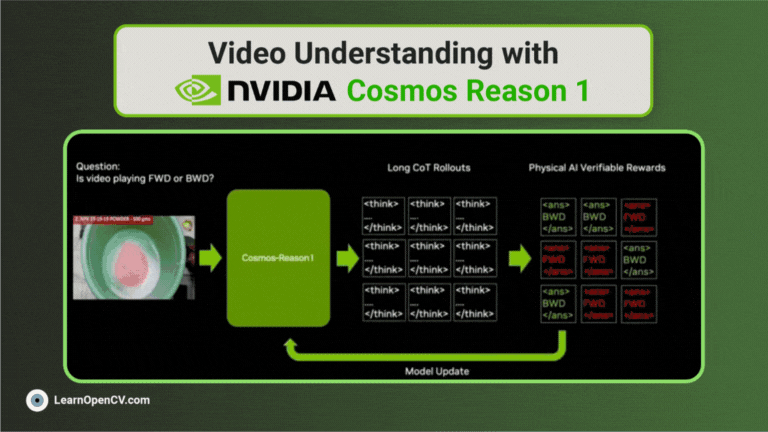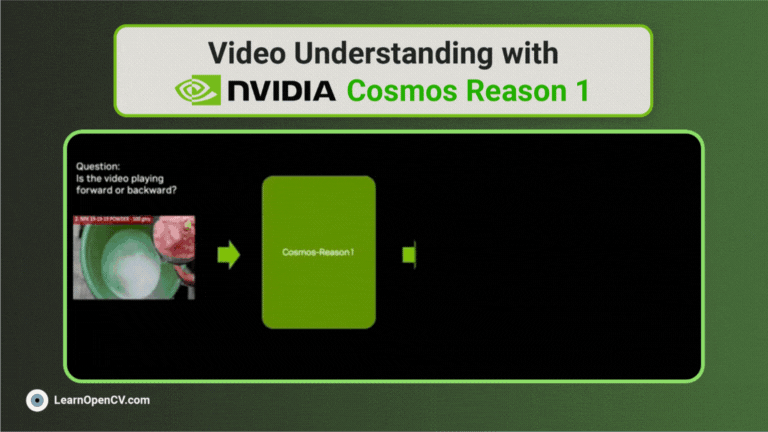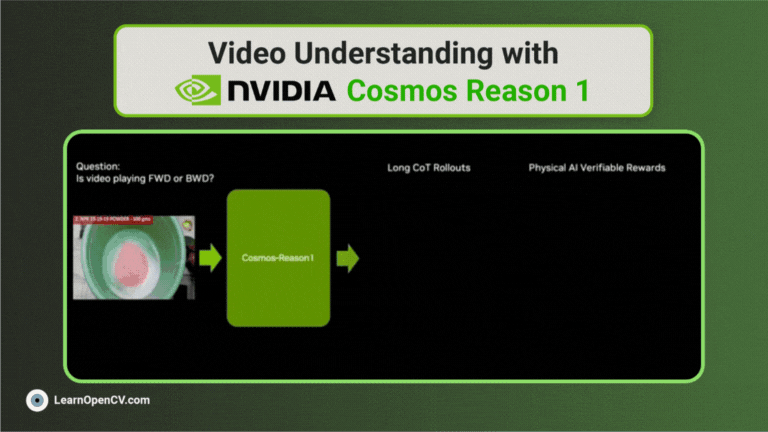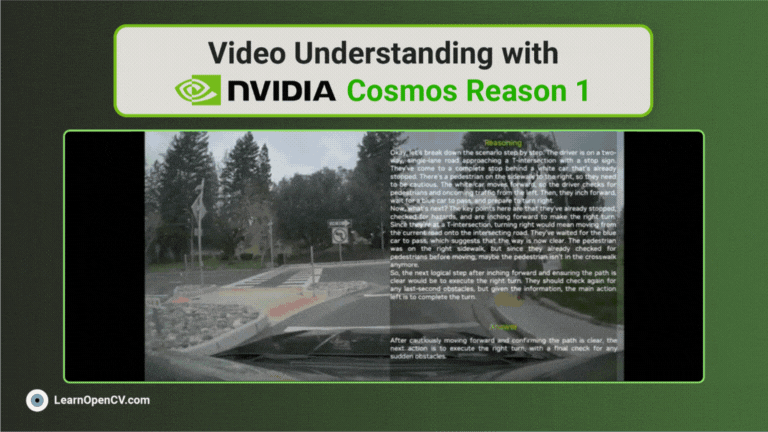
Traditional Optical Character Recognition (OCR) systems are primarily designed to extract plain text from scanned documents or images. While useful, such systems often ignore semantic structure, ...
Nanonets-OCR-s: Enabling Rich, Structured Markdown for Document Understanding
June 23, 2025
1 Comment