



What is YOLOv8?
YOLOv8 is the latest family of YOLO based Object Detection models from Ultralytics providing state-of-the-art performance.
Leveraging the previous YOLO versions, the YOLOv8 model is faster and more accurate while providing a unified framework for training models for performing
- Object Detection,
- Instance Segmentation, and
- Image Classification.
As of writing this, a lot of features are yet to be added to the Ultralytics YOLOv8 repository. This includes the complete set of export features for the trained models. Also, Ultralytics will release a paper on Arxiv comparing YOLOv8 with other state-of-the-art vision models.
YOLO Master Post – Every Model Explained
Don’t miss out on this comprehensive resource, Mastering All Yolo Models for a richer, more informed perspective on the YOLO series.

YOLOv8 Architecture and What’s New in YOLOv8?
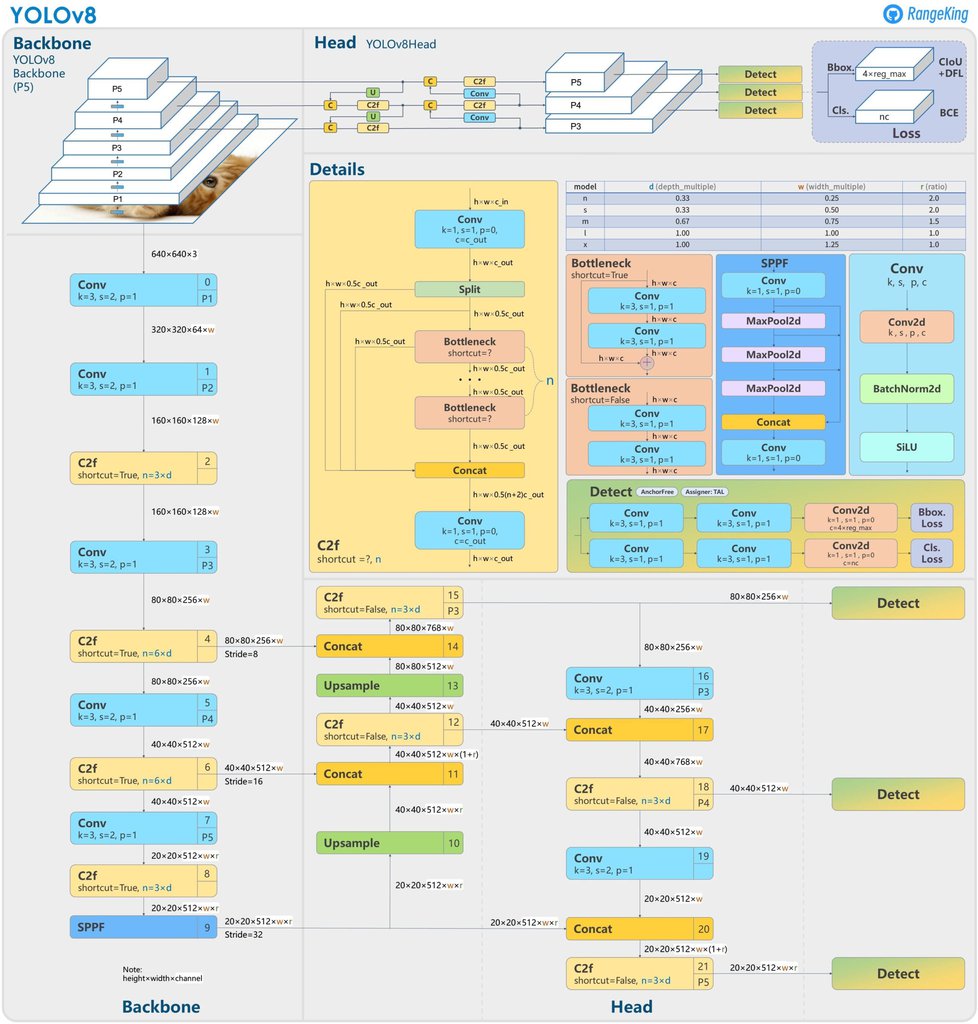
Ultralytics have released a completely new repository for YOLO Models. It is built as a unified framework for training Object Detection, Instance Segmentation, and Image Classification models.
Here are some key features about the new release:
- User-friendly API (Command Line + Python).
- Faster and More Accurate.
- Supports
- Object Detection,
- Instance Segmentation,
- Image Classification.
- Extensible to all previous versions.
- New Backbone network.
- New Anchor-Free head.
- New Loss Function.
YOLOv8 is also highly efficient and flexible supporting numerous export formats and the model can run on CPUs & GPUs.
On an architecture level, the following changes have been made according to this GitHub issue:
- The C3 modules have been replaced with C2f modules.
- The first 6×6 Conv has been replaced with 3×3 Conv in the Backbone.
- Usage of decoupled head and deletion of the Objectness branch.
- The first 1×1 Conv in Backbone has been replaced with 3×3 Conv.
Models Available in YOLOv8
There are five models in each category of YOLOv8 models for detection, segmentation, and classification. YOLOv8 Nano is the fastest and smallest, while YOLOv8 Extra Large (YOLOv8x) is the most accurate yet the slowest among them.
| YOLOv8n | YOLOv8s | YOLOv8m | YOLOv8l | YOLOv8x |
YOLOv8 comes bundled with the following pre-trained models:
- Object Detection checkpoints trained on the COCO detection dataset with an image resolution of 640.
- Instance segmentation checkpoints trained on the COCO segmentation dataset with an image resolution of 640.
- Image classification models pretrained on the ImageNet dataset with an image resolution of 224.
Let’s take a look at the output using the YOLOv8x detection and instance segmentation models.

How to Use YOLOv8?
Using the full potential of YOLOv8 requires installing the requirements from the repository as well as the ultralytics package.
To install the requirements, we need first to clone the repository.
git clone https://github.com/ultralytics/ultralytics.git
Next, install the requirements.
pip install -r requirements.txt
With the latest release, Ultralytics YOLOv8 provides both, a complete Command Line Interface (CLI) API and Python SDK for performing training, validation, and inference.
To use the yolo CLI, we need to install ultralytics package.
pip install ultralytics
How to use YOLOv8 using the command line interface (CLI)?
After installing the necessary packages, we can access the YOLOv8 CLI using the yolo command. Following is an example of running object detection inference using the yolo CLI.
yolo task=detect \
mode=predict \
model=yolov8n.pt \
source="image.jpg"
The task flag can accept three arguments: detect, classify, and segment. Similarly, the mode can be either of train, val, or predict. We can also pass the mode as export when exporting a trained model.
The following image shows all the possible yolo CLI flags and arguments.
How to use YOLOv8 using the Python API?
We can also create a simple Python file, import the YOLO module and perform the task of our choice.
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # load a pretrained YOLOv8n model
model.train(data="coco128.yaml") # train the model
model.val() # evaluate model performance on the validation set
model.predict(source="https://ultralytics.com/images/bus.jpg") # predict on an image
model.export(format="onnx") # export the model to ONNX format
For example, the above code will first train the YOLOv8 Nano model on the COCO128 dataset, evaluate it on the validation set and carry out prediction on a sample image.
Let’s use the yolo CLI and carry out inference using object detection, instance segmentation, and image classification models.

Inference Results for Object Detection using YOLOv8
The following command runs detection on a video using the YOLOv8 Nano model.
yolo task=detect mode=predict model=yolov8n.pt source='input/video_3.mp4' show=True
The inference runs at almost 105 FPS on a laptop GTX 1060 GPU. And we get the following output.
The YOLOv8 Nano model confuses the cats as dogs in a few frames. Let’s run detection on the same video using the YOLOv8 Extra Large model and check the outputs.
yolo task=detect mode=predict model=yolov8x.pt source='input/video_3.mp4' show=True
The Extra Large model runs at an average of 17 FPS on the GTX 1060 GPU.
Although the misclassifications are slightly less this time, still, the model is detecting the bench wrongly in a few of the frames.
Inference Results for Instance Segmentation using YOLOv8
Running inference using the YOLOv8 instance segmentation model is just as easy. We just need to change the task and the model name in the above command.
yolo task=segment mode=predict model=yolov8x-seg.pt source='input/video_3.mp4' show=True
Because instance segmentation is coupled with object detection, this time, the average FPS was around 13.
The segmentation maps appear pretty clean in the output. Even when the cat hides under the block in the last few frames, the model is able to detect and segment it.
Inference Results for Image Classification using YOLOv8
Finally, as YOLOv8 already provides pretrained classification models, let’s run classification inference on the same video using the yolov8x-cls model. This is the largest classification model that the repository provides.
yolo task=classify mode=predict model=yolov8x-cls.pt source='input/video_3.mp4' show=True
By default, the video is annotated with the top-5 classes that the model predicts. Without any post-processing the annotations directly match the ImageNet class names.
Human Pose Estimation using YOLOv8
The latest YOLOv8 family of models also includes pose estimation models which can detect human keypoints with extreme accuracy. You can run human pose estimation on a video using the following command.
yolo task=pose mode=predict model=yolov8x-pose.pt source=video.mp4 show=True
Following is the output video.
Not only that, we can also fine tune YOLOv8 pose models for animal keypoint detection.
YOLOv8 vs YOLOv7 vs YOLOv6 vs YOLOv5
Right away, YOLOv8 models seem to perform much better compared to the previous YOLO models. Not only YOLOv5 models, YOLOv8 is ahead of the curve against YOLOv7 and YOLOv6 models also.

When compared with other YOLO models trained at 640 image resolution, all the YOLOv8 models have better throughput with a similar number of parameters.
Now, let’s take a detailed view of how the latest YOLOv8 models perform in comarison with the YOLOv5 models from Ultralytics. The following tables show a comprehensive comparison between YOLOv8 and YOLOv5.
Overall Comparison
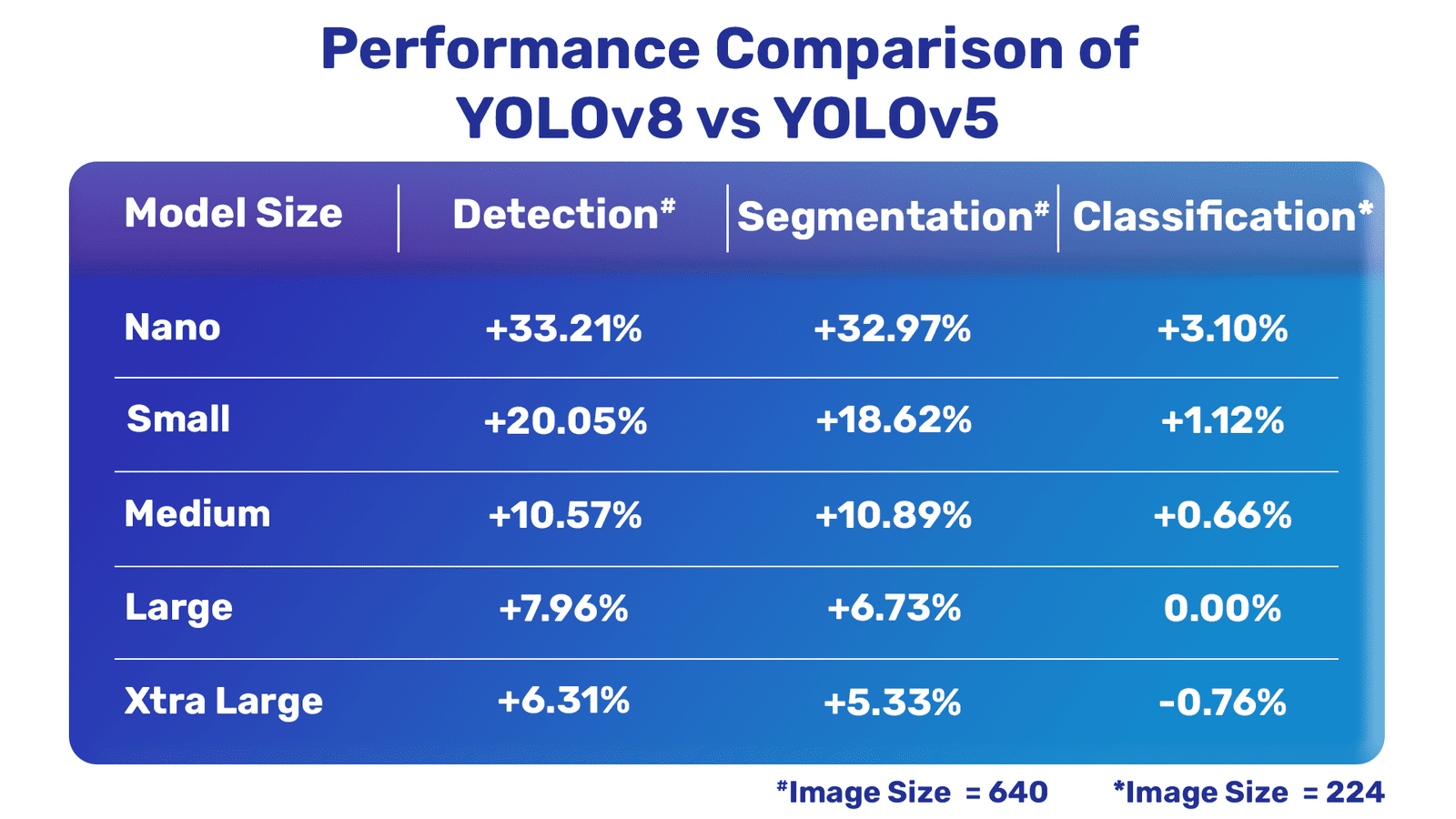
Object Detection Comparison

Instance Segmentation Comparison
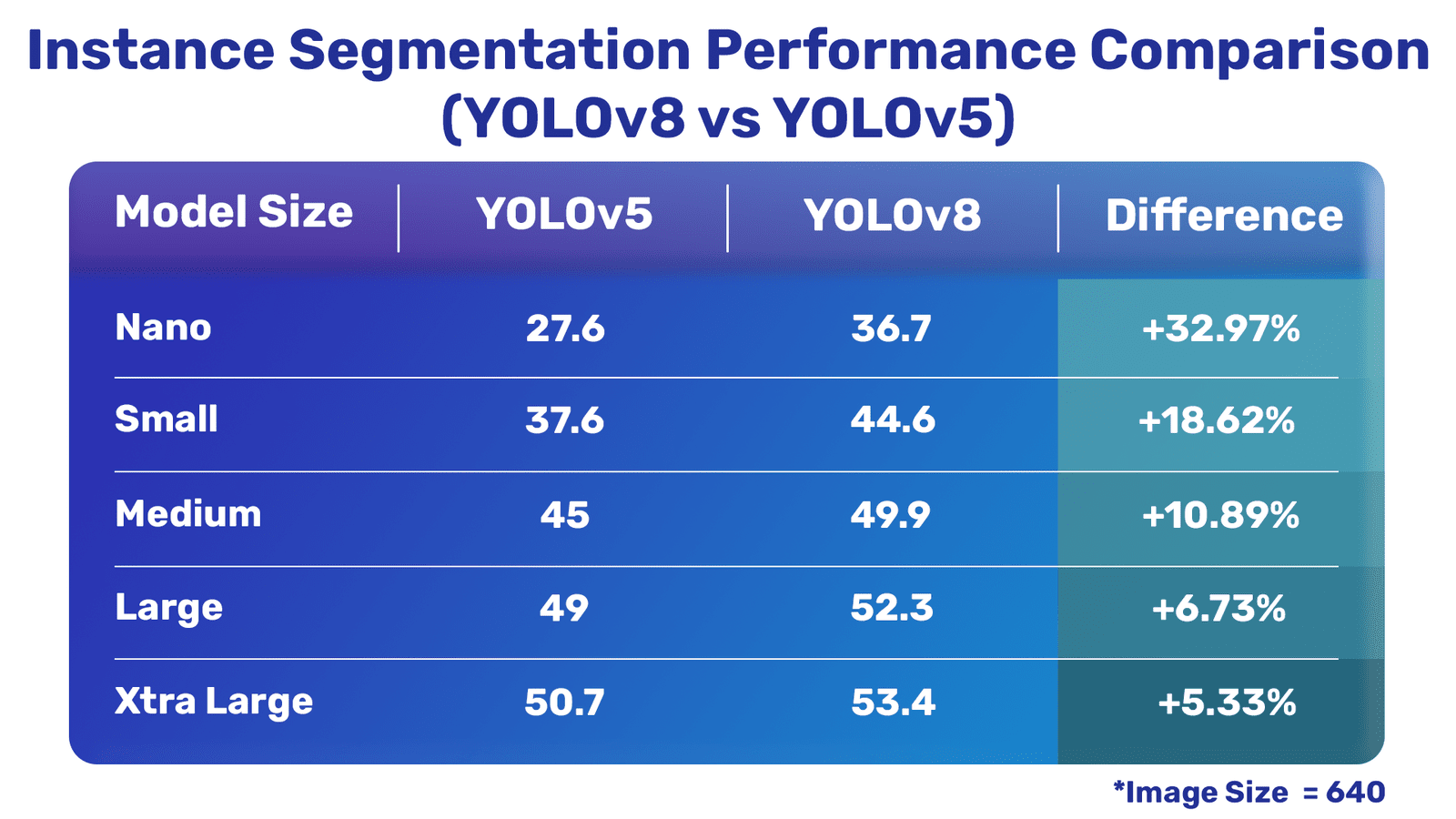
Image Classification Comparison
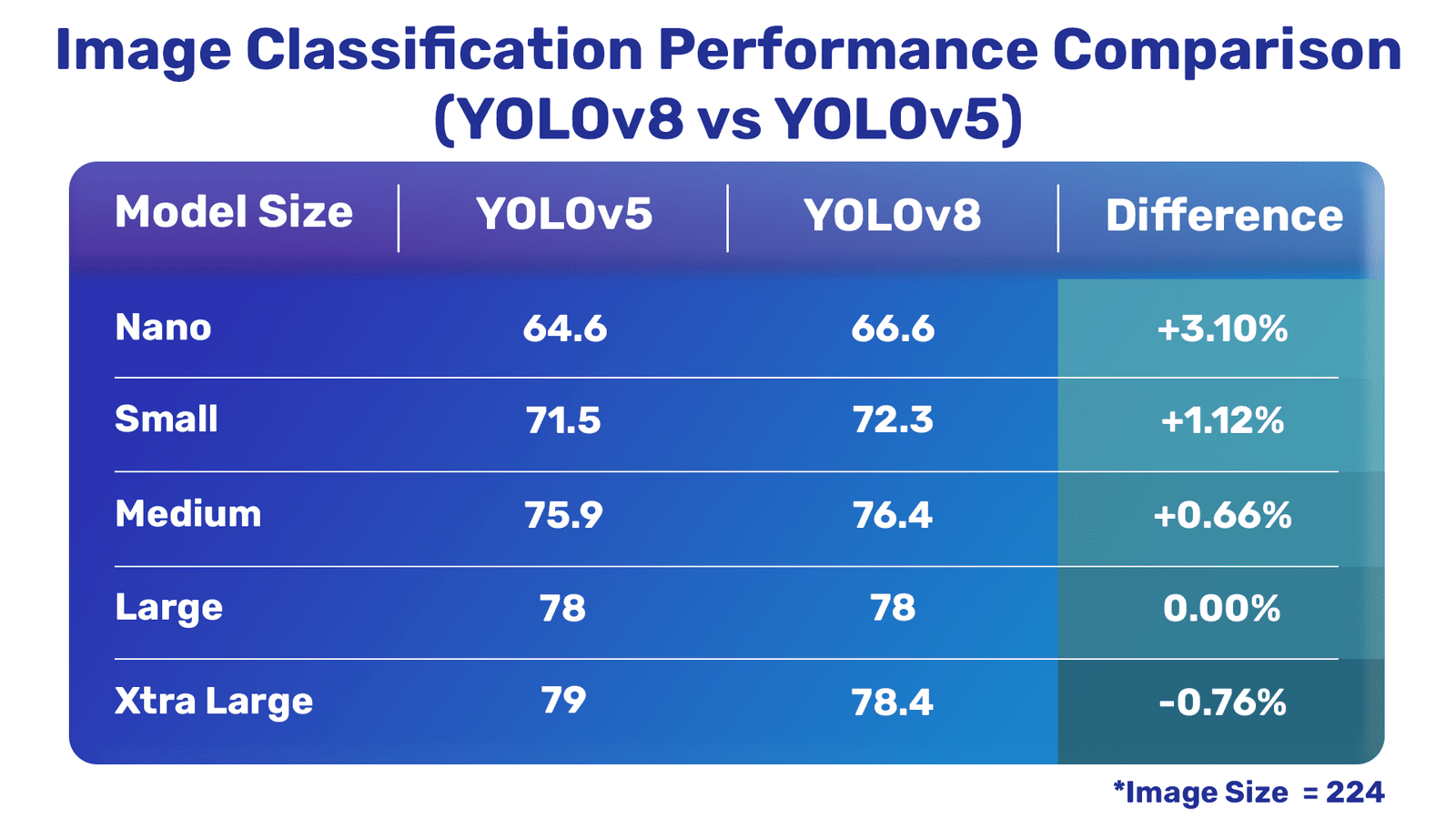
It is clear that the latest YOLOv8 models are much better compared to YOLOv5 except for one of the classification models.
Evolution of YOLOv8 Object Detection Model
Here is an image showing the timeline of YOLO object detection models and how the evolution of YOLOv8 happened.
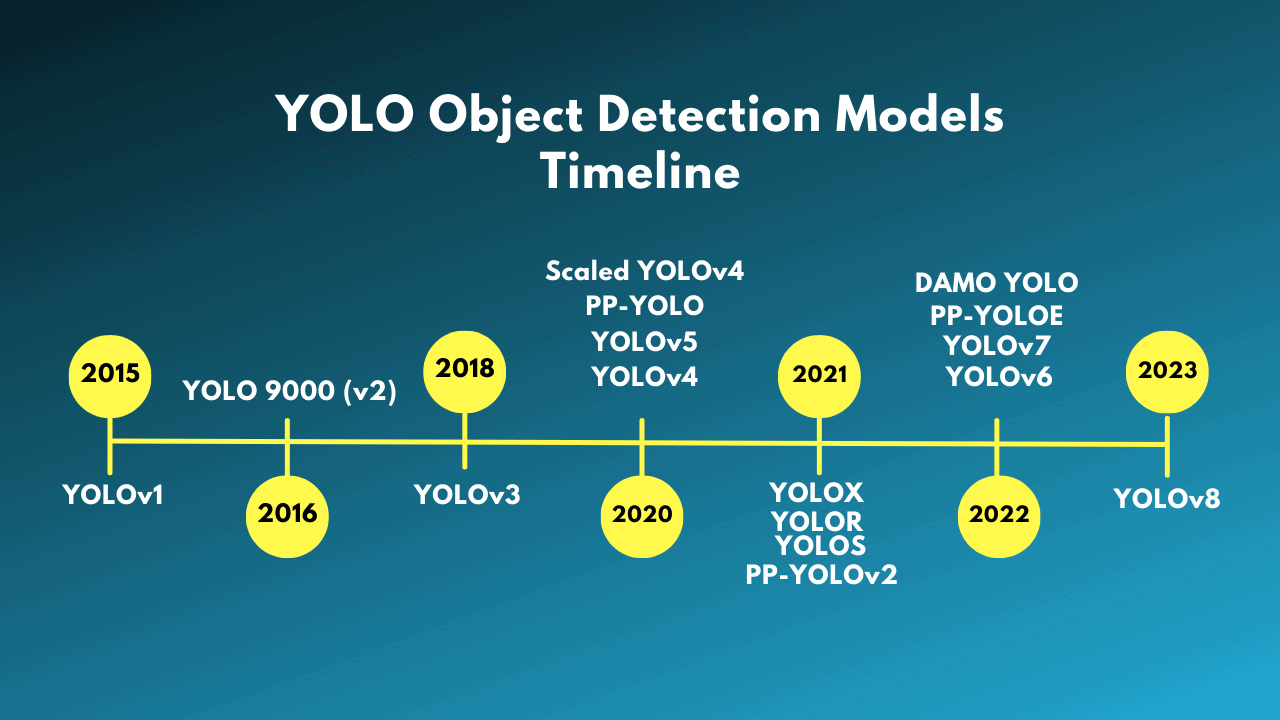
YOLOv1
The very first version of YOLO object detection, that is YOLOv1 was published by Joseph Redmon et al. in 2015. It was the first single stage object detection (SSD) model which gave rise to SSDs and all of the subsequent YOLO models.
YOLO 9000 (v2)
YOLOv2, also known as YOLO 9000 was published by the original YOLOv1 author, Joseph Redmon. It improved upon YOLOv1 by introducing the concept of anchor boxes and a better backbone, that is Darknet-19.
YOLOv3
In 2018, Joseph Redmon and Ali Farhadi published YOLOv3. It was less of an architectural leap and more of a technical report, but a big improvement in the YOLO family nonetheless. YOLOv3 uses the Darknet-53 backbone, residual connections, better pretraining, and image augmentation techniques to bring in improvements.
Ultralytics YOLO Object Detection Models
All the YOLO object detection models till YOLOv3 were written using the C programming language and used the Darknet framework. Newcomers find it difficult to traverse the codebase and fine-tune the models.
Around the same time as YOLOv3, Ultralytics released the first ever YOLO (YOLOv3) implemented using the PyTorch framework. It was much more accessible and easy to use for transfer learning as well.
Shortly after publishing YOLOv3, Joseph Redmon stepped away from the Computer Vision research community. YOLOv4 (by Alexey et al.) was the last YOLO model to be written in Darknet. After that, there have been many YOLO object detections. Scaled YOLOv4, YOLOX, PP-YOLO, YOLOv6, and YOLOv7 are some of the prominent among them.
After YOLOv3, Ultralytics also released YOLOv5 which was even better, faster, and easier to use than all other YOLO models.
As of now (January 2023), Ultralytics published YOLOv8 under the ultralytics repository which is perhaps the best YOLO model till date.
Conclusion
In this article, we explored the latest installment of YOLO models, i.e., YOLOv8. We covered the new models, their performance, and also the command line interface that comes with the package. Along with that, we also carried inference on videos.
In future posts, we will also fine-tune the YOLOv8 models on a custom dataset.
Let us know in the comment section if you carry out any experiments of your own.
In case you missed it, here’s the complete list of posts from our YOLO series:
- YOLOR Paper Explanation and Comparison
- YOLOv6 Custom Training for Underwater Trash Detection
- YOLOv6 Object Detector Paper Explanation and Inference
- YOLOX Object Detector and Custom Training on Drone Dataset
- YOLOv7 Object Detector Training on Custom Dataset
- YOLOv7 Object Detector Paper Explanation and Inference
- YOLOv5 Custom Object Detector Training on Vehicles Dataset
- YOLOv5 Object Detection using OpenCV DNN
- YOLOv4 – Training a Custom Pothole Detector

