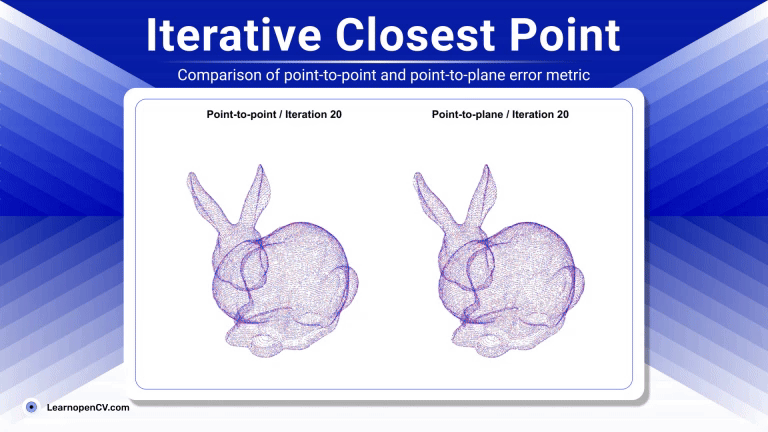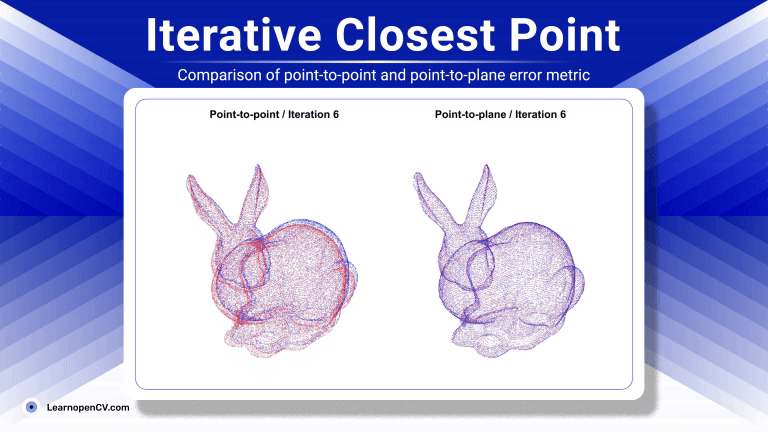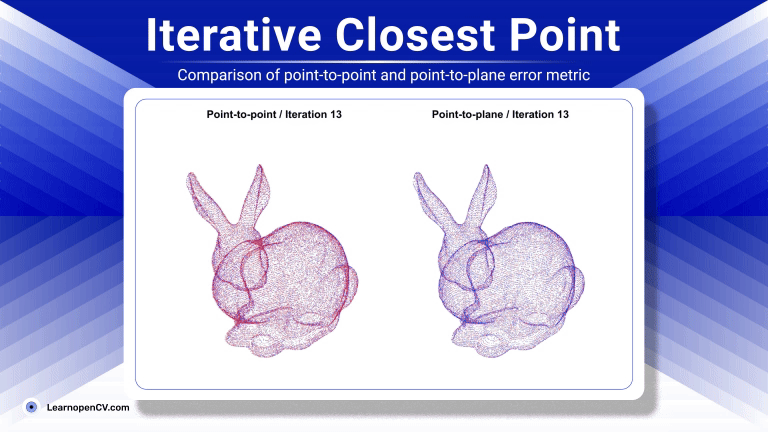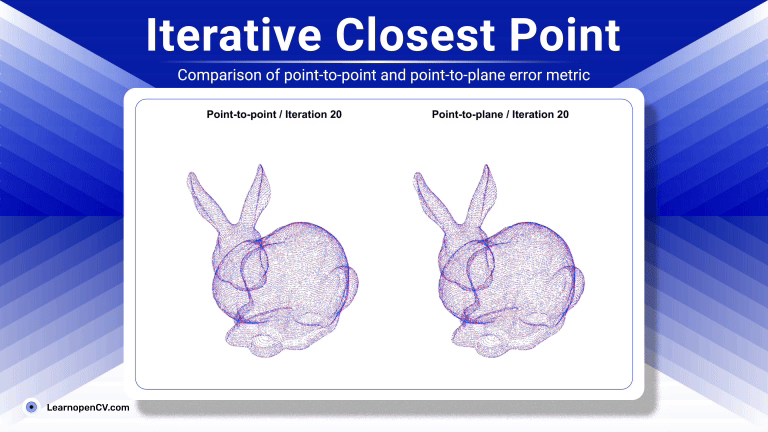
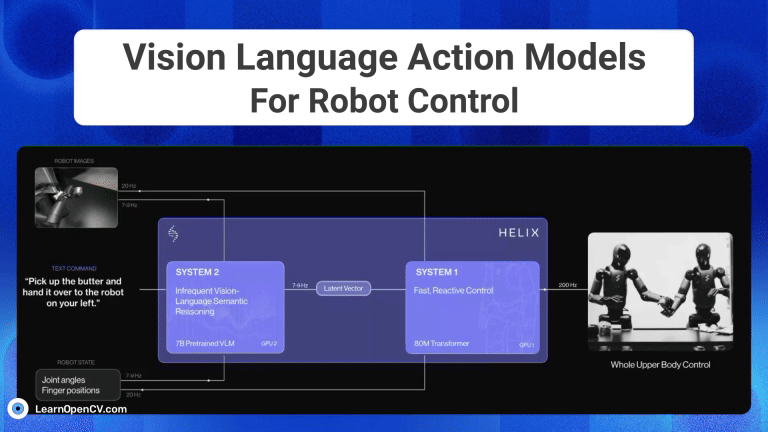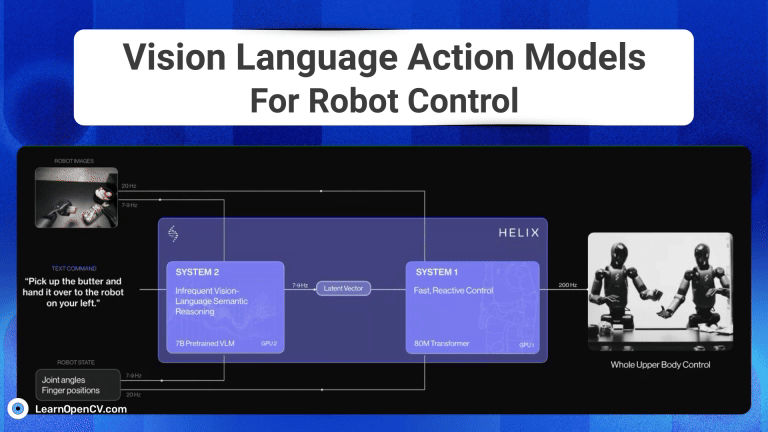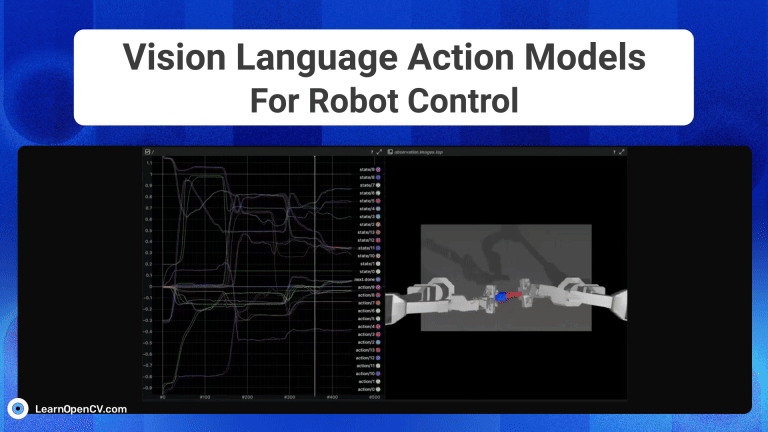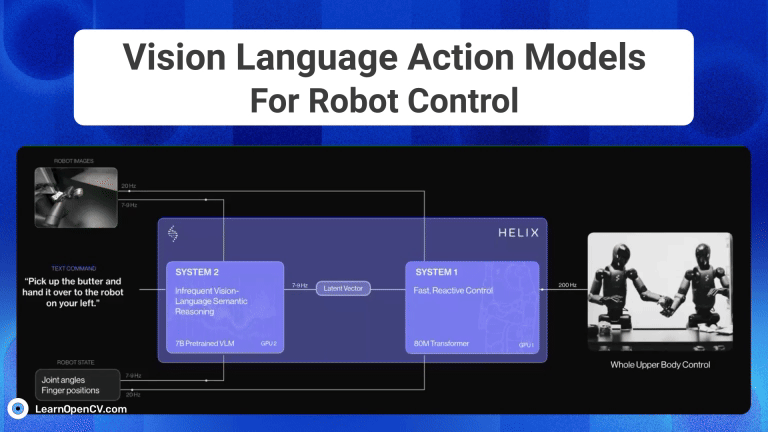
Imagine you're a robotics enthusiast, a student, or even a seasoned developer, and you've been captivated by the idea of robots that can see, understand our language, and then act on that ...
SmolVLA: Affordable & Efficient VLA Robotics on Consumer GPUs
June 5, 2025
1 Comment