SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction ...







SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction ...
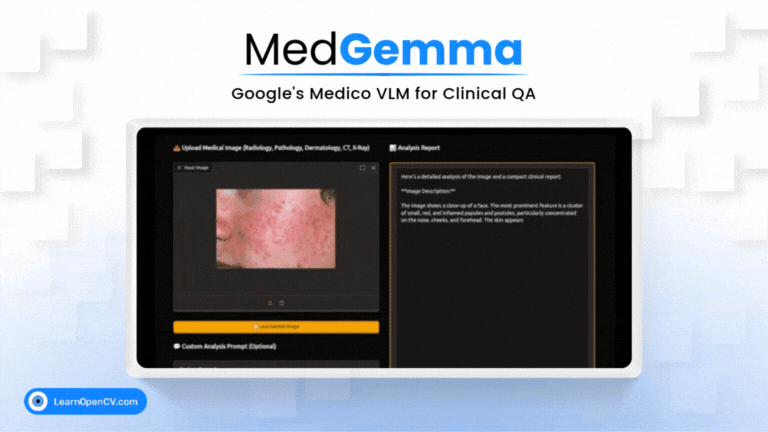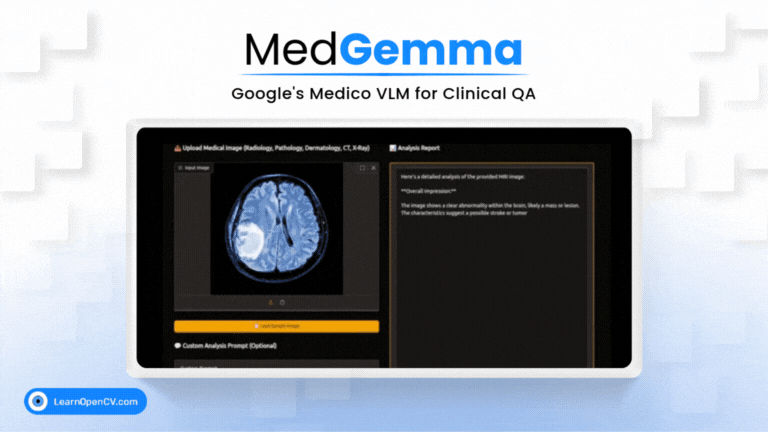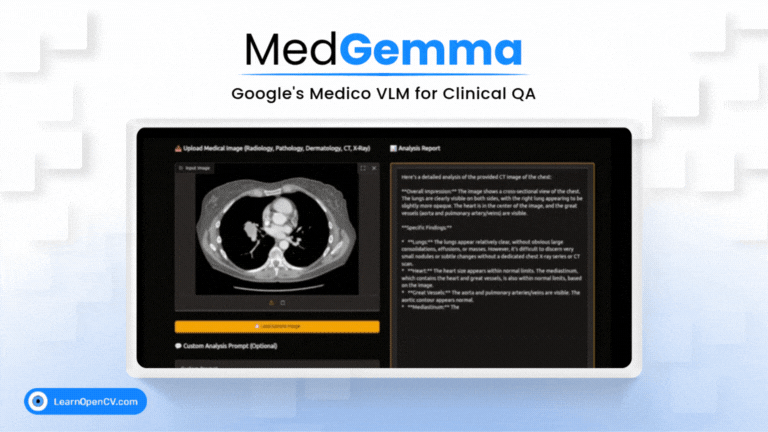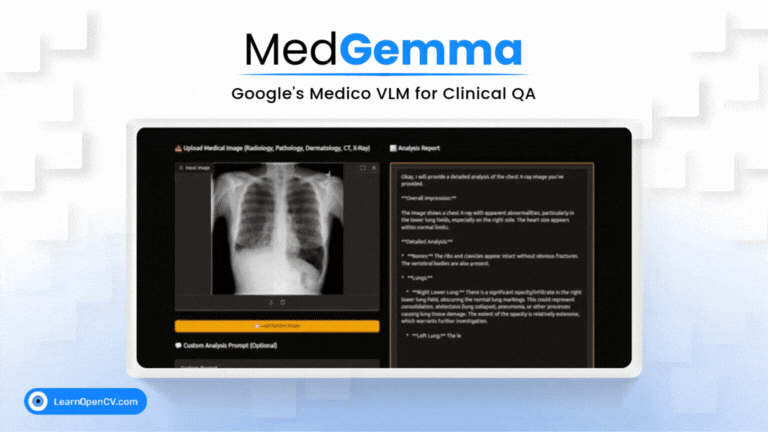
Picture this: Dr. Aris, a radiologist with a decade of experience, is staring at his screen. The stack of digital files, chest X-rays, and CT scans seems endless. Each image holds a story, a clue to a ...
Traditional Optical Character Recognition (OCR) systems are primarily designed to extract plain text from scanned documents or images. While useful, such systems often ignore semantic structure, ...
The domain of video understanding is rapidly evolving, with models capable of interpreting complex actions and interactions within video streams. Meta AI's VJEPA-2 (Video Joint Embedding Predictive ...
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride toward this vision ...
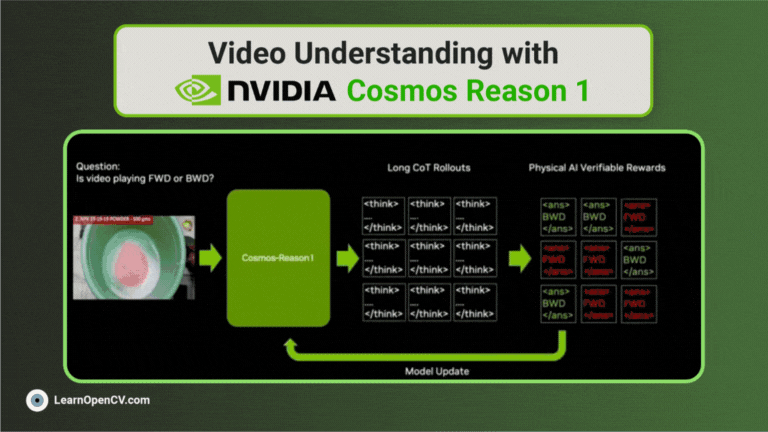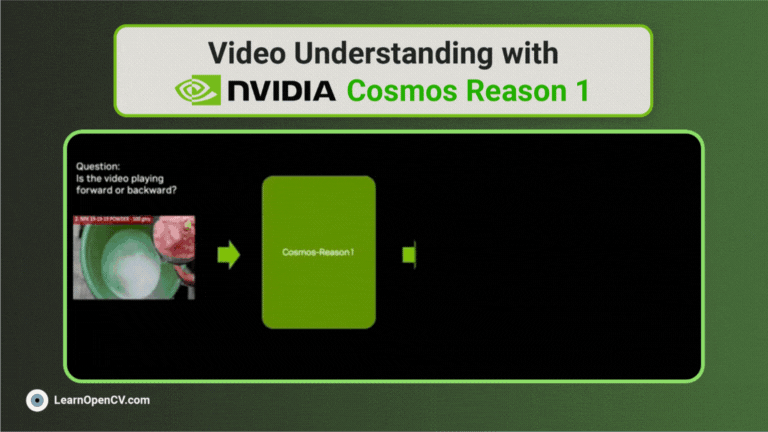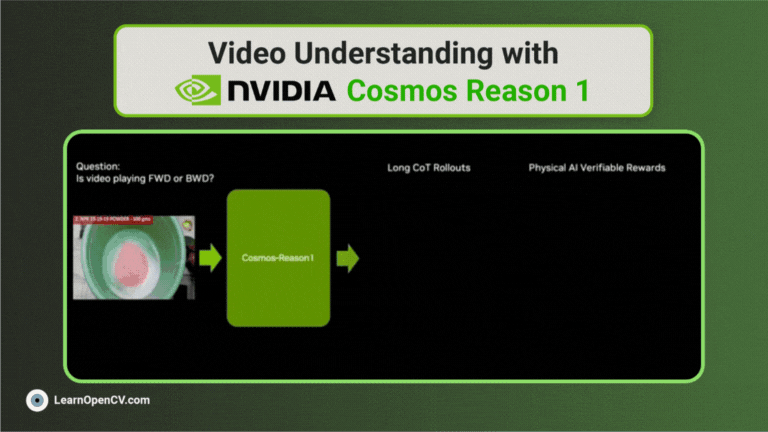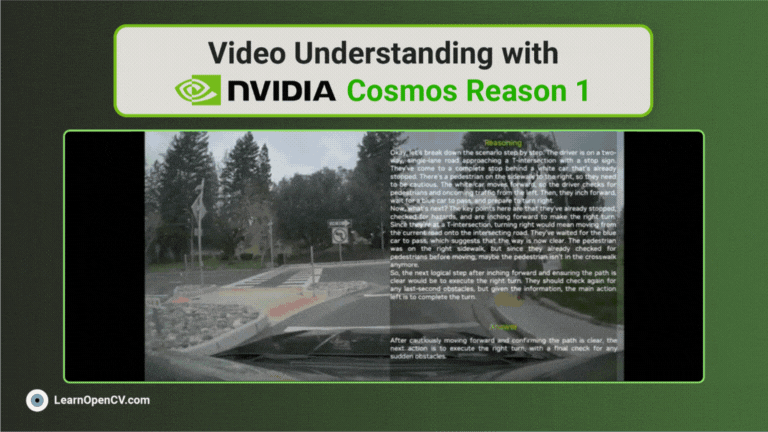
NVIDIA's Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender ...