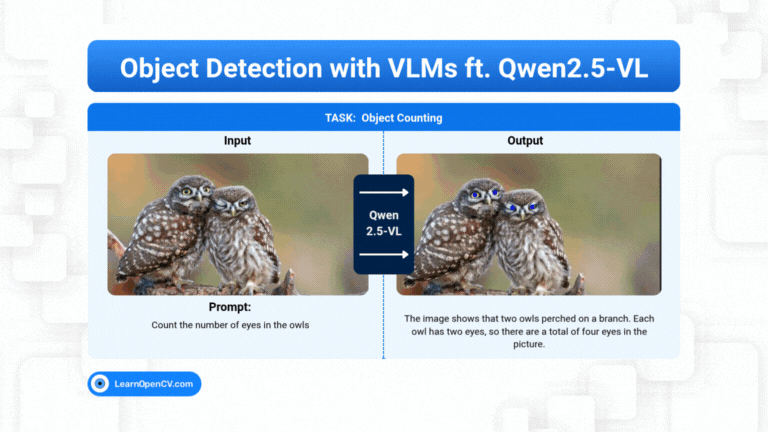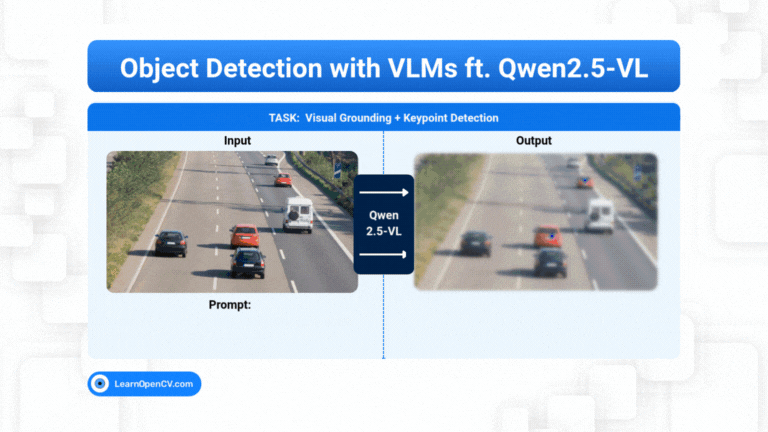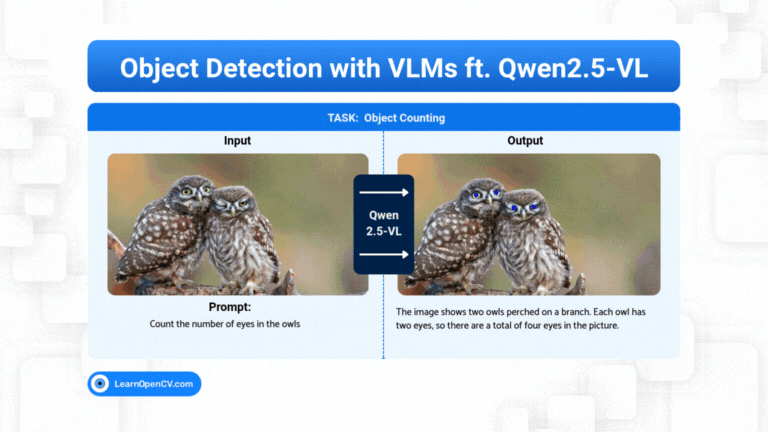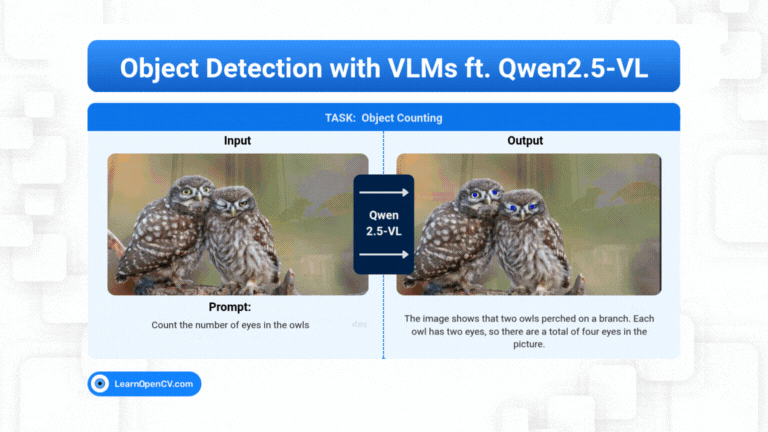
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on CARLA Leaderboard 2.0 and
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride
The field of computer vision is fueled by the remarkable progress in self-supervised learning. At the forefront of this revolution is DINOv2, a cutting-edge self-supervised vision transformer developed by Meta
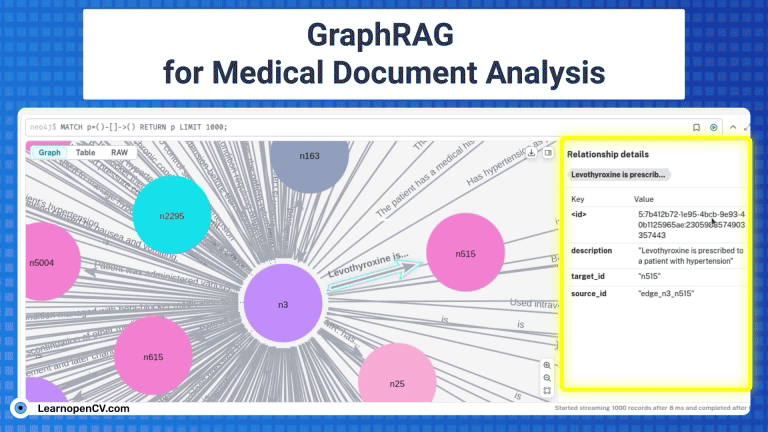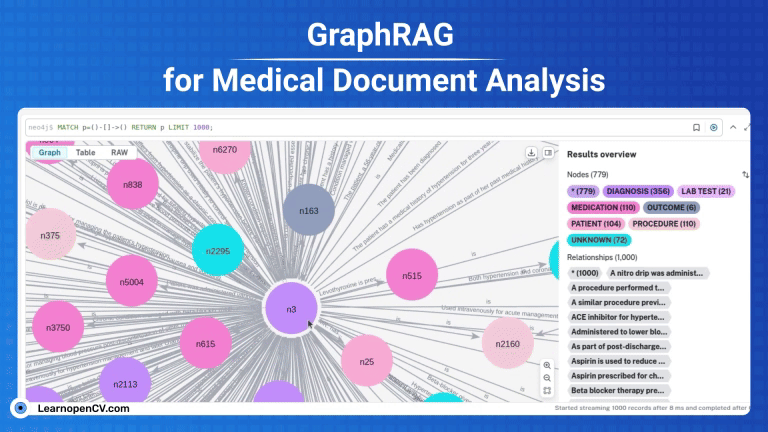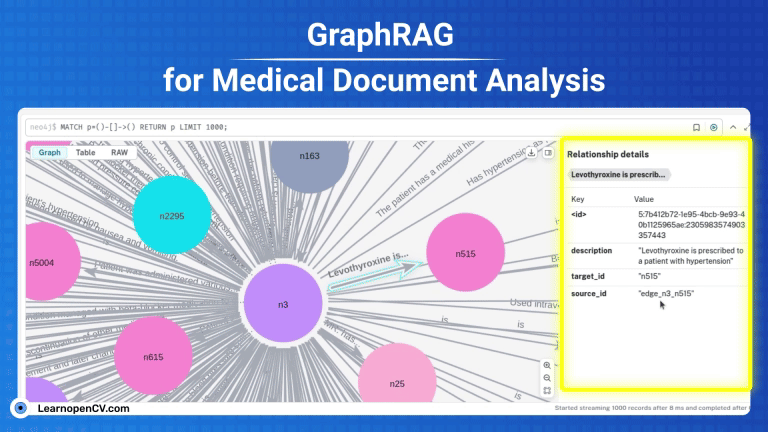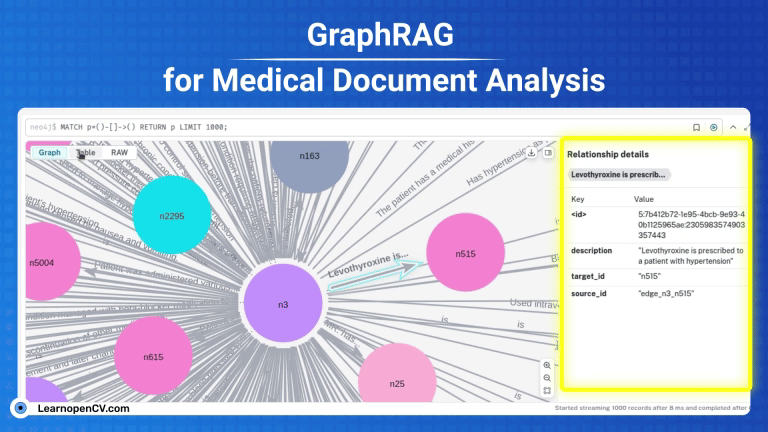
GraphRAG is a pivotal research from Microsoft improving the shortcomings of naive RAG by employing structured Knowledge graph which includes entities, relations, claims etc, for traceability by traversing multi-hop nodes.
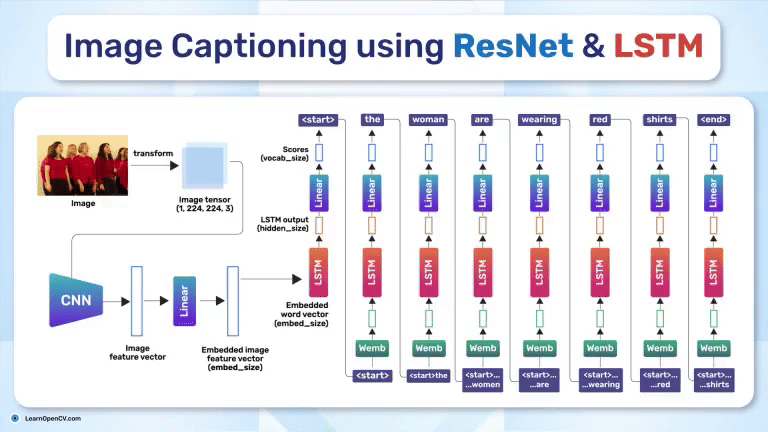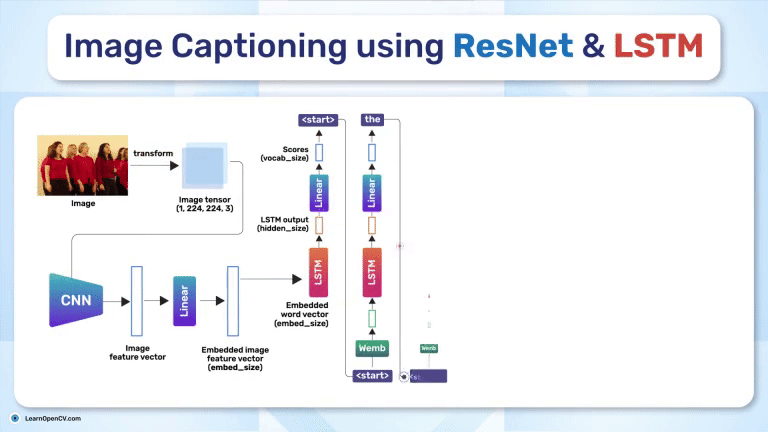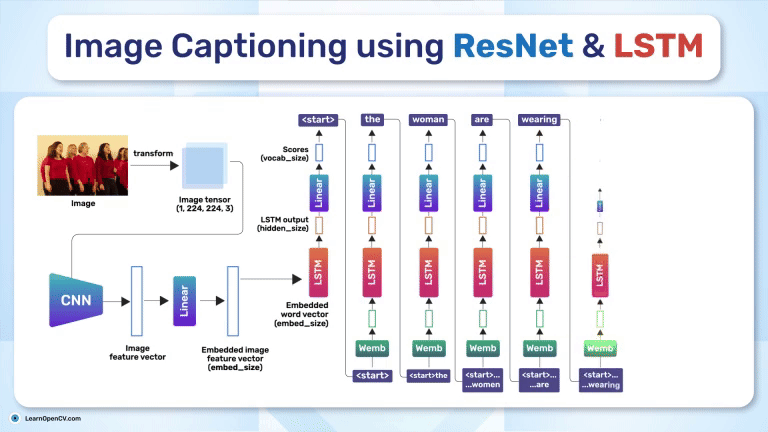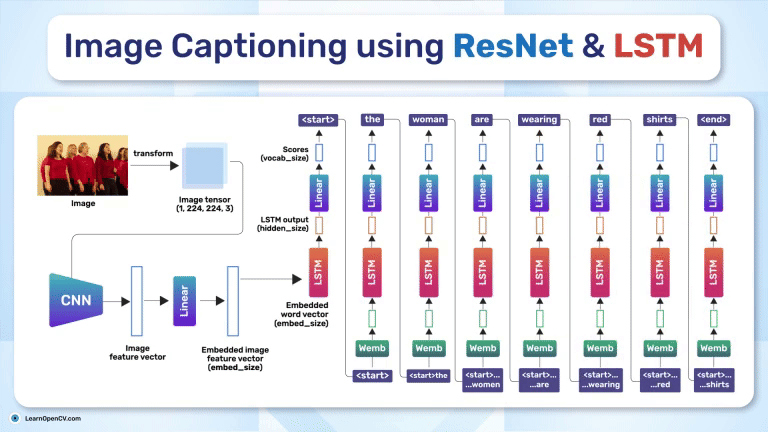
Image Captioning using ResNet and LSTM bridges vision and language, enabling machines to "see" images and "describe" them in text. This model powers applications like accessibility for visually impaired users,
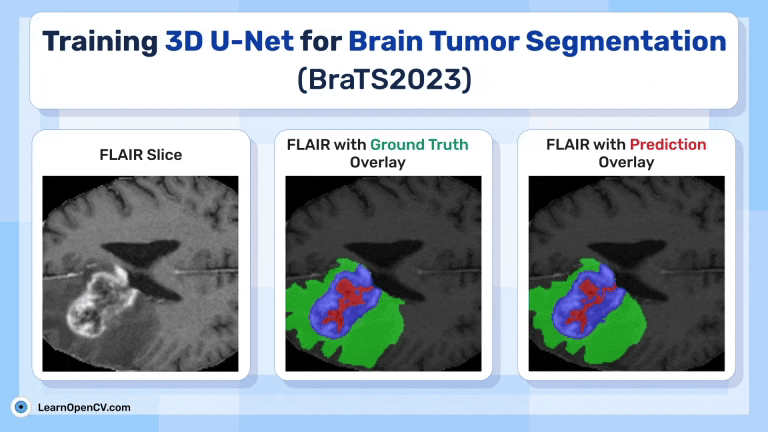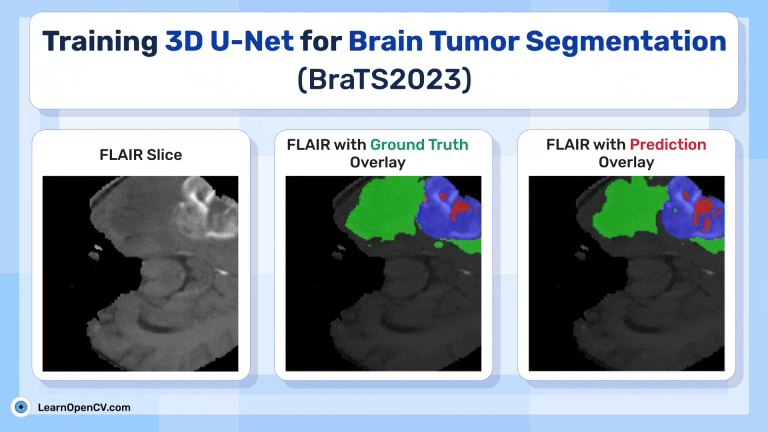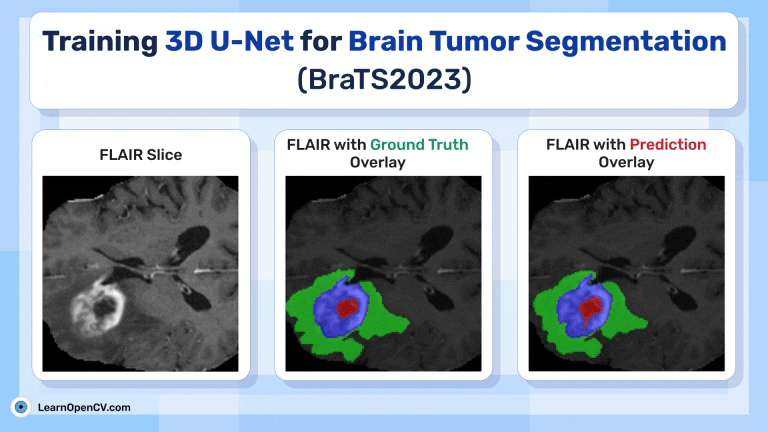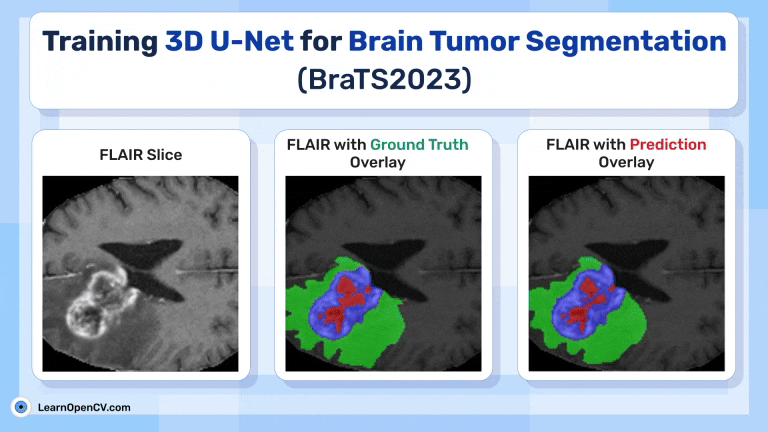
This articles discussed Training 3D U-Net for Brain Tumor Segmentation - BraTS2023. Glioma Detection It touches upon the importance of 3D U-Net over 2D U-Net for MRI Brain Scans.
The article primarily discusses capabilities Sapiens a foundational human vision model by meta, achieves state-of-the-art performance in tasks like 2D pose estimation, body-part segmentation, normal and depth estimation.
Performing RAG on Unstructured elements that too in complex pdfs like finance, law reports is challenging. ColPali a novel document retrieval approach achieves SOTA results with high quality retrieval. This
Feature matching using deep learning is a game-changer for computer vision tasks like panorama stitching, video stabilization, and face recognition, providing greater accuracy and reliability. Dive into how this technology