

Molmo VLM is an exceptional open-source family of Vision-Language models, demonstrating remarkable strengths in tasks like Pointing, Counting, VQA and clock face recognition. What sets Molmo apart from other open-source VLMs is its unique approach to pretraining. Instead of relying solely on synthetic datasets generated by proprietary models like GPT-4 or Claude, Molmo leverages the meticulously curated PixMo dataset.

Combined with a well-optimized VLM training pipeline, the dataset not only enhances Molmo’s performance but also serves as a blueprint for the open-source community, showcasing how to create high-quality multimodal datasets from the ground up and inspiring future advancements toward even better models.
The topics discussed are outlined as follows,
- Pointers from Molmo VLM paper
- Code Walkthrough – Molmo Points + SAM2 Segmentation
- Testing Molmo VLM on tasks like Pointing, OCR and VQA.
- Limitations and Failure Cases of Molmo VLM
This is the sixth article in our Mastering LLMs series. If you’re just getting started with LLMs and their applications, be sure to check out our other articles in this series for comprehensive understanding.
Individuals working on integrating Multimodal LLM’s in Robotics and VR applications will find the demo applications section to be very interesting.
- What makes Molmo VLM stand out?
- PixMo Dataset: The Key Factor
- Molmo Architecture
- Code Walkthrough
- Failure Cases and Limitations
- Key Takeaways
- Conclusion
What makes Molmo VLM stand out?
Small is the new big, less is the new more
The Multimodal Open Language Model (Molmo) from AllenAI (Ai2) highlights to the open-source community how model design choices and training data, shape the response quality of Vision-Language Models (VLMs).
Molmo outperforms VLMs that are 10x its size and stands as the state-of-the-art open-source VLM, as of 2024 achieving the highest score on the ELO rankings. Instead of relying on any type of RLHF (Reinforcement Learning with Human Feedback), the authors included specific instances within the dataset itself to help the model avoid false positives in images, enabling more accurate object understanding.

One aspect of Molmo that caught our attention is its unique pointing and clock face reading capability, showcased in the Molmo announcement blog post by Ai2. This is largely credited to its high-quality labeled dataset, achieved through supervised fine-tuning across different PixMo categories using pre-trained vision and language backbones.
PixMo Dataset: The Key Factor
High-quality, well-understood, auditable data is priceless.
– Ted Friedman, VP, Gartner
The Pixels for Molmo (PixMo) dataset consists of several categories, including a curated subset annotated by human experts (PixMo Annotated) and synthetic datasets generated using text-only LLMs (PixMo Synthetic).

- PixMo-Captions and PixMo-CapQA : The captioning dataset was prepared using an effective approach involving audio transcripts from a group of annotators, who described each image within 60–90 seconds for 712k images that were sampled from 70 diverse topics. This method produced richer captions in less time compared to typing, which often misses subtle nuances in the image. Then using an LLM the transcripts are filtered and normalized to obtain on average 200+ words dense descriptions. From generated captions, QA pairs were prepared using an LLM to query over image captions.
- PixMo-Points: For pointing tasks, points on relevant pixels were used as object references instead of creating segmentation masks or bounding box annotations. This clever approach significantly saves time enabling more (2.3 M) annotated instances.
- PixMo-Docs: Proprietary LLMs like Claude were used to synthetically generate graphs, charts, and plots with matplotlib, aiding in the understanding of unstructured document elements.
- PixMo-Clocks: PixMo-Clocks is a curated collection of virtual watch faces and time annotations, designed to enhance Molmo’s ability to accurately read time from analog clocks. Unlike GPT-4o, which struggles with such tasks, Molmo delivers precise time readings, making it a standout feature.
The image below summarizes how both the synthetic and annotated PixMo dataset enhances Molmo VLM capabilities particularly tasks like Pointing, Spatial Understanding and clock face reading.

Molmo Architecture

Molmo comprises of four main components:
- Pre-processor: Processes image into multi square crops at different scales.
- Image encoder (CLIP): Encodes patches features as embeddings.
- Connector: Projects patch embeddings into LLM embedding space. Additionally pooling is applied to each 2×2 patch window to reduce dimensionality without losing the spatial context. It is pre-trained with a higher learning rate and a warmup start, allowing the connector parameters to adjust quickly.
- LLM decoder: The input query is tokenized and concatenated with image embeddings, and passed to the LLM decoder to generate response.
Model Variants:
| Variant | Vision Encoder | LLM |
| MolmoE-1B | ViT-L/14 336px CLIP | OLMoE-1B-7B |
| Molmo-7B-O | ViT-L/14 336px CLIP | OLMo-7B |
| Molmo-7B-D | ViT-L/14 336px CLIP | Qwen2 7B |
| Molmo-72B | ViT-L/14 336px CLIP | Qwen2 72B |
To improve Molmo on fine-grained tasks like OCR and captioning the input image is preprocessed as follows,
Multi-Scale:
- The raw image is resized or padded to the vision encoder’s supported resolution (336 × 336), which aids in capturing the overall context at a lower resolution.
Multi-Crops:
- Before being passed to the vision encoder, the input image is divided into multiple overlapping crops, with each crop overlapping by 56 pixels or 4 patches. This overlap helps retain the context of nearby patches. However, patches from these overlapping crops are not passed to the connectors or the LLM. This ensures a consistent number of image tiles and prevents repeated instances of the same patch in the processing pipeline.

To encode the image as crops, a maximum number of crops (typically 12) is specified. If the image cannot accommodate that many crops, it is resized to fit within a grid with black padding, while maintaining its aspect ratio. To distinguish the padded pixels from naturally black pixels in the image, a learned embedding is used. Each crop consists of 144 patches, arranged in a 12×12 grid per crop.

The low-res image is placed at the beginning, followed by high-res crops, separated by special tokens (<im_start>, <im_end>), and then passed as patch sequences to the ViT. Each crop is processed independently by the ViT, with additional tokens (<im_col>) indicating the row transitions.
During pretraining, applying dropout to text-only tokens significantly enhanced Molmo’s downstream capabilities by encouraging the model to rely more on image pixels rather than language priors. A length hint along with the prompt improves the caption quality guiding the model’s output length.
Experimental testing from paper suggests that encoding point coordinates as plain text, (e.g., <point x="10.0" y="10.0" alt="alt text">Inline text</point>), works best. During inference, use the keyword “Point” to trigger Molmo for pointing tasks.
“To make Molmo point it right, do prompt it right”.
What we mean by that, is adding subtle cues in the prompt makes a huge difference in the response quality of Molmo’s points. But you may wonder how to craft the optimal prompt query.
First, ask the model to describe the image in detail. Review its response, from that interpret what actually the model’s understanding about the image. Based on this, you can come up with a better prompting style and technique. We will cover several examples to know the right prompting techniques.
While this isn’t unique to Molmo, the effectiveness of a prompt plays a crucial role in achieving responses with better precision and recall.

