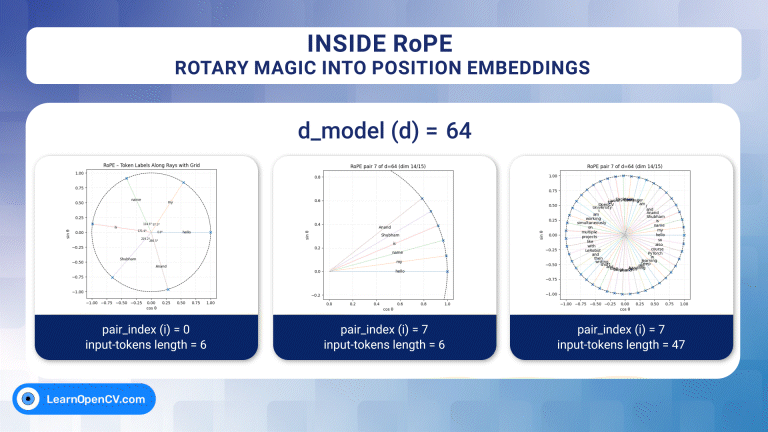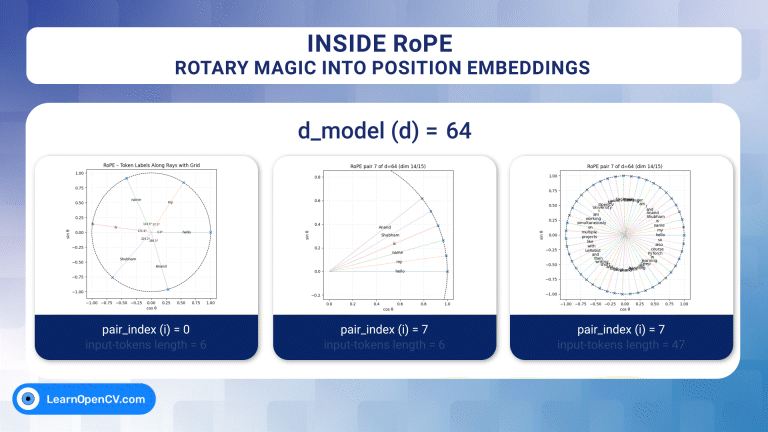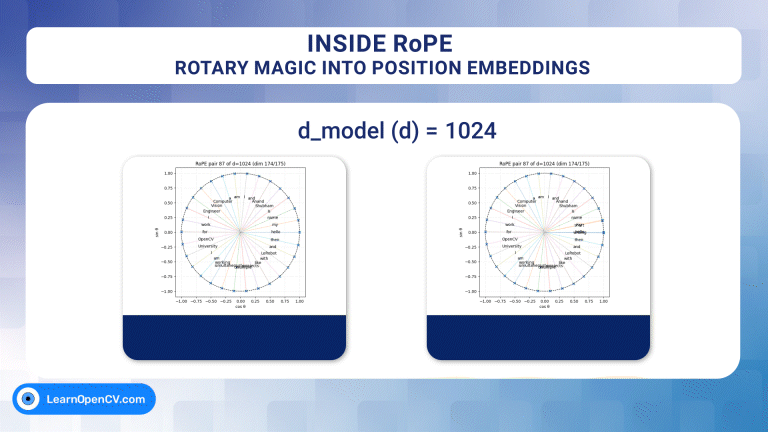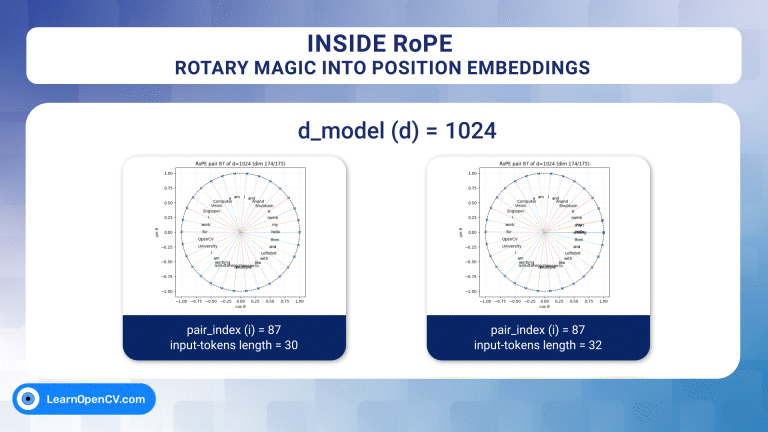
In the groundbreaking 2017 paper "Attention Is All You Need", Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or ...







In the groundbreaking 2017 paper "Attention Is All You Need", Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or ...
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which ...
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on ...
