




Diffusion models, including Glide, Dalle-2, Imagen, and Stable Diffusion, have spearheaded recent advances in AI-based image generation, taking the world of “AI Art generation” by storm. Generating high-quality images from text descriptions is a challenging task. It requires a deep understanding of the underlying meaning of the text and the ability to generate an image consistent with that meaning. In recent years, Diffusion models have emerged as a powerful tool for addressing this problem.
These models make it incredibly easy to generate high-quality images in various styles using just a few words. For example, we generated the below image by simply providing the prompt:
“the house in the forest, dark night, leaves in the air, fluorescent mushrooms, clear focus, very coherent, very detailed, contrast, vibrant, digital painting”


Currently, because of the sheer amount of different diffusion models available, traversing this space from an end user’s perspective can be difficult and, at times, overwhelming.
In this article, we’ll cover the following topics in a friendly and easy way that is digestible for anyone new to the exciting world of diffusion models for image generation.
- Briefly discuss deep-learning-based image generative models space and the ups and downs of the different techniques involved.
- Explain in simple terms what “Diffusion” is and how diffusion models work.
- Provide a high-level view of the four most popular diffusion models:
- OpenAI’s Dall-E 2
- Google’s Imagen
- StabilityAI’s Stable Diffusion
- Midjourney
- Finally, we will discuss some apps and websites that provide services related to diffusion models or use diffusion models as a service.
The best part is that we’ll also provide you with a Jupyter notebook that you can use to run Stable Diffusion image generation prompts with as low as 6 GB VRAM or even run Stable Diffusion on the CPU.
- What Are Generative Models?
- What Is Diffusion?
- What Are Diffusion Models?
- Well-Known Diffusion Models for Image Generation
- Popular Variations Of Stable Diffusion Models
- Applications Of Diffusion Models
- Tools
- Summary
What Are Generative Models?
Most of the Machine Learning and Deep Learning problems you solve are conceptualized from the Generative and Discriminative Models. Simply put, “Generative Models” are statistical models designed for “generating/synthesizing data.” Their job is to “convert noise to a representative data sample.”
Throughout the years, we have seen many creative applications of generative models. One particular application that most of us will recollect was Cadbury’s Ad which used Audio Generation and Lip Syncing to map the facial expression and speech of various celebrities. It can be used to create a personalized celebrity advertisement.
The four well-known deep learning-based image generative models are:
- Variational Autoencoders (VAE)
- Flow-based models
- Generative Adversarial Networks.
- Diffusion (a recent trend)
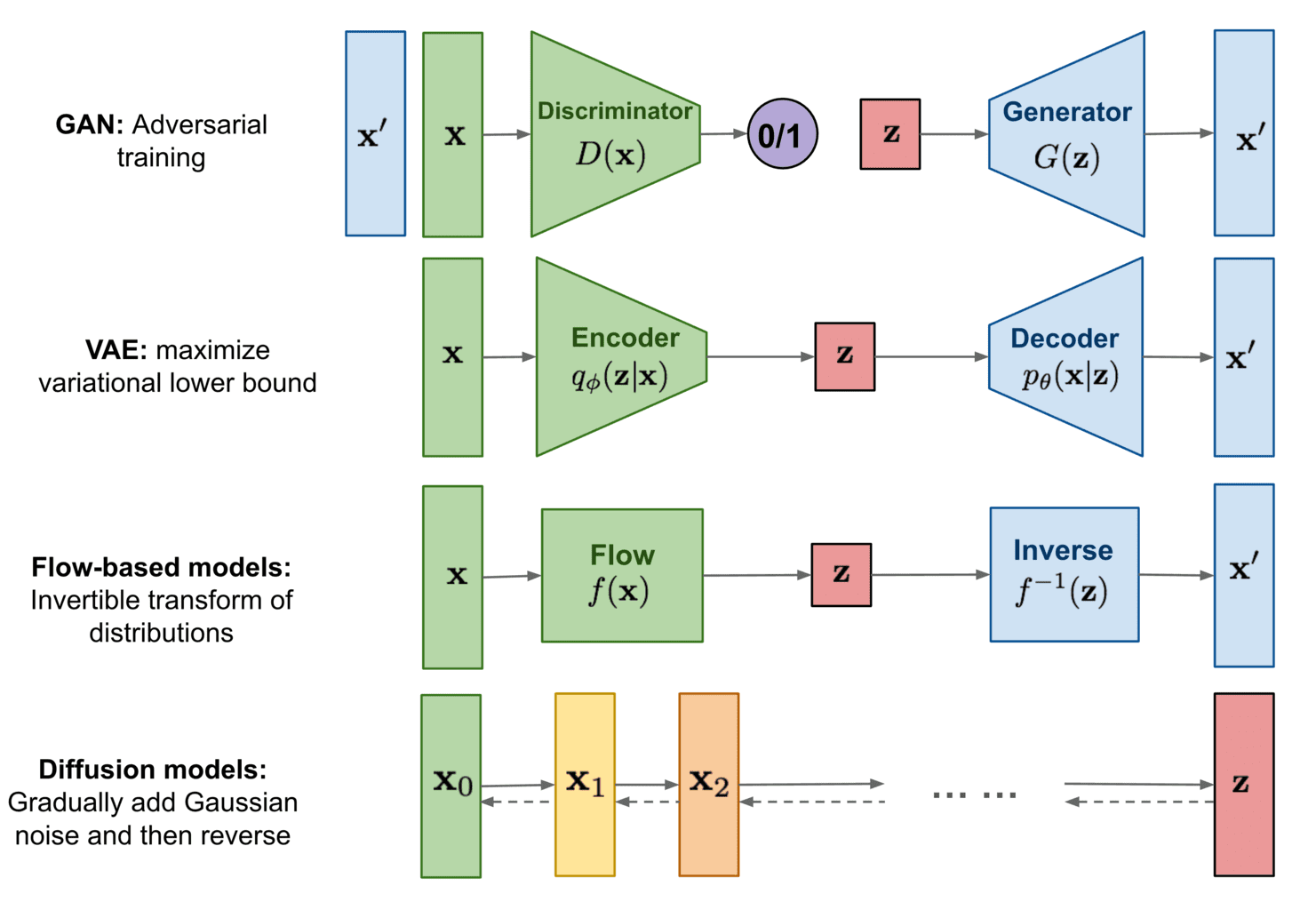
Source: https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
These models are first trained so that they learn to model the “data distribution” (of the training data). Once trained, the model knows how to approximate the original data distribution and can use it to generate new data (images) at will.
The precursor to understanding “Variational Autoencoders” are “Autoencoders.” The primary objective of Autoencoders is data compression. The architecture of Autoencoders is fairly straightforward. It contains three components:
- An Encoder
- A Bottleneck (responsible for compression)
- A Decoder
An added benefit of this design is that we can use Autoencoders for image denoising.
In Autoencoders, the distribution of the compressed data/latents is “unconstrained.” The data is compressed such that there’s minimal reconstruction error. This leads to a major drawback i.e. because we have no idea/information about the distribution of the latent, so generating new samples (using just the decoder) is difficult.
In Variational Autoencoders, this is no longer an issue. A constraint is added to the bottleneck layer, so the encoder’s compressed data needs to mimic a (simple handpicked) probability distribution (generally a standard gaussian) as closely as possible. To generate new samples, we can simply sample a point from the chosen probability distribution and pass it to the decoder.
At the time of writing, we still haven’t settled on one go-to model for all tasks related to generative modeling, and that’s fair. Every application domain has its own challenges, and people generally use various techniques to solve them. All four above-listed models have problems, which are illustrated aptly in the gif below.

Source: https://nvlabs.github.io/denoising-diffusion-gan/
To summarize:
| VAE | Flow | GAN | Diffusion | |
| Pros | Fast Sampling rate. Diverse sample generation | Fast Sampling rate. Diverse sample generation | Fast Sampling rate. High sample generation quality. | High sample generation quality. Diverse sample generation |
| Cons | Low sample generation quality | Need specialized architecture, low sample generation quality | Unstable training, low sample generation diversity (Mode Collapse) | Low sampling rate |
Created in ‘14 by Ian Goodfellow, Generative Adversarial Networks (GANs) were pretty much the norm for generating image samples.
Many variations from the original GAN were created, such as:
- Conditional GAN (cGAN): Controlling the class/category of the generated images.
- Deep Convolutional GAN (DCGAN): architecture significantly improves the quality of GANs using convolutional layers.
- Image-to-Image translation with Pix2Pix: Converting images from one domain to another by learning a mapping between the input and output.
Now in the era of diffusion models, researchers are sure to use the years of knowledge gained from working on GANs. This is one of the main reasons for such rapid progress in diffusion models in such a short amount of time.
What Is Diffusion?
Before we understand Diffusion models, let’s quickly understand the meaning of the term “Diffusion.” Diffusion (or Diffusion process) is a well-known and explored domain in non-equilibrium statistical physics.
In non-equilibrium statistical physics, the diffusion process refers to:
“The movement of particles or molecules from an area of high concentration to an area of low concentration, driven by a gradient in concentration.”

The diffusion process is driven by the random motion of the particles or molecules, described by the laws of thermodynamics and statistical mechanics.



