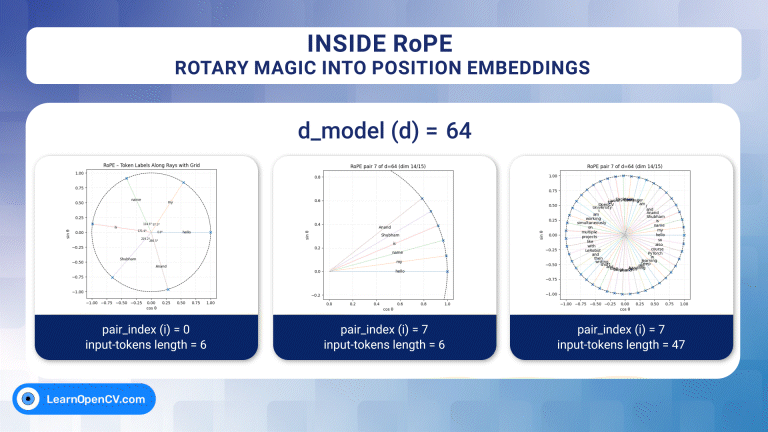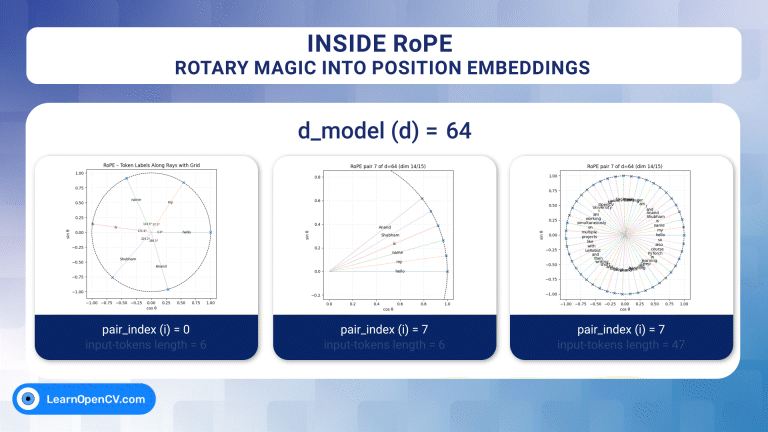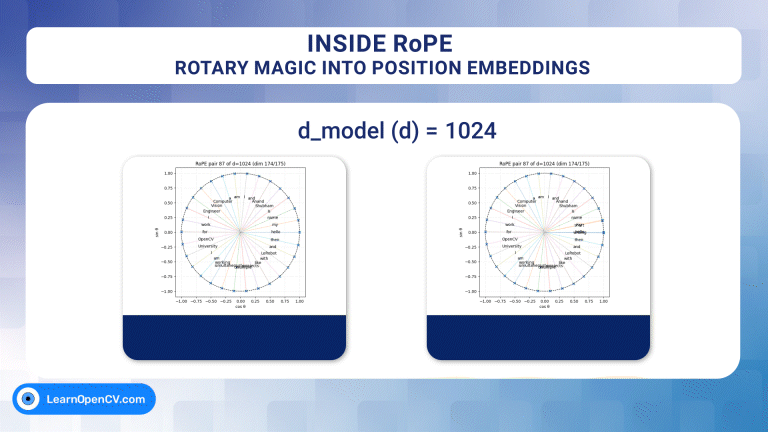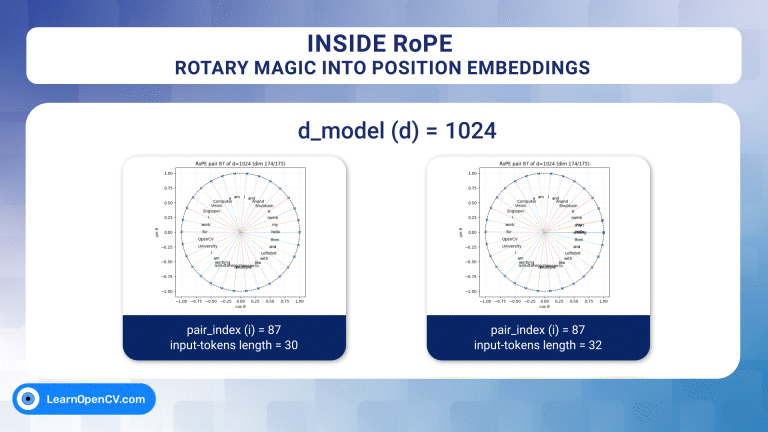
Welcome to the second part of our series on vision transformer. In the previous post, we introduced the self-attention mechanism in detail from intuitive and mathematical points of view. We also ...
The Future of Image Recognition is Here: PyTorch Vision Transformers
February 13, 2023
6 Comments