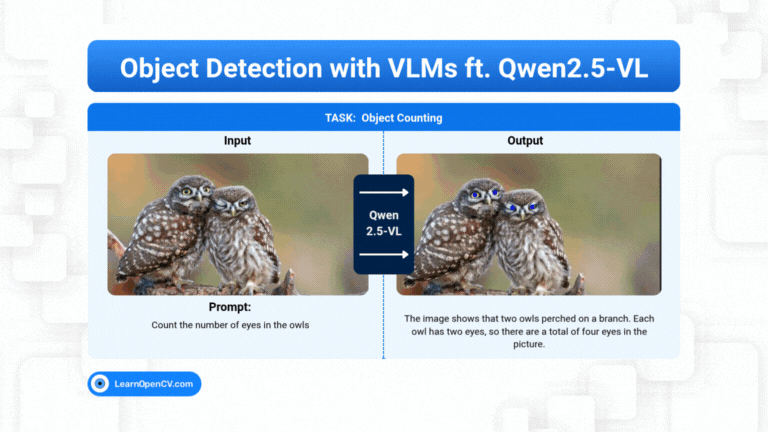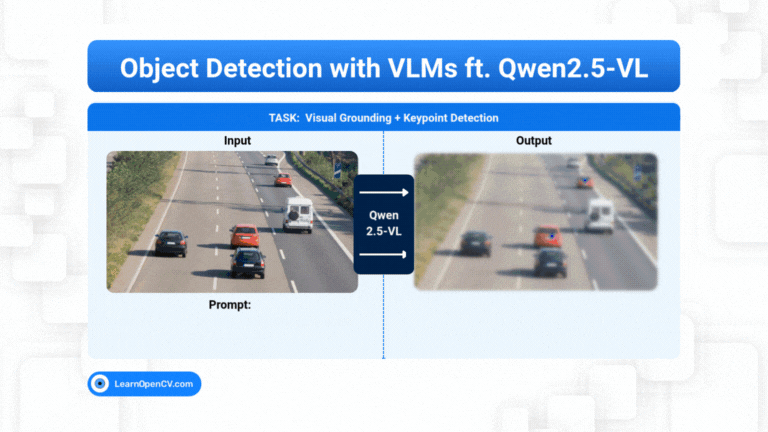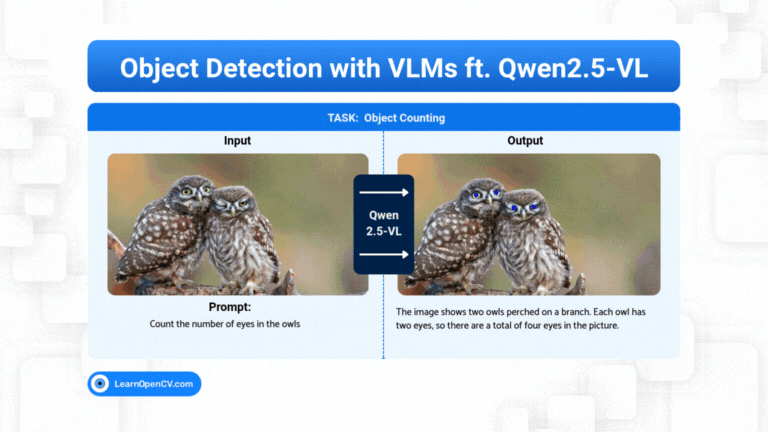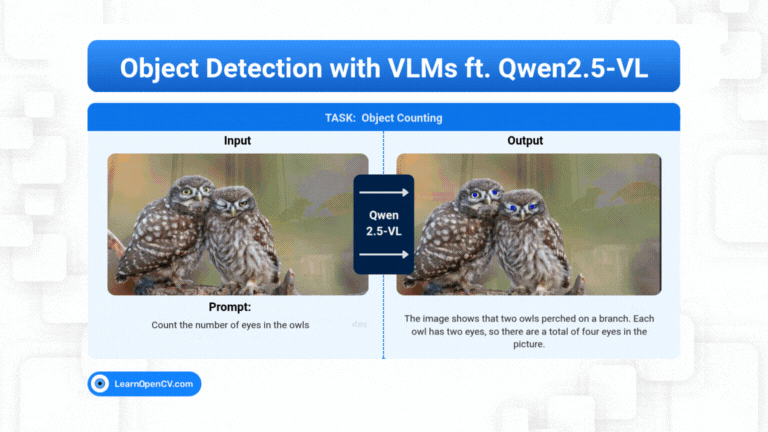
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on CARLA Leaderboard 2.0 and
Fine-Tuning Gemma 3 allows us to adapt this advanced model to specific tasks, optimizing its performance for domain-specific applications. By leveraging QLoRA (Quantized Low-Rank Adaptation) and Transformers, we can efficiently
Gemma 3 is the latest addition to Google’s family of open models, built from the same research and technology used to create the Gemini models. It is designed to be
Molmo VLM is an open-source Vision-Language Model (VLM) showcasing exceptional capabilities in tasks like pointing, counting, VQA, and clock face recognition. Leveraging the meticulously curated PixMo dataset and a well-optimized