What Are Diffusion Models?
In simple terms – “Diffusion Models are a class of probabilistic generative models that turn noise to a representative data sample.”
Using Diffusion models, we can generate images either conditionally or unconditionally.
- Unconditional image generation simply means that the model converts noise into any “random representative data sample.” The generation process is not controlled or guided, and the model can generate an image of any nature.
- Conditional image generation is where the model is provided additional information via text (text2img) or class labels (like in CGANs). This is a case of guided or controlled image generation. By providing by passing additional information, we expect the model to generate specific sets of images. For eg, you can refer to the two images at the start of the post.
In this section, we’ll focus on the process of “unconditional image generation.”
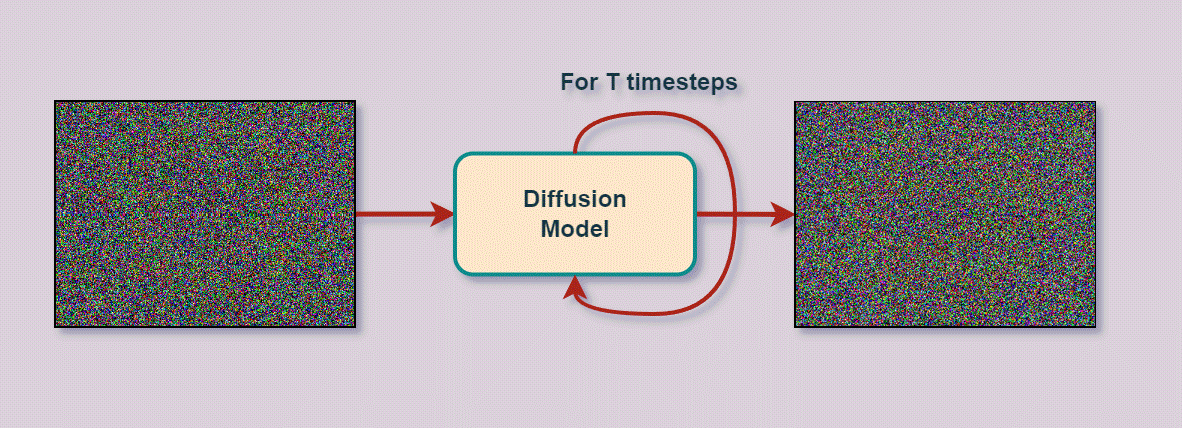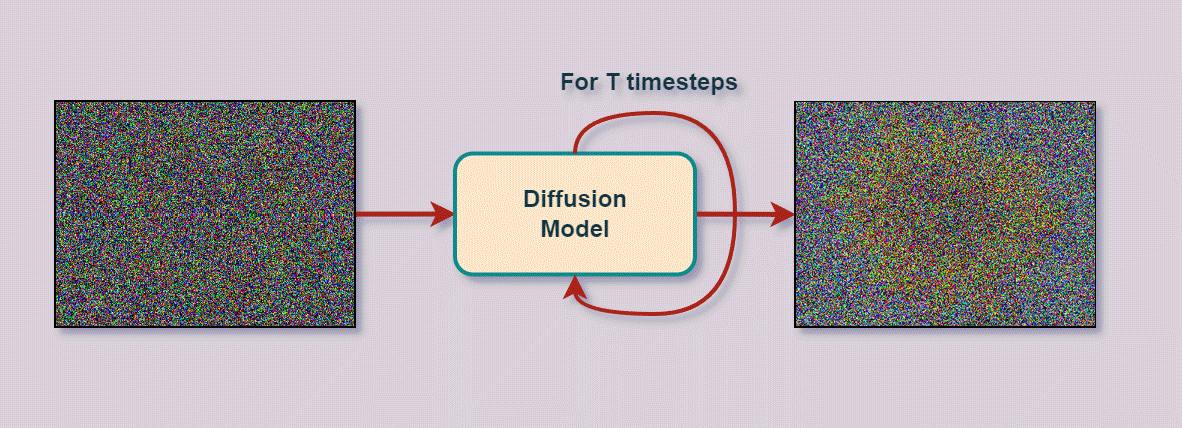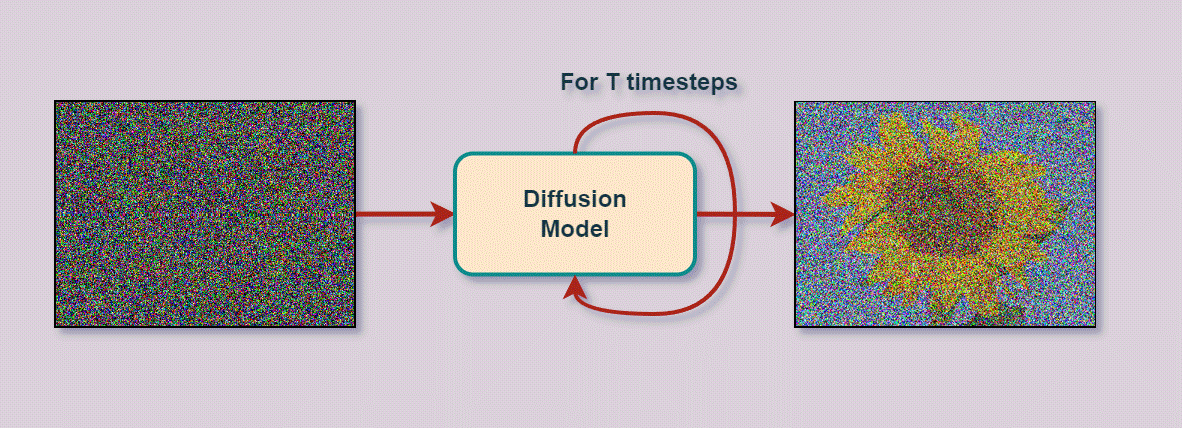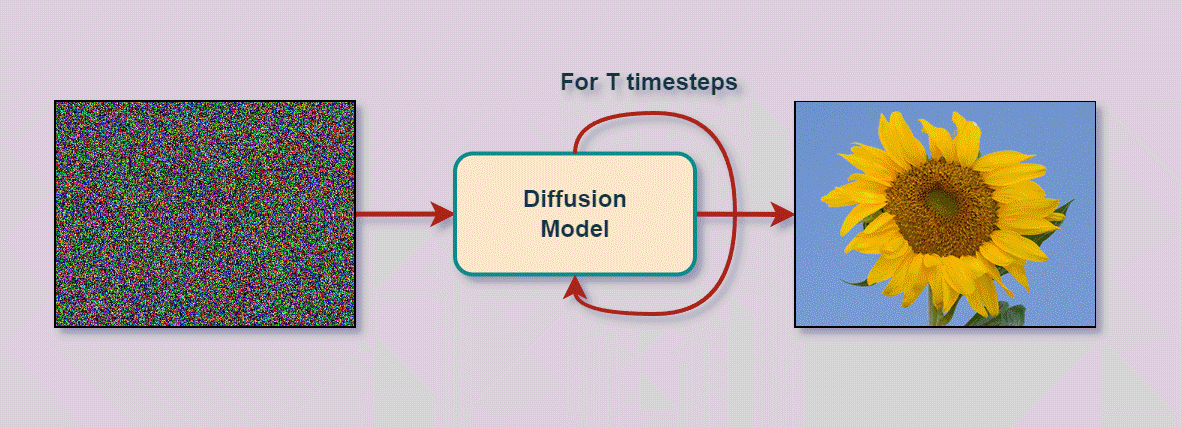
A bit of history…
Diffusion models in deep learning were first introduced by Sohl-Dickstein et al. in the seminal 2015 paper “Deep Unsupervised Learning using Nonequilibrium Thermodynamics.” Unfortunately, it remained behind the curtains for a while.
But, in 2019, Song et al. published a paper, “Generative Modeling by Estimating Gradients of the Data Distribution,” using the same principle but a different approach. In 2020, Ho et al. published the paper, now-popular “Denoising Diffusion Probabilistic Models” (DDPM for short).
After 2020, research in diffusion models took off 🚀. Much progress has been made in creating, training, and improving diffusion-based generative modeling in a relatively short time.
How Do Diffusion-Based Image Generation Models Work?
The general principle behind the workings of diffusion models is really simple to understand.
The diffusion method can be summarized as follows:
…systematically and slowly destroy the structure in a data distribution through an iterative forward diffusion process. We then learn a reverse diffusion process that restores structure in data, yielding a highly flexible and tractable generative model of the data. This approach allows us to rapidly learn, sample from, and evaluate probabilities in deep generative models …
– Deep Unsupervised Learning using Nonequilibrium Thermodynamics, 2015
Let’s take a step back and look at the gas diffusion gif above. When the jar is opened, the green gas molecules quickly move out of the jar and into the surrounding. This is essentially diffusion. As time passes, the concentration of green gas molecules inside and outside the jar will even out. The distribution of gas molecules has changed entirely from before the jar was opened. To reverse this process is no easy task; this is where non-equilibrium statistical physics comes into the picture.
An idea used in non-equilibrium statistical physics is that we can gradually convert one distribution into another. In 2015, Sohl-Dicktein et al., inspired by this, created “Diffusion Probabilistic models” or “Diffusion models” in short, building on this essential idea.
They build – “A generative Markov chain which converts a simple known distribution (e.g., a Gaussian) into a target (data) distribution using a diffusion process.”
A Markov chain simply means that the state of an entity/object at any point in the chain depends solely on the previous entity/object.
Now, we can do this both ways, i.e., we can also convert our training data’s (unknown) distribution into another distribution. And to put the cherry on top, both (data to noise and noise to data) can be modeled using the same functional form. This is exactly what’s done in diffusion models.
The authors describe that –
“Our goal is to define a forward (or inference) diffusion process which converts any complex data distribution into a simple, tractable, distribution, and then learn a finite-time reversal of this diffusion process which defines our generative model distribution.”
– Deep Unsupervised Learning using Nonequilibrium Thermodynamics, 2015
The structure (distribution) of the original image is gradually destroyed by adding noise and then using a neural network model to reconstruct the image, i.e., remove the noise at each step. Doing so enough times and with good data, the model eventually learns to estimate the underlying (original) data distribution. Then, we can simply start with just noise and use the trained neural network to generate a new image representative of the original training dataset.
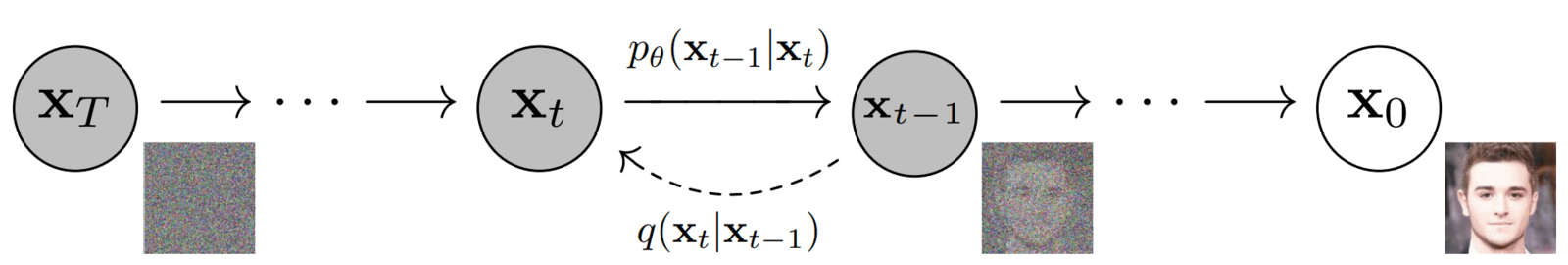
What we just described are the two essential processes/stages performed by every diffusion model. Without going into the mathematical details, let’s go over them a bit more and use the above image as a reference.
- Forward Diffusion:
- The original image (x0) is slowly corrupted iteratively (a Markov chain) by adding (scaled Gaussian) noise.
- This process is done for some T time steps, i.e., xT.
- Image at timestep t is created by: xt-1 + εt-1 (noise) → xt
- No model is involved at this stage.
- At the end of the forward diffusion stage xT, due to the iterative addition of noise, we are left with a (pure) noisy image representing an “Isotropic Gaussian.” This is just a mathematical way of saying that we have a standard normal distribution and the variance of the distribution is the same along all dimensions. We have converted the data distribution to a Gaussian distribution.
- Backward/Reverse diffusion:
- In this stage, we undo the forward process. The task is to remove the noise added in the forward process, again in an iterative fashion (a Markov chain). This is done using a neural network model.
- The model is tasked with the following: Given a timestep t and the noisy image xt , predict the noise (έ) added to the image at step t-1.
- xt → Model → έ (predicted noise). The model predicts (approximates) the noise added to xt-1 in the forward pass.
Comparison with GANs:
- Due to the iterative nature of the diffusion process, the training and generation process is generally more stable than GANs.
- In GANs, the generator model has to go from pure noise to image in a single step xT → x0, which is one of the sources for unstable training.
- Unlike GANs, where training requires two models, in diffusions, there’s just one model required.
- One observation from the above image is that the “dimension of the image stays the same” throughout the process, unlike GANs, where the latent tensor can be of different sizes. This can be an issue when generating high-quality images due to limited GPU memory. However, the authors of “Stable Diffusion” (“latent diffusion,” to be more precise) circumvent this issue by using a variational autoencoder.
Some points to note about the Diffusion process:
- Another benefit of its iterative nature is that we perform supervised training at each timestep.
- In diffusions, the popular architecture of choice is the UNet (with attention) which is trained using the MSE loss function in a supervised fashion.
- At each timestep, the noise added to an image is controlled using a “variance scheduler” or simply “scheduler”. It’s the schedulers’ job to determine how much noise should be added such that during the forward process, the image at the end xT is an isotropic gaussian.
- In the DDPM paper, the authors used a “linear scheduler.” This means that the noise added at each timestep was increased linearly.
- The number of timesteps T was set to T=1000. So, given gaussian noise, the model would require 1000 iterations to generate the result. This is the low sampling rate issue mentioned in the previous section. But in recent papers, by introducing new techniques and different schedulers, researchers could generate artistic images in as low as T=4 timesteps.
Well-Known Diffusion Models for Image Generation


Let’s review some of the Diffusion-based Image Generation models that became famous over the past few months. As the field is now occupied by hundreds of diffusion models and their variations, we will do a bit of sampling of our own and cover the more famous ones. These include:
- Dall-E 2 by OpenAI
- Imagen by Google
- Stable Diffusion by StabilityAI
- Midjourney
Here, we will not go into the depths of the above architectures. Instead, we will cover the overview of each model and create a dedicated post in the future. We will also check out a few prompts and the images generated by Dall-E 2 and Stable Diffusion.
DALL-E 2
Dall-E 2 was published by OpenAI in April 2022. It is based on OpenAI’s previous ground-breaking works on GLIDE, CLIP, and Dall-E. Although Dall-E 2 is the superior successor to Dall-E, the former contains 3.5 billion parameters compared to 12 billion parameters in Dall-E.
Without going into too many architectural details, Dall-E 2 is a combination of three different models:
- CLIP
- A prior neural network
- A decoder neural network
For now, it is enough to know that the decoder network generates images during inference. One can access Dall-E 2’s web UI by submitting a request on the official OpenAI website.
Here are a few prompts and their respective images generated by Dall-E 2.


Imagen
Following Dall-E 2, just after a month in April 2022, Google released its diffusion-based image generation algorithm. They aptly named it Imagen (for image generation).
It is built on top of large transformer-based language models. For their publication, the authors of Imagen chose the T5-XXL transformer language model. Following it, Imagen consists of three more image generation diffusion models:
- A diffusion model to generate a 64×64 resolution image.
- Followed by a super-resolution diffusion model to upsample the image to 256×256 resolution.
- And one final super-resolution model, which upsamples the image to 1024×1024 resolution.
Currently, Google’s Imagen is unavailable to the general public and is accessible through invitation only.



Stable Diffusion
Created by StabilityAI, Stable Diffusion builds upon the work of High-Resolution Image Synthesis with Latent Diffusion Models by Rombach et al. It is the only diffusion-based image generation model in this list that is entirely open-source.
As of writing this, Stable Diffusion v2.1 is available on StabilityAI’s official repository.
Not only that, the open-source community has been very active since its release. In a short span of time, the community has released several open-sourced Stable diffusion models fine-tuned on different artistic stylized datasets. One can freely use these models and generate new images using these styles.
These can range anything from Japanese anime and futuristic robots to cyberpunk worlds. Just to intrigue your imagination, here are a few examples from Stable Diffusion models.

The complete architecture of Stable Diffusion consists of three models:
- A text-encoder that accepts the text prompt.
- Convert text prompts to computer-readable vectors.
- A U-Net
- This is the diffusion model responsible for generating images.
- A Variational autoencoder consisting of an encoder and a decoder model.
- The encoder is used to reduce the image dimensions. The UNet diffusion model works on this smaller dimension.
- The decoder is then responsible for enhancing/reconstructing the image generated by the diffusion model back to its original size.
One can easily access the Stable Diffusion models using their DreamStudio platform. Creating an account will initially provide you with 200 credits, which you can use to play around with prompts and generate images of choice.
Alternatively, if you have the compute resource, you can also set up Stable Diffusion to run on your system by following the documentation on their repository.
Midjourney
Midjourney is another diffusion-based image generation model developed by the company with the same name. Midjourney became available to the masses in March 2020. It quickly gained a large following thanks to its expressive style and the fact that it became publicly available before DALLE and Stable Diffusion.
As of now, it is a completely closed source and does not have a related paper. However, one can access the image generation capabilities of Midjourney using their official Discord bot. Recently, the company announced the alpha testing phase of the v4 model.

Popular Variations Of Stable Diffusion Model
The open-source nature of Stable Diffusion makes it possible for developers worldwide to train on a particular style and create variations of Stable Diffusion. We can find ample examples online, including Stable Diffusion models that generate Disney characters, anime characters, and even the styles of other diffusion models.
Almost all the models and examples we will follow here are accessible through the HuggingFace hub. So, if you want to try them out, don’t hesitate to run the code yourself.
Here are a few examples:
Anything V3
Anything V3 is a variation of Stable Diffusion that generates images in the style of anime characters.

Robo Diffusion
A model that generates Robots from the subject and characters we enter in our prompt.

Open Journey
An open-source community-created replication of MidJourney that generates images in style similar to what Midjourney generates. Open Journey is a variation of Stable Diffusion that has been trained on the images generated by Midjourney.

Arcane Diffusion
Arcan Diffusion is a Stable Diffusion model which has been fine-tuned on image styles from the TV show Arcane.

Mo-Di Fusion
This version of Stable Diffusion generated characters with Pixar-like style.

Applications Of Diffusion Models
In the above sections, we’ve covered a few well-known diffusion models, and among them, Stable Diffusion and its variants are the only ones freely accessible. As a result of the codebase being open-source, the community of developers and researchers have come up with clever ways to use Stable Diffusion. In this section, we’ll look at some notable applications and uses of diffusion models.
The easiest way to use Stable Diffusion text-to-image image generation models is via Stable Diffusion 2-1 – a Hugging Face Space by stabilityai. Just add the textual description and click “Generate Image.”
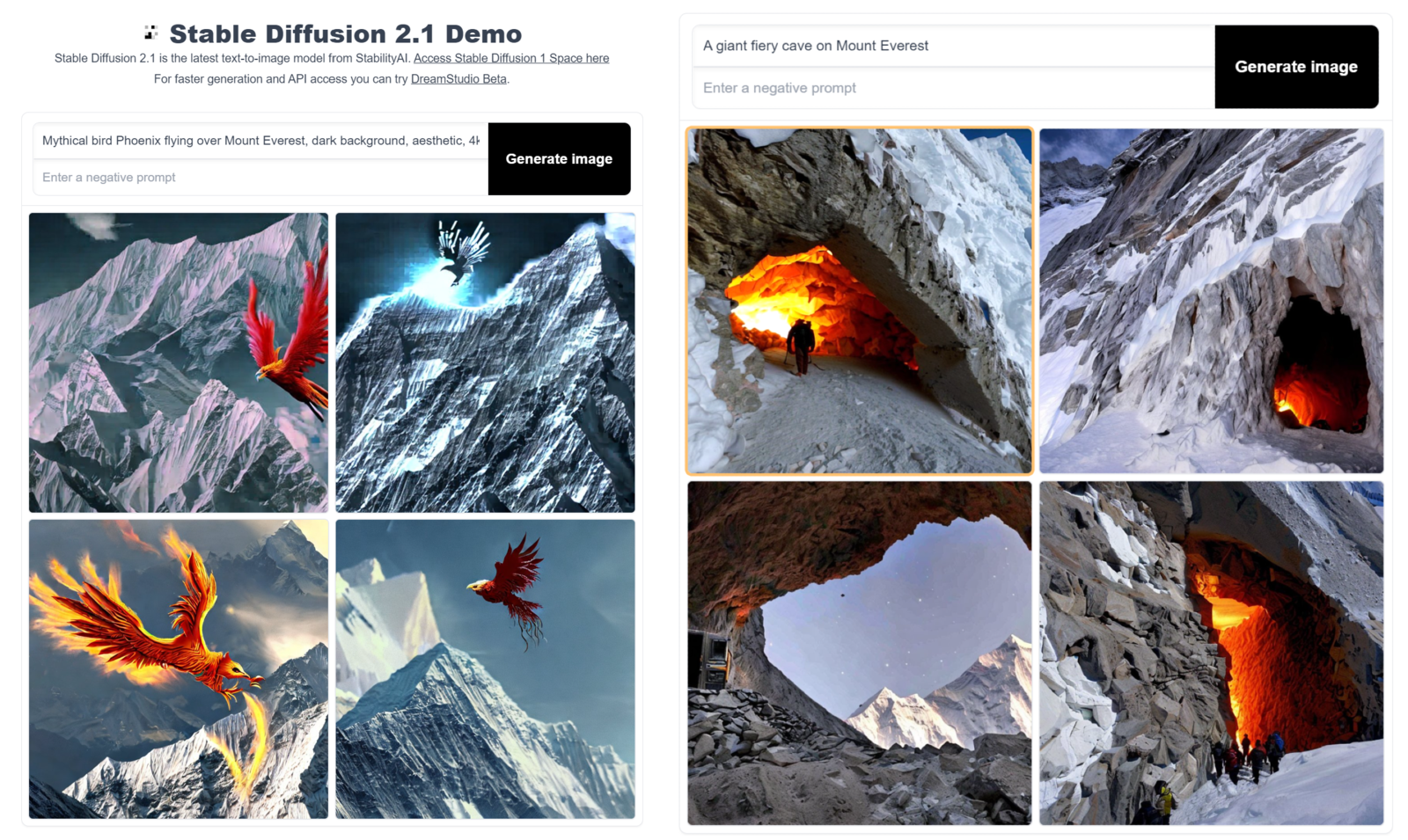
The drawbacks of using the freely hosted service are that it can have a big queue, so you may have to wait for your image to be generated, and there are no customization options or controls available.
To resolve this, we can download and run Stable Diffusion models locally. There are two approaches one can take:
- Install a community-build ready-to-go application that we can install locally or use on Google Colab.
- Directly work the open-source code and use it as we want. For this, we are providing our readers with a jupyter notebook.
The only downside of this approach is that we need a local GPU. On CPUs, the process will be much slower. We have listed the spaces and tools we used for the post in the “Tools” section at the bottom.
So let’s get started.
Textual Inversion
Using textual inversion, we can finetune a diffusion model to generate images using personal objects or artistic styles using as few as 10 images. This is not an application per se but a clever trick to train diffusion models that one can use to generate more personalized images.
From the authors of the textual inversion paper:
“We learn to generate specific concepts, like personal objects or artistic styles, by describing them using new “words” in the embedding space of pre-trained text-to-image models. These can be used in new sentences, just like any other word.”
– An Image is worth one word, 2022

✨With textual inversion, we generated a few using images of Satya using the Lensa iOS app.

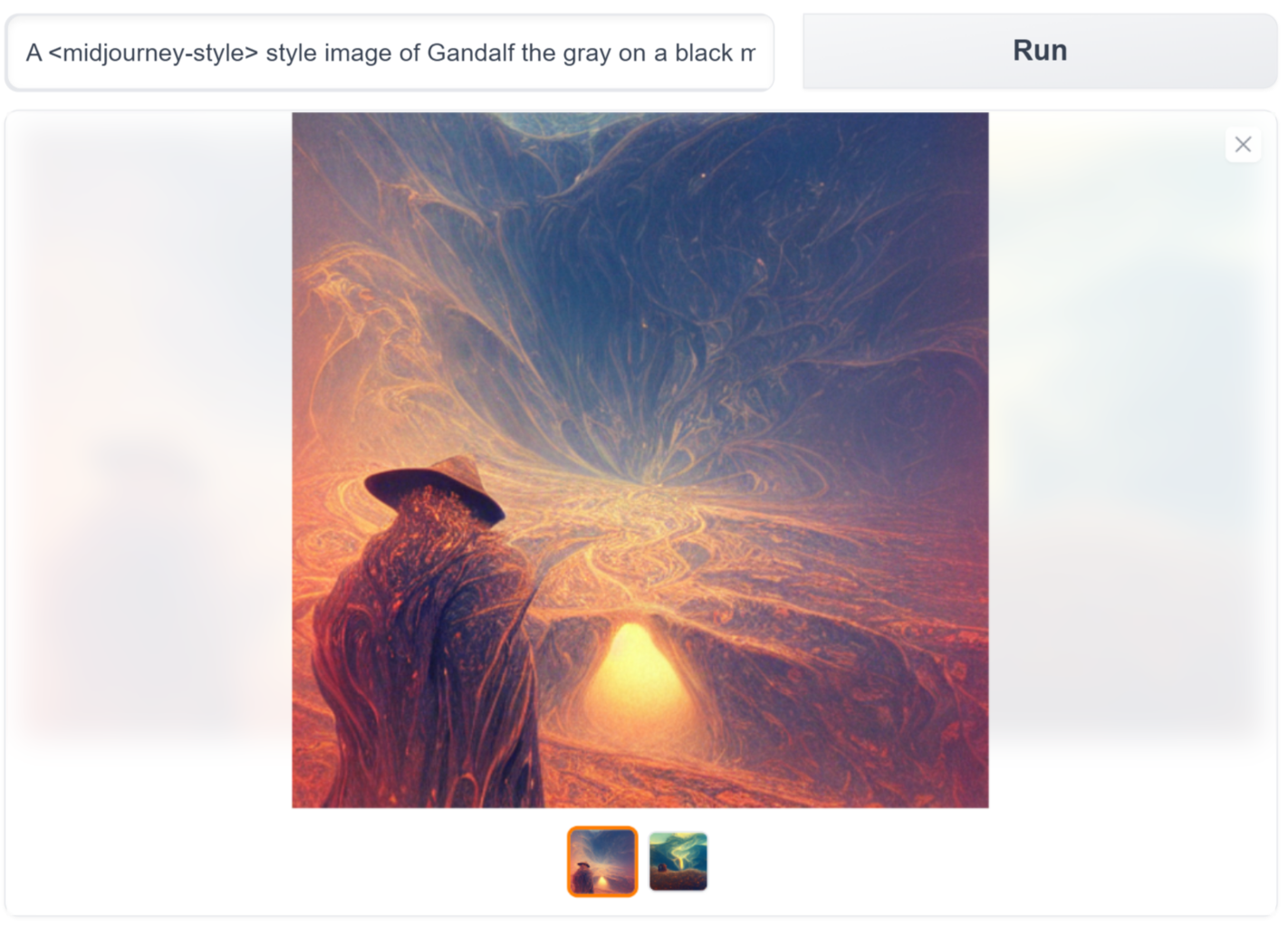
If you aren’t looking for anything too personal and want to generate images using some known styles, you can try out the Stable Diffusion Conceptualizer space. Here you’ll find a collection of diffusion models trained on different artistic styles. You can choose anyone to your liking and start generating without any hassle. You can choose any to your liking and start generating without hassle.
For example, we generated the below image using the “midjourney style” of Gandalf the Gray on a black mountain.
Text To Videos
As the name suggests, we can use diffusion models to directly generate videos with the help of text prompts. Extending the concept used in text-to-image to videos, one can use diffusion models to generate videos from stories, songs, poems, etc.
Source: Example from “Stable Diffusion Videos” on Replicate – Generate videos by interpolating the latent space of Stable Diffusion
There are other (maybe better) text-to-video diffusion models, such as Google’s Imagen Video and Phenaki and Meta’s Make-A-Video. But unfortunately, the code is currently available to the public.
Text To 3D
This application was showcased in the “Dreamfusion” paper, where the authors, with the help of “NeRFs,” could use a trained 2D text-to-image diffusion model to perform text-to-3D synthesis.
“The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. Our approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors.”
– DreamFusion: Text-to-3D using 2D Diffusion, 2022

Text To Motion
This is another upcoming and exciting application where diffusion models (along with other techniques) are used to generate simple human motion. Specifically, we are referring to the “Human Motion Diffusion model.”
“Natural and expressive human motion generation is the holy grail of computer animation. It is a challenging task, due to the diversity of possible motion, human perceptual sensitivity to it, and the difficulty of accurately describing it…. We show that our model is trained with lightweight resources and yet achieves state-of-the-art results on leading benchmarks for text-to-motion and action-to-motion.“
– MDM: Human Motion Diffusion Model, 2022
Source: https://guytevet.github.io/mdm-page/
Image To Image
Image-to-image (Img2Img for short) is a method we can use to modify existing images. It is a technique to transform an existing image to a target domain using the text prompt. Simply put, we can generate a new image with the same content as an existing image but with some transformations. We can provide the textual description of the transformation we want.
For example, in the below grid, the left side image is of an “air balloon festival” first generated using “text2img” and then passed to img2img to convert it to a Disney Pixar-style image art.

R – “pixar, disney pictures, air balloons, balloon festival, dark sky, bright stars, award winning, 4k. Hd“
The user provides an input image as a guide/starting point and can change it by providing instructions to the model using the prompt. The diffusion model will generate a new image with the same color and composition as the input image with the new changes.
Using img2img, you can also convert your portraits to Pixar-style images.


Another exciting use case of Img2Img a to convert crude hand-drawn or unfinished images into beautiful pictures with the same content. As down in the example below.
As an experiment: I converted my “bad drawing of nature” into “oil painting,” and the results are outstanding.

A use-case of Img2Img is Style Tranfer. In Style transfer, we take two images: one for content and one for style reference. A new image is generated that is a mixture of both: the first’s content in another’s style.
Style transfer is an exciting and fun topic to explore. In one of our recent posts, we used Style Transfer and created an application for real-time style transfer in Zoom calls.

Image Inpainting
Image Inpainting is an image restoration technique to remove unwanted objects in an image or replace them with some other object/texture/design entirely. To perform image inpainting, the user first draws a mask around the object or the pixels that need to be altered. After creating the mask, the user can tell the model how it should alter the masked pixels.
Some examples:


Here, the part of the sheep on the left is replaced with green grass.



Image Outpainting
Outpainting or infinity painting is a process in which the diffusion model adds details outside/beyond the original image. We can extend our original image by either utilizing parts of the original image (or newly generated pixels) as reference pixels or by adding new textures and concepts using the text prompt.
Source: https://github.com/lkwq007/stablediffusion-infinity
Infinite Zoom In & Zoom Out
A. Infinite Zoom In

It can be considered a clever way to use image inpainting to create fractal-like design patterns.
The process used to generate an “Infine zoom in” is as follows:
- Generate an image using the Stable Diffusion model.
- Scale the image down and copy-paste it into the center.
- Mask out a boundary outside the small copy.
- Use Stable Diffusion inpainting to fill in the masked part.
Another example of Infinite Zoom In is from Twitter user @hardmaru, a researcher at Stability.ai.
B. Infinite Zoom Out
The methods used to generate “Infine Zoom Out” is pretty easy to grasp. It can be considered as an extension of “outpainting.” Unlike image outpainting, the image size stays constant throughout the process.

The size of the image generated using the initial prompt is gradually decreased. This creates a blank space between the image border and the resized image. The additional space is filled using the diffusion model conditioned on the same prompt with the new image (containing the blank space and the initial image) as an initial point. We can generate a video by continuing this process for some iterations, as shown in the examples above.
Image Search & Reverse Image Search
These two are utility services created for finding images that were created using Stable diffusion or performing a reverse image search.
- Lexica – It is a Stable Diffusion search engine. It hosts more than ~5 million images generated, and the prompt generates the image.
- Ternaus – Ternaus is different as it combines image search (image to image) and reverse image search (image to text) in one request. It focuses on finding generated images free of license restrictions.
That’s it; that’s all we wanted in this section. The above list captures some fantastic applications and services that caught our eye. There are several other promising papers that we didn’t showcase, such as:
- Palette: Image-to-Image Diffusion Models that use diffusion models for Image Inpainting, Colorization, Uncropping (similar to Outpainting), and JPEG restoration.
- DiffusionDet: Diffusion Model for Object Detection
- DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
- Pix2Seq-D: A Generalist Framework for Panoptic Segmentation of Images and Videos
We believe after going through the applications we showcased can act as a starting point for our readers to prepare and make them comfortable in finding their way in the world of diffusion models.
Tools
In this section, we list the famous and upcoming community-built tools and online services our users can explore and use for their tasks.
For Local & Colab Installation
- Most Popular – AUTOMATIC1111: Stable Diffusion web UI
- Run on Google Colab fast-stable-diffusion Colab Notebooks, AUTOMATIC1111
- invoke-ai: InvokeAI is a leading creative engine for Stable Diffusion model.
- Sygil-Dev: Stable Diffusion web UI
- cmdr2: Easiest 1-click install Stable Diffusion
- abhishekkrthakur: diffuzers: a web ui for 🤗 diffusers
- 🧨 Diffusers
For Online Testing
- Craiyon – Craiyon is an AI model that can draw images from any text prompt!
- nateraw/stable-diffusion-videos
- deforum/deforum_stable_diffusion
- ashawkey/stable-dreamfusion: A pytorch implementation of text-to-3D dreamfusion, powered by stable diffusion.
- MDM – Human Motion diffusion model
- stability-ai/stable-diffusion-img2img
- Diffuse The Rest – a Hugging Face Space
- Runway Inpainting – a Hugging Face Space
- Stable Diffusion Inpainting – a Hugging Face Space
- Stablediffusion Infinity – Outpainting with Stable Diffusion on an infinite canvas.
- arielreplicate/stable_diffusion_infinite_zoom in
- Huggingface Diffusion Spaces
Summary
Diffusion models are here to stay!
Diffusion models can immensely augment the world of creative work and content creation in general. They have already proved their capability in the past few months. The number of diffusion models is growing daily, and older versions are getting outdated quickly. In fact, there is a very high chance that by the time you read this article, some of the models mentioned above would have their newer versions.
In any case, it is time that creators and businesses start using diffusion models for image and content generation. Even if not as a final product, diffusion models can act as a means to inspire the world of creative workers.
In this article📜, we covered a comprehensive list of related topics. To summarise:
- We began by exploring the place of diffusion models in deep learning-based generative models.
- We provided a high-level overview of diffusion and diffusion models and how they work.
- We discussed some of the most impactful and popular diffusion models and their community-built variants.
- Finally, we finished by discussing different exciting and fun applications of diffusion models and the different tools & services one can use to play with diffusion models.
We would love to hear from you. Please feel free to ask questions in the comment section; we are more than happy to converse with you.
🌟Happy learning!
References
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics
- Denoising Diffusion Probabilistic Models
- Understanding Diffusion Models: A Unified Perspective
- What are Diffusion Models?
- Improving Diffusion Models as an Alternative To GANs, Part 1
- Introduction to Diffusion Models for Machine Learning
- Diffusion Models: A Practical Guide
- Diffusion models are autoencoders
- The recent rise of diffusion-based models
- The Illustrated Stable Diffusion

