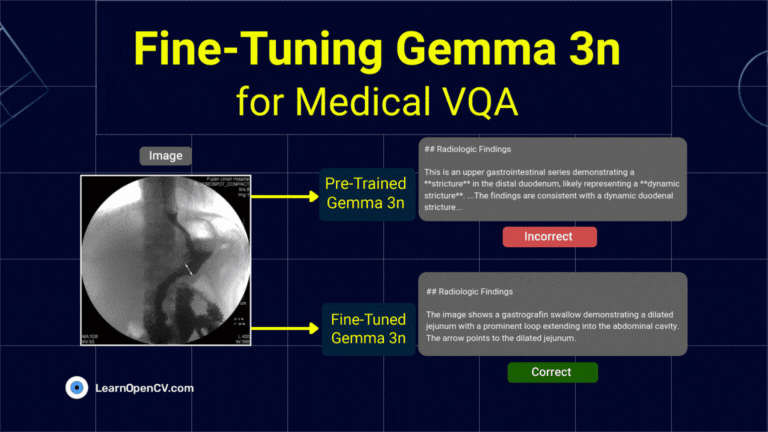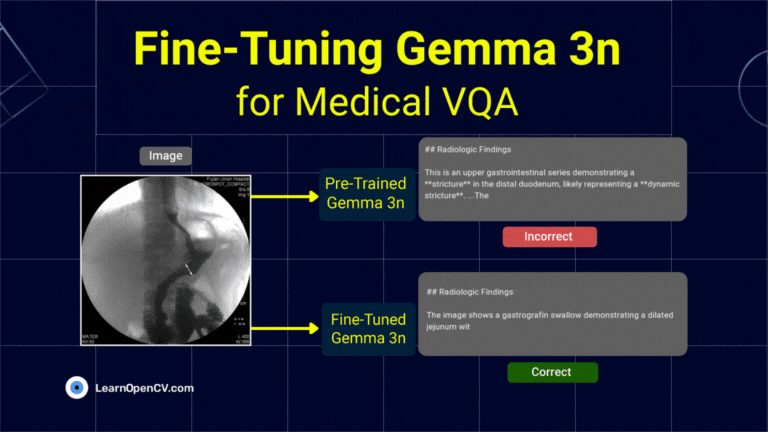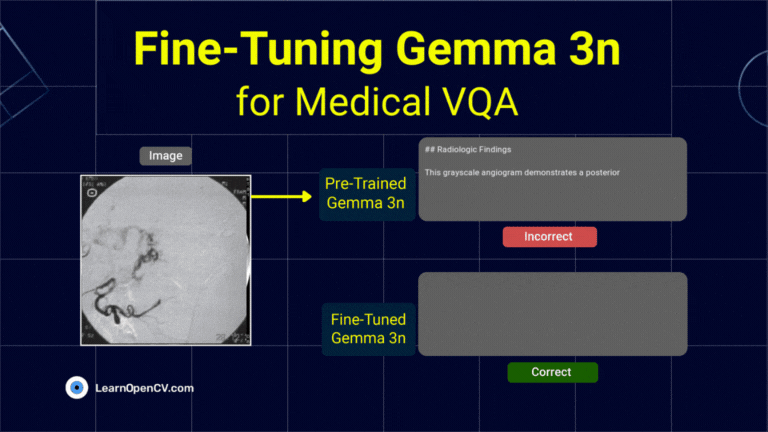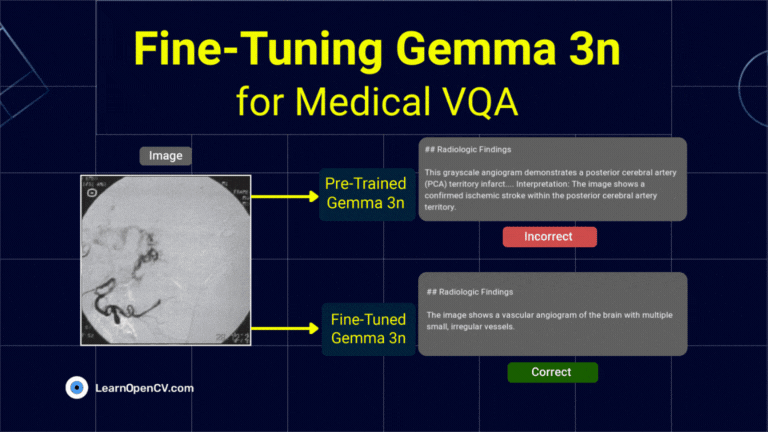
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
The domain of video understanding is rapidly evolving, with models capable of interpreting complex actions and interactions within video streams. Meta AI’s VJEPA-2 (Video Joint Embedding Predictive Architecture) stands out
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride
As Machine Learning and AI technologies continue to advance, the need for efficient and secure methods to store, share, and deploy trained models becomes increasingly critical. Model weights file formats
The field of computer vision is fueled by the remarkable progress in self-supervised learning. At the forefront of this revolution is DINOv2, a cutting-edge self-supervised vision transformer developed by Meta
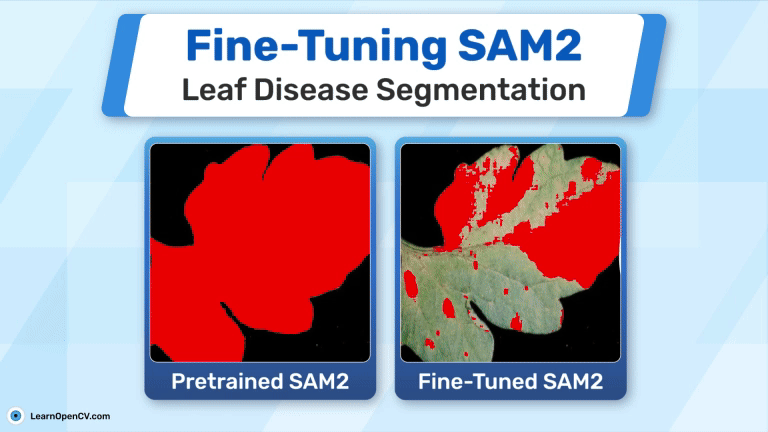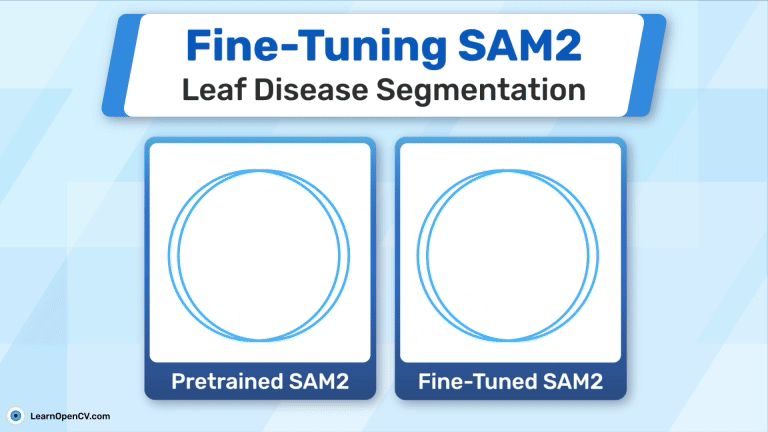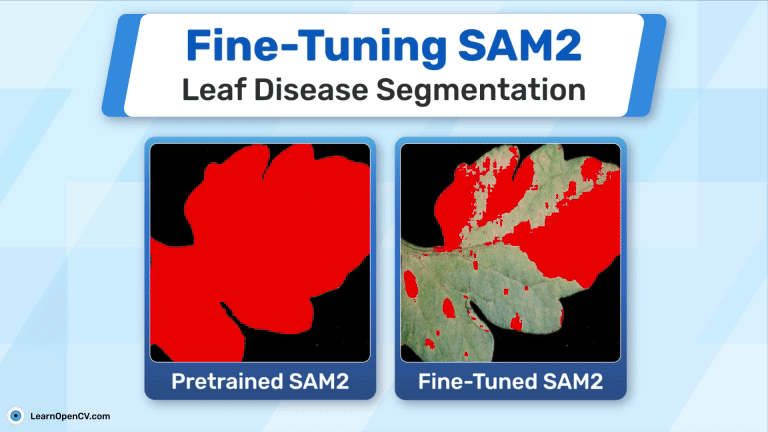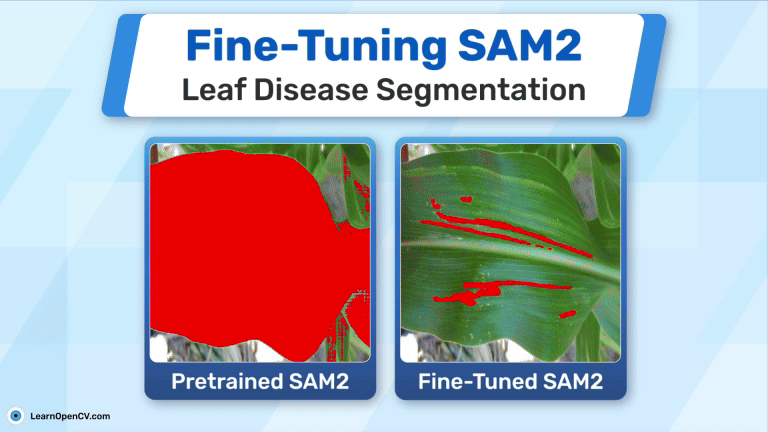
Leaf diseases reduce crop yields and impact food security. Finetuning SAM2 helps detect and segment diseased areas using deep learning. With a small dataset, we achieved 74% IoU, making early
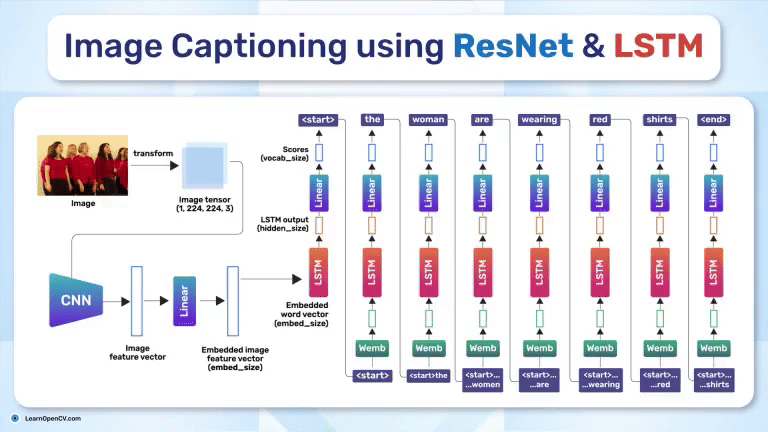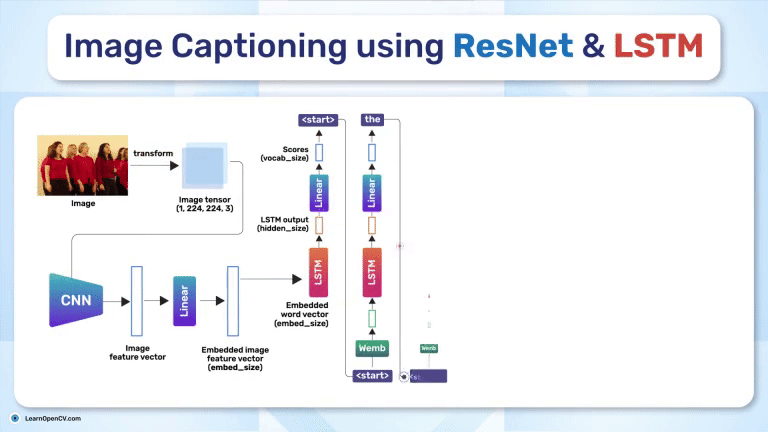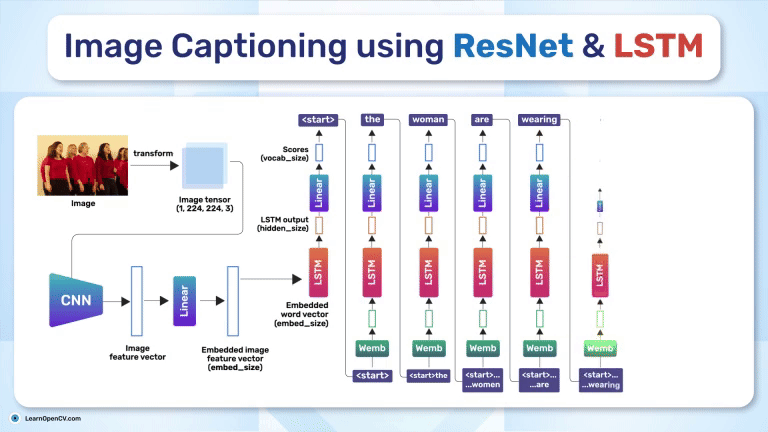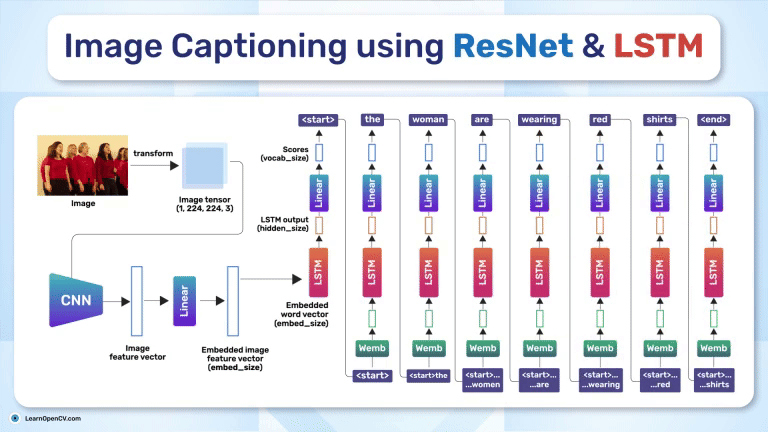
Image Captioning using ResNet and LSTM bridges vision and language, enabling machines to "see" images and "describe" them in text. This model powers applications like accessibility for visually impaired users,
The article primarily discusses capabilities Sapiens a foundational human vision model by meta, achieves state-of-the-art performance in tasks like 2D pose estimation, body-part segmentation, normal and depth estimation.
In the preceding article, YOLO Loss Functions Part 1, we focused exclusively on SIoU and Focal Loss as the primary loss functions used in the YOLO series of models. In