.
alexnet = models.alexnet(pretrained=True)
# You will see a similar output as below
# Downloading: "https://download.pytorch.org/models/alexnet-owt- 4df8aa71.pth" to /home/hp/.cache/torch/checkpoints/alexnet-owt-4df8aa71.pth
Note that usually the PyTorch models have an extension of .pt or .pth
Once the weights have been downloaded, we can proceed with the other steps. We can also check out some details of the network’s architecture as follows.
print(alexnet)
Don’t worry about the overflowing output. This basically states the various operations and layers in the AlexNet architecture.
Step 2: Specify image transformations
Once we have the model with us, the next step is to transform the input image so that they have the right shape and other characteristics like mean and standard deviation. These values should be similar to those used while training the model. This makes sure that the network will produce meaningful answers.
We can pre-process the input image with the help of transforms present in TochVision module. In this case, we can use the following transforms for both AlexNet and ResNet.

from torchvision import transforms
transform = transforms.Compose([ #[1]
transforms.Resize(256), #[2]
transforms.CenterCrop(224), #[3]
transforms.ToTensor(), #[4]
transforms.Normalize( #[5]
mean=[0.485, 0.456, 0.406], #[6]
std=[0.229, 0.224, 0.225] #[7]
)])
Let’s try to understand what happened in the above code snippet.
Line [1]: Here we are defining a variable transform which is a combination of all the image transformations to be carried out on the input image.
Line [2]: Resize the image to 256×256 pixels.
Line [3]: Crop the image to 224×224 pixels about the center.
Line [4]: Convert the image to PyTorch Tensor data type.
Line [5-7]: Normalize the image by setting its mean and standard deviation to the specified values.
Step 3: Load the input image and pre-process it
Next, let’s load the input image and carry out the image transformations specified above. Note that we will use Pillow (PIL) module extensively with TorchVision as it’s the default image backend supported by TorchVision.
# Import Pillow
from PIL import Image
img = Image.open("dog.jpg")

Next, pre-process the image and prepare a batch to be passed through the network.
img_t = transform(img)
batch_t = torch.unsqueeze(img_t, 0)
Step 4: Model Inference
Finally, it’s time to use the pre-trained model to see what the model thinks the image is.
First, we need to put our model in eval mode.
alexnet.eval()
Next, let’s carry out the inference.
out = alexnet(batch_t)
print(out.shape)
This is all good but what do we do with this output vector out with 1000 elements? We still haven’t got the image’s class (or label). For this, we will first read and store the labels from a text file having a list of all the 1000 labels. Note that the line number specified the class number, so it’s very important to ensure that you don’t change that order.
with open('imagenet_classes.txt') as f:
classes = [line.strip() for line in f.readlines()]
Since AlexNet and ResNet have been trained on the same ImageNet dataset, we can use the same classes list for both models.
Now, we need to find the index where the maximum score in output vector out occurs. We will use this index to find out the prediction.
_, index = torch.max(out, 1)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
print(labels[index[0]], percentage[index[0]].item())
There we go! The model predicts the image to be of a Labrador Retriever with a 41.58% confidence.
But that sounds too low. Let’s see what other classes the model thought the image belonged to.
_, indices = torch.sort(out, descending=True)
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
And here are the outputs:
[('Labrador retriever', 41.585166931152344),
('golden retriever', 16.59166145324707),
('Saluki, gazelle hound', 16.286880493164062),
('whippet', 2.8539133071899414),
('Ibizan hound, Ibizan Podenco', 2.3924720287323)]
If you are not aware, all these are dog breeds. So the model managed to predict that it was a dog with a fairly high confidence but it was not very sure about the breed of the dog.
Let’s try the same thing for an image of strawberries and a car and see the ouputs we get.

Here is the output obtained for the above image of strawberries. As we can see, the class with highest score was “Strawberries” with a score of close to 99.99%.
[('strawberry', 99.99365997314453),
('custard apple', 0.001047826954163611),
('banana', 0.0008201944874599576),
('orange', 0.0007371827960014343),
('confectionery, confectionary, candy store', 0.0005758354091085494)]