Code Walkthrough of Molmo VLM Inference on Downstream Tasks
Installing Dependencies
!pip install transformers opencv-python einops torchvision accelerate bitsandbytes matplotlib
import os
import logging
from datetime import datetime
import warnings
import cv2
import requests
import re
import numpy as np
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
from transformers import (
AutoModelForCausalLM,
AutoProcessor,
GenerationConfig,
BitsAndBytesConfig,
)
# Suppress warnings
warnings.filterwarnings("ignore")
os.makedirs("Molmo_pts", exist_ok=True)
Based on the type of input, whether it is a file path or URL, the image is read and converted into a NumPy array.
def read_image_url(image_url):
response = requests.get(image_url)
image_pil = Image.open(BytesIO(response.content))
image_np = np.array(image_pil)
return image
def read_image(path):
image = cv2.imread(path)
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
return rgb_image
path = "input_images/dog.jpg"
img_path = os.path.join(os.getcwd(), path)
if image_url:
ip_img = read_image_url(image_url)
else:
ip_img = read_image(img_path)
We will be testing the MolmoE-1B-0924 model locally on an RTX3080 Ti system equipped with an i7 13th Gen processor. The MolmoE-1B-0924 is a Mixture of Experts (MoE) model with 1.2 billion active parameters out of a total of 6.9 billion. Its LLM MLP layers employ 64 experts, with 8 active at any given time.
model_id = "allenai/MolmoE-1B-0924" #allenai/Molmo-7B-D-0924 ,
To fit the model within the available GPU setup, it is loaded using normalized 4-bit float precision with BitsAndBytes, occupying ~5.8GB of VRAM.
quant_config = BitsAndBytesConfig(
load_in_4bit=True, bnb_4bit_quant_type="nf4", bnb_4bit_use_double_quant=False
)
def load_model(
model_id, quant_config: BitsAndBytesConfig = None, dtype="auto", device="cuda"
):
# Load the processor
processor = AutoProcessor.from_pretrained(
model_id, trust_remote_code=True, torch_dtype="auto", device_map=device
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=dtype,
device_map=device,
quantization_config=quant_config,
)
return model, processor
model, processor = load_model(
model_id, quant_config=quant_config, dtype="auto", device="cuda"
)
As usual, to use any VLM with the Transformers pipeline, the image is preprocessed into the expected format required by the model. The MolmoProcessor resizes the image to a 336×336 square with a patch size of 14. Additionally, as noted earlier, the image is divided into up to 12 crops with an overlap of 4 pixels for further processing.
MolmoProcessor:
- image_processor: MolmoImageProcessor {
"auto_map": {
"AutoImageProcessor": "allenai/MolmoE-1B-0924--image_preprocessing_molmo.MolmoImageProcessor",
"AutoProcessor": "allenai/MolmoE-1B-0924--preprocessing_molmo.MolmoProcessor"
},
"base_image_input_size": [336, 336],
"do_normalize": true,
"image_mean": [0.48145466, 0.4578275, 0.40821073],
"image_std": [0.26862954, 0.26130258, 0.27577711],
"image_padding_mask": true,
"image_patch_size": 14,
"image_processor_type": "MolmoImageProcessor",
"image_token_length_h": 12,
"image_token_length_w": 12,
"max_crops": 12,
"overlap_margins": [4, 4],
"processor_class": "MolmoProcessor"
}
Next, we define a simple wrapper function that accepts the user’s query and an input image array, processes them, and returns the generated output text from the Molmo model. The inputs are passed as a dictionary of batches to the model, with the maximum generation token length set to 2048 (or any value of your choice).
def molmo_answer(query_text, input_img):
inputs = processor.process(images=input_img, text=query_text)
# Move inputs to the correct device and create a batch of size 1
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
# Generate output; maximum 2048 new tokens; stop generation when <|endoftext|> is generated
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=2048, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer,
)
# Only get generated tokens; decode them to text
generated_tokens = output[0, inputs["input_ids"].size(1) :]
generated_text = processor.tokenizer.decode(
generated_tokens, skip_special_tokens=True
)
return generated_text
A simple utility function to extract the (x, y) coordinates of points from the generated text is defined. Molmo provides these point values as strings normalized between 0 and 100. A sample output text will look like:
<points x1=”93.5″ y1=”29.8″ x2=”93.5″ y2=”38.1″ x3=”93.5″ y3=”45.4″ x4=”93.5″ y4=”53.1″ x5=”93.5″ alt=”person”>person</points>
Using a specific regex pattern for single or multiple points, that we identified with GPT’s assistance, the function extracts the normalized points and rescales them to the image’s original dimensions (Height × Width). This ensures precise localization of points on the input image.
def get_coords(image, generated_text):
h, w, _ = image.shape
if "</point" in generated_text:
matches = re.findall(
r'(?:x(?:\d*)="([\d.]+)"\s*y(?:\d*)="([\d.]+)")', generated_text
)
if len(matches) > 1:
coordinates = [
(int(float(x_val) / 100 * w), int(float(y_val) / 100 * h))
for x_val, y_val in matches
]
else:
coordinates = [
(int(float(x_val) / 100 * w), int(float(y_val) / 100 * h))
for x_val, y_val in matches
]
else:
print("There are no points obtained from regex pattern")
return coordinates
Finally, to annotate the points on the input image, we use OpenCV’s circle function with a customizable radius and color.
def overlay_points_on_image(image, points, radius=5, color=(255, 0, 0)):
# Define the BGR color equivalent of the hex color #f3599e
pink_color = (158, 89, 243) # Color for the points (BGR format)
for (x, y) in points:
# Draw an outline for the point
outline = cv2.circle(
image,
(int(x), int(y)),
radius=radius + 1,
color=(255, 255, 255),
thickness=2,
lineType=cv2.LINE_AA
)
# Draw the point itself
image_pt = cv2.circle(
outline,
(int(x), int(y)),
radius=radius,
color=color,
thickness=-1,
lineType=cv2.LINE_AA
)
# Save and convert the image
sav_image = image_pt.copy()
image = cv2.cvtColor(sav_image, cv2.COLOR_BGR2RGB)
cv2.imwrite("output_pt.jpg", sav_image)
return image


Molmo VLM Meets SAM2
Running both the MolmoE-1B model with INT4 quantization and the SAM2.1 Hiera Large model requires approximately 8.2GB of VRAM. This setup is compatible with the Colab T4 free tier.
!pip install git+https://github.com/facebookresearch/sam2.git
from sam2.sam2_image_predictor import SAM2ImagePredictor
import torch
sam_model_id = "facebook/sam2.1-hiera-large"
now = datetime.now()
current_time = now.strftime("%H_%M_%S")
os.makedirs("sam_molmo_outputs", exist_ok=True)
Segment Anything (SAM) with Molmo points enables a wide range of interesting tasks. The SAM2ImagePredictor class provides an easy way to prompt the SAM2 model. To use this, we first instantiate the class and pass the input image using the set_image method, which calculates the image embeddings. Then, using the predict method, we can prompt SAM segmentation with point coordinates and labels. Point labels are used to indicate the number of selected objects, represented by an array of 1s. For example, if there are two points, the labels would be [1, 1].
def segment(image, points, show_pts=True, sam_model_id="facebook/sam2.1-hiera-large"):
points_cp = np.array(points)
point_labels = np.ones(len(points_cp), dtype=np.uint8)
predictor = SAM2ImagePredictor.from_pretrained(sam_model_id)
with torch.inference_mode():
predictor.set_image(image)
masks, scores, logits = predictor.predict(
point_coords=points_cp,
point_labels=point_labels,
multimask_output=False, # if True returns multiple binary masks
)
sam_op_img = show_masks(image, masks, scores, borders=True)
r = int(image.shape[0] * 0.007)
if show_pts is not None:
final_image = overlay_points_on_image(
sam_op_img, points_cp, radius=r, color=(0, 0, 255, 0.6)
)
dpi = plt.rcParams["figure.dpi"]
figsize = image.shape[1] / dpi, image.shape[0] / dpi
plt.figure(figsize=figsize)
plt.imshow(final_image)
plt.axis("off")
plt.tight_layout()
plt.subplots_adjust(left=0, right=1, top=1, bottom=0)
plt.savefig(
f"sam_molmo_outputs/molmo_op_sam_pt_{current_time}.png",
bbox_inches="tight",
pad_inches=0,
)
plt.show()
SAM2 returns a set of masks with different probability scores; however, we are interested in the mask with the highest probability to remove redundant masks. For this, the masks are sorted in descending order based on the score indices. Finally, we get the top mask, which is overlaid onto the input image.
As in a typical segmentation task, the mask is first binarized by setting the maximum pixel value to 255 using unsigned int8 (np.uint8). The mask is then blended with the image at 0.6 opacity, but only in areas where the mask values are greater than 0. Finally, the image is rescaled for proper visualization. Optionally, a border is added using cv2.drawContours to provide a neat segmented output from SAM with Molmo points as prompts.
def show_masks(image, masks, scores, borders=True):
sort_idxs = np.argsort(scores)[::-1] # descending order
masks = masks[sort_idxs]
scores = scores[sort_idxs]
if len(masks) == 0:
print("No masks found")
return image
top_mask = masks[sort_idxs][0]
final_image = show_mask(top_mask, image, borders=True)
return final_image
Here is where we call the Molmo+SAM2 pipeline as a complete process: an input query is passed along with an image, and Molmo returns the corresponding points. These points are then used to generate a segmented output image, which is saved with a unique filename based on the current timestamp.
def show_mask(mask, base_image, color=(1.0, 40 / 255, 50 / 255, 0.6), borders=True):
"""
Parameters:
- mask: 2D numpy array of shape (H, W), where non-zero values indicate the mask.
- base_image: 3D numpy array of shape (H, W, 3), the original image.
- color: Tuple of (R, G, B, A), where A is the alpha transparency.
- borders: Boolean indicating whether to draw contours around the mask.
Returns:
- blended: 3D numpy array of shape (H, W, 3), the image with mask overlay.
"""
# Ensure mask is binary
mask = (mask > 0).astype(np.uint8)
# Dimensions
h, w = mask.shape
# Extract RGB and alpha components
overlay_color = np.array(color[:3], dtype=np.float32) # RGB, without opacity
alpha = color[3] # opacity
# Normalize base image to [0,1]
base_image_float = base_image.astype(np.float32) / 255.0
# Create an empty overlay image
overlay = np.zeros_like(base_image_float)
# Assign the overlay color to the masked regions
# Using the 2D mask to index the first two dimensions
overlay[mask == 1] = overlay_color
# Blend the overlay with the base image only where mask is present
blended = base_image_float.copy()
blended[mask == 1] = (
alpha * overlay[mask == 1] + (1 - alpha) * base_image_float[mask == 1]
)
# Convert back to [0,255] uint8
blended = np.clip(blended * 255, 0, 255).astype(np.uint8)
# If borders are requested, draw contours on the blended image
if borders:
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# Draw contours in blue color with thickness 2
cv2.drawContours(
blended, contours, -1, (255, 0, 0), 2
) # BGR = (255,0,0) for blue contours
return blended
Here is where we call the Molmo+SAM2 pipeline as a complete process: an input query is passed along with an image, and Molmo returns the corresponding points. These points are then used to generate a segmented output image, which is saved with a unique filename based on the current timestamp.
input_query = 'Point to the Santa dog'
generated_text = molmo_answer(query_text=input_query, input_img=ip_img)
if "</point" in generated_text:
# Extract coordinates from the generated text
points = get_coords(ip_img, generated_text)
print("Scaled points: ", points)
# Perform segmentation on the image
segment(ip_img, points, sam_model_id=sam_model_id)
# Create a copy of the input image for overlaying points
img_copy = ip_img.copy()
# Overlay points on the image
only_pts_img = overlay_points_on_image(
image=img_copy,
points=points,
color=(0, 0, 255),
radius=4
)
# Get the current timestamp
now = datetime.now()
current_time = now.strftime("%H_%M_%S")
# Save the image with points overlaid
cv2.imwrite(f"Molmo_pts/molmo_pts_{current_time}.jpg", only_pts_img)
DEMO
Query: Point to the Santa dog.

Molmo Point + SAM2 Segmentation

Query: Point to the sunglasses, rubber duck

Note: From here, all the demos shown are inference from Molmo’s chat website with Molmo-7B-D.
Pointing + VQA
This is a relatively complex question where we ask Molmo to point out specific elements. While the results weren’t successful for every element queried, this task requires image understanding and the ability to map color codes from the legends.
Q1: Point to all noble gas elements

Q2: What are the applications of noble gases?
Noble gases have a wide range of applications across various fields:
1. Lighting: They're used in neon signs, laser technology, and high-intensity discharge lamps.
2. Anesthesia: helium and neon are used in medical settings for deep breathing and pain management.
3. Protection: argon is used to protect materials from oxygen during welding and in industrial processes.
4. Cooling: krypton and xenon are used in cryogenic equipment and cooling systems for scientific instruments.
5. Semiconductor manufacturing: they're used in etching processes for creating integrated circuits.
6. Food preservation: argon is used to extend the shelf life of packaged foods.
7. Underwater diving: helium is used for deep-sea diving due to its low density and inert properties.
8. Vacuum tubes: neon and argon are used in vacuum tubes for television and computer displays.
9. Spectroscopy: noble gases are used as coolants in spectrometers and as background gases in various analytical techniques.
10. Atmospheric science: they're used to study atmospheric composition and climate change.
These versatile properties make noble gases essential in both scientific research and everyday technology.
Counting
By default, for counting tasks, Molmo uses a chain-of-thought approach with point-then-count reasoning. When pointing to multiple items, the output points are ordered from top-to-bottom and left-to-right. To avoid memory errors, Molmo is limited to generating a maximum of 40 points.
Query: Count the total number of people in the image.

Query: Count the total number of coins in the image

Counting the total number of coins in the image shows a total of 26.
Pointing in Robotics
Molmo’s precise pointing capability positions it as an ideal Vision-Language-Action model for enabling robot grippers to interact seamlessly with physical objects.
Query: Point to location where the gripper has to hold to pick the white pan

Query: Point to the location where the bottle has to placed for washing

Reasoning over Points
Query: Point to Presidents of Russia, China and India

While the result is impressive, it incorrectly identifies Shri Narendra Modi as the President, whereas he is the Prime Minister(PM) of India. For the same query, GPT-4o and Gemini correctly identified him as the PM.
This output helps us understand Molmo’s precision capabilities.
Clock Face Recognition
Query: What is the time shown?

The time shown on the watch is 1:06. The hour hand is positioned just before the 2, indicating it’s a few minutes before 2 o’clock. The minute hand is pointing slightly past the 1, which represents 6 minutes past the hour. This precise time of 1:06 is clearly displayed on the watch face.
Captioning
Query: Caption this moment

Source FIFA World Cup 2022
In this captivating image, Lionel Messi, the renowned Argentine footballer, is seen in a moment of pure elation. He is holding the iconic FIFA World Cup trophy, its golden surface gleaming under the stadium lights. Messi is gently kissing the trophy, his eyes closed in a gesture of deep emotion and accomplishment. His short brown hair and beard are clearly visible, and his tattooed right arm is wrapped around the base of the cup.
Messi is wearing his signature white jersey with blue and black stripes, representing the Argentine national team. The background is blurred, drawing all attention to Messi and the trophy, but you can make out the presence of other people, including someone holding a phone to capture this historic moment.
This image perfectly encapsulates Messi's journey and the culmination of his dreams. It's a powerful representation of the passion, dedication, and triumph that have defined his illustrious career in football.
Prepare a recipe
Query: How to prepare this veg recipe with ingredients?

To prepare this colorful veggie pizza recipe, you'll need the following ingredients:
1. Pizza dough (homemade or store-bought)
2. Tomato sauce
3. Melted cheese (mozzarella or a veggie alternative)
4. Red bell peppers
5. Green bell peppers
6. Red onions
7. Black olives
8. Corn kernels
9. Olive oil
10. Garlic (optional, but great for flavor)
11. Herbs like basil or oregano (optional)
Here's how to make it:
1. Preheat your oven to 425°F (220°C).
2. Roll out the pizza dough and spread a layer of tomato sauce over it.
3. Sprinkle the melted cheese evenly over the sauce.
4. Arrange the red bell peppers, green bell peppers, red onions, and black olives in a single layer on top of the cheese.
5. Add corn kernels for extra sweetness and crunch.
6. Drizzle olive oil over the vegetables and sprinkle with minced garlic and herbs if using.
7. Place the pizza in the preheated oven and bake for 15-20 minutes, or until the crust is golden brown and the cheese is bubbly and slightly browned.
8. Remove from the oven and let it cool for a few minutes before slicing and serving.
This veggie pizza is a delicious and nutritious option that's perfect for meat-free meals or as a fun twist on traditional pizza. The combination of colorful vegetables and melted cheese creates a visually appealing and tasty dish.
VLM-aided OCR
We observe a shift towards adapting VLMs for OCR tasks instead of relying solely on OCR-specific models, despite their higher VRAM requirements. VLMs are inherently capable of extracting text and outputting it in standard formats like JSON or YAML when appropriately prompted.
Query: List all the text and their corresponding pairs in a neat JSON

Here’s a JSON representation of the text pairs from the receipt:

If you are looking for use cases of VLMs specific to OCR, AllenAI recently released OlmOCR an excellent model based on Qwen2-VL-7B-Instruct. Do give it a spin with your docs on their website.
Table VQA
Query 1: Describe the image in detail
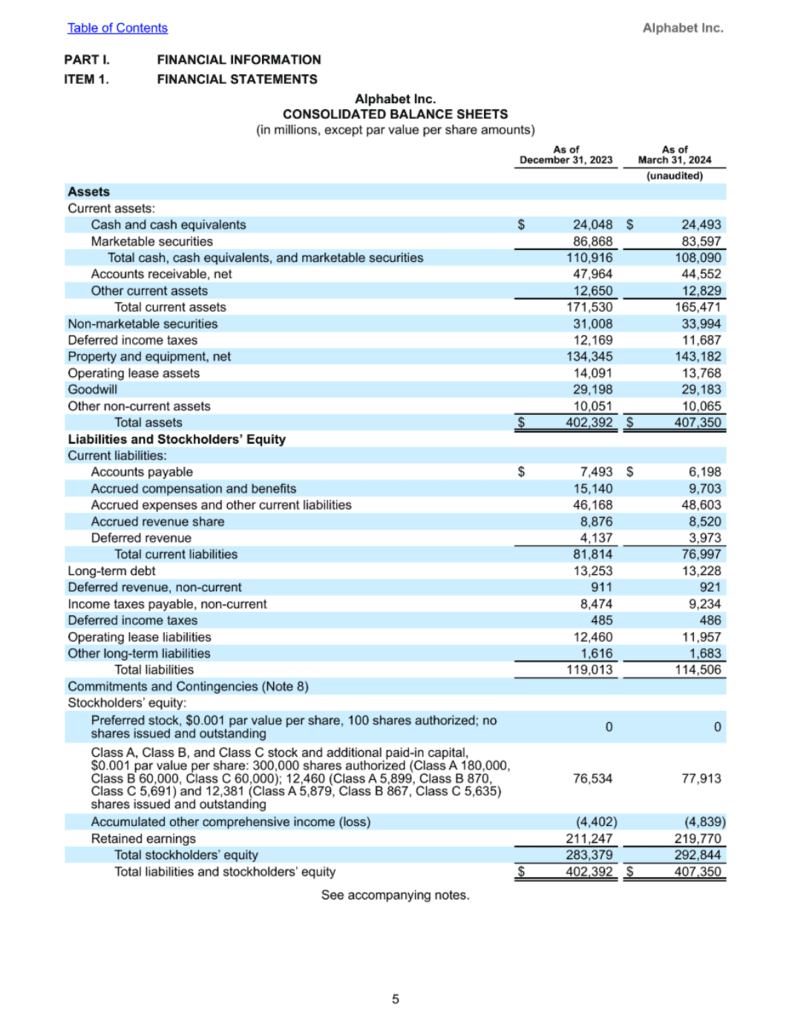
The image displays a detailed financial statement for Alphabet Inc., specifically the consolidated balance sheet. The document is divided into two main sections: assets and liabilities and stockholders' equity.
In the assets section, the statement lists various categories such as cash and cash equivalents, marketable securities, property, plant, and equipment, as well as other assets. The liabilities section includes entries for accounts payable, accrued expenses, long-term debt, and operating lease liabilities. The stockholders' equity section details preferred stock, common stock, and retained earnings.
The financial statement provides figures for both December 31, 2023, and March 31, 2024, allowing for a comparison of the company's financial position over these two periods. The document is presented in a clear, organized manner, making it easy to read and understand the financial data at a glance.
Query 2: What are the total liabilities as of Mar 31, 2024
The total liabilities as of March 31, 2024, according to the balance sheet, is $114,506 million.
This figure represents the sum of all current and long-term liabilities listed in the liabilities section of the statement.
Graph Interpretation – VQA
Query: From the graph, what is the shareholder return of Nvidia as of 1/30/22 and 1/28/24

The graph shows the cumulative total shareholder return for Nvidia Corporation over a five-year period. As of January 30, 2022, Nvidia's shareholder return was approximately 600%. By January 28, 2024, this return had significantly increased to about 1500%.
These figures demonstrate the substantial growth in Nvidia's stock value over this two-year timeframe, with a notable acceleration in the more recent period leading up to January 2024.
Image VQA
US Election results – Interpret
Query 1: Who are the candidates here?

The candidates shown in the 2024 U.S. presidential election results are:
Donald Trump (Republican Party)
Kamala Harris (Democratic Party)
Jill Stein (Green Party)
Robert Kennedy Jr. (Independent)
Chase Oliver (Libertarian Party)
Additionally, there's a category for "Other candidates" at the bottom of the list, though specific names aren't provided for this category.
Query 2: Interpret the results
The image shows the results of the 2024 U.S. presidential election. Donald Trump has won the race, securing 312 electoral votes. Kamala Harris has obtained 226 electoral votes, making her the runner-up.
Trump's electoral vote total is 106 more than the 208 needed to secure a majority in the Electoral College. Harris has 86 fewer electoral votes than Trump.
The map of the United States is displayed, with states colored blue or red to indicate which candidate won each state. The blue states represent Trump's victories, while the red states represent Harris's wins.
This election result represents a significant victory for Trump, as it's the first time a non-incumbent president has won re-election since James K. Polk in 1844. Trump's win also breaks the trend of Democratic presidents winning consecutive terms that had been in place since Franklin D. Roosevelt's victories in 1932 and 1936.
Training Bias:

The candidates shown in the electoral map are Donald Trump and Joe Biden. Trump is indicated as the winner with 312 electoral votes, while Biden has 226 electoral votes. The map displays the results of the 2020 U.S. presidential election, with states colored to represent which candidate won each one.
Our Interpretation: From the image, we can infer that without the title “2024 US Elections,” the system mistakenly identifies Joe Biden as the Democrat candidate, even though Kamala Harris is shown in the image. This could be due to training bias, where the model associates Joe Biden with electoral contexts based on the 2020 U.S. presidential election data.
Failure Cases and Limitations of Molmo 7B on our Tests:
Molmo doesn’t consistently return high-quality responses and is highly susceptible to slight changes in input. We observed that even minor modifications, such as adding the word “the,” can lead to entirely different outputs, despite the intent remaining the same. This highlights significant variability in its response quality.
Case 1: Pointing over abstract concepts
Query:
Type 1: Point to red color coded US states
Type 2: Point to the states where Republicans won.

Case 2: VQA

Query: What are the different types of computer vision segmentation tasks shown here?
The image shows four different types of segmentation tasks:
A) Input Image: This is the original photograph of three people on a beach at sunset.
B) Silhouette Extraction: The image shows the people as red silhouettes against a yellow and blue background, with a purple hill.
C) Color Segmentation: Here, the people are separated into different colors (red, purple, and orange) against a black background.
D) Selective Segmentation: This task shows the people as red silhouettes, but with a purple hill and blue sky in the background.
These tasks demonstrate various methods of separating people from their background in images, ranging from simple color extraction to more complex selective segmentation while maintaining different background elements.
For the same image, GPT-4o and Gemini successfully identified each task correctly, whereas Molmo 7B-D completely failed, even when explicitly said that they are computer vision segmentation tasks.
Case 3: VQA

Source: https://www.fastandup.in/nutrition-world/health-benefits-of-surya-namaskar/
Query: Describe the image in detail like a Yoga instructor
Welcome to our comprehensive guide to the Classic Sun Salutation! This 12-image sequence will take you through each step of this powerful and rejuvenating yoga pose.
Let's begin in the first pose. We'll start with a standing position, feet together, arms at your sides. This is the preparatory stance, setting the foundation for the entire sequence.
As we move to the second pose, we'll hinge forward, reaching towards the ground with our fingertips. This helps to open the chest and calm the mind.
In the third pose, we'll bring our hands back to our hips, feet together. This alignment helps to strengthen the core and prepare for the next movement.
Next, we'll step our right foot back, creating a lunge position. This opens the hip flexor and stretches the front leg, preparing for the backbend.
Now, we'll transition into the backbend. We'll place our hands on the floor, fingers interlaced, and lift our hips towards the sky. This pose opens the chest, stretches the spine, and strengthens the core.
Moving on, we'll come back to a standing position, but with our hands on our hips. This helps to integrate the changes made in the backbend and strengthens the legs.
In the next pose, we'll reach our right arm towards the sky, opening the chest and creating a beautiful, flowing line from head to toe.
Now, we'll bring our hands together in front of our heart center. This pose promotes relaxation and deepens the breath.
Next, we'll hinge forward again, reaching towards the ground with our fingertips. This helps to release tension in the back and calm the mind.
In the penultimate pose, we'll come back to a standing position, but with our hands on our hips. This integrates the changes made in the forward bend and strengthens the legs.
Finally, we'll finish with a standing pose, arms at our sides. This last pose helps to ground us and finish the sequence on a positive note.
Remember, the Sun Salutation is not just about the physical pose, but also about the breath and the flow between movements. Take your time, listen to your body, and enjoy the journey of this beautiful yoga practice.
When we ask the model to describe the image, it doesn’t explicitly identify it as the classic Sun Salutation sequence. However, when prompted explicitly as in the example above, it provides a detailed response, though nearly 50% of the information is incorrect.
Case 4: Reasoning over Spatial Understanding

Query1: Who is sitting direct opposite to red
The figure sitting directly opposite the red figure is the purple figure.
In a circular arrangement, the purple figure would be positioned at the 9 o'clock spot
if we imagine the circle as a clock face, with the red figure at the 12 o'clock position.
To improve results, let’s use the same analogy it made to understand the circular seating arrangement with an analog clock which serves as a hint.
Query2: You can take range from 5 to 7 o’clock, now say who is opposite to red
If we consider a range from 5 to 7 o'clock for the position of the red figure's opposite, the green figure would still be the closest match.
The green figure is positioned at approximately the 5:30 to 6 o'clock range in the image, making it the most direct opposite to the red figure within that specified range.
While the purple figure is also in that vicinity, it's slightly further away, so the green figure remains the most accurate answer for the opposite of red within the 5-7 o'clock range.`
Key Takeaways from Molmo VLM
- While Molmo is a promising project, it still faces limitations in reasoning capabilities and handling complex queries. When multiple queries are cascaded into a single prompt, it often ignores the latter part of the query.
- Contrary to the claims in the paper that Molmo outperforms Gemini Flash, our tests with the Molmo 7B-D model revealed several shortcomings, especially in reasoning and handling complex queries. In contrast, Gemini Flash models excelled, providing accurate responses to similar queries.
- Fine-tuning on specific downstream tasks and datasets can help address the shortcomings observed in Molmo.
- Recently Agentic AI Browser Use tasks with OmniParser or Magma have gained a significant traction among AI community. However, they involve multiple sub processes running behind such as layout detection, captioning and the reasoning steps by LLMs. Due to Molmo’s pointing ability, it can natively operate on these use cases better at just 7B parameter size.
Conclusion
Based on our experimentation, we see VLMs like Molmo demonstrate immense potential and a wide range of applications especially in Robotics. However, surprisingly, the GenAI community, which often creates buzz around model releases with minor metric improvements, has not fully recognized the true value of Molmo and its PixMo dataset. Open-source contributions of this caliber deserve appreciation.
Kudos to the team at Ai2 for openly sharing comprehensive details about their training methodologies and dataset preparation strategies with the open-source community.
References



100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning