





In this post, we will discuss the theory behind Mask RCNN Pytorch and how to use the pre-trained Mask R-CNN model in PyTorch.
This post is part of our series on PyTorch for Beginners.
1. Semantic Segmentation, Object Detection, and Instance Segmentation.
As part of this series, so far, we have learned about:
- Semantic Segmentation: In semantic segmentation, we assign a class label (e.g. dog, cat, person, background, etc.) to every pixel in the image.
- Object Detection: In object detection, we assign a class label to bounding boxes that contain objects.
A very natural idea is to combine the two together. We want to only identify a bounding box around an object, and we want to find which of the pixels inside the bounding box belong to the object.
In other words, we want a mask that indicates ( using color or grayscale values ) which pixels belong to the same object. An example is shown below:
The class of algorithms that produce the above mask are called Instance Segmentation algorithms. Mask R-CNN is one such algorithm.
Instance segmentation and semantic segmentation differ in two ways:
- In semantic segmentation, every pixel is assigned a class label, while in instance segmentation, that is not the case.
- We do not tell the instances of the same class apart in semantic segmentation. For example, all pixels belonging to the “person” class in semantic segmentation will be assigned the same color/value in the mask. In instance segmentation, they are assigned different values, and we can tell them which pixels correspond to which person. We can see this in the above image.
Check this post about image segmentation, where we have discussed the concept in detail.
Mask R-CNN Architecture
The architecture of Mask R-CNN is an extension of Faster R-CNN, which we discussed in this post.
Recall that the Faster R-CNN architecture had the following components
- Convolutional Layers: The input image is passed through several convolutional layers to create a feature map. If you are a beginner, think of the convolutional layers as a black box that takes in a 3-channel input image, and outputs an “image” with a much smaller spatial dimension (7×7), but a large number of channels (512).
- Region Proposal Network (RPN). The output of the convolutional layers is used to train a network that proposes regions that enclose objects.
- Classifier: The same feature map is also used to train a classifier that assigns a label to the object inside the box.
Also, recall that Faster R-CNN was faster than Fast R-CNN because the feature map was computed once and reused by the RPN and the classifier.
Mask R-CNN takes the idea one step further. In addition to feeding the feature map to the RPN and the classifier, it uses it to predict a binary mask for the object inside the bounding box.
One way of looking at the mask prediction part of Mask R-CNN is that it is a Fully Convolutional Network (FCN) used for semantic segmentation. The only difference is that the FCN is applied to bounding boxes, and it shares the convolutional layer with the RPN and the classifier.
The figure below shows a very high-level architecture.

2. Mask R-CNN with PyTorch [ code ]
In this section, we will learn how to use the Mask R-CNN pre-trained model in PyTorch.
2.1. Input and Output
The model expects the input to be a list of tensor images of shape (n, c , h, w), with values in the range 0-1. The size of images need not be fixed.
- n is the number of images
- c is the number of channels, for RGB images it is 3
- h is the height of the image
- w is the width of the image
The model returns - coordinates of bounding boxes,
- labels of classes the model predicts to be present in the input image, scores of the labels,
- the masks for each class are present in the labels.
2.2. Pretrained Model
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
The list of labels for instance segmentation is same as the object detection task.

2.3. Prediction of the Model
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
def get_prediction(img_path, threshold):
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x>threshold][-1]
masks = (pred[0]['masks']>0.5).squeeze().detach().cpu().numpy()
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())]
masks = masks[:pred_t+1]
pred_boxes = pred_boxes[:pred_t+1]
pred_class = pred_class[:pred_t+1]
return masks, pred_boxes, pred_class
- The image is obtained from the image path
- The image is converted to image tensor using PyTorch’s transforms
- The image is passed through the model to get the predictions
- Masks, prediction classes and bounding box coordinates are obtained from the model and soft masks are made binary(0 or 1). Example: the segment of cat is made 1 and the rest of the image is made 0.
The masks of each predicted object is given random colour from a set of 11 predefined colours for visualization of the masks on the input image.
def random_colour_masks(image):
colours = [[0, 255, 0],[0, 0, 255],[255, 0, 0],[0, 255, 255],[255, 255, 0],[255, 0, 255],[80, 70, 180],[250, 80,
190],[245, 145, 50],[70, 150, 250],[50, 190, 190]]
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
r[image == 1], g[image == 1], b[image == 1] = colours[random.randrange(0,10)]
coloured_mask = np.stack([r, g, b], axis=2)
return coloured_mask
2.4. Pipeline for Semantic Segmentation
def instance_segmentation_api(img_path, threshold=0.5, rect_th=3, text_size=3, text_th=3):
masks, boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for i in range(len(masks)):
rgb_mask = random_colour_masks(masks[i])
img = cv2.addWeighted(img, 1, rgb_mask, 0.5, 0)
cv2.rectangle(img, boxes[i][0], boxes[i][1],color=(0, 255, 0), thickness=rect_th)
cv2.putText(img,pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size,
(0,255,0),thickness=text_th)
plt.figure(figsize=(20,30))
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
- Masks, prediction class, and bounding box are obtained by get_prediction.
- Each mask is given a random color from the set of 11 colors.
- Each mask is added to the image in the ratio 1:0.5 with OpenCV.
- A bounding box is drawn with cv2.rectangle with the class name annotated as text.
- The final output is displayed


2.5 Inference
The pre-trained Model takes around 10 seconds for inference on CPU and 0.21 second in NVIDIA GTX 1080 Ti GPU.

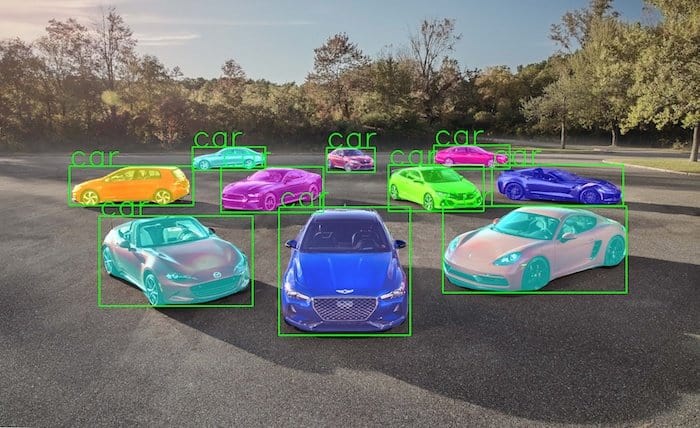


3. Faster R-CNN vs. Mask R-CNN performance
We know the Mask R-CNN is computationally more expensive than Faster R-CNN because Mask R-CNN is based on Faster R-CNN, and it does the extra work needed for generating the mask.
How much more expensive is this model? Let’s find out.
3.1 Comparing the inference time of model in CPU & GPU
We measured the time taken by the model to predict the output for an input image on a CPU and on a GPU. On the CPU the speed is surprisingly close, but on the GPU, Mask R-CNN takes about 47 milliseconds more.
| Models | CPU | GPU |
|---|---|---|
| Faster R-CNN ResNet-50 FPN | 8.45859 s | 0.15356 s |
| Mask R-CNN ResNet-50 FPN | 9.82342 s | 0.21595 s |
3.2 Memory requirements of the models
We also measured the memory required by the model.
| Models | memory(GB) |
|---|---|
| Faster R-CNN ResNet-50 FPN | 5.2 |
| Mask R-CNN ResNet-50 FPN | 5.4 |


100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning