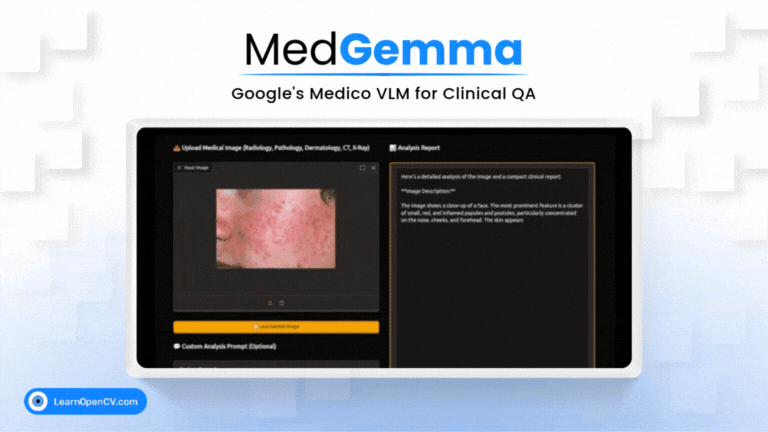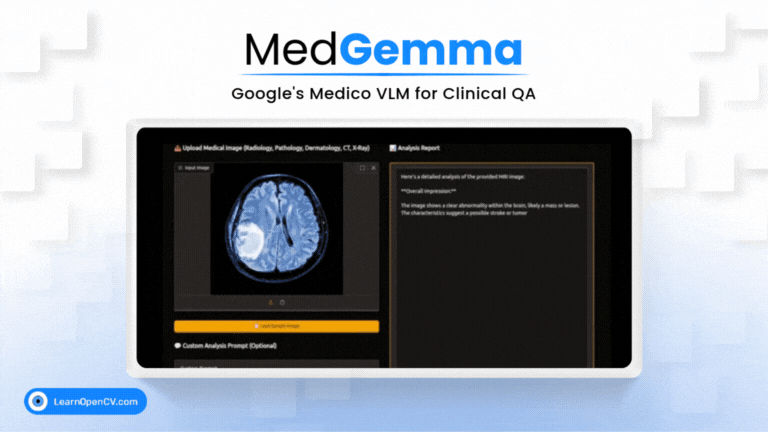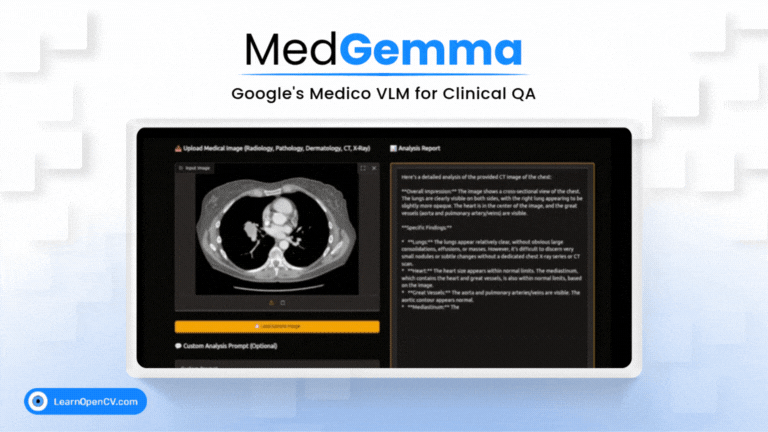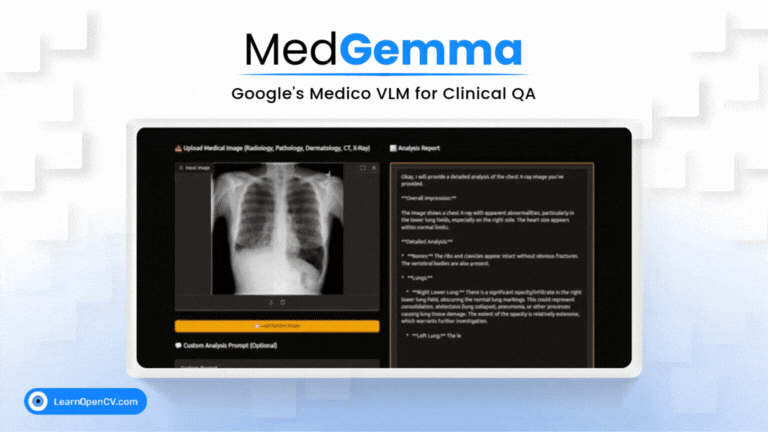
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for
The article primarily discusses capabilities Sapiens a foundational human vision model by meta, achieves state-of-the-art performance in tasks like 2D pose estimation, body-part segmentation, normal and depth estimation.
Performing RAG on Unstructured elements that too in complex pdfs like finance, law reports is challenging. ColPali a novel document retrieval approach achieves SOTA results with high quality retrieval. This
Discover the power of SDXL Inpainting, an advanced AI model that restores and enhances photos with precision. Learn how this technology repairs damaged images and fosters creative digital editing, making