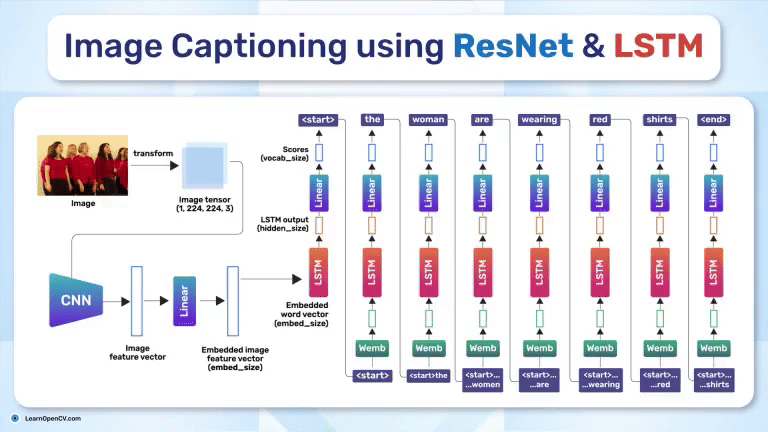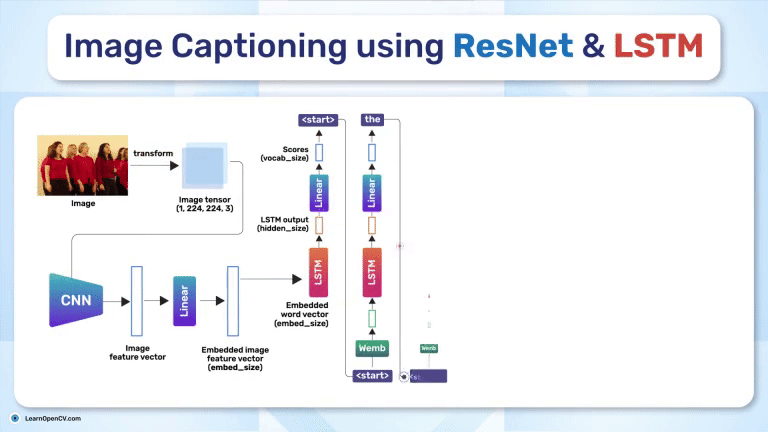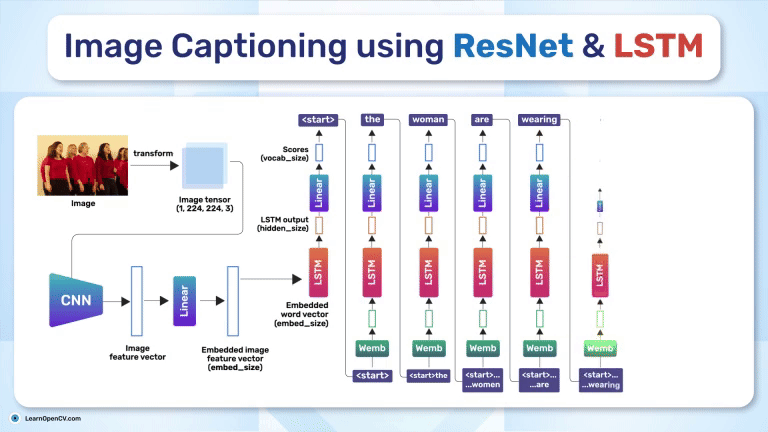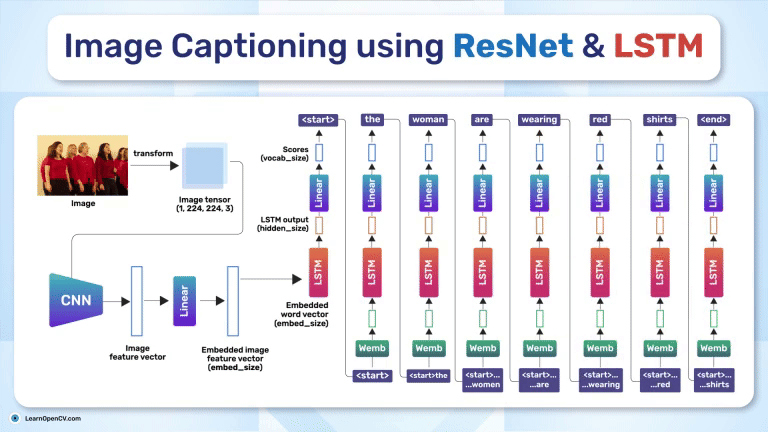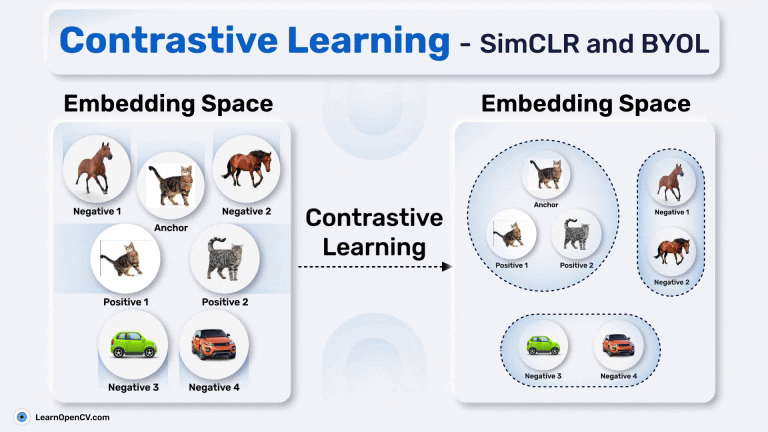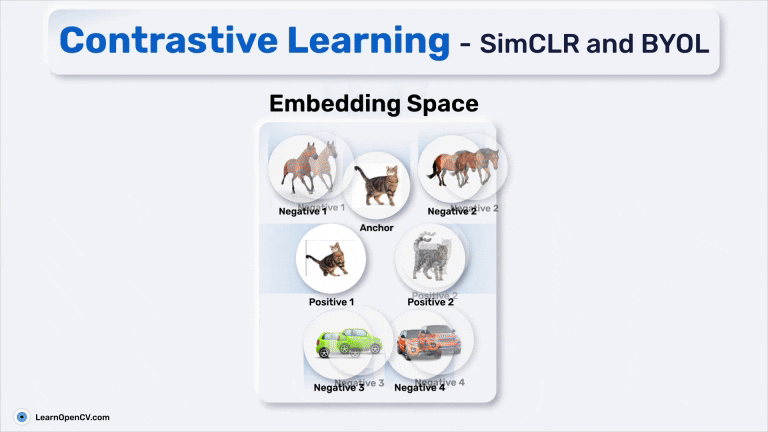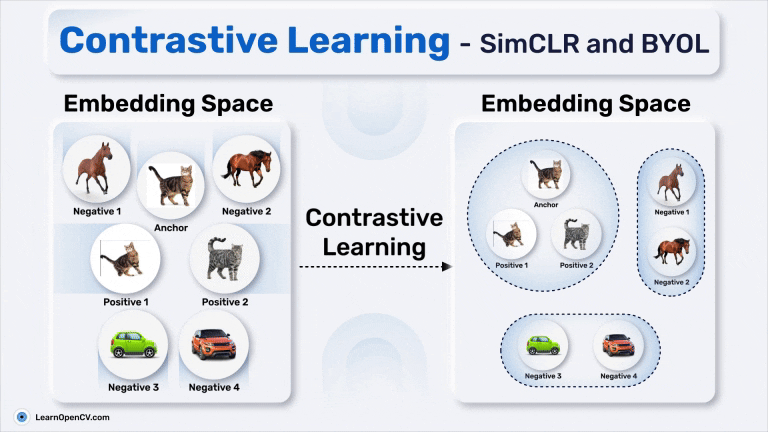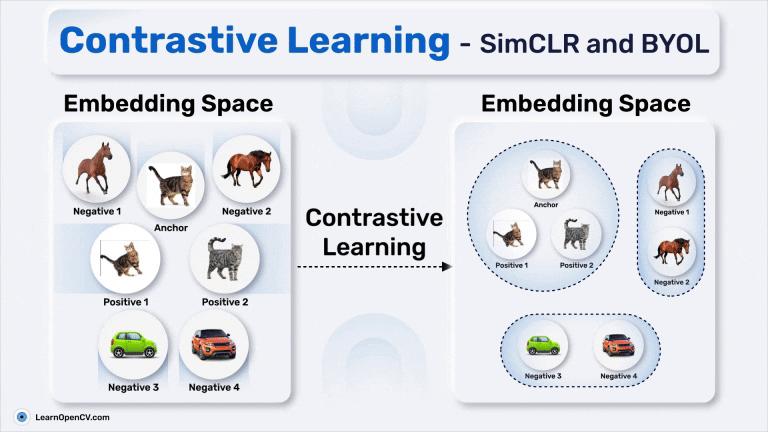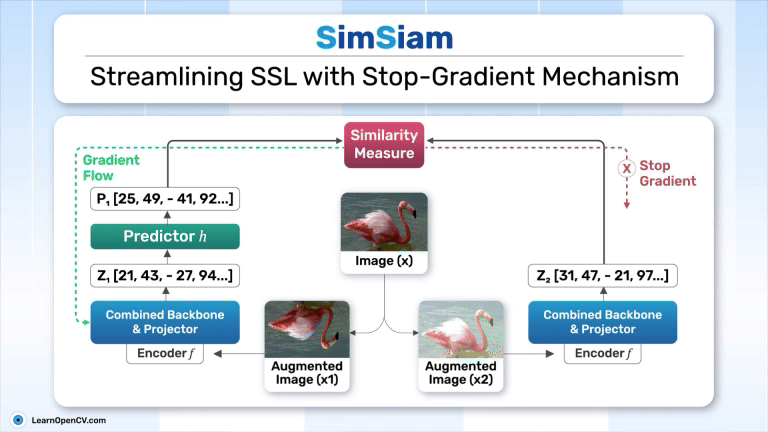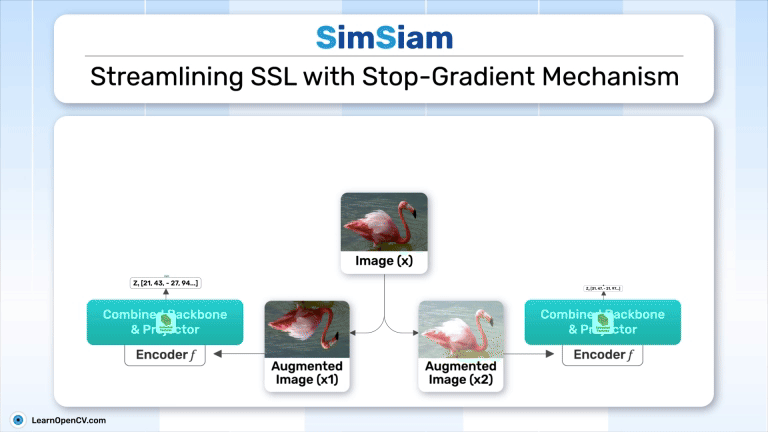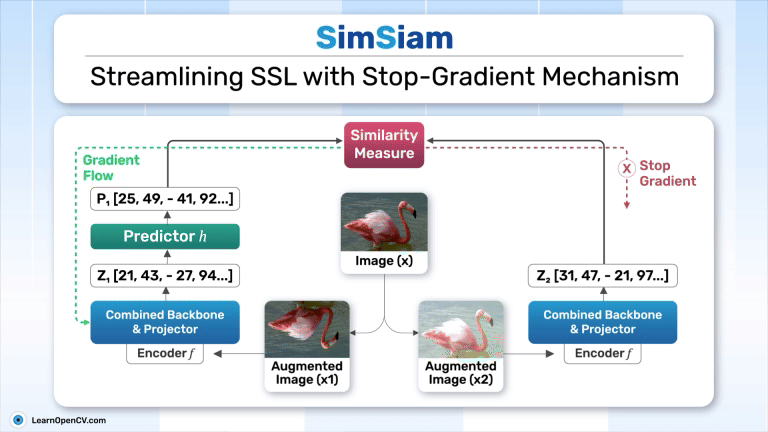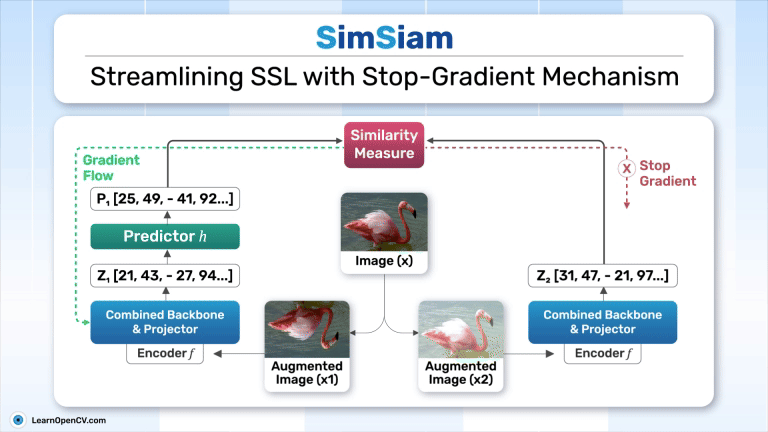
SimSiam holds an eminent status in Self-Supervised Learning by simplifying Representation Learning without relying on negative pairs - typically employed in SimCLR to contrast between dissimilar ...
SimSiam: Streamlining SSL with Stop-Gradient Mechanism
January 7, 2025
2 Comments