




The domain of video understanding is rapidly evolving, with models capable of interpreting complex actions and interactions within video streams. Meta AI's VJEPA-2 (Video Joint Embedding Predictive ...
Search Results for: c
V-JEPA 2: Meta’s Breakthrough in AI for the Physical World

The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride toward this vision ...
VLM for Video Understanding with Spatial and Temporal Context: NVIDIA Cosmos Reason1
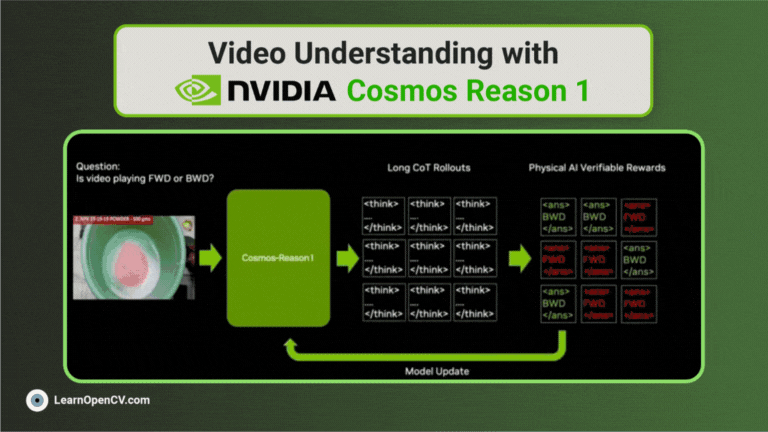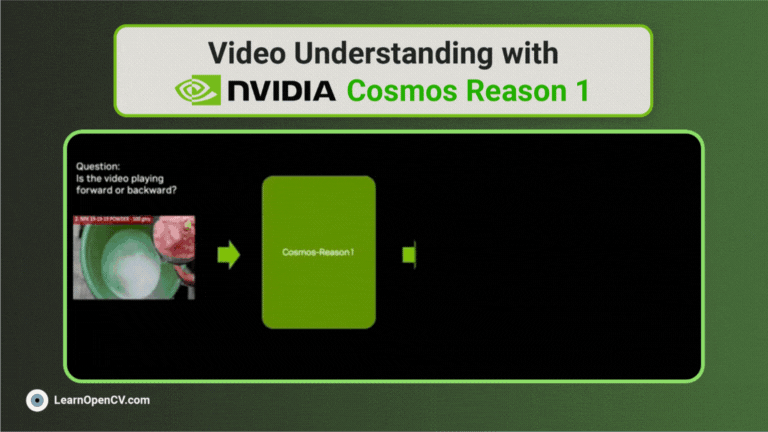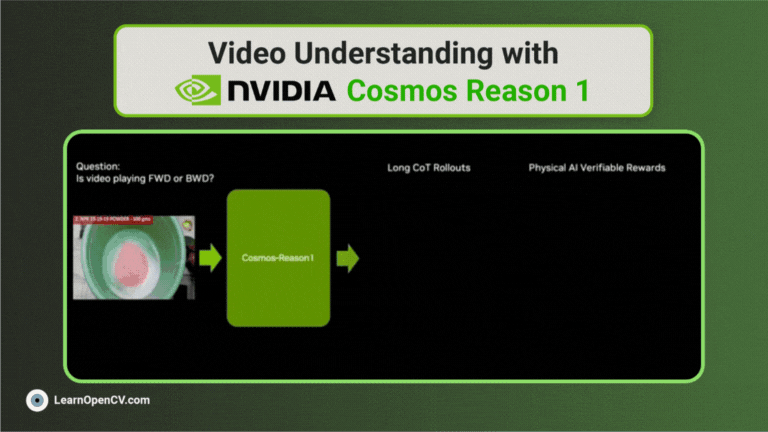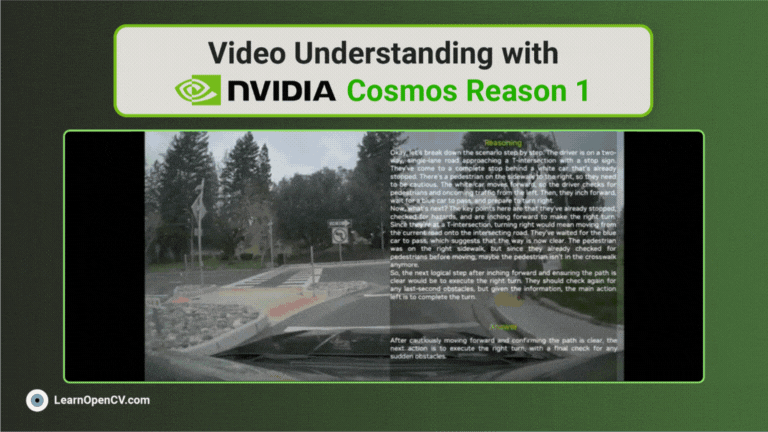
NVIDIA's Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender ...
The Definitive Guide to LLaVA: Inferencing a Powerful Visual Assistant

To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the focus of ...
SmolVLA: Affordable & Efficient VLA Robotics on Consumer GPUs

Imagine you're a robotics enthusiast, a student, or even a seasoned developer, and you've been captivated by the idea of robots that can see, understand our language, and then act on that ...
Fine-Tuning Grounding DINO: Open-Vocabulary Object Detection

Object detection has traditionally been a closed-set problem: you train on a fixed list of classes and cannot recognize new ones. Grounding DINO breaks this mold, becoming an open-set, ...

