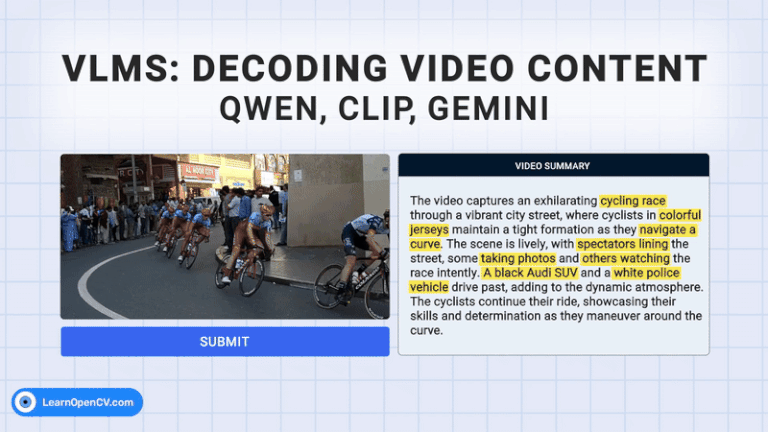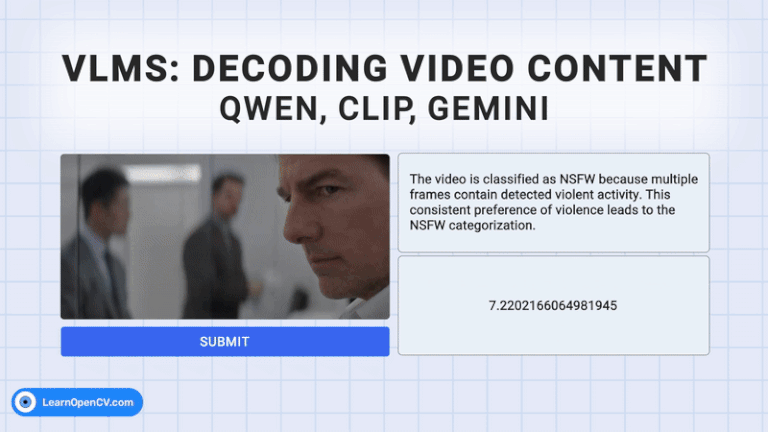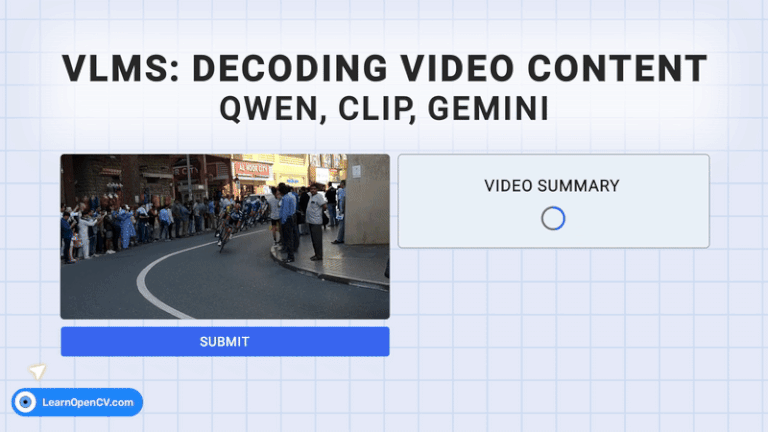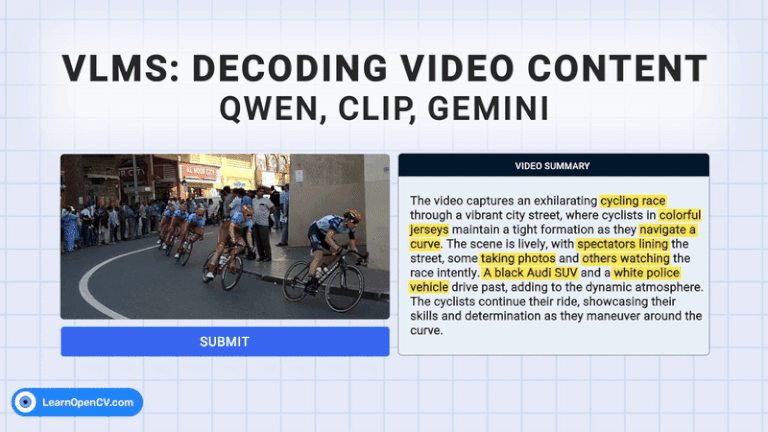
In 2018, Pete Warden from TensorFlow Lite said, “The future of machine learning is tiny.” Today, with AI moving towards powerful Vision Language Models (VLMs), the need for high computing power has ...







In 2018, Pete Warden from TensorFlow Lite said, “The future of machine learning is tiny.” Today, with AI moving towards powerful Vision Language Models (VLMs), the need for high computing power has ...
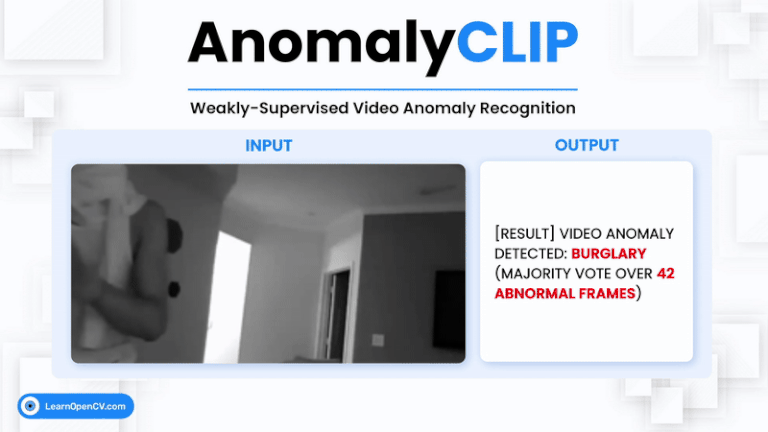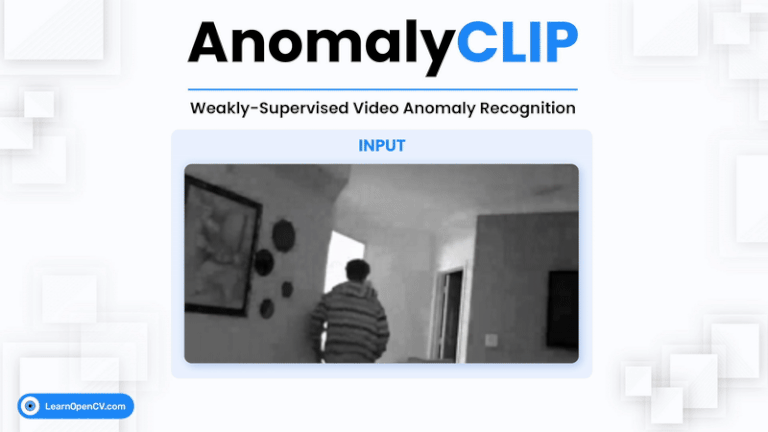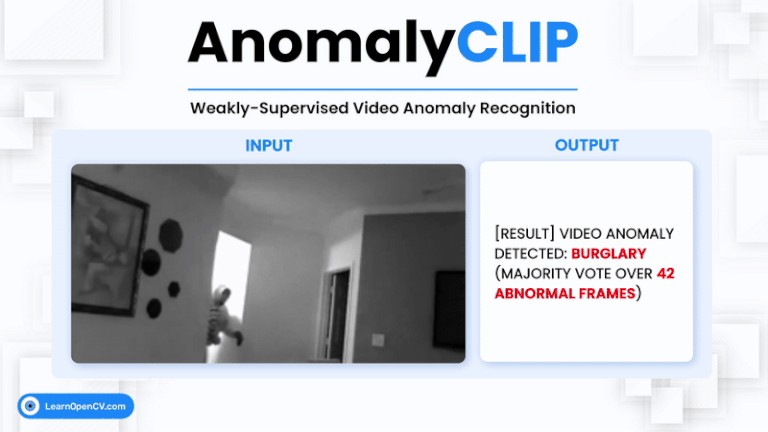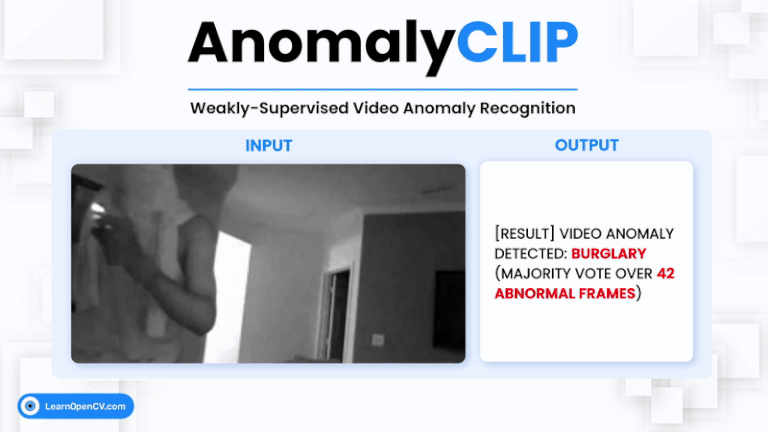
Video Anomaly Detection (VAD) is one of the most challenging problems in computer vision. It involves identifying rare, abnormal events in videos - such as burglary, fighting, or accidents - amidst ...
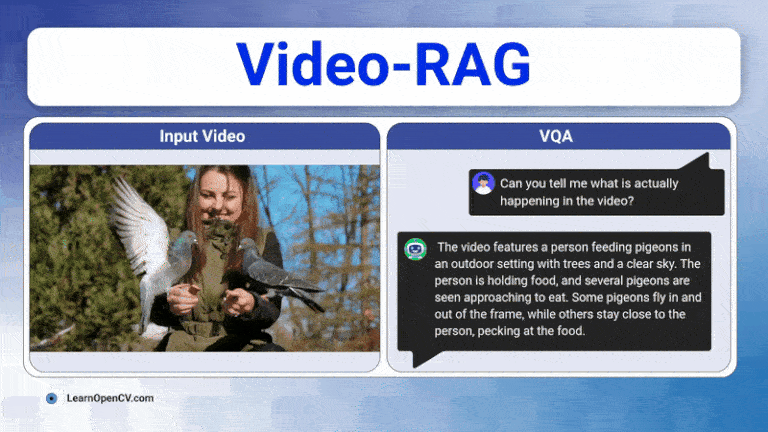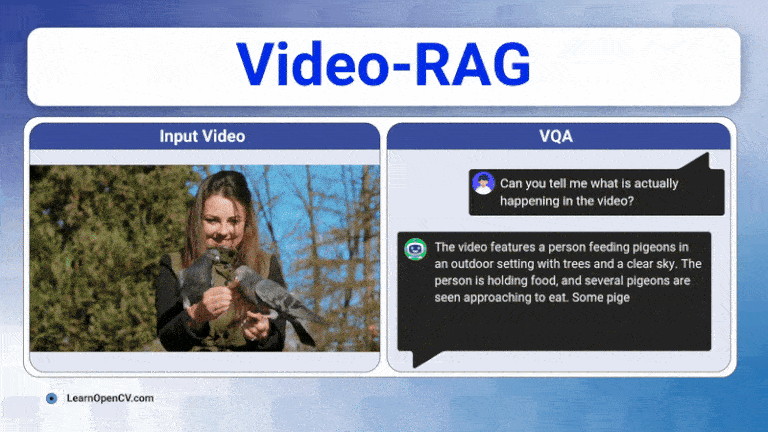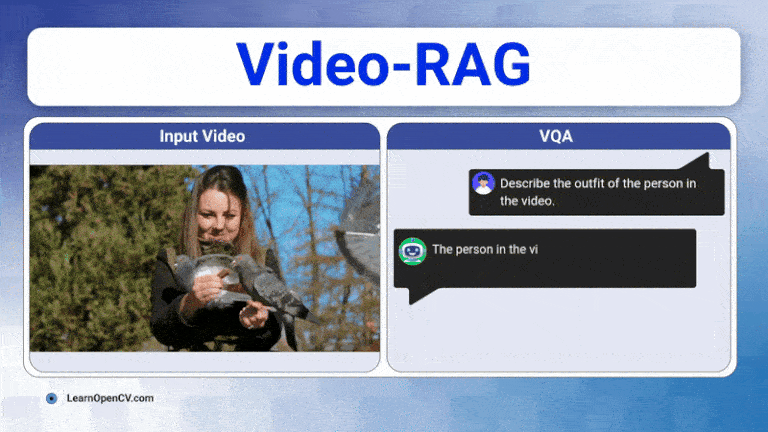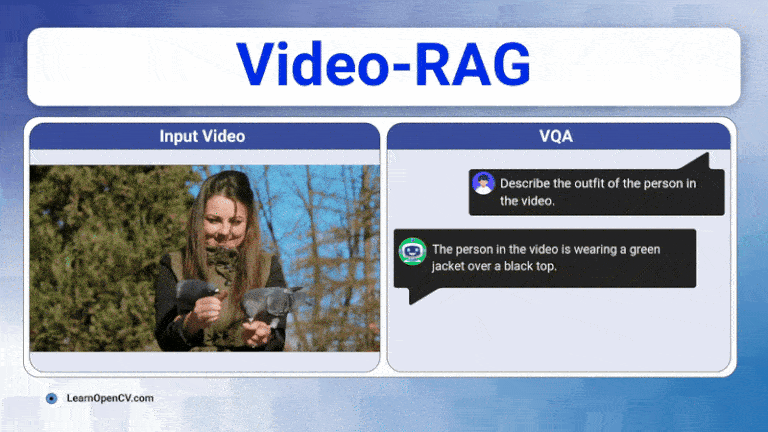
The rapid growth of video content has created a need for advanced systems to process and understand this complex data. Video understanding is a critical field in AI, where the goal is to enable ...
Long videos are brutal for today’s Large Vision-Language Models (LVLMs). A 30-60 minute clip contains thousands of frames, multiple speakers, on-screen text, and objects that appear, disappear, and ...
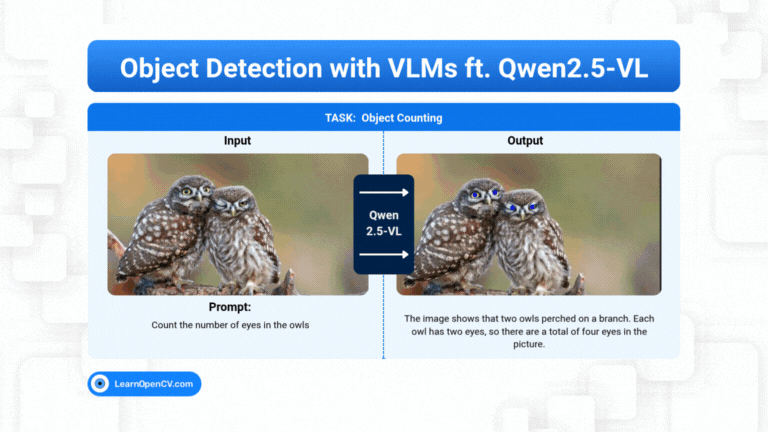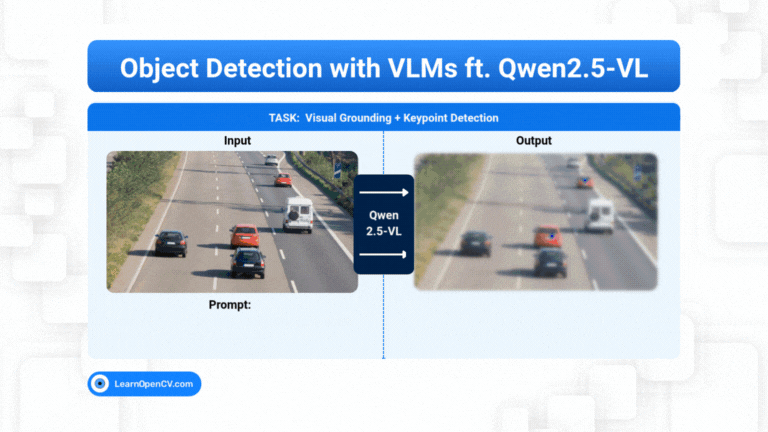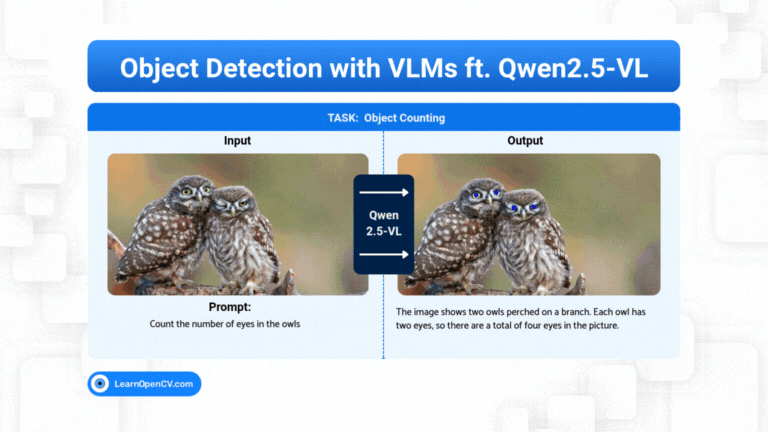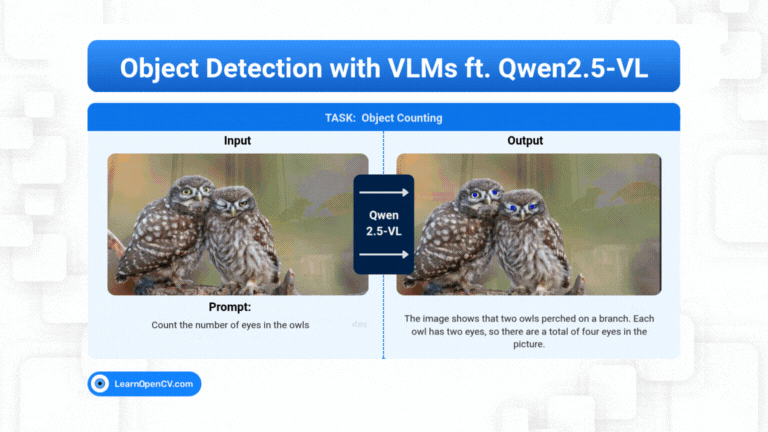
Object Detection is predominantly a vision task where we train a vision model, like YOLO, to predict the location of the object along with its class. But still it depends on the pre-trained classes, ...
Welcome back to our LangGraph series! In our previous post, we explored the fundamental concepts of LangGraph by building a Visual Web Browser Agent that could navigate, see, scroll, and ...