

CVPR 2024 (Computer Vision and Pattern Recognition) is an annual conference held from June 17th to 21st at the Seattle Convention Center, USA, which was a huge success. The IEEE CVPR 2024 Research Papers has an acceptance rate of just ~ 23.6%, proving its high-quality research standards. The conference offered many interesting papers, workshops, datasets, and benchmarks for the computer vision community, which may be the foundation for the next decade.

In this article, we primarily aim to focus on:
- What problem statement existed in each category?
- What were the novel methodologies the authors carried out?
- And finally, there are impressive demos with the GitHub repository link for the respective papers.
This is the second part of our series on noteworthy papers from CVPR 2024. In our last article, we covered a wide variety of papers that drive current research in 3D Diffusion, Autonomous Vehicles, NeRF, and more.
If you are here directly to this article, bookmark our Part 1 of CVPR 2024: An Overview to read it for later.

Here is a quick overview of 11 papers that we will cover.
- Florence 2
- DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
- DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
- From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
- Object Recognition as Next Token Prediction
- MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
- ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation
- MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation
- EventPS: Real-Time Photometric Stereo Using an Event Camera
- Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods
- LEAP-VO: Long-term Effective Any Point Tracking for Visual Odometry
- Key Datasets
- Special Mention
- Conclusion
1. Florence 2
Arxiv: https://arxiv.org/abs/2311.06242
Problem statement: Unified Architecture for Vision tasks.
Category: Vision, Language, and Reasoning

Florence-2 by Bin Xiao et al. from Azure AI, Microsoft is a strong foundational VLM that outshines its competitors showcasing task agnostic zero-shot performance. Florence-2 was pre-trained on the FLD-5B dataset having 126M images. The authors point out that by unfreezing the vision backbone the model’s ability is enhanced to learn from region and pixels. It was also found that language pre-trained weights had less impact on purely vision-based tasks.
The datasets were prepared and refined using specialist models and services like Mask R-CNN, DINO, Azure OCR, etc., which excel at specific task categories and are trained with weak supervision.
Model Architecture

Understanding global semantics and local features is vital for image comprehension. Florence 2 excels at this and adopts a sequence-to-sequence framework to address various vision tasks in a unified manner.
Vision or Image Encoder
Florence 2 uses a DaViT vision encoder to preprocess input images of shape I ∈ R H×W×3 (H, W, channels) to flatten visual token embeddings (V ∈ R Nv×Dv, where Nv and Dv represent the number and dimensionality of vision tokens, respectively). Along with this, multi-task prompts are tokenized as text+location embeddings.
Multi-modality encoder decoder
Following the Image Encoder, a standard transformer encoder block’s cross-attention captures the relationship between visual and textual queries. Then, the decoder’s higher-dimensional output is projected into interpretable text, visual, and location representations for downstream tasks.
Model Configuration:

Inference Results: (Florence-2-large-ft)
Here, FT means a Fine-tuned model on a collection of downstream tasks.
Let’s perform some experiments on an RTX 4050 GPU with an i5 CPU machine to test Florence-2-large-ft’s capabilities on various downstream tasks. You can test with your images using HuggingFace Spaces listed on the Model’s Page.
Task: <MORE_DETAILED_CAPTION>

Task: <OPEN_VOCABULARY_DETECTION>
Prompt: Camel

Task: <OCR>

Highlights of Paper:
- By extending the vocab size of the tokenizer to include location tokens, the model performed better in both spatial coverage and semantic granularity. This eliminates the need for task-specific heads, making Florence-2 a good generalist model.
- Despite their small sizes (base – 0.23B and large – 0.77 B), the models give a neck-to-neck performance to large models like Flamingo, PALI, and Kosmos2.
- Because of its unified architecture, Florence-2 is capable of tasks such as Visual grounding, Object Detection, Referring Expression Segmentation, open vocabulary detection, detailed captioning etc.
💡 Interesting Fact: Earlier in 2018, Project Florence by Microsoft aimed to develop a plant human interface using light and electrical signals.
Observation and Takeaways
From our initial testing, we found that Florence-2 excels at OCR and Detailed Captioning. However, in some images consisting of difficult scenarios, it struggles with prompt specified object detection or segmentation compared to supervised task specific models like YOLO and Mask R-CNN.
The author suggests further fine-tuning Florence 2 can improve its domain and task adaption.
- Florence-2 Inference Notebook [ Link ]
- Fine-tune Florence-2 Blog [ Link ]


2. DocRes: A Generalist Model Toward Unifying Document Image Restoration Tasks
Arxiv: https://arxiv.org/abs/2405.04408
Problem statement: Single network capable of doing five document restoration tasks.
Category: Document analysis and understanding
- DocRes, by Jiaxin Zhang et al. from South China University, is a generalist model for document restoration that eliminates the need for multiple models for specific tasks which misses the synergies in input images among tasks.It can do five mutli-tasks like dewarping,deshadowing, appearance enhancement, deblurring and binarization.
- Existing methods heavily rely on image-to-image pair visual prompts, ProRes, and Mask Image Modeling (MIM). These methods are resource intensive as they follow a ViT framework which is limited to (448×448). This confines it to adapt to variable resolutions commonly up to 1K.
- DocRes addresses this through an effective visual prompt approach called Dynamic Task-Specific Prompt (DTSPrompt). DocRes using DTSPrompt analyzes the input image to extract task-specific features. On the basis of prior extracted features, DTSPrompt dynamically generates prompts specific to each task resulting in superior model performance.
DTSPrompt dynamically adapts to the input image ![$[ \text{Is} \in \mathbb{R}^{h \times w \times 3} ]$](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-8fa90edba8414f9c17814e83cf47c79f_l3.png) .
.
![$ \text{DTSPrompt} = [ G(\text{Is}, \text{task}) \in \mathbb{R}^{h \times w \times 3} ] $](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-f8d9c758df6206bdbed02354147226e3_l3.png)
where, 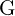 – DTSPromptGenerator ;
– DTSPromptGenerator ; 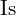 – Input document
– Input document
Unlike Florence-2 which is a task agnostic generalist model, DocRes is a task oriented generalist model which is an essential aspect for document restoration tasks.

Dynamic task-specific prompt:
1. Dewarping: The network uses the simplest text line mask algorithm for de-warping, which assists the document segmentation model in generating document masks. Additionally the authors incorporate the x and y coordinates of each pixel as positional information (prior features) to facilitate backward mapping, thus enabling the model to better understand and correct spatial distortions.
DTSPrompt for flattening documents is as follows:
![$[ G(\text{Is}, \text{``dewarp''}) = [P_m (\text{Is}), P_{cx}, P_{cy}] ]$](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-c9685312228c8b3d4a5ca4a1060a7489_l3.png)
where, prior document masks and positional information is concatenated along the channel dimension.
2. Deshadowing:
DocRes pipeline uses the background of the document with shadow as prior features. The author mentions that to get the background they use dilation operations followed by a median filter to remove text and to smooth out artifacts.
DTSPrompt for shadow removal is,
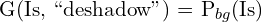
3. Appearance Enhancement: Usually, background light, shadow map, or white-balance kernels are used as prior features for a clean appearance restoration. But here, the author opted for a simple approach by finding a difference between an input image and document background estimated (Pbg) as in our earlier task, as a guidance cue to the model for the initial enhancement process.
Clean appearance restoration follows an empirical formula as:
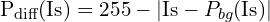
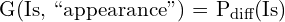
4. Deblurring: When trying to fix a blurred image, traditionally, we use methods like gradient distribution of the image as a prior feature, which shows how the brightness varies across the image. However, in this paper, the advantage of the gradient map (Pg (Is) ∈ R^h×w ) of a picture is taken into account.
Deblurring is achieved using a DTSPrompt as:
![$G(\text{Is}, \text{``deblur''}) = [P_g(\text{Is}), P_g(\text{Is}), P_g(\text{Is})]$](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-4ff7bc9586800de7b11480778d09d8bf_l3.png)
5. Binarization: As we know, Binarization involves converting a grayscale or color image into a binary mask to separate the text from the background. For this, DocRes first uses the Sauvola binarization algorithm to determine which pixels of an image should be either black(0) or white(255), denoted by Pb(Is). Along with this, threshold map (Pt) and gradient information (Pg) are used as prior features for refining network’s decision.
For the Text segmentation task, the DTSPrompt is formulated as
![$G(\text{Is}, \text{``binarize''}) = [P_b(\text{Is}), P_t(\text{Is}), P_g(\text{Is})]$](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-2fc13085672faef2c0d7bbf12d94991b_l3.png)

Highlights of the Paper
- “DocRes” ingenuity lies in its Prompt fusion and restoration network. The authors did this by integrating DTSPrompt with input image ( ) along the channel dimension to create a new input
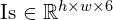 to the restoration network (Restormer model).
to the restoration network (Restormer model).
- DocRes shows excellent performance across multi-tasks often surpassing unified models like De-GAN, DocDiff as well as task-specific SOTA models like DocGeo for dewarping, BGSNet for deshadowing, UDoc-GAN for appearance enhancement and deblurring. However, for the binarization task, GDB holds the lead, with DocRes closely trailing behind it.
- DocRes can be adapted for various image resolutions by replacing the framework(e.g., ViT). Also, the author discusses how DocRes is capable of generalizing out-of-domain data through their ablation studies.
Inference Results
Now it’s time for real testing; inference is performed on an RTX 3080Ti and i7-13700K with 12-cores.
Note: In inference.py, replace np.bool with bool to run without numpy error in colab.
!python inference.py --im_path ./input/151_in.png --task end2end --save_dtsprompt 1

end2endObservation and Takeaways
Based on our initial round of testing, we found that the DocRes end2end task requires nearly 10GB GPU vRAM. However, the inference results are quite promising. Future work can focus on finding ways to run DocRes in an optimized way.
Repository: [ Link ]
HuggingFace Spaces [ DocRes ]
For a similar Document restoration using deep learning and document scanner using OpenCV, you may find it interesting to read our earlier posts.
You can access the inference notebook for the above project from the Download Code section.

3. DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Arxiv: https://arxiv.org/abs/2403.02075
Problem statement: Realtime and accurate diffusion-based non-linear tracker.
Category: Video: Low-level Analysis, motion, and tracking
DiffMOT by Weiyi Lv et al. from Shanghai University is a first-of-its-kind, diffusion probabilistic-based model for real-time Multi-Object Tracking (MOT) focusing on challenges in predicting non-linear motion.
MOTs that involve linear motion, like Pedestrian detection, are easily tracked by heuristic methods like the Kalman filter. Kalman Filters assume that an object’s motion, velocity, and direction remain constant within small intervals of time. As a result, KF Trackers don’t work well in complex scenarios with non-linear motion (i.e., non-uniform velocity and direction).
For example, dancers on a stage or players in a sport perform different movements at varying speeds.
But DiffMOT tackles this kind of movement effectively by predicting the next position of an object’s bounding box. It does this by conditioning the trajectories of the object from the previous n frames, guiding the denoising process for the current frame.
Diffusion probabilistic models are inefficient because they start with a rough MOT guess and require generating thousands of samples and iterative refinement for precise final predictions, demanding heavy computation. To overcome this shortcoming, DiffMOT uses a Decoupled Diffusion-based Motion Predictor (D²MP ) approach.From previous trajectories and motion information, the motion predictor uses just one-step sampling to reduce inference time while still maintaining high accuracy. The association of correct bounding boxes over time uses the Hungarian Algorithm (similar to ByteTrack).
Architecture
Unlike a typical diffusion model with only data-to-noise mapping, D²MP contains data-to-zero (Forward process) and zero-to-noise (Reverse process) over time. An HMINet (Historical Memory Information Network) is used in the Reverse Process of motion predictor. This uses Multi Head Self Attention (MHSA) to capture long-range dependencies in the previous frame and summarize them into a conditional embedding to predict the motion in the next frame.
Highlights of the Paper:
- DiffMOT achieves State-of-the-art performance on non-linear datasets like DanceTrack and SportsMOT with HOTA metrics of 62.3% and 76.2%, respectively, and a real-time inference speed of nearly 22.7FPS on an RTX3090 machine.
- It also outperforms widely used trackers like SORT, FairMOT, QDTrack, and ByteTrack in terms of accuracy.
- The detector can be easily replaced with any object detection model to increase speed and detection accuracy, indicating DiffMOT’s flexibility.
Tip
The HOTA (High Order Tracking Accuracy) metric combines the detection accuracy of the detector (YOLO-X), associated accuracy, and Localization accuracy by the tracker (D²MP).
Inference Results (Courtesy: DiffMOT Project)
Observation and Takeaways:
From the above inference results, we can observe that DiffMOT performs excellently in detection. However, it still faces challenges in videos with sudden changes or complex movements, leading to ID switching. Despite this, as the authors rightly mentioned in the paper, it clearly outperforms KF Trackers. DiffMOT is a good starting point for developing more accurate trackers based on diffusion models.
Note: As we have not tested DiffMOT extensively, we are refraining from making a qualitative comparison between DiffMOT and other state-of-the-art trackers. If you are interested in this further, please check the supplementary section of the paper on page 13.
Repository: [ Link ]
4. From Audio to Photoreal Embodiment: Synthesizing Humans in Conversations
Arxiv: https://arxiv.org/abs/2401.01885
Problem statement: Generate 3D avatars with just a single audio
Category: Humans: Face, body, pose, gesture, movement.
The Audio to Photreal framework by Evonne Ng et.al from Meta proposes a novel approach of generating photorealistic avatars that produce realistic conversational motions and gestures for the face, body, and hands just using an audio input.
The team achieved this by combining the diverse gesture possibilities offered by Vector Quantization (VQ) with the nuanced enhancements, such as eye gaze and smirks, provided by the diffusion network.
To better understand this, let’s look at an example: Let’s say we are animating a virtual person in a meta world to wave their hand.
- Without VQ and Diffusion, the wave might look stiff and repetitive like a robot.
- But with VQ, we can simulate it to have varying wave patterns or styles each time, making it look more like a human.
- Additionally, with a diffusion network, subtle realistic hand movements, such as bending fingers or hands, will make the avatar appear more natural and lifelike.
How does it work?
A rich set of dyadic conversations is captured between two people for training.The motion model comprises three major parts:
- a) Face Motion Model: This network is a diffusion model conditioned on conversational audio and lip movements. It generates facial expressions to reconstruct the facial mesh.
- b) Guide Pose Predictor: This autoregressive transformer-based VQ network takes audio as input and outputs coarse guide pose at 1 FPS.
- c) Pose Motion Predictor: The coarse poses are used as extra conditioning to this diffusion network to fill in higher frequency details of the motion.
Finally, the face and body pose are fed into an avatar render network, which generates a photorealistic avatar.
Highlights of Paper:
- The paper presents an alternative way to create synthesized motions of interpersonal conversation with photorealism, addressing the shortcomings of mesh-based or skeletal avatars.
- For the same input audio, the network generates diverse samples resulting in more peaky and dynamic motion like pointing. Despite being trained on specific individuals, the input features to the network are person agnostic and can adapt any persona for unseen audio without retraining.
- The team open-sourced a multi-view dyadic(between two people) conversation dataset for accurate body or face tracking and photorealistic 3D reconstruction.
Repository: [ Link ]
Colab Notebook: [ Link ]
💡 DEMO
You may be interested in seeing Real-Time Automatic Speech Recognition and Diarization results with OpenAI Whisper from our earlier article.

