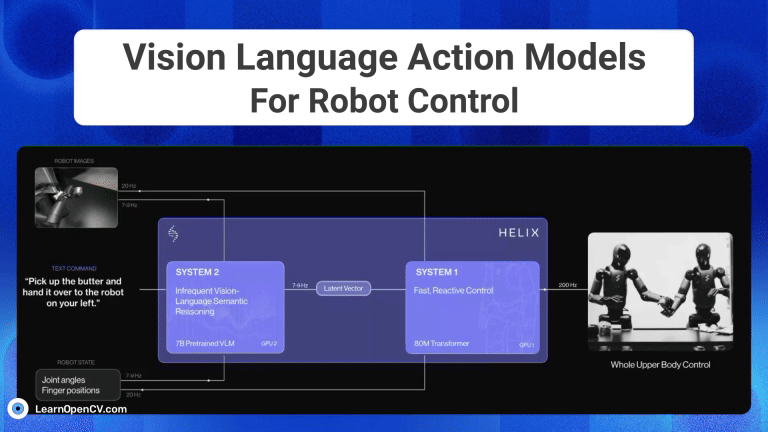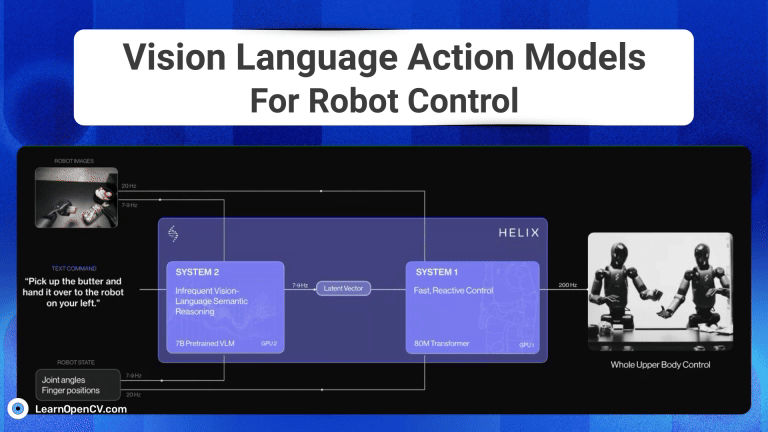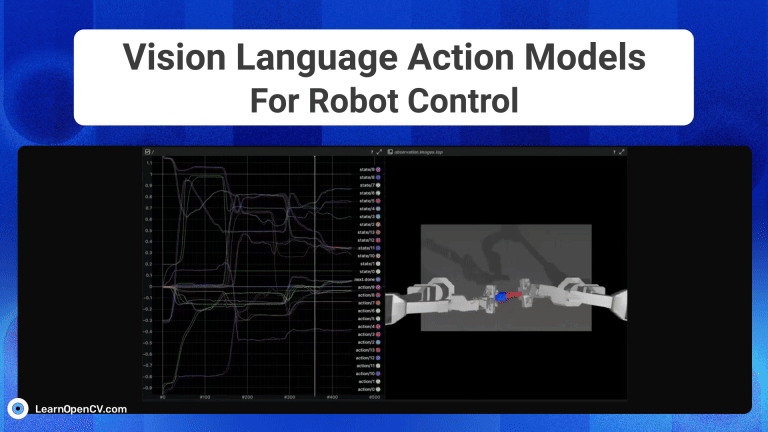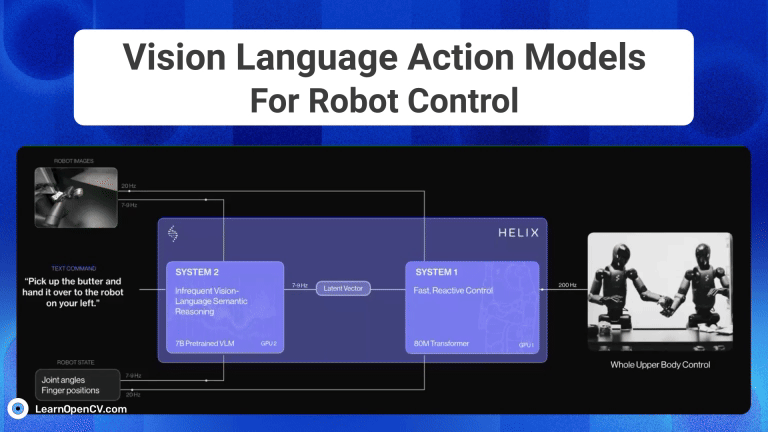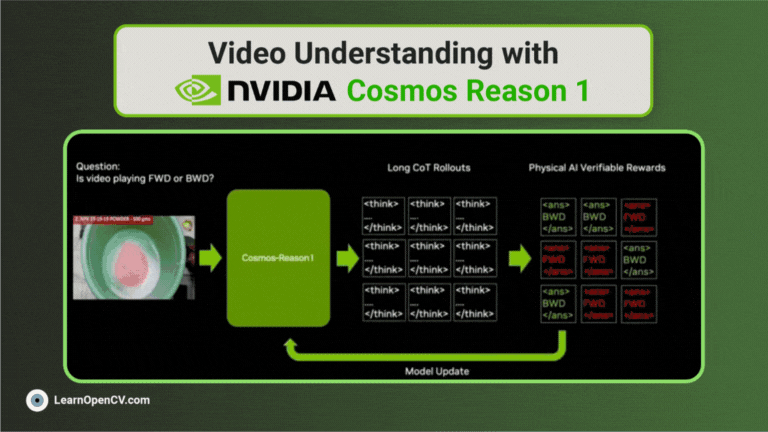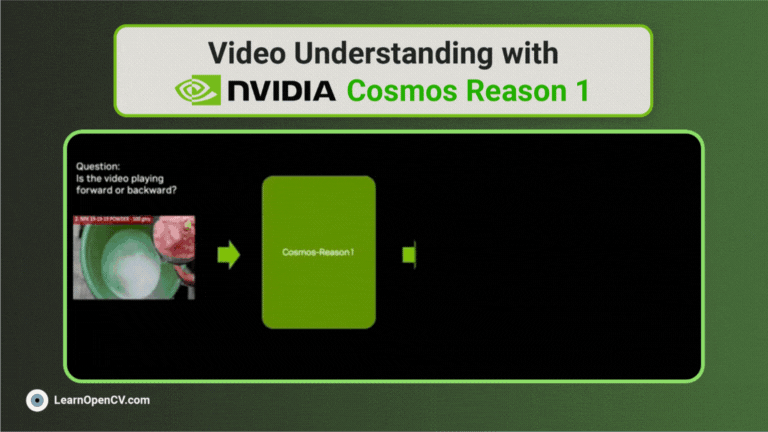