



The field of computer vision has existed since the late 1960s. Image classification and object detection are some of the oldest problems in computer vision that researchers have tried to solve for many decades. Using neural networks and deep learning, we have reached a stage where computers can start to understand and recognize an object with high accuracy, even surpassing humans in many cases. And to learn about neural networks and deep learning with computer vision, the OpenCV DNN module is a great place to start. With its highly optimized CPU performance, beginners can get started easily even if they do not have a very powerful GPU enabled system.
In this regard, this blog post will serve as the best starting point.

Not only the theory part but also we cover hands-on experience with OpenCV DNN. We will discuss classification and object detection in images and real-time videos in detail.
- What is an OpenCV DNN Module?
- A complete step by step guide to image classification using OpenCV DNN.
- Object Detection using OpenCV DNN
- Summary
So, let’s jump into the blog post now and get started with deep learning in computer vision with the OpenCV DNN module.
What is OpenCV DNN Module?
We all know OpenCV as one of the best computer vision libraries. Additionally, it also has functionalities for running deep learning inference as well. The best part is supporting the loading of different models from different frameworks, using which we can carry out several deep learning functionalities. The feature of supporting models from different frameworks has been a part of OpenCV since version 3.3. Still, many newcomers to the field are unaware of this great feature of OpenCV. Therefore, they tend to miss many fun and good learning opportunities.
Why Choose the OpenCV DNN Module?
The OpenCV DNN module only supports deep learning inference on images and videos. It does not support fine-tuning and training. Still, the OpenCV DNN module can be a perfect starting point for any beginner to get into deep learning based computer vision and play around.
One of the OpenCV DNN module’s best things is that it is highly optimized for Intel processors. We can get good FPS when running inference on real-time videos for object detection and image segmentation applications. We often get higher FPS with the DNN module when using a model pre-trained using a specific framework. For example, let us look at image classification inference speed for different frameworks.
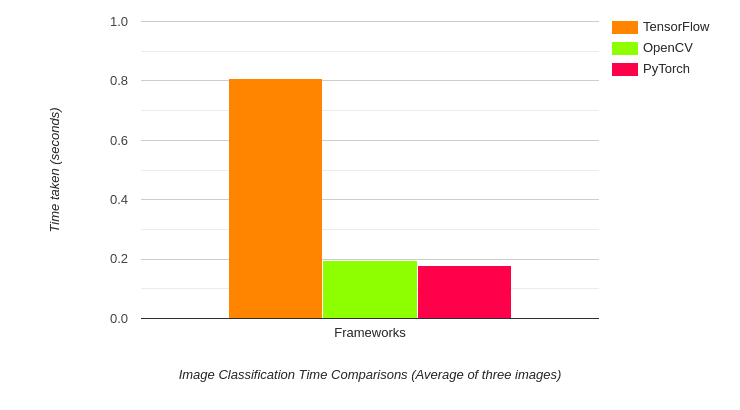
The above results are inference timing for the DenseNet121 model. Surprisingly, OpenCV is much faster than TensorFlow’s original implementations while falling behind PyTorch by a small margin. In fact, TensorFlow’s inference time is close to 1 second, whereas OpenCV takes less than 200 milliseconds.
The above benchmarks are done using the latest versions at the time of this writing. They are PyTorch 1.8.0, OpenCV 4.5.1, and TensorFlow 2.4. All tests are done on Google Colab which has Intel Xeon processors 2.3Ghz processors.
The same is true even in the case of object detection.

The above plot shows the results for FPS on video with Tiny YOLOv4 on the original Darknet framework and OpenCV. The benchmark was done on an Intel i7 8th Gen laptop CPU with 2.6 GHz clock speed. We can see that in the same video, the OpenCV’s DNN module is running at 35 FPS whereas Darknet compiled with OpenMP and AVX is running at 15 FPS. And Darknet (without OpenMP or AVX) Tiny YOLOv4 is the slowest, running at only 3 FPS. This is a huge difference considering we are using the original Darknet Tiny YOLOv4 models in both cases.
The above graphs show the actual usefulness and power of the OpenCV DNN module when working with CPUs. Because of its fast inference time, even on CPUs, it can act as an excellent deployment tool on edge devices where computation power is limited. The edge devices based on ARM processors are some of the best examples. The following graph is good proof of that.

The above plots show the FPS for different frameworks and models running on the Raspberry Pi 3B. The results are very impressive. For the SqueezeNet and MobileNet models, OpenCV surpasses all the other frameworks in terms of FPS. For GoogLeNet, OpenCV comes second, with TensorFlow being the fastest. For Network in Network, OpenCV Raspberry FPS is the slowest.
The above few graphs show optimized OpenCV, and how fast it is for neural network inference. The data serves as a perfect reason to choose to learn about the OpenCV DNN module in detail.
Different Deep Learning Functionalities that OpenCV DNN Module Supports
We have established that by using the OpenCV DNN module, we can carry out deep learning based computer vision inference on images and videos. Let us take a look at all the functionalities it supports. Interestingly, most of the deep learning and computer vision tasks that we can think of are supported. The following list will give us a pretty good idea of the features.
- Image classification.
- Object Detection.
- Image segmentation.
- Text detection and recognition.
- Pose estimation.
- Depth estimation.
- Person and face verification and detection.
- Person Reid.
The list is extensive and provides a lot of practical deep learning use cases. Find out more about all these in detail by visiting the OpenCV repository’s Deep Learning in OpenCV Wiki page.
The impressive fact is that there are many models to choose from depending on the system’s hardware and computing capability (we will see them later). We can find a model for every use case, from really compute-intensive models for state-of-the-art results to models that can run on low-powered edge devices.
Observe that it is impossible to go through all the above use cases in a single blog post. Hence, we will discuss Object Detection and human pose estimation in detail to give an idea of the working of select different models using OpenCV DNN.


Different Models that OpenCV DNN Module Supports
To support all the applications we discussed above, we need a lot of pre-trained models. Moreover, there are many state-of-the-art models to choose from. The following table lists some models according to the different deep learning applications.
| Image Classification | Object Detection | Image Segmentation | Text detection and recognition | Human Pose estimation | Person and face detection |
| Alexnet | MobileNet SSD | DeepLab | Easy OCR | Open Pose | Open Face |
| GoogLeNet | VGG SSD | UNet | CRNN | Alpha Pose | Torchreid |
| VGG | Faster R-CNN | FCN | Mobile FaceNet | ||
| ResNet | EfficientDet | OpenCV FaceDetector | |||
| SqueezeNet | |||||
| DenseNet | |||||
| ShuffleNet | |||||
| EfficientNet |
The models mentioned above are not exhaustive. There exist many more models. As noted earlier, completing listing or discussing each in detail in a single blog is almost impossible. The above list gives us a pretty good idea of how practical the DNN module can be in exploring deep learning in computer vision.
Different Frameworks that OpenCV DNN Module Supports
Looking at all the above models, a question that comes to mind is, “are all these models supported by a single framework”? Actually, no.
OpenCV DNN module supports many popular deep learning frameworks. The following are the deep learning frameworks that the OpenCV DNN module supports.
Caffe
We need two things to use a pre-trained Caffe model with OpenCV DNN. One is the model.caffemodel file that contains the pre-trained weights. The other one is the model architecture file which has a .prototxt extension. It is like a plain text file with a JSON like structure containing all the neural network layers’ definitions. To get a clear idea of how this file looks, please visit this link.
TensorFlow
For loading pre-trained TensorFlow models, we also need two files. The model weights file and a protobuf text file contain the model configuration. The weight file has a .pb extension which is a protobuf file containing all the pre-trained weights. If you have worked with TensorFlow before, you would know that the .pb file is the model checkpoint we get after saving the model and freezing the weights. The model configuration is held in the protobuf text file, which has a .pbtxt file extension.
Note: In newer versions of TensorFlow the model weight file might not be in .pb format. This is also true if you are trying to use one of your own saved models which may be in .ckpt or .h5 format. In that case, there are some intermediate steps to be performed before the models can be used with the OpenCV DNN module. In such cases, converting the models to ONNX format and then to .pb format is the best possible way to ensure that everything will work as expected.
Torch and PyTorch
For loading Torch model files, we need the file containing the pre-trained weights. Generally, this file has a .t7 or .net extension. But with the latest PyTorch models having a .pth extension, first converting to ONNX is the best way to proceed. After converting to ONNX, you can load them directly as OpenCV DNN supports ONNX models.
Darknet
The OpenCV DNN module supports the famous Darknet framework as well. One may recognize this if they have used official YOLO models with the Darknet framework.
Generally, to load the Darknet models, we need one model weights file having the .weights extension. The network configuration file will always be a .cfg file for a Darknet model.
Using Models that have been converted to ONNX format from different frameworks like Keras and PyTorch
Often, models trained in frameworks like PyTorch or TensorFlow might not be ready for use directly with the OpenCV DNN module. In those cases, generally, we convert the models to the ONNX format (Open Neural Network Exchange), which can then be used as it is or even converted to formats supported by other frameworks like TensorFlow or PyTorch.