5. Object Recognition as Next Token Prediction
Arxiv: https://arxiv.org/abs/2312.02142
Problem Statement: Object recognition with language decoders
Category: Recognition: Categorization, detection, retrieval
The paper presents a thoughtful idea of object recognition in an autoregressive manner with LLMs by Kaiyu Yue et al. from Meta.

We know traditional linear classification networks like ResNet pretrained on the Imagenet dataset, which contains 1k classes and has a fixed final layer output dimension of 1000. This limits the ability of pretrained image classification models on a particular dataset to extend to other classes.
Modern architectures like CLIP can overcome this limitation to some extent by creating a flexible set of object embeddings to detect any class from the input image. However, CLIP requires a predefined set of object descriptions(gallery) to function as intended. The predefined gallery can cover only a subset of all possible objects and their variations.
In simple terms, if an image has a dog or cat, CLIP can identify them but may not be able to detect specific features like the breed (like a Dalmatian dog or Angora cat). Thus, even CLIP is limited and can cover only a portion of textual space in practical scenarios. Additionally, increasing the gallery size of CLIP results in performance degradation.
So, an ideal approach is to use LLM as a decoder to recognize any object and its variations in the textual space. Google’s Flamingo follows a similar approach, but it requires a few shot samples for each downstream task prior to the inference prompt.
To address this, the authors suggest a more straightforward approach: aligning LLM for recognition tasks only.

Here, pretrained CLIP or ViT is used as an image encoder, which projects the image embeddings to higher dimensions of the language decoder (LLM).
Model Architecture
- Instead of training the model on Visual Question Answering triplets, the approach uses image-caption pairs. The model was trained on the G70M dataset, which was made by gathering image pairs CC3M, COCO Captions, SBU, LAION-Synthetic-115M, etc.
- The model generates short and concise tags or labels only rather than a descriptive sentence about the image.
- The author’s ingenuity lies in the model’s tokenization mechanism. Different object labels are treated independently, but tokens from the same label remain conditional. All labels are mainly dependent on image embeddings to determine their coexistence within an image. Then by one-shot sampling the model generates labels for all objects in an image at same time.
- To decrease the inference time and improve efficiency by taking an LLM like LLaMA, retain only the first few transformer blocks and the final layer which are essential for recognition. This makes the LLM decoder to be more compact resulting in a 4.5x faster inference.

Highlights of Paper:
- Techniques like decoupling tokens of different labels to be independent with a Non-causal attention mask which avoids repetition issues are quite impressive. Additionally making use of the strong parallelization capability of the transformer with one-shot sampling to simultaneously process multi-labels choosing top-k tokens is an unique approach.
- From benchmarks it suggests that the model superseeds GPT-4V Preview, LLaVA, Flamingo, CLIP etc for recognition tasks on the COCO Validation split.
Inference Results

Observation and Takeaways
- The proposed model architecture can be an excellent choice for open vocabulary recognition, overcoming the limitations of CLIP. However this might be also an overhead to use LLM for object recognition in hardware resource limited machines.
Colab Notebook: [ Link ]
Starting with the Large Language Model can be an overwhelming yet demanding skill in the current job market. Have a look at our tri-part series on LLMs.
6. MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Arxiv: https://arxiv.org/abs/2406.01595
Problem statement: 3D Reconstruction from Monocular video
Category: Humans: Face, body, pose, gesture, movement
MultiPly is a novel framework by Zeren Jiang et.al from ETH Zurich and Microsoft to reconstruct multi-people in 3D from monocular RGB videos. Typically to estimate in-the-wild 3D reconstruction, the setup demands multi-view and specialized equipment. The task also has additional challenges like depth ambiguities, human-human occlusions and dynamic human movements.

MultiPly takes into account all these and recovers 3D Humans with high-fidelity shape, surface geometry and appearance by pixel level decomposition (accurate instance-level segmentation) and plausible multi-person pose estimation.
Method

- The process begins by taking each subject’s video frame and pose initializations as input and fusing them into single, temporally consistent human representations in a canonical space.
Note
The human points were sampled along a camera ray with Sparse Pixel Matching Loss (SPML) using NeRF++.
- Then, these canonical human models are parameterized by a learnable MLP Network calculating sine distance and radiance values.
- Following that, a layer-wise differential volume rendering for the entire scene (frame) is applied to extract human meshes.
- To enhance clean separation even in close interactions or occluded scenes, progressive input prompts to SAM are given to dynamically update the instance segmentation masks until the whole human body is covered.
- In addition, a confidence-guided optimization formulation is employed to avoid harmful shape update due to inaccurate poses resulting in spatially coherent 3D reconstruction.
Highlights of the Paper
- MultiPly eliminates the need for high-quality 3D data and outperforms contemporary SOTA approaches like ECON and Vid2Avatar in monocular videos with highly occluded scenes.
- Multiple Loss metrics including Reconstruction loss, Instance Mask Loss, Eikonal Loss, Depth Order Loss and Interpenetration loss are considered by the authors to generate highly accurate 3D humans with the MultiPly framework.
Observations and Takeaways
With the advent of Spatial Computing based devices like Apple Vision Pro, Meta Oculus Quest etc., Audio2Photoreal and MultiPly frameworks can have a huge impact for creating realistic avatars or virtual agents in AR/VR space.
Repository: [ Link ]
💡 DEMO
7. ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation
Arxiv: https://arxiv.org/abs/2312.16217
Problem Statement: Manipulate anything with MLLM
Category: Robotics
ManipLLM developed by Xiaoqi Li et.al from Peking University focuses on integrating MultiModal LLM or MLLM’s reasoning capabilities of robots for effectively handling objects with the hand gripper.
As we have seen, recent advancements in integrating VLM models for robotics perception and reasoning, like 3D-VLA as language models, can adapt dynamically to any unseen environment due to their generalization capability. Traditionally robots manipulate the end effector directions or gripper after extensive training and simulation. However even after training, the decisive model might fail to handle unseen objects or out of domain events.

ManipLLM addresses this problem very effectively by bringing a multi-modal LLM with backbones like LLaMA into the loop.
System Pipeline

During inference, the system takes in an RGB image captured by intel realsense projected to higher dimension of the LLMs embedding space and text prompts are fed into LLaMA from the user to predict the initial pose of the gripper with a chain of thought reasoning approach. The network then returns its understanding of the image based on instructions given with a set of coordinates to establish the contact at a precise location determined by the LLaMA model.
The chain of thought is to the point with three main objectives,
- To determine the category of the object.
- Think about how to complete the given task.
- To return end effectors pose (coordinates and rotation angle).

After making initial contact, an Active Impedance Adaptation Policy within the network plans to create waypoints to achieve the task gradually with an end effector in a closed loop.
Highlights of the Paper:
- In general, the LLM doesn’t have the capability to manipulate objects, so Vision and Language adaptors are injected into the network. These injectors are further fine-tuned to adapt this manipulation task yet still retain the reasoning capability of the MLLM model.
- From 2D Pixel coordinates and gripper rotation angle, returned by the MLLM, the network uses depth maps to project 2D coordinates into 3D space.
Observations and Takeaways
Many research institutes and robotics companies have adopted MLLM’s as the reasoning mind to enhance robots to interpret their perception and motion. Notable partnerships included integrating OpenAI GPT-4 into FigureAI robots and in Boston robotics. We believe as language and vision space fuse, there is a great scope for cross-domain knowledge transfer, enabling robots to adapt to new tasks with just a few shot samples.
Repository: [ Link ]
CVPR Talk [ Link ]
💡 DEMO

Having a career in robotics is a “Pursuit of Happiness.” For a foundational understanding, explore our Getting Started with Robotics Series.
8. MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation
Paper: [ Link ]
Problem Statement: Robust ECG Segmentation Model
Category: Medical and biological vision, cell microscopy
MemSAM by Deng et.al from Shenzhen University is a novel echocardiography segmentation model aimed to tackle challenges like speckle noise, artifacts, blurred contours and shape variations of heart structures over time in an ultrasound image.

Tip
Echocardiography segmentation aims to segment key structures of the heart in ultrasound videos.
Examining and manually assessing the echocardiography is a time-consuming task. Even expert medical practitioners sometimes find it hard to write a perfect evaluation report about the condition. Automating medical imaging with AI is a crucial and demanding need in clinical practice. But the main challenge is limited access to perfectly annotated segments and apparently, there exists a need to annotate segments in each frame of an echocardiographic video.
That’s where MemSAM shows its excellence in proposing temporally consistent image segmentations in fast-changing ECG videos. We know that SAM stands apart due to its excellent feature representation and zero-shot generalizability on natural images. While existing SAM derived medical segmentation models like MedSAM, SAMed, SAMUS show promising results but they aren’t yet explored for video segmentation tasks.

We can still use these variants by passing videos as frames for segmentation, but these methods heavily rely on a large number of prompts and annotations.

MemSAM just requires a point prompt for the first and last frames (annotated frames), while the in-between frames are tracked using Memory Prompt generated by the network. Finally the loss is calculated on just the annotated frames.
MemSAM Framework

- In the SAM block(in gray), at first the image is converted to image embeddings. Following that a positive Point Prompt is encoded to guide the model, together they pass to the mask decoder to generate a predicted probability segmentation map. Suppose if the image is not the first frame in the video, the image embedding is projected to the memory feature space for Memory Reading.
- The second block (represented in orange) queries and generates Memory Prompt from multiple feature memory (including Sensory Memory, Working Memory, and Long-term Memory).
- At last the predicted probability map from mask decoder is encoded and used to update the multiple feature memory after memory reinforcement.
Highlights of the Paper
- The addition of Memory Reading and Memory Reinforcement is a unique approach: In Memory reading, the image embedding is projected to a Query(q), which performs an Affinity query(W) to the Memory bank (Long-term and working memory) containing a key-value pair to get Memory Readout(F). The image embedding, sensory memory, and memory read are fused to generate a Memory embedding. Finally to avoid noise on memory updation, a memory reinforcement module is employed.
- MemSAM achieves state-of-the-art performance on EchoNet-Dynamic and CAMUS-Semi video datasets, outperforming five medical foundational models with semi-supervised (fewer annotations).
Observation and Takeaways
Medical Imaging with AI is expected to thrive, offering great value in the upcoming years. Institutes and companies like Google Deepmind, Microsoft, and OpenAI are actively looking to integrate AI-assisted evaluation reports to ease out the process, potentially saving many lives by early-stage detections. At the same time, always an expert clinician in the loop is necessary to monitor hallucinations and any adversarial effects.
Repository: [ Link ]
💡 DEMO
9. EventPS: Real-Time Photometric Stereo Using an Event Camera
Paper: [ Link ]
Problem Statement: Surface Normal Estimation with Stereo camera
Category: Physics-based vision and shape from X
EventPS by Bohan Yu et al. from Peking University is an exceptional technique to estimate the surface normal of an object, taking advantage of phenomenal characteristics of an event camera like temporal resolution, dynamic range and less latency.

What is an Event Camera?
In Layman’s terms, generally, frame cameras capture sequences of frames at regular intervals of time. However, event cameras only detect when there is a motion or change in the scene, kind of like a motion detector reducing the need to store additional information about objects that didn’t change over time. This makes event cameras an excellent choice for real-time applications. The event camera records only logarithmic scene radiance changes(i.e., data points(events) like change in brightness) that point out in a scene when and where a change has occurred.

When the change in the brightness of a pixel reaches a trigger threshold, an event will be triggered by the event camera hardware.
Are you wondering what a photometric stereo (PS) is?
Photometric stereo involves keeping the object and the camera as static while changing the source of light’s position around the object. By capturing multiple images of the object, we can estimate its surface normal.

Prior to this work, frame-based cameras were the only choice for PS. Conventional Photometric Stereo caters to any of these two lighting setups:

- The first setup would involve holding the light source in a robotic arm and capturing it by moving the light around the object densely with good accuracy. However, it’s time consuming and not real-time.
- The second choice is to use multiple flash lights located at fixed locations and turn them consecutively. It is real time but is inaccurate.
Understanding EventPS setup and Working
EventPS is mathematically modeled as,
![$I_x(t) = \max [0, a_x(n_x \cdot L(t))]$](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-7bb72e27cef9a16474a7a1a69d1cfb0d_l3.png)
where,
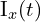 – Lambertain model ;
– Lambertain model ; 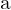 – albedo or unknown ;
– albedo or unknown ; 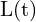 – Lightning direction (Calibrated) ;
– Lightning direction (Calibrated) ; 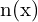 – surface normal
– surface normal

EventPS’s ingenuity lies in its setup. The setup addresses twoComparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods main questions,
How to illuminate an object for an event camera?
The setup involves an event camera fixed location that captures through a continuously rotating slit light setup(in green). The speed of light is 30 rotations per second, which is equivalent to the frame rate of a conventional camera powered by a DC Motor.
How do we estimate surface normal without absolute intensity?
The proposed idea is to convert each pair of consecutive events into a null space vector.
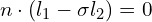 ; where
; where 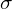 is the event trigger threshold.
is the event trigger threshold.

The null space vector is perpendicular to the object’s surface normal.
Interesting Fact
Null space vector caters to its use case in
- In data analysis, determining which direction data varies the least results in dimensionality reductions like PCA.
- Linear programming can be used to find feasible directions to improve objective function.
- In computer vision for 3D reconstruction and camera calibration.
💡 DEMO

Highlight of the Paper
- To solve noise in null space vectors of real events, multiple events are captured and converted to null space vectors and combined with a Singular Value Decomposition (SVD) algorithm.
- EventPS setup achieves very accurate surface normal estimation of both static and moving objects.
Observation and Takeaways
Neuromorphic based event camera based systems can hugely impact Robotics and autonomous vehicle systems which are prone to a lot of unpredictable events. The author suggests it has a lot of scope for future research in AR/VR based face rendering. The main application would be finding artifacts in an industry product using the surface normal.
10. Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods
Arxiv : https://arxiv.org/abs/2212.06872
Problem Statement: Understanding decision principles of Transformers and CNNs.
Category: Explainable Computer Vision
Award: Best Student Paper – Runner-up (Honorable Mention)
Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods by Mingqi Jiang et.al from Oregon State University won CVPR awards in the Explainable Computer Vision category. The paper discusses interesting methodologies used to understand how deep black-box models like Transformer and CNN recognize images.

We know that prior works from Zhuang Liu1 et.al, that is employing the strategies used in training Transformers models, CNN based models like ConvNext were able to achieve on par performance of Transformers models like ViT and Swin Transformers. So this poses further questions, such as whether the attention mechanism of Transformers is specifically responsible for its robustness. Or have only the design principles of ConvNext contributed to an increase in performance?Traditionally, attribution-based model explanations include gradient-based (Grad-CAM), Perturbation-based (RISE), and Optimization-based (iGOS++), etc. highlighting the attribution map of deep networks in an image for classification.

However, it is limited to only one explanation per image. So, in 2021, earlier work of Mingqi et al. proposed a search-based method called Structural Attention Graphs (SAG) that goes beyond just one explanation per image.

Search based algorithms produce Minimally Sufficient Explanations (MSEs) or minimal set of patches that are sufficient to make predictions with decision confidence like the same when a full image is shown. SAG uses beam search to find all combinations of images that generate high classification confidence so we get different explanations for each image.

Usually, explanation methods were used to explain just a single image. SAG explanation algorithms are tested on thousands of images from ImageNet to learn differences among network backbones (CNN and Transformers). The author proposes two different approaches as follows,
a) Sub-Explanation Counting:
An image is divided into non overlapping patches, followed by beam search to get MSE at more than 90% confidence level. Then sub explanation counting of an MSE is done by creating multiple child nodes or subsets with different classification confidence by deleting a patch (marked in red) of the parent MSE.
When the child node of an MSE has less than 50% likelihood ratio, the tree expansion is stopped.

b) Cross Testing
The second approach evaluates the similarity between the decision principle of CNN and Transformer models. This is done by generating an attribution map from Model A like VGG-19 (CNN-based) and making mask patches by insertion/deletion, then passing it to Swin-T (Transformer) to evaluate the two models. If both the models make decisions on the basis of the same features, then they score high in cross-testing.



From the results, the model’s behavior falls under two categories:
- Compositional Behavior: Models like ConvNext and non-distilled transformers make decisions based on multiple features in an image. If some parts are deleted, there is only a small change in the decision-making confidence.
- Disjunctive Behavior: On the contrary CNNs and distilled transformers make decisions based on a few parts in the image. So even if a large part in the image is missing, the model still makes accurate predictions.

The author also conducted ablation studies by decreasing the receptive field with a 3×3 kernel size in ConvNexT-T and 4×4 in Swin-T-4 and observed a 40% drop in the total number of sub explanations. To better understand why this significant drop, multiple iterations of experiments are conducted. The best result was obtained by replacing the layer normalization with batch normalization and training it with a small receptive field, and a drop in sub-explanation count was found by 88%.
It is found that less sub explanations drives the model to be more disjunctive in behavior. So the authors conclude that normalization layers can have a great impact on the model’s behavior. Layer Normalization/Group Normalization results in Compositional behavior while Batch Normalization makes the model to be of Disjunctive in behavior.
Highlights of the Paper
- Instead of just anecdotes or assumptions, the paper shows actual experimental results on the validation subset of the ImageNet dataset on the first 5k images.
- The paper answers our initial questions with models of the same type that use similar features for their predictions.
Observation and Takeaways:
The study conducted is unique in its kind that can bridge our gap in understanding how these deep black-box models make decisions on certain features or fundamentally design principles. More of this kind of research opens new possibilities for achieving optimal neural models for production and research that reduce carbon footprints.
Repository [ Link ]
11. LEAP-VO: Long-term Effective Any Point Tracking for Visual Odometry
Arxiv: https://arxiv.org/abs/2401.01887
Problem statement: Tracking dynamic scenes, occlusion, and low texture areas with point trackers.
Category: Video: Low-level Analysis, motion, and tracking
LEAP-VO by Weirong Chen et.al TU Munich is a new method for enhancing motion estimation and track uncertainty in dynamic environments. LeapVO makes use of temporal context with long-term point tracking.
Visual odometry(VO) estimates the motion of a moving camera based on visual cues. In simple terms, given a sequence of images, VO determines the location and orientation of the capturing camera.
Feature Visual Odometry
Classical approaches like Feature based Visual Monocular SLAM extracts the feature points in the first image and tracks them throughout the video. The camera pose can be recovered by optimizing the reprojection error. i.e. Bundle Adjustment.

Note
A reprojection error is the distance between a key point detected in an image and its corresponding 3D world point projected in the same image.
However, Feature-based VO is unreliable in the following case:
- when the scene is dynamic
- when there is an occlusion
- for a low-texture area.
Prior works use a two-view or pair-wise tracker to track subsequent frames that don’t handle occlusion properly. Taking all these into account, LeapVO follows an effective learning-based approach with rich temporal context and continuous motion patterns to tackle all these challenges in multi-viewpoint tracking, even under partial occlusion.
Methodology
Point Tracking Front-end(LEAP) handles
- Occlusion handling with Multi-frame tracking
- Dynamic detection with Anchor-based motion estimation
- Reliable estimation with Temporal probabilistic formulation
In this pipeline, the feature map is extracted from images captured over time. Then, query points are sampled from an image, and additional anchor points based on image gradients are tracked over time. These points are refined iteratively to improve tracking using a refinement network. The network attributes the following.
- Channel: Uses channel information between feature maps
- Inter-track: uses the relationship between points being tracked
- Temporal: Utilizes temporal information of the image sequence.
The refinement network outputs point distribution and motion over time, which tells about visibility and dynamic motion in the video.

In a video, feature keypoints are extracted from a sequence of RGB images, which are fed into the LEAP front end for tracking. Then trajectories are created for these key points which the LEAP module tracks over frames within the LEAP window. Not all keypoints tracked are useful. Some might be invisible or unreliable so it’s better to remove them as they will induce noise when averaged.
Finally, the local Bundle Adjustment (BA) module is applied across frames in the current BA Window to update the camera pose and 3D positions, effectively minimizing reprojection error.

The green points represent the static scene in an image, the yellow points are ambiguous or unreliable, and the red points are for dynamic scenes.
💡 DEMO
Highlights of the Paper
- LEAP-VO outperforms state of the art methods including VO and SLAM based across different datasets for both static and dynamic scenes with its effective Long Term Point Tracking.
Observation and Takeaways
Leap-VO can cater its application extensively to autonomous vehicle navigation, robot path planning, and tracking movements in AR/VR.
Repository: [ Link ]
Key Datasets

| Datasets | Project |
| 1. 4D-DRESS: A 4D Dataset of Real-world Human Clothing with Semantic Annotations | Link |
| 2. VideoCon: Robust Video-Language Alignment via Contrast Captions | Link |
| 3. MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark | Link |
| 4. SceneFun3D: Fine-Grained Functionality and Affordance Understanding in 3D Scenes | Link |
| 5. DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision | Link |
| 6. Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild | Link |
| 7. EgoGen: An Egocentric Synthetic Data Generator | Link |
| 8. MM-AU: Multi-modal accident video understanding | Link |
| 9. DiVa-360: The Dynamic Visual Dataset for Immersive Neural Fields | Link |
| 10. MCD: Diverse Large-Scale Multi-Campus Dataset for Robot Perception | Link |
| 11. MARS: MultiAgent, multitRaverSal, multimodal autonomous vehicle dataset | Link |

Special Mention🔥
- Longuet-Higgins Prize recognizes CVPR Papers from ten years ago that have made a significant impact in the field of computer vision research. This year it was awarded to the famous object detection and semantic segmentation R-CNN paper from 2014. Check our post on how Region Proposals in R-CNN works.
- Rich Human Feedback for Text-to-Image Generation from Google got the Best Paper Award of CVPR 2024.
- Mip-Splatting: Alias-free 3D Gaussian Splatting by Zehao Yu et al. got the Best Student Paper Award.
Key Takeaways of CVPR 2024 Research Papers
- Conferences like CVPR, NeurIPS, IROS never fail to surprise us by bringing innovative research into the limelight in the Deep Learning and Robotics domain.
- Any single research paper can be game-changing and define the pace of technology for the next 10 to 20 years, like “Attention is All You Need.” In addition to these groundbreaking papers, there were notable workshops on autonomous vehicles by Wayve.ai, GenAI Sora by OpenAI, and others.
Conclusion
We hope you found it intriguing and insightful to read the essential gist of the latest research trends in AI with demos. In a two-part series, we gave a comprehensive overview of CVPR 2024, covering major categories to the best of our knowledge. Which of the CVPR 2024 research papers do you think was a showstopper and had an absolute visual treat? We would love to hear from you in the comments.
Looking ahead, we will try to provide an in-depth review of the latest research and conferences in the fields of AI and Computer Vision.
Stay tuned by subscribing to get notifications.🔔






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning