




If you’ve ever watched two toddlers swap toys without an adult translating (“Truck!” … “Dino!” … trade accepted), you’ve glimpsed the vision behind Google’s A2A Protocol. ...
Search Results for: c
RF-DETR by Roboflow: Speed Meets Accuracy in Object Detection

Object detection has come a long way, especially with the rise of transformer-based models. RF-DETR, developed by Roboflow, is one such model that offers both speed and accuracy. Using Roboflow’s ...
Vision Language Action Models (VLA) Overview: LeRobot Policies Demo
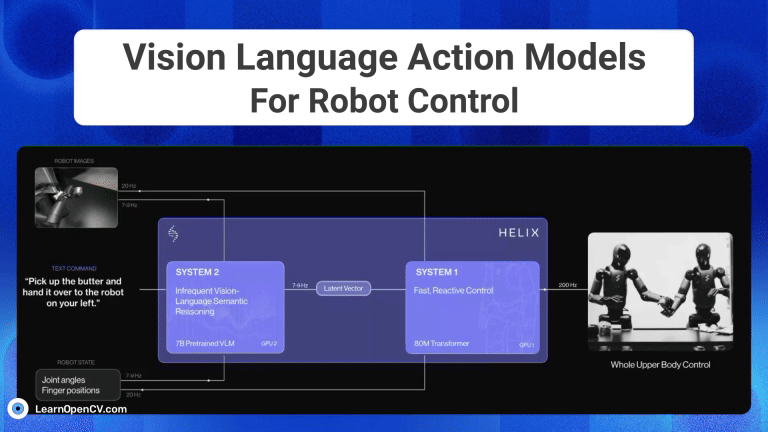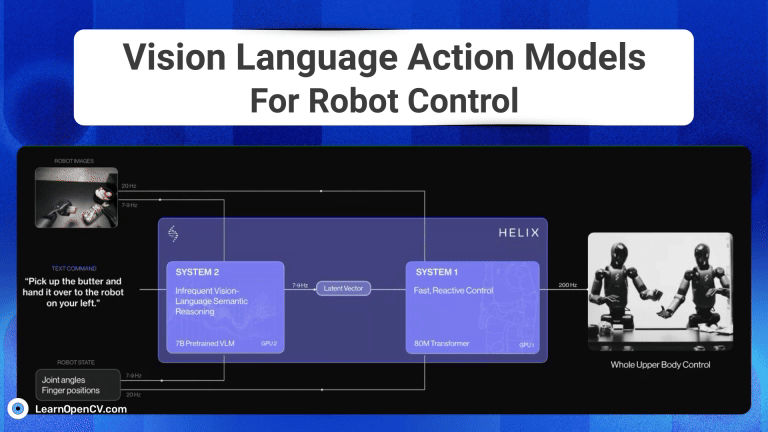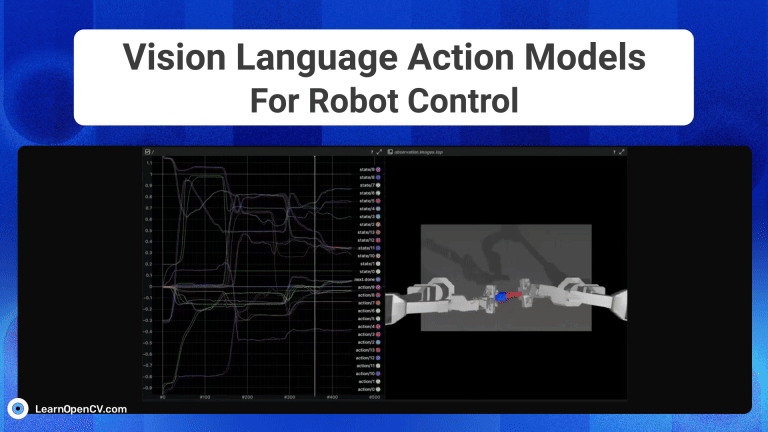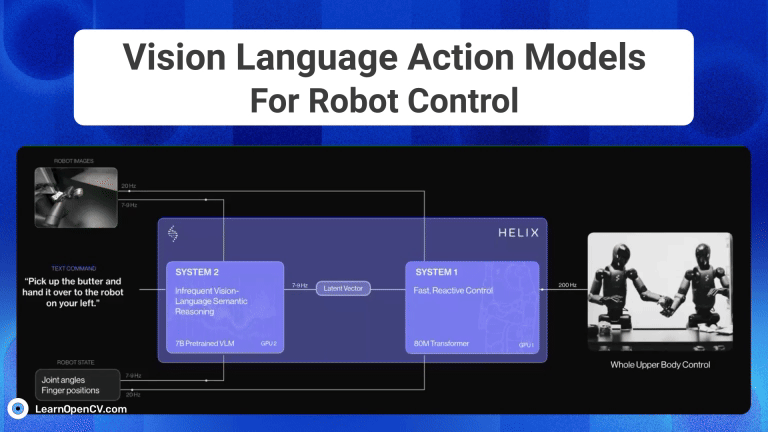
The advent of Generative AI, has fundamentally transformed robotic intelligence, enabling significant strides in how advanced humanoid robots "perceive, reason and act" in the physical world. This ...
Fine-Tuning Gemma 3 VLM using QLoRA for LaTeX-OCR Dataset

Fine-Tuning Gemma 3 allows us to adapt this advanced model to specific tasks, optimizing its performance for domain-specific applications. By leveraging QLoRA (Quantized Low-Rank Adaptation) and ...
Diving into the Nodes: An Introduction to ComfyUI for Stable Diffusion

ComfyUI – a powerful, node-based graphical user interface (GUI) that offers flexibility and transparency when working with stable diffusion models. This article provides an introduction to ComfyUI, ...
Introduction to GPT-4o Image Generation – Here’s What You Need to Know

OpenAI finally introduced GPT-4o image generation in ChatGPT and SORA. GPT-4o (omni) is a multimodal AI model; it can interact with different modalities like text, images, and audio, enabling far more ...

