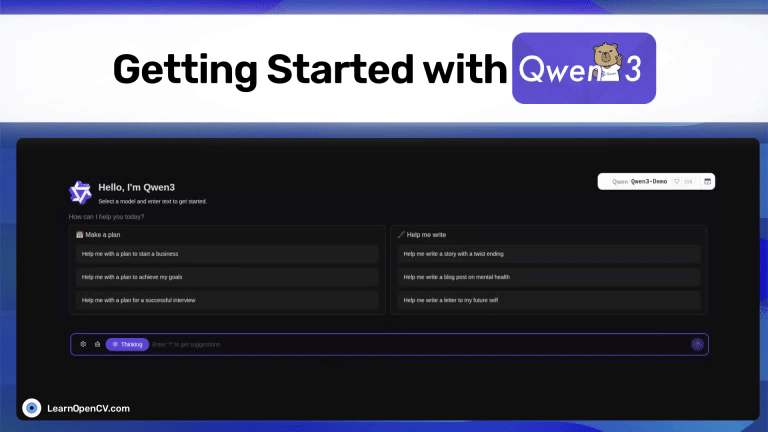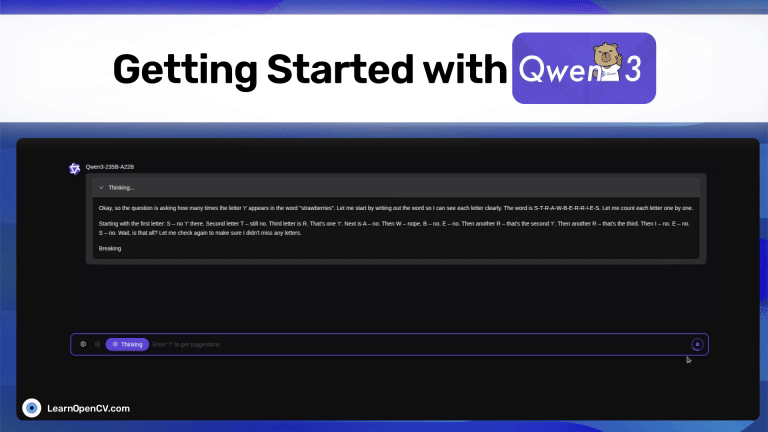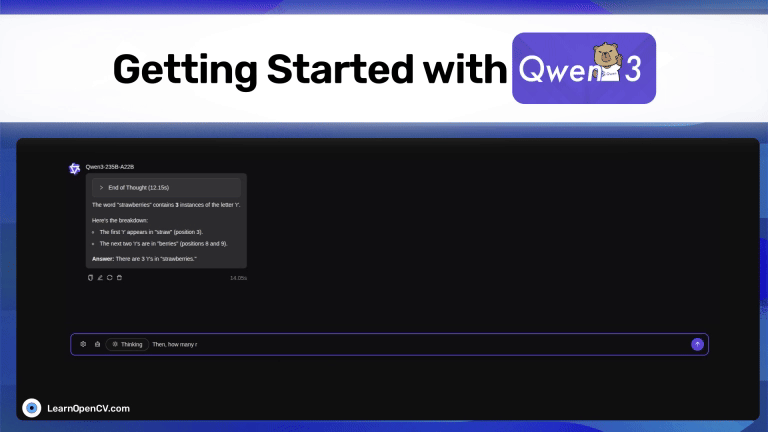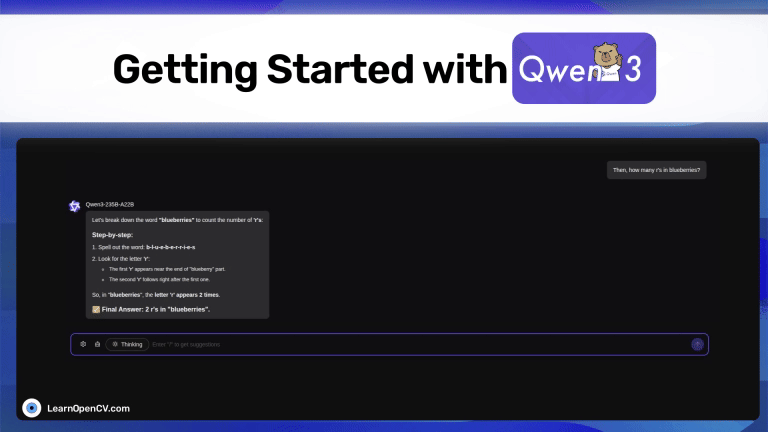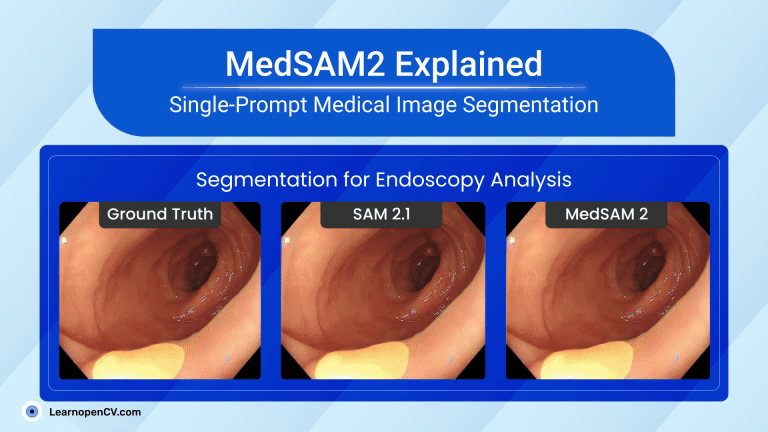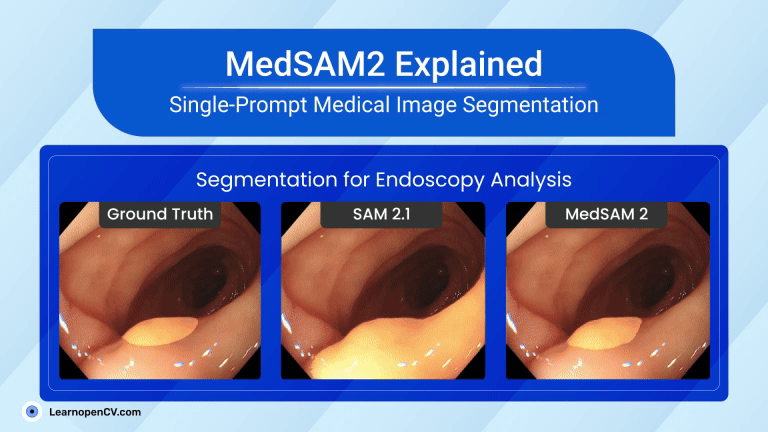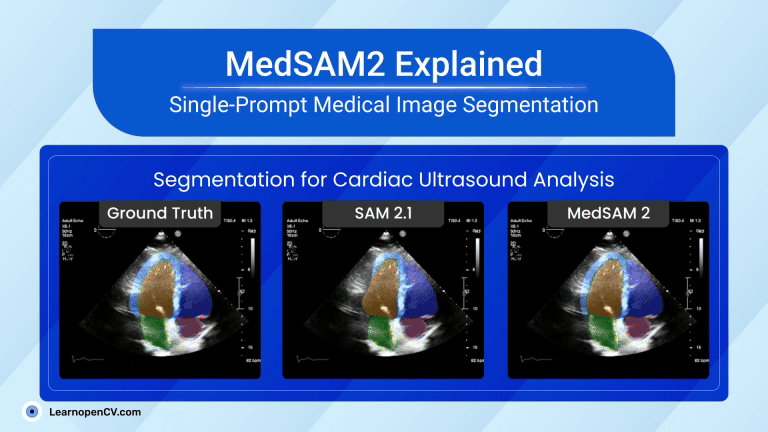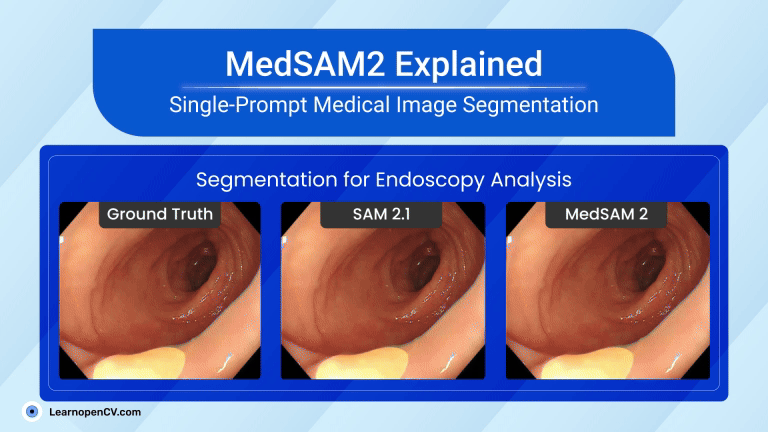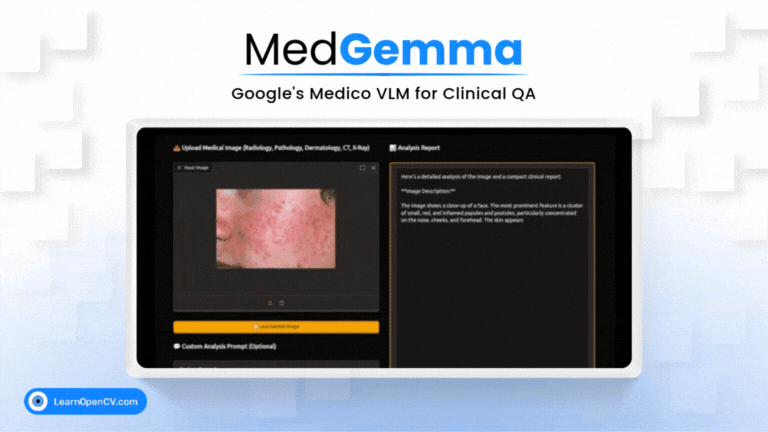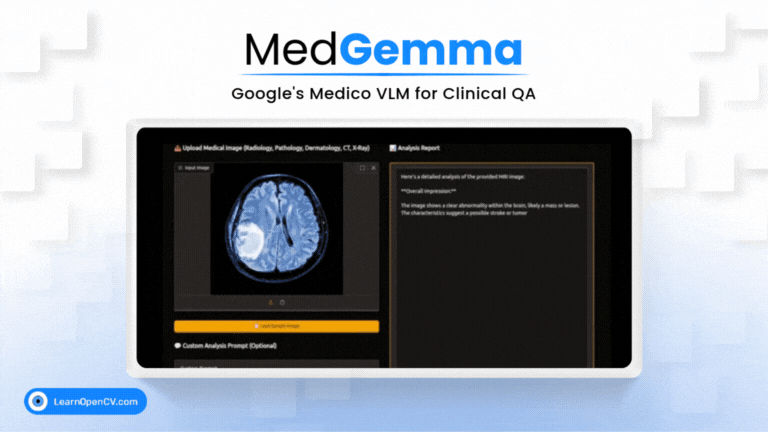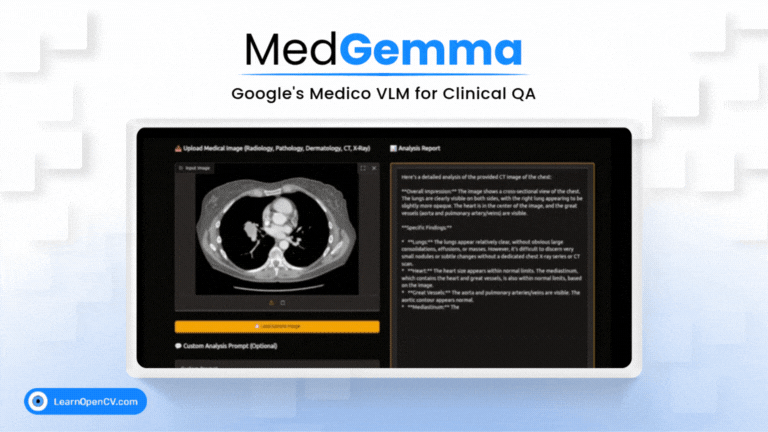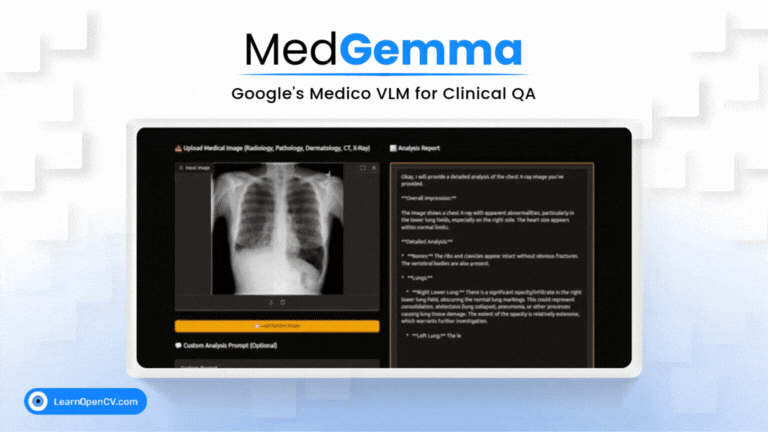
Picture this: Dr. Aris, a radiologist with a decade of experience, is staring at his screen. The stack of digital files, chest X-rays, and CT scans seems endless. Each image holds a story, a clue to a ...
MedGemma: Google’s Medico VLM for Clinical QA, Imaging, and More
June 24, 2025 1 Comment