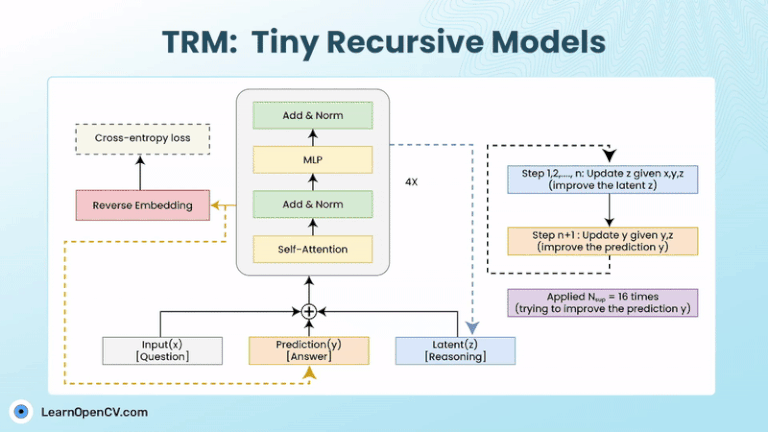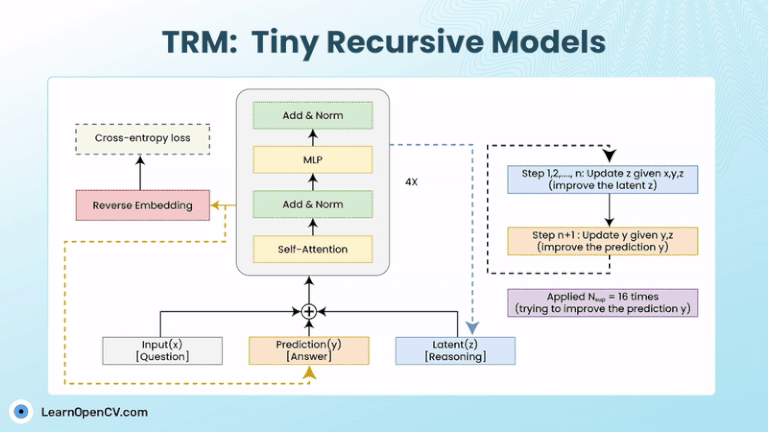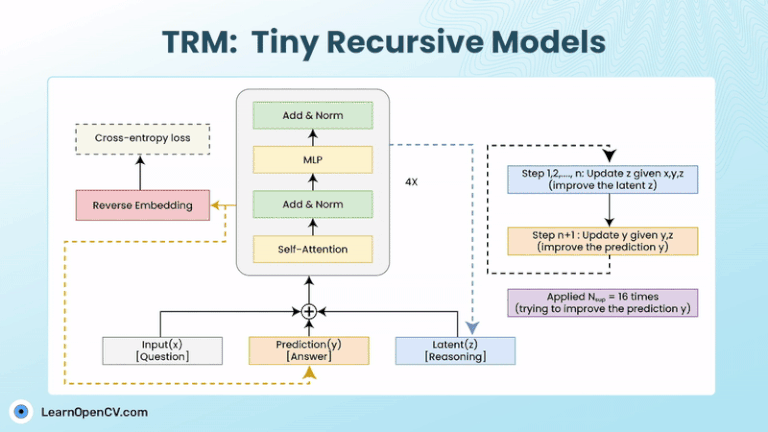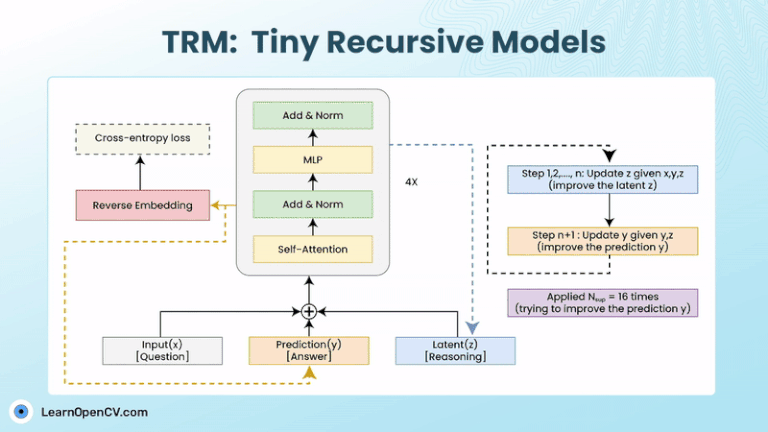
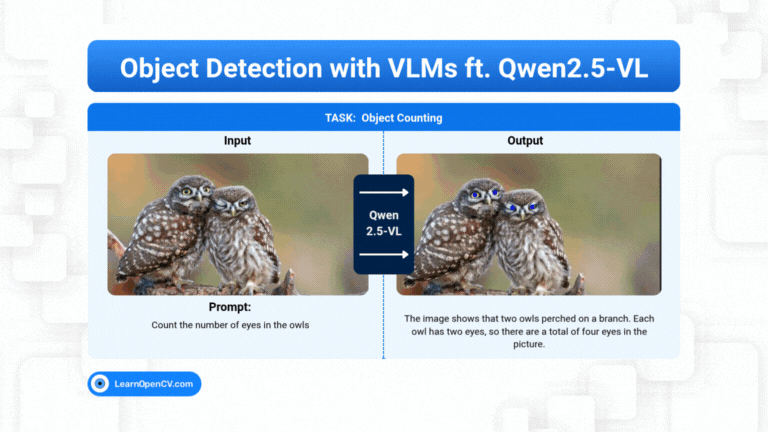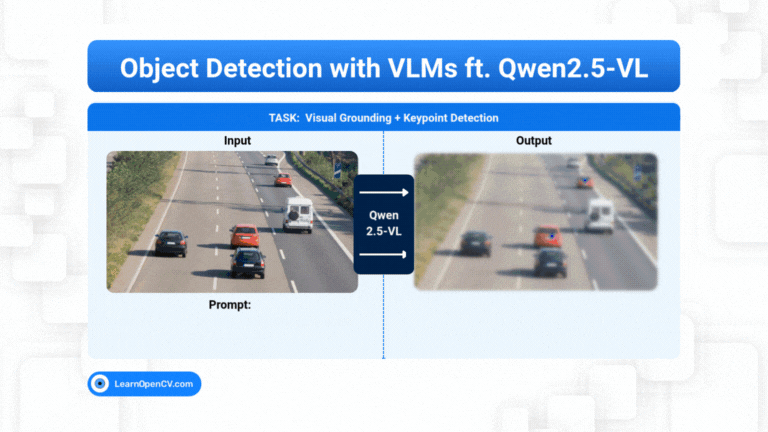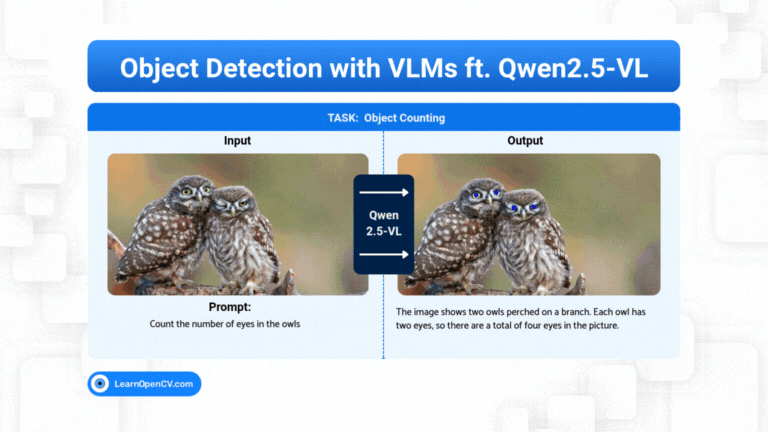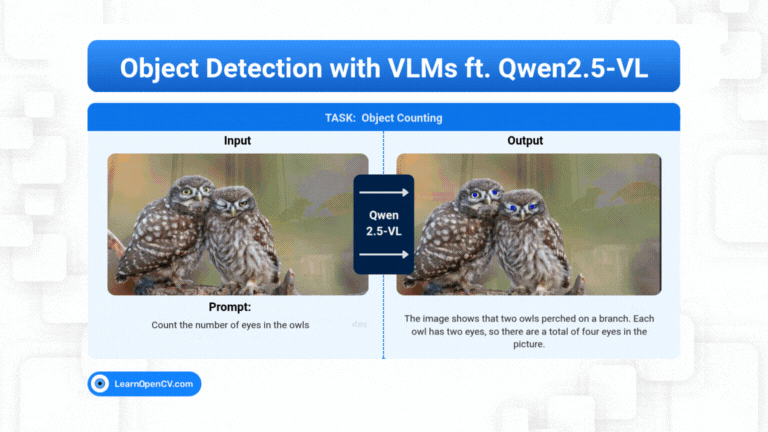
Models with billions, or trillions, of parameters are becoming the norm. These models can write essays, generate code, as well as create art. But they can still get stuck on
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
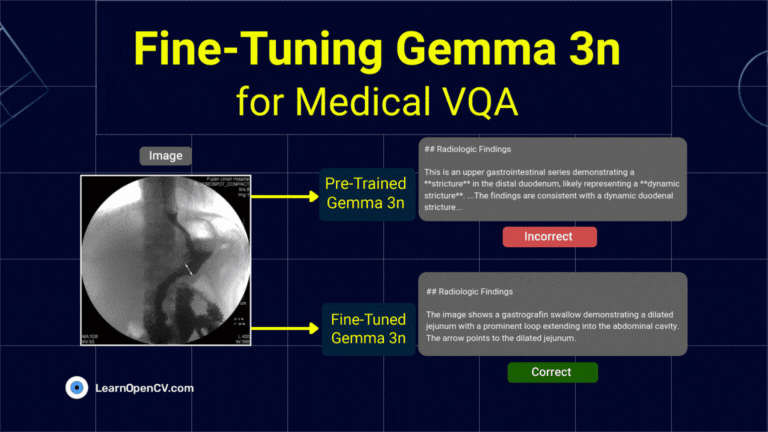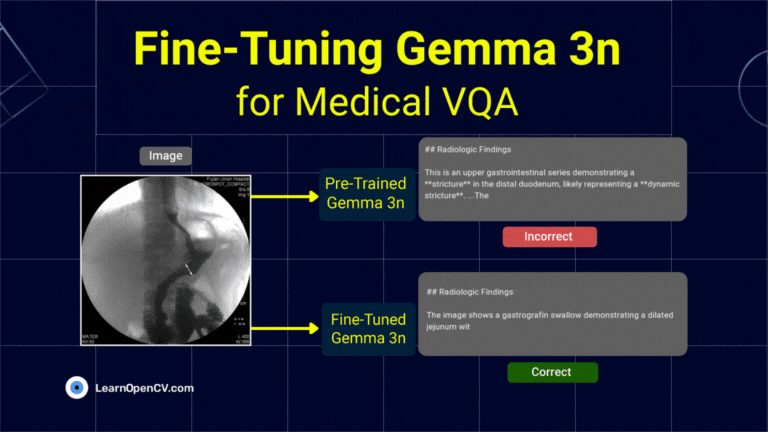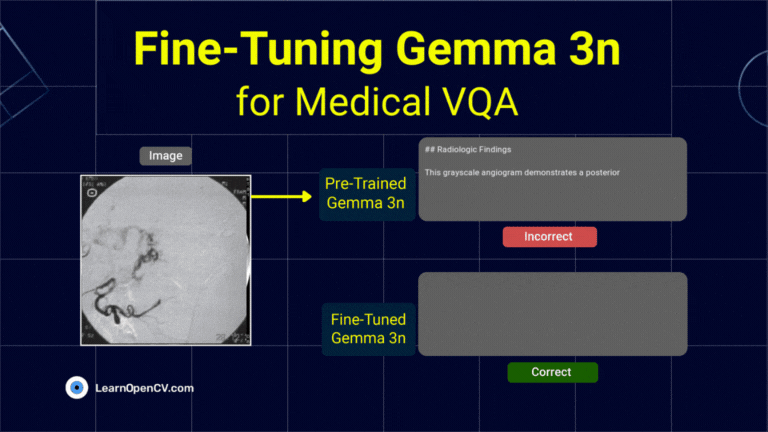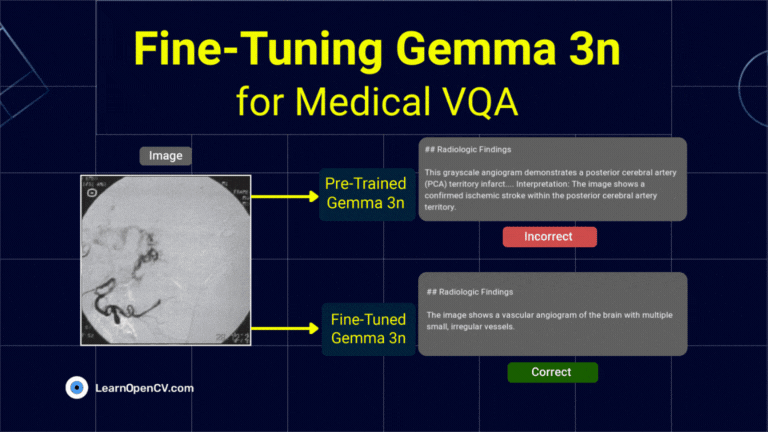
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
The field of computer vision is fueled by the remarkable progress in self-supervised learning. At the forefront of this revolution is DINOv2, a cutting-edge self-supervised vision transformer developed by Meta
GPT-4o image generation is a game-changer! With native support in ChatGPT, you can now create stunning visuals from text prompts, refine them, and explore styles like Studio Ghibli or photorealism.
Apple's DepthPro is quite impressive, producing pixel-perfect, high-resolution metric depth maps with sharp boundaries through monocular depth estimation. It outperforms all of its contenders like Metric3D v2 and DepthAnything in
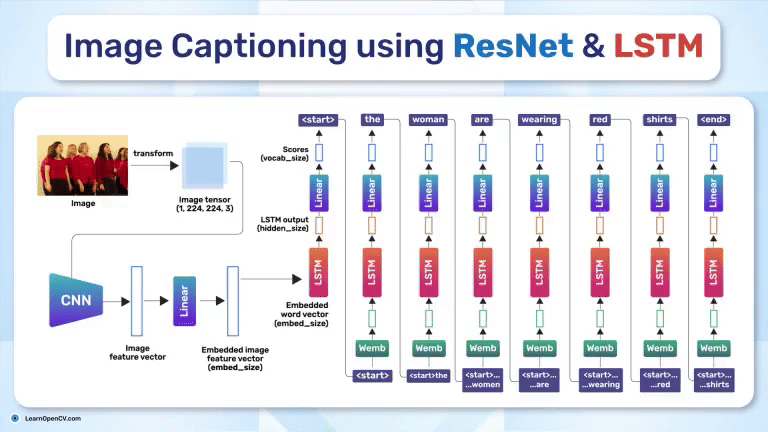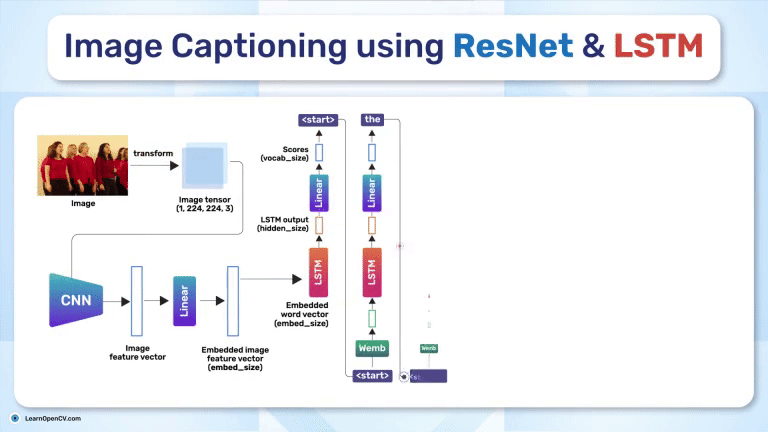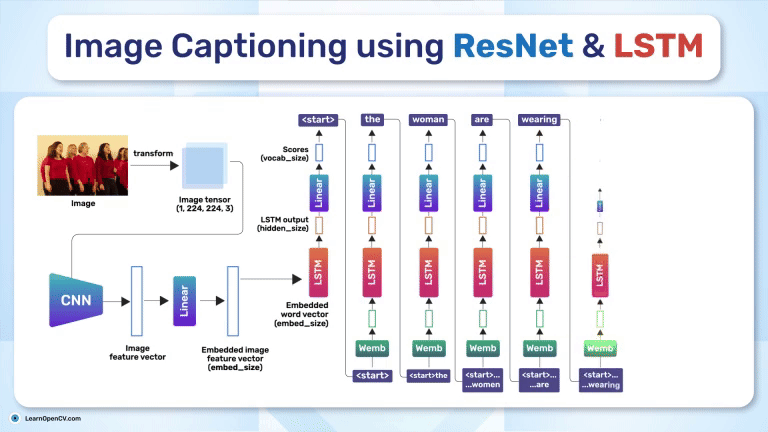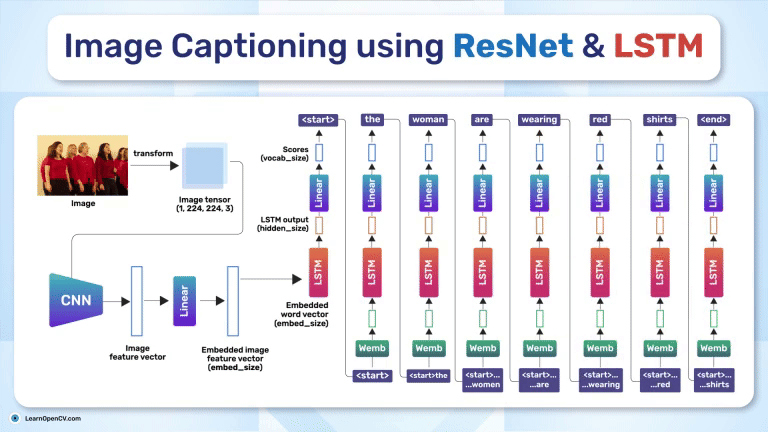
Image Captioning using ResNet and LSTM bridges vision and language, enabling machines to "see" images and "describe" them in text. This model powers applications like accessibility for visually impaired users,
This article discusses the architecture of LightRAG from HKU, exploring its in-depth internal workings and comparing it with GraphRAG and NaiveRAG for local document analysis.
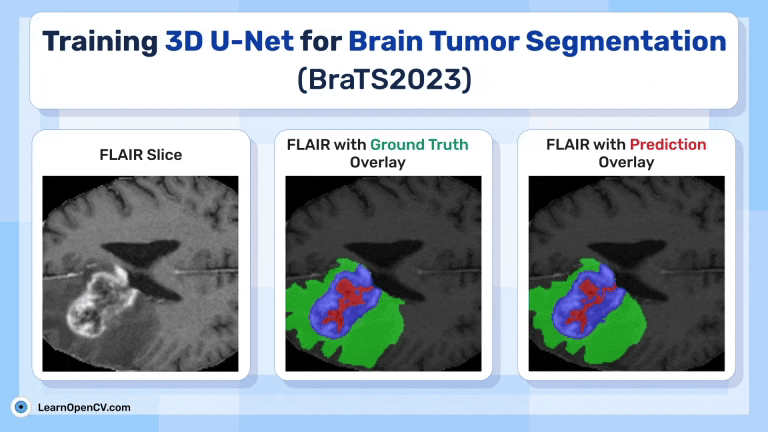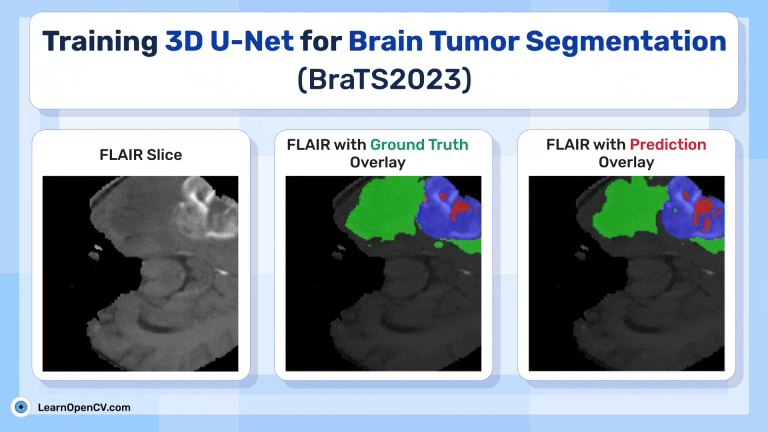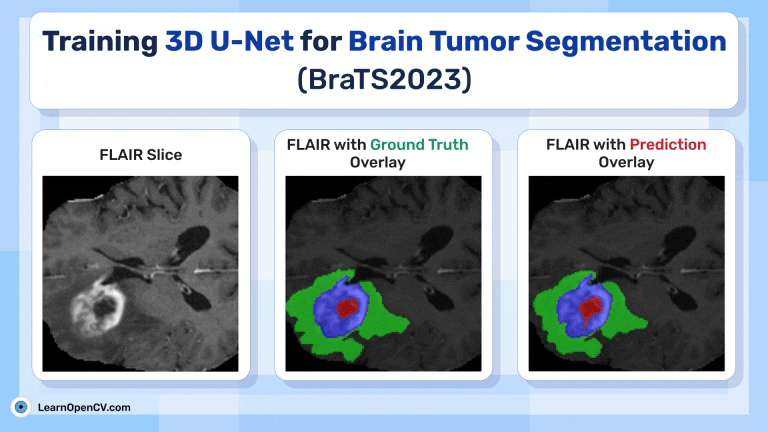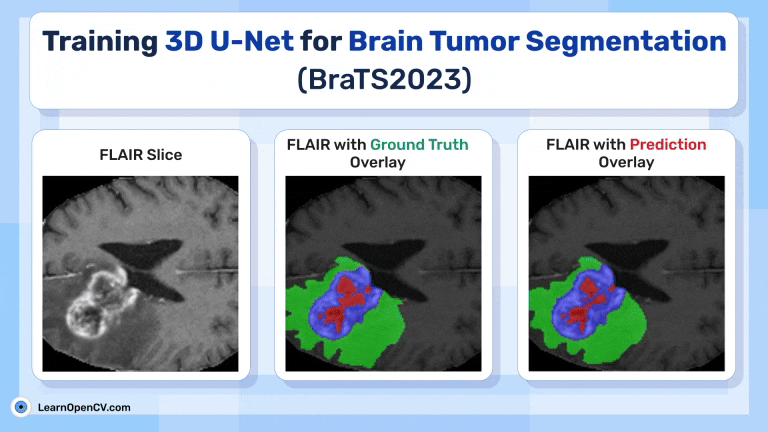
This articles discussed Training 3D U-Net for Brain Tumor Segmentation - BraTS2023. Glioma Detection It touches upon the importance of 3D U-Net over 2D U-Net for MRI Brain Scans.
The article primarily discusses capabilities Sapiens a foundational human vision model by meta, achieves state-of-the-art performance in tasks like 2D pose estimation, body-part segmentation, normal and depth estimation.