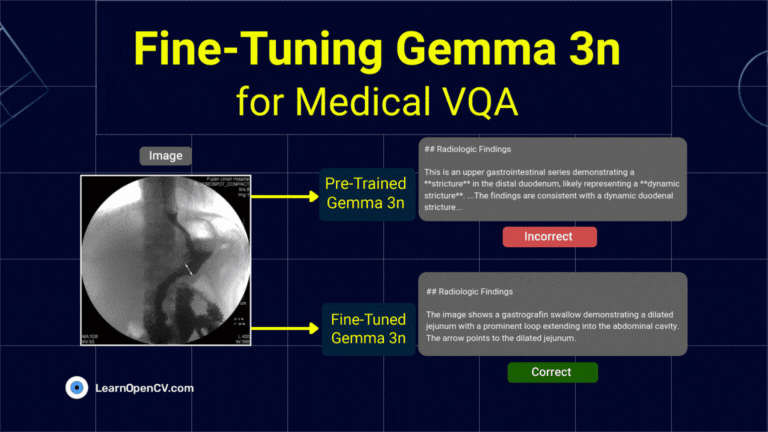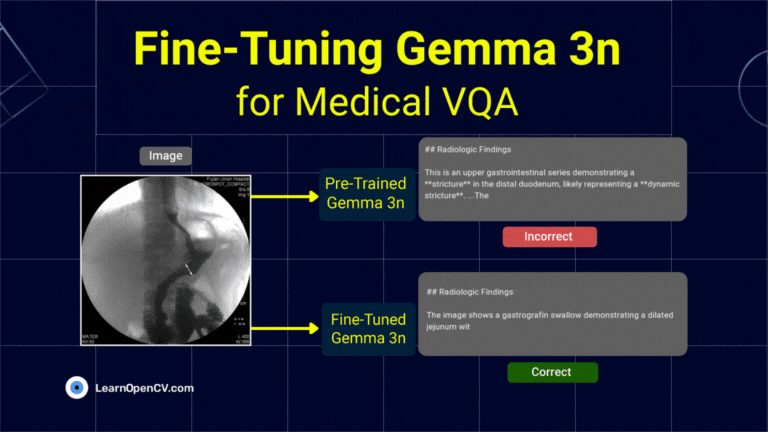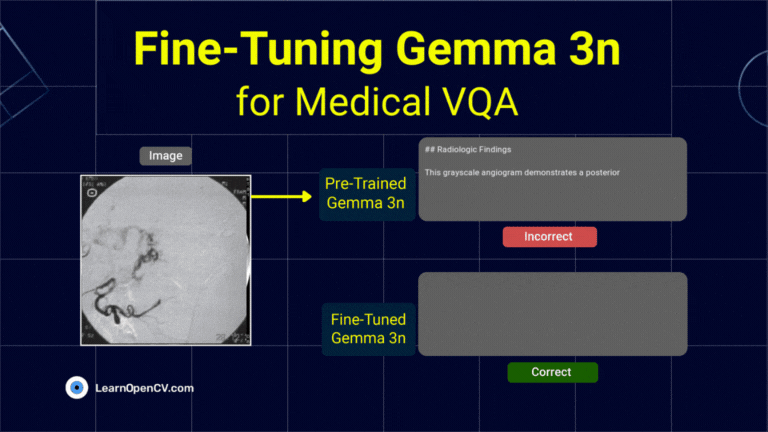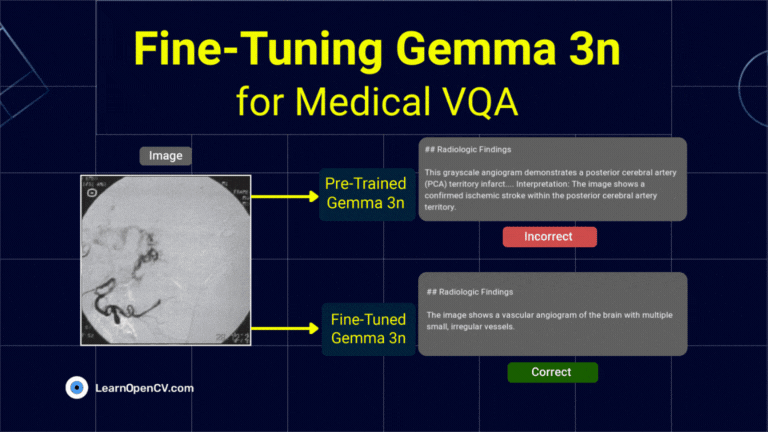
The release of Gemma 3n, Google's latest family of open nano models, made LLM edge deployment more accessible. Its unique architecture is engineered to address the persistent challenges ...
In the evolving landscape of open-source language models, SmolLM3 emerges as a breakthrough: a 3 billion-parameter, decoder-only transformer that rivals larger 4 billion-parameter peers on many ...
Developing intelligent agents, using LLMs like GPT-4o, Gemini, etc., that can perform tasks requiring multiple steps, adapt to changing information, and make decisions is a core challenge in AI ...