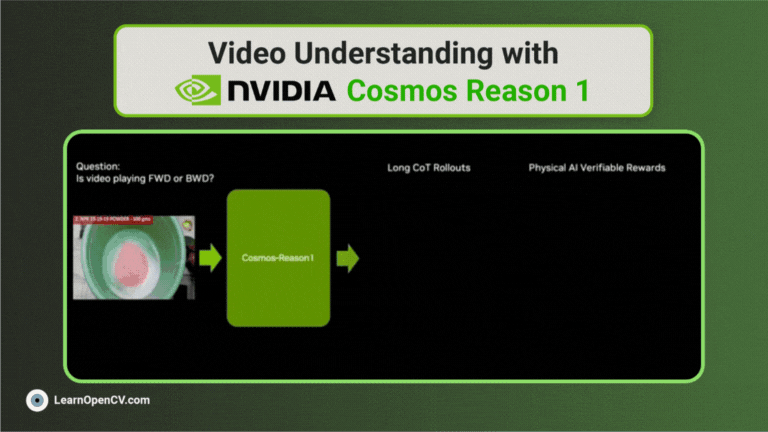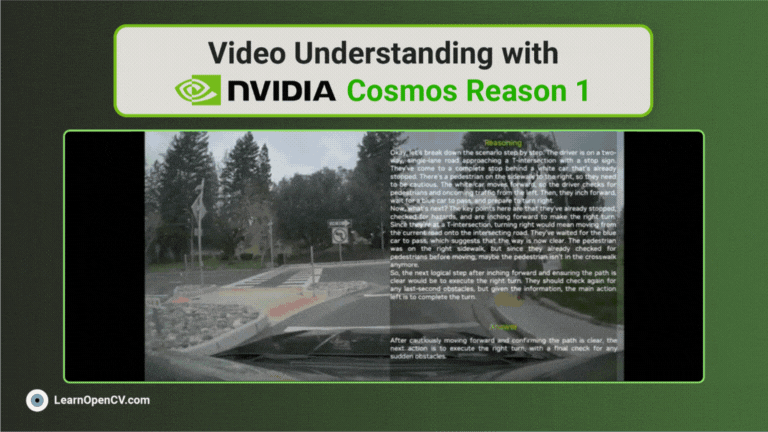
NVIDIA's Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender ...
VLM for Video Understanding with Spatial and Temporal Context: NVIDIA Cosmos Reason1
June 17, 2025 1 Comment