Similarly, for the the image of the car given above, the output is as follows.
[('cab, hack, taxi, taxicab', 33.30569839477539),
('sports car, sport car', 14.424001693725586),
('racer, race car, racing car', 10.685123443603516),
('beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon',
7.846532821655273),
('passenger car, coach, carriage', 6.985556125640869)]
That’s it! All it takes is these 4 steps to carry out image classification using pre-trained models.
How about we try the same with ResNet?
1.4. Using ResNet for Image Classification
We will use resnet101 – a 101 layer Convolutional Neural Network. resnet101 has about 44.5 million parameters tuned during the training process. That’s huge!
Let’s quickly go through the steps required to use resnet101 for image classification.
# First, load the model
resnet = models.resnet101(pretrained=True)
# Second, put the network in eval mode
resnet.eval()
# Third, carry out model inference
out = resnet(batch_t)
# Forth, print the top 5 classes predicted by the model
_, indices = torch.sort(out, descending=True)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
[(labels[idx], percentage[idx].item()) for idx in indices[0][:5]]
And here is what resnet101 predicted.
[('Labrador retriever', 48.25556945800781),
('dingo, warrigal, warragal, Canis dingo', 7.900787353515625),
('golden retriever', 6.916920185089111),
('Eskimo dog, husky', 3.6434383392333984),
('bull mastiff', 3.0461232662200928)]
Just like AlexNet, ResNet managed to predict that it was a dog with very high confidence and predicted that it was a Labrador Retriever with a 48.25% confidence. That’s pretty good!
2. Model Comparison
So far we have discussed how we can use pre-trained models to perform image classification but one question that we have yet to answer is how do we decide which model to choose for a particular task. In this section we will compare the pre-trained models based on the following criteria:
- Top-1 Error: A top-1 error occurs if the class predicted by a model with the highest confidence is not the same as the true class.
- Top-5 Error: A top-5 error occurs when the true class is not among the top 5 classes predicted by a model (sorted in terms of confidence).
- Inference Time on CPU: Inference time is the time taken for the model inference step.
- Inference Time on GPU
- Model size: Here size stands for the physical space occupied by the .pth file of the pre-trained model supplied by PyTorch
A good model will have low Top-1 error, low Top-5 error, low inference time on CPU and GPU and low model size.
All the experiments were performed on the same input image and multiple times so that the average of all the results for a particular model can be analyzed. The experiments were performed on Google Colab. Now, let’s have a look at the results obtained.
2.1. Accuracy Comparison of Models
The first criterion we will discuss consists of Top-1 and Top-5 errors. Top-1 error is when the top predicted class differs from the ground truth. Since the problem is rather a difficult one, there is another error measure called Top-5 error. A prediction is classified as an error if none of the top-5 predicted classes are correct.

Notice from the graph that both errors follow a similar trend. AlexNet was the first attempt based on Deep Learning and there has been improvement in the error since then. Notable mentions are GoogLeNet, ResNet, VGGNet, ResNext.
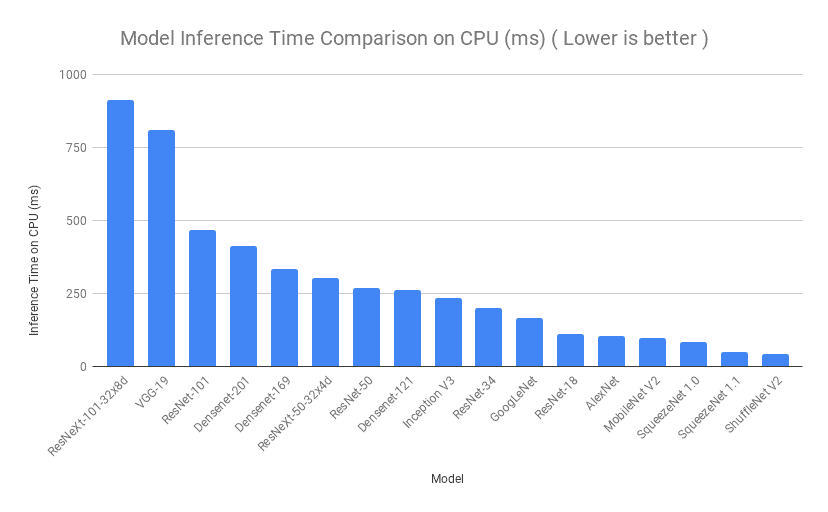
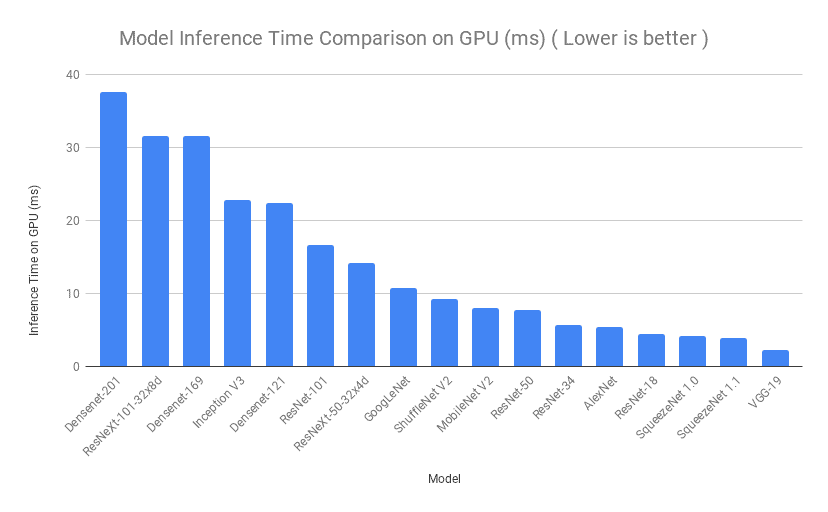
2.2. Inference Time Comparison
Next, we will compare the models based on the time taken for model inference. One image was supplied to each model multiple times and the inference time for all the iterations was averaged. Similar process was performed for CPU and then for GPU on Google Colab. Even though there are some variations in the order, we can see that SqueezeNet, ShuffleNet and ResNet-18 had a really low inference time, which is exactly what we want.
2.3. Model Size Comparison
A lot of times when we are using a Deep Learning model on an android or iOS device, the model size becomes a deciding factor, sometimes even more important than accuracy. SqueezeNet has the minimum model size (5 MB), followed by ShuffleNet V2 (6 MB) and MobileNet V2 (14 MB). It’s obvious why these models are preferred in mobile apps utilizing deep learning.

2.4. Overall Comparison
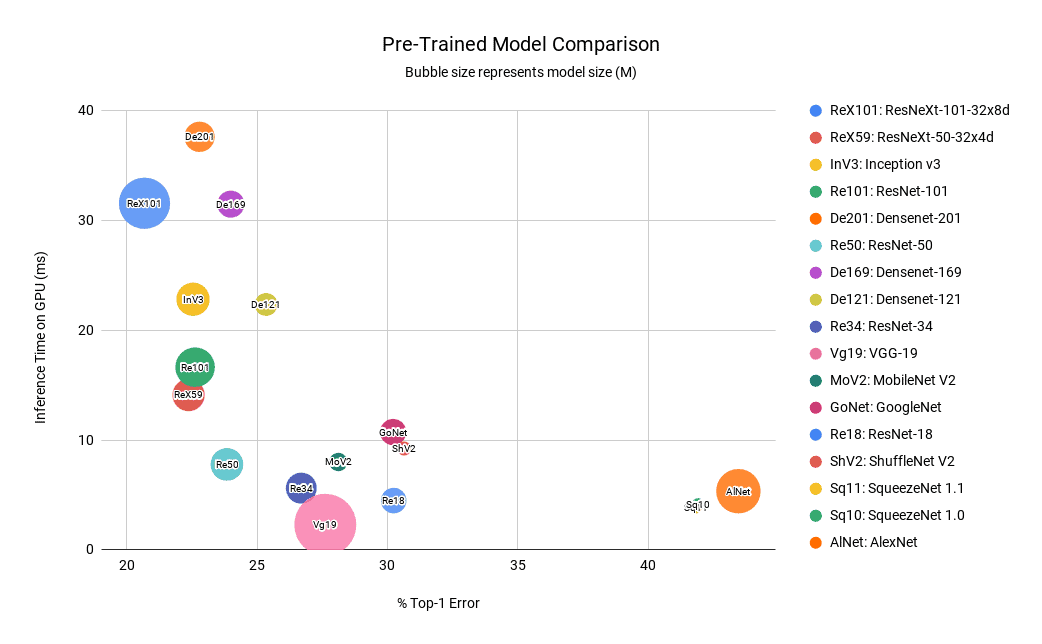
We discussed which model performed better based on a particular criterion. We can squeeze all those important details in one bubble chart which we can then refer to for deciding which model to go for based on our requirements.
The x-coordinate we are using is Top-1 error (lower is better). The y-coordinate is the inference time on GPU in milliseconds (lower is better). The bubble size represents the model size (lower is better).
NOTE :
- Smaller Bubbles are better in terms of model size.
- Bubbles near the origin are better in terms of both Accuracy and Speed.
3. Final Verdict
- It is clear from the above graph that ResNet50 is the best model in terms of all three parameters ( small in size and closer to origin )
- DenseNets and ResNext101 are expensive on inference time.
- AlexNet and SqueezeNet have pretty high error rate.
Well, that’s all, folks! In this post, we covered how we can use the TorchVision module to carry out Image Classification using pre-trained models – a 4-step process. We also made model comparisons to decide what model to choose depending on our project requirements. In the next post, we will cover how to use transfer learning to train a model on a custom dataset using PyTorch.
Also read: PyTorch for Beginners: Semantic Segmentation using torchvision
100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning