




SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction ...
Search Results for: c
GR00T N1.5 Explained: NVIDIA’s VLA Model for Humanoids

Imagine trying to teach a toddler a new skill, like stacking blocks to build a tower. You’d show them, maybe guide their little hands, and explain, "This one goes on top." After a few tries, they ...
Getting Started with Qwen3 – The Thinking Expert
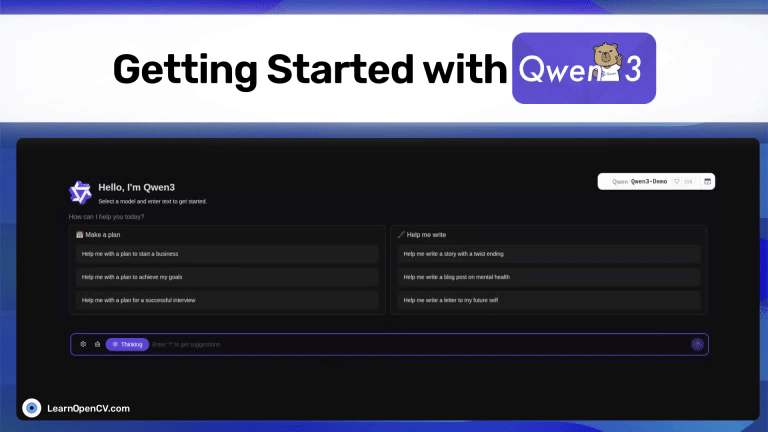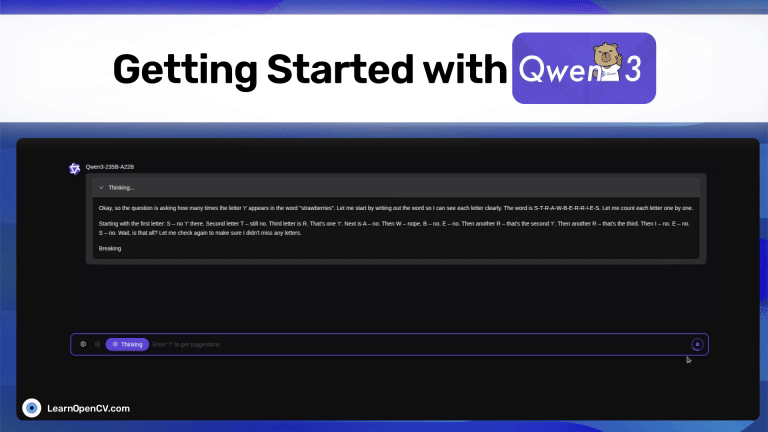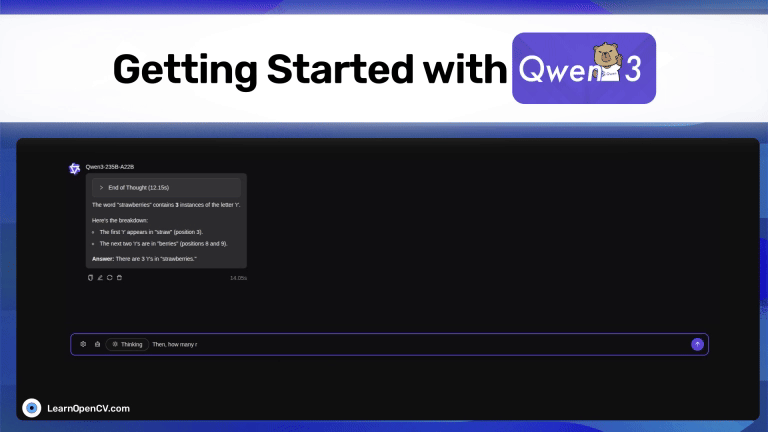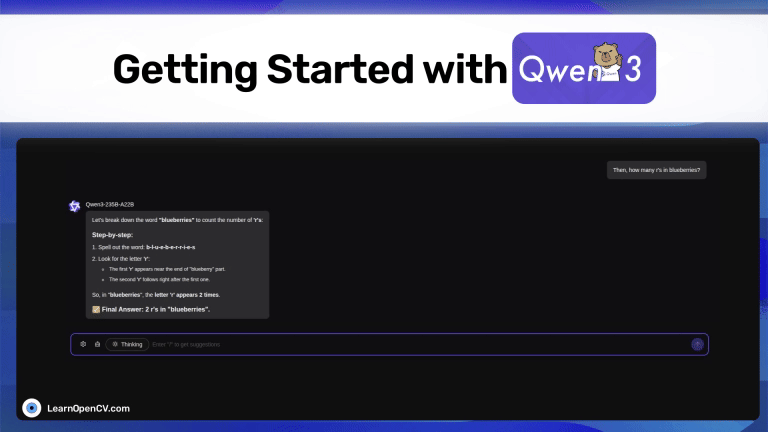
Alibaba Cloud just released Qwen3, the latest model from the popular Qwen series. It outperforms all the other top-tier thinking LLMs, such as DeepSeek-R1, o1, o3-mini, Grok-3, and ...
Google I/O 2025: All you need to know

Google I/O, the much-anticipated annual developer conference, once again served as the epicenter for groundbreaking announcements, offering a comprehensive glimpse into Google's technological roadmap ...
SANA-Sprint: The One-Step Revolution in High-Quality AI Image Synthesis

The domain of image generation has achieved remarkable milestones, particularly through the advent of diffusion models. However, a persistent challenge has been the computational cost associated with ...
DINOv2 by Meta: A Self-Supervised foundational vision model

The field of computer vision is fueled by the remarkable progress in self-supervised learning. At the forefront of this revolution is DINOv2, a cutting-edge self-supervised vision transformer ...