To load an ONNX model, we need the .onnx weight file for the OpenCV DNN module.
Please visit the official OpenCV documentation to learn about the different frameworks, their weight files, and the configuration files.
Most probably, the above list covers all the famous deep learning frameworks. To get a complete idea of all the frameworks and models that the OpenCV DNN module supports, please visit the official Wiki page.
All the models we see here are tested to work perfectly with the OpenCV DNN module. In theory, any model from the above frameworks should work with the DNN module. We only need to find the correct weight file and the corresponding neural network architecture file. Things will clarify more when we start this tutorial’s coding part.
We have covered enough theory. Let us dive into the coding part of this tutorial. First, we will have a complete walkthrough of image classification using the OpenCV DNN module. Then we will carry out object detection using the DNN module.
A Complete Guide to Image Classification using OpenCV DNN Module
This section will classify an image using the OpenCV DNN module. We will cover each step in detail to clear everything by the end of this section.
We will use a neural network model trained on the very famous ImageNet dataset using the Caffe framework. Specifically, we will use the DensNet121 deep neural network model for the classification task. The advantage being it is pre-trained on 1000 classes from the ImageNet dataset. We can expect that the model will already see whatever image we want to classify. This allows us to choose from an extensive range of images.
We will use the following image of a tiger for the image classification task.

In very brief, the following are the steps that we will follow while classifying an image.
- Load the class names text file from the disk and extract the required labels.
- Load the pre-trained neural network model from disk.
- Load the image from the disk and prepare the image to be in the correct input format for the deep learning model.
- Forward propagate the input image through the model and obtain the outputs.
Now let us see each step in detail, along with the code.
Importing the Modules and Loading the Class Text Files
We will need to import the OpenCV and Numpy modules for the Python code. For C++, we need to include the OpenCV and OpenCV’s DNN library.

Python:
import cv2
import numpy as np
C++
#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/dnn/all_layers.hpp>
using namespace std;
using namespace cv;
using namespace dnn;
Remember that we discussed that the DenseNet121 model we will use had been trained on the 1000 ImageNet classes. We will need some way to load these 1000 classes into memory and have easy access to them. Such classes are typically available in text files. One such file is called the classification_classes_ILSVRC2012.txt file containing all the class names in the following format.
tench, Tinca tinca
goldfish, Carassius auratus
great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias
tiger shark, Galeocerdo cuvieri
hammerhead, hammerhead shark
…
Each new line contains all the labels or class names specific to a single image. For example, the first line contains tench, Tinca Tinca. These are two names that belong to the same kind of fish. Similarly, the second line has two names belonging to the goldfish. Typically, the first name is the most common name that almost everyone recognizes.
Let us see how we can load such a text file and extract the first name from each line to use them as labels while classifying images.
Python:
# read the ImageNet class names
with open('../../input/classification_classes_ILSVRC2012.txt', 'r') as f:
image_net_names = f.read().split('\n')
# final class names (just the first word of the many ImageNet names for one image)
class_names = [name.split(',')[0] for name in image_net_names]
C++
std::vector<std::string> class_names;
ifstream ifs(string("../../input/classification_classes_ILSVRC2012.txt").c_str());
string line;
while (getline(ifs, line))
{
class_names.push_back(line);
}
First, we open the text file containing all the class names in reading mode and split them using each new line. Now, we would have all the classes stored in the image_net_names list in the following format.
[‘tench, Tinca tinca’, ‘goldfish, Carassius auratus’, ‘great white shark, white shark, man-eater, man-eating shark’, ...]
However, we need the first name from each line only. That is what the second line of code does. For each element in the image_net_names list, we split the elements using comma (,) as the delimiter and only keep the first of those elements. These names are saved in the class_names list. Now, the list will look like the following.
['tench', 'goldfish', 'great white shark', 'tiger shark', 'hammerhead', …]
Load the Pre-Trained DenseNet121 Model from Disk
As discussed earlier, we will use a pre-trained DenseNet121 model that has been trained using the Caffe deep learning framework.
We will need the model weight files (.caffemodel) and the model configuration file (.prototxt).
Let us see the code and then get to the explanation part of the loading of the model.
Python:
# load the neural network model
model = cv2.dnn.readNet(model='../../input/DenseNet_121.caffemodel', config='../../input/DenseNet_121.prototxt', framework='Caffe')
C++
// load the neural network model
auto model = readNet("../../input/DenseNet_121.prototxt",
"../../input/DenseNet_121.caffemodel",
"Caffe");
You can see, we are using a function called readNet() from the OpenCV DNN module, which accepts three input arguments.
model: This is the path to the pre-trained weights file. In our case, it is the pre-trained Caffe model.config: This is the path to the model configuration file, and it is the Caffe model’s .prototxt file in this case.framework: Finally, we need to provide the framework name that we are loading the models. For us, it is the Caffe framework.
Along with the readNet() function, the DNN module also provides functions to load models from specific frameworks, where we do not have to provide the framework argument. The following are those functions.
readNetFromCaffe(): This is used to load pre-trained Caffe models and accepts two arguments. They are the path to the prototxt file and the path to the Caffe model file.readNetFromTensorflow(): We can use this function to directly load the TensorFlow pre-trained models. This also accepts two arguments. One is the path to the frozen model graph and the other is the path to the model architecture protobuf text file.readNetFromTorch(): We can use this to load Torch and PyTorch models which have been saved using thetorch.save() function. We need to provide the model path as the argument.readNetFromDarknet(): This is used to load the models trained using the DarkNet framework. We need to provide two arguments here as well. One of the path to the model weights and the other is the path to the model configuration file.readNetFromONNX(): We can use this to load ONNX models and we only need to provide the path to the ONNX model file.
This blog post will stick with the readNet() function to load the pre-trained models. We will use the same function in the object detection section as well.
Read the Image and Prepare it for Model Input
We will read the image from the disk, as usual, using OpenCV’s imread() function. Note there are a few other details that we need to take care of. The pre-trained models we load using the DNN module do not directly take the read image as input. We need to do some preprocessing before that.
Let us first write the code, and then it will be much easier to get into the technical details.
Python:
# load the image from disk
image = cv2.imread('../../input/image_1.jpg')
# create blob from image
blob = cv2.dnn.blobFromImage(image=image, scalefactor=0.01, size=(224, 224), mean=(104, 117, 123))
C++
// load the image from disk
Mat image = imread("../../input/image_1.jpg");
// create blob from image
Mat blob = blobFromImage(image, 0.01, Size(224, 224), Scalar(104, 117, 123));
While reading the image, we assume that it is two directories previous to the current directory and inside the input folder. The next few steps are essential. We have a blobFromImage() function which prepares the image in the correct format to be fed into the model. Let us go over all the arguments and learn about them in detail.
image: This is the input image that we just read above using the imread() function.scalefactor: This value scales the image by the provided value. It has a default value of 1 which means that no scaling is performed.size: This is the size that the image will be resized to. We have provided the size as 224×224 as most classification models trained on the ImageNet dataset expect this size only.mean: The mean argument is pretty important. These are actually the mean values that are subtracted from the image’s RGB color channels. This normalizes the input and makes the final input invariance to different illumination scales.
There is one other thing to note here. All the deep learning models expect input in batches. However, we only have one image here. Nevertheless, the blob output that we get here actually has a shape of [1, 3, 224, 224]. Observe that one extra batch dimension has been added by the blobFromImage() function. This would be the final and correct input format for the neural network model.
Forward Propagate the Input Through the Model
Now, as our input is ready, we can make the predictions.
Python
# set the input blob for the neural network
model.setInput(blob)
# forward pass image blog through the model
outputs = model.forward()
There are two steps for making predictions.
- First, we have to set the input blob to our neural network model that we have loaded from the disk.
- The second step is to use the forward() function for forward propagating the blob through the model, which gives us all the outputs.
We are carrying out both the steps in the above code block.
The outputs, which is an array, holds all the predictions. But before we can see the outputs and class labels correctly, there are a few preprocessing steps that we need to complete.
Currently, outputs has a shape of (1, 1000, 1, 1) and it is difficult to extract the class labels as it is. So, the following block of code reshapes the outputs, after which we can easily get the correct class labels and map the label ID to the class names.
Python:
final_outputs = outputs[0]
# make all the outputs 1D
final_outputs = final_outputs.reshape(1000, 1)
# get the class label
label_id = np.argmax(final_outputs)
# convert the output scores to softmax probabilities
probs = np.exp(final_outputs) / np.sum(np.exp(final_outputs))
# get the final highest probability
final_prob = np.max(probs) * 100.
# map the max confidence to the class label names
out_name = class_names[label_id]
out_text = f"{out_name}, {final_prob:.3f}"
# put the class name text on top of the image
cv2.putText(image, out_text, (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('Image', image)
cv2.waitKey(0)
cv2.imwrite('result_image.jpg', image)
C++
// set the input blob for the neural network
model.setInput(blob);
// forward pass the image blob through the model
Mat outputs = model.forward();
Point classIdPoint;
double final_prob;
minMaxLoc(outputs.reshape(1, 1), 0, &final_prob, 0, &classIdPoint);
int label_id = classIdPoint.x;
// Print predicted class.
string out_text = format("%s, %.3f", (class_names[label_id].c_str()), final_prob);
// put the class name text on top of the image
putText(image, out_text, Point(25, 50), FONT_HERSHEY_SIMPLEX, 1, Scalar(0, 255, 0), 2);
imshow("Image", image);
imwrite("result_image.jpg", image);
After we shape the outputs, it has a shape of (1000, 1,) indicating that it has 1000 rows for all the 1000 labels. Each row holds the score corresponding to the class label, which looks like the following.
[[-1.44623446e+00]
[-6.37421310e-01]
[-1.04836571e+00]
[-8.40160131e-01]
…
]
From these, we are extracting the highest label index and storing it in label_id. However, these scores are not actually probability scores. We need to get the softmax probabilities to know with what probability the model predicts the highest-scoring label.
In the Python code above, we are converting the scores to softmax probabilities using np.exp(final_outputs) / np.sum(np.exp(final_outputs)). Then we are multiplying the highest probability score with 100 to get the predicted score percentage.
The final steps would be annotating the class name and percentage on top of the image. Then we are visualizing the image and saving the result to the disk.
After executing the code, we will get the following output.

The DenseNet121 model correctly predicts the image as that of a tiger, and that too with 91% confidence. The result is quite good.
In the above sections, we saw how to use the OpenCV DNN module for image classification using the DenseNet121 neural network model. We also went through each of the steps in detail to better understand the working of the DNN module.
We will use OpenCV DNN and object detection in images and videos in the following sections.
Object Detection using OpenCV DNN
Using the OpenCV DNN module, we can easily get started with Object Detection in deep learning and computer vision. Like classification, we will load the images, the appropriate models and forward propagate the input through the model. The preprocessing steps for proper visualization in object detection is going to be a bit different. We will get to all of that as we progress through the rest of the blog post.
Let us start with object detection in images.
Object Detection in Images using OpenCV DNN
Just like classification, here also, we will leverage the pre-trained models. These models have been trained on the MS COCO dataset, the current benchmark dataset for deep learning based object detection models.
MS COCO has almost 80 classes of objects, starting from a person to a car, to a toothbrush. The dataset contains 80 classes of everyday objects. We will also use a text file to load all the labels in the MS COCO dataset for object detection.
For object detection, we will use the following image.

We will use MobileNet SSD (Single Shot Detector), which has been trained on the MS COCO dataset using the TensorFlow deep learning framework. SSD models are generally faster when compared to other object detection models. Moreover, the MobileNet backbone also makes them less compute-intensive. So, it is a good model to start learning about object detection with OpenCV DNN.
Let us start with the coding part.
Python
import cv2
import numpy as np
C++
#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/dnn/all_layers.hpp>
using namespace std;
using namespace cv;
using namespace dnn;
- In the Python code, first we are importing the cv2 and numpy modules.
- For C++, we need to include the OpenCV and OpenCV DNN libraries.
Python
# load the COCO class names
with open('object_detection_classes_coco.txt', 'r') as f:
class_names = f.read().split('\n')
# get a different color array for each of the classes
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
C++
std::vector<std::string> class_names;
ifstream ifs(string("../../../input/object_detection_classes_coco.txt").c_str());
string line;
while (getline(ifs, line))
{
class_names.push_back(line);
}
Next we read the object_detection_classes_coco.txt file, which contains all the class names separated by a new line. We are storing each class name in class_names list.
The class_names list will be similar to the following.
['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', … 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush', '']
Along with that, we also have a COLORS array that holds tuples of three integer values. We can apply these random colors while drawing the bounding box for each class. The best part is that we will have a different colored bounding box for each class, and it will be easy for us to differentiate between the classes in the final result.
Load the MobileNet SSD Model and Prepare the Input
We will load the MobileNet SSD model using the readNet() function, which we used earlier also.
Python
# load the DNN model
model = cv2.dnn.readNet(model='frozen_inference_graph.pb', config='ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt',framework='TensorFlow')
C++
// load the neural network model
auto model = readNet("../../../input/frozen_inference_graph.pb",
"../../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt", "TensorFlow");
In the above code block:
- The model argument accepts the frozen inference graph path as the input, a pre-trained model that contains the weights.
- The
configargument accepts the path to the model configuration file that is a protobuf text file. - Finally, we specify the
framework, which is TensorFlow in this case.
Next, we will read the image from the disk and prepare the input blob file.
Python
# read the image from disk
image = cv2.imread('../../input/image_2.jpg')
image_height, image_width, _ = image.shape
# create blob from image
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True)
# set the blob to the model
model.setInput(blob)
# forward pass through the model to carry out the detection
output = model.forward()
C++
// read the image from disk
Mat image = imread("../../../input/image_2.jpg");
int image_height = image.cols;
int image_width = image.rows;
//create blob from image
Mat blob = blobFromImage(image, 1.0, Size(300, 300), Scalar(127.5, 127.5, 127.5),true, false);
//create blob from image
model.setInput(blob);
//forward pass through the model to carry out the detection
Mat output = model.forward();
Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());
For object detection, we are using a bit different argument values in the blobFromImage() function.
- We specify the
sizeto be 300×300 is the input size that SSD models generally expect in almost all frameworks. It is the same for TensorFlow as well. - We are also using the
swapRBthe argument this time. Generally, OpenCV reads the image in BGR format, and for object detection, the models expect the input to be in RGB format. So, theswapRBargument will swap the R and B channels of the image, making it RGB format.
We then set the blob to the MobileNet SSD model and forward propagating it using the forward() function.
The output we have is structured as follows:
[[[[0.00000000e+00 1.00000000e+00 9.72869813e-01 2.06566155e-02 1.11088693e-01 2.40461200e-01 7.53399074e-01]]]]
- Here, index position 1 contains the class label, which can be from 1 to 80.
- Index position 2 contains the confidence score. This is not a probability score but rather the model’s confidence for the object belonging to the class that it has detected.
- Of the final four values, the first two are x, y bounding box coordinates, and the last is the bounding box’s width and height.
Looping Over the Detections and Drawing the Bounding Boxes
We are all set to loop over the detections in output, and draw the bounding boxes around each detected object. The following is the code for looping over the detections.
Python
# loop over each of the detection
for detection in output[0, 0, :, :]:
# extract the confidence of the detection
confidence = detection[2]
# draw bounding boxes only if the detection confidence is above...
# ... a certain threshold, else skip
if confidence > .4:
# get the class id
class_id = detection[1]
# map the class id to the class
class_name = class_names[int(class_id)-1]
color = COLORS[int(class_id)]
# get the bounding box coordinates
box_x = detection[3] * image_width
box_y = detection[4] * image_height
# get the bounding box width and height
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# draw a rectangle around each detected object
cv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2)
# put the FPS text on top of the frame
cv2.putText(image, class_name, (int(box_x), int(box_y - 5)), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
cv2.imshow('image', image)
cv2.imwrite('image_result.jpg', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
C++
for (int i = 0; i < detectionMat.rows; i++){
int class_id = detectionMat.at<float>(i, 1);
float confidence = detectionMat.at<float>(i, 2);
// Check if the detection is of good quality
if (confidence > 0.4){
int box_x = static_cast<int>(detectionMat.at<float>(i, 3) * image.cols);
int box_y = static_cast<int>(detectionMat.at<float>(i, 4) * image.rows);
int box_width = static_cast<int>(detectionMat.at<float>(i, 5) * image.cols - box_x);
int box_height = static_cast<int>(detectionMat.at<float>(i, 6) * image.rows - box_y);
rectangle(image, Point(box_x, box_y), Point(box_x+box_width, box_y+box_height), Scalar(255,255,255), 2);
putText(image, class_names[class_id-1].c_str(), Point(box_x, box_y-5), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,255,255), 1);
}
}
imshow("image", image);
imwrite("image_result.jpg", image);
waitKey(0);
destroyAllWindows();
- Inside the
forloop, first, we extract the confidence score of the current detected object. As discussed, we can get it from the index position 2. - Then we have the
ifblock to check whether the detected object’s confidence is above a certain threshold or not. We are only moving forward to draw the bounding boxes of the confidence is above 0.4. - We get the class ID and map it to the MS COCO class names. Then we get a single color for the current class to draw the bounding boxes and put the class label text on top of the bounding box.
- We are then extracting the bounding box x and y coordinates and the bounding box’s width and height. Multiplying them with the image width and height, respectively, provides us with the correct values to draw the rectangles.
- In the final few steps, we are drawing the bounding box rectangles, writing the class text on top and visualizing the resulting image.
This is all the code that we need for object detection in images using OpenCV DNN. Executing the code gives us the following result.

In the above image, we can see that the results seem good. The model is detecting almost all the objects that are visible. However, there are a few incorrect predictions too. For example, the MobileNet SSD model is detecting the bicycle as a motorcycle on the right side. MobileNet SSDs tend to make such mistakes as they are made for real-time applications and trade accuracy for speed.
This marks object detection in images using OpenCV DNN. We will do one final thing to improve the learning process in this blog post. That is object detection in videos.
Object Detection in Videos using OpenCV DNN
The code for object detection in videos will be very similar to that of images. There will be a few changes as we make predictions on video frames instead of images.
The few lines of code are identical to object detection in images. Let us complete that part first.
Python
import cv2
import time
import numpy as np
# load the COCO class names
with open('object_detection_classes_coco.txt', 'r') as f:
class_names = f.read().split('\n')
# get a different color array for each of the classes
COLORS = np.random.uniform(0, 255, size=(len(class_names), 3))
# load the DNN model
model = cv2.dnn.readNet(model='frozen_inference_graph.pb', config='ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt',framework='TensorFlow')
# capture the video
cap = cv2.VideoCapture('../../input/video_1.mp4')
# get the video frames' width and height for proper saving of videos
frame_width = int(cap.get(3))
frame_height = int(cap.get(4))
# create the `VideoWriter()` object
out = cv2.VideoWriter('video_result.mp4', cv2.VideoWriter_fourcc(*'mp4v'), 30, (frame_width, frame_height))
C++
#include <iostream>
#include <fstream>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
#include <opencv2/dnn/all_layers.hpp>
using namespace std;
using namespace cv;
using namespace dnn;
int main(int, char**) {
std::vector<std::string> class_names;
ifstream ifs(string("../../../input/object_detection_classes_coco.txt").c_str());
string line;
while (getline(ifs, line))
{
class_names.push_back(line);
}
// load the neural network model
auto model = readNet("../../../input/frozen_inference_graph.pb",
"../../../input/ssd_mobilenet_v2_coco_2018_03_29.pbtxt.txt","TensorFlow");
// capture the video
VideoCapture cap("../../../input/video_1.mp4");
// get the video frames' width and height for proper saving of videos
int frame_width = static_cast<int>(cap.get(3));
int frame_height = static_cast<int>(cap.get(4));
// create the `VideoWriter()` object
VideoWriter out("video_result.avi", VideoWriter::fourcc('M', 'J', 'P', 'G'), 30, Size(frame_width, frame_height));
We can see that most of the code is the same. We are loading the same MS COCO class file and MobileNet SSD model.
Here, instead of an image, we are capturing a video using the VideoCapture() object. We are also creating a VideoWriter() object to properly save the resulting video frames.
Looping Over the Video Frames and Detecting Objects in Each Frame
As of now, we have our video and the MobileNet SSD model ready. The next step is to loop over each video frame and carry out object detection in each frame. In this way, we will treat each frame just as an image.
Python
# detect objects in each frame of the video
while cap.isOpened():
ret, frame = cap.read()
if ret:
image = frame
image_height, image_width, _ = image.shape
# create blob from image
blob = cv2.dnn.blobFromImage(image=image, size=(300, 300), mean=(104, 117, 123), swapRB=True)
# start time to calculate FPS
start = time.time()
model.setInput(blob)
output = model.forward()
# end time after detection
end = time.time()
# calculate the FPS for current frame detection
fps = 1 / (end-start)
# loop over each of the detections
for detection in output[0, 0, :, :]:
# extract the confidence of the detection
confidence = detection[2]
# draw bounding boxes only if the detection confidence is above...
# ... a certain threshold, else skip
if confidence > .4:
# get the class id
class_id = detection[1]
# map the class id to the class
class_name = class_names[int(class_id)-1]
color = COLORS[int(class_id)]
# get the bounding box coordinates
box_x = detection[3] * image_width
box_y = detection[4] * image_height
# get the bounding box width and height
box_width = detection[5] * image_width
box_height = detection[6] * image_height
# draw a rectangle around each detected object
cv2.rectangle(image, (int(box_x), int(box_y)), (int(box_width), int(box_height)), color, thickness=2)
# put the class name text on the detected object
cv2.putText(image, class_name, (int(box_x), int(box_y - 5)), cv2.FONT_HERSHEY_SIMPLEX, 1, color, 2)
# put the FPS text on top of the frame
cv2.putText(image, f"{fps:.2f} FPS", (20, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
cv2.imshow('image', image)
out.write(image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
else:
break
cap.release()
cv2.destroyAllWindows()
C++
while (cap.isOpened()) {
Mat image;
bool isSuccess = cap.read(image);
if (! isSucess) break;
int image_height = image.cols;
int image_width = image.rows;
//create blob from image
Mat blob = blobFromImage(image, 1.0, Size(300, 300), Scalar(127.5, 127.5, 127.5),
true, false);
//create blob from image
model.setInput(blob);
//forward pass through the model to carry out the detection
Mat output = model.forward();
Mat detectionMat(output.size[2], output.size[3], CV_32F, output.ptr<float>());
for (int i = 0; i < detectionMat.rows; i++){
int class_id = detectionMat.at<float>(i, 1);
float confidence = detectionMat.at<float>(i, 2);
// Check if the detection is of good quality
if (confidence > 0.4){
int box_x = static_cast<int>(detectionMat.at<float>(i, 3) * image.cols);
int box_y = static_cast<int>(detectionMat.at<float>(i, 4) * image.rows);
int box_width = static_cast<int>(detectionMat.at<float>(i, 5) * image.cols - box_x);
int box_height = static_cast<int>(detectionMat.at<float>(i, 6) * image.rows - box_y);
rectangle(image, Point(box_x, box_y), Point(box_x+box_width, box_y+box_height), Scalar(255,255,255), 2);
putText(image, class_names[class_id-1].c_str(), Point(box_x, box_y-5), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0,255,255), 1);
}
}
imshow("image", image);
out.write(image);
int k = waitKey(10);
if (k == 113){
break;
}
}
cap.release();
destroyAllWindows();
}
In the above code block, the model detects objects in each frame until there are no frames to be looped over in the video. Some important things to note:
- We are storing the start time before the detections in the
startvariable and the end time after the detection ends. - The above time variables help us to calculate the FPS (Frames Per Seconds). We are calculating the FPS and storing it in
fps. - In the final part of the code, we are also writing the calculated FPS on top of the current frame to get an idea of what kind of speed we can expect while running MobileNet SSD models using the OpenCV DNN module.
- Finally, we are visualizing each frame on the screen and saving those to disk as well.
Executing the above code will give the following output.
We are getting around more than 40 FPS on most frames on an i7 12th Gen laptop CPU. That is not bad at all, considering the number of detections. The model can detect almost all persons, vehicles, and traffic lights. Still, it is suffering a bit when trying to detect small objects such as handbags and backpacks. The 40 FPS on the CPU is what we get in return for the trade-off in accuracy and fewer detections of smaller objects.
Inference on GPU
We can also run all the classification and detection inference on GPU. We will need to compile the OpenCV DNN module from the source with GPU.
- If on Ubuntu, visit this post of LearnOpenCV.com to compile OpenCV with GPU.
- If on Windows, visit this link to compile OpenCV with GPU.
To run the inference on GPU, we need to simply change the C++ and Python code.
Python:
net.setPreferableBackend(cv2.dnn.DNN_BACKEND_CUDA)
net.setPreferableTarget(cv2.dnn.DNN_TARGET_CUDA)
C++:
net.setPreferableBackend(DNN_BACKEND_CUDA);
net.setPreferableTarget(DNN_TARGET_CUDA);
After loading the neural network model from the disk, we should add the above two lines of code. The first line of code ensures that the neural network will use the CUDA backend if the DNN module supports the CUDA GPU model.
The second line of code tells that all the neural network computations will happen on the GPU instead of the CPU. Using the CUDA enabled GPU, we should get higher FPS on the object detection video inference compared to the CPU. Even with images, the inference time should be much lower than in the case of CPU.
Summary
We introduced OpenCV’s DNN Module and discussed why we chose the DNN module. We have seen bar graphs comparing the performance. We also looked at the different Deep Learning functionalities, models and frameworks that OpenCV DNN Supports.
We discussed the Image Classification and Object Detection tasks using OpenCV’s DNN module for a hands-on experience. We also saw Object Detection in Videos using OpenCV DNN.
Key Takeaways
- Neural Networks and Deep Learning have reached a stage where computers can accurately understand and recognize objects. On occasion, they even surpass humans in certain use cases.
- OpenCV DNN module:
- Is the preferred choice for model inference, especially on Intel CPUs.
- Is easy to install.
- It comes with off-shelf, ready-to-use models and algorithms that fit most use cases.
- Although the DNN module does not have training capabilities but still has excellent deployment support for edge devices.
I hope you enjoyed the blog and learned the basics of OpenCV’s DNN Module. Do share your experience in the comments section.
100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning