


We often take out our phones and say, “Hey Siri, play Perfect by Ed Sheeran” or “Ok Google, set an alarm at 7.30 in the morning.” And the work is done on the flow by our phones! But have you ever wondered how this magic happens? In 2024, an LLM like GPT-4o or a robot like Tesla Optimus can speak with us. But how? Speech to Speech, yes, this is the term we use in NLP to describe the process.

So, In this article, we will explore:
- What is Speech to Speech (StS)?
- What are the applications of StS?
- What are the building blocks of the StS pipeline?
- How does Speech to Speech work?
- Some interesting experimental results!
- Finally, a quick recap of the article.
We will learn how a machine (computer) can talk like humans. Isn’t that fascinating? So, grab a cup of coffee. This will be a fascinating journey for sure!
What is Speech to Speech (StS)
Speech to Speech is a process where we can speak to our system like anyone else. Now the question is how? In very simple terms:
- First, we filter our speech with a voice activity detection (VAD) model.
- Then, we pass this filtered voice input to a Speech to Text model to do the transcription and convert the audio into text.
- Then, we give this text as a prompt to a large-language model (LLM), and generate an answer to our prompt.
- Finally, we convert the generated answer to a voice using a Text to Speech (TTS) model.
This is a high-level view of the entire Speech to Speech pipeline. In between, there are a few things that we need to know in detail. We will dive deeper into each component in the later part of the article.


Applications of Speech to Speech: Why do we need it?
Speech to Speech is the most accessible form of NLP in our lifestyle. StS provides a wide range of applications, which include:
Virtual Assistants:

Applications like Siri, Alexa, and Google Assistant use StS to answer questions, perform tasks, and have casual conversations. Even in smart homes or appliances, we use these assistants to simplify our tasks.
Healthcare:

Doctors can interact with StS-enabled devices to document patient records or get information without touching a screen.
Customer Service:
Automated customer service systems can handle inquiries conversationally, reducing wait times and improving service efficiency. Today, all customer service systems are semi-automated and automated by voice agents. We will see in the near future that all the call centers will be replaced by speech to speech models.
Language Translation:
Real-time translation tools enable multilingual communication in business, travel, and education. We used to do this with our phones whenever we traveled to a new place outside of our language region.
Robotics:

Humanoids like Tesla Optimus interact with people naturally, assisting with tasks and answering questions. All under the hood is a Speech to Speech method that powers the robot to interact with humans.
Autonomous Vehicles:

All cars support an interactive agent like Google Gemini or Apple Siri to interact with your car system without distraction while driving.
However, this is just the beginning—there are countless new possibilities cooking in our brains! Once you’ve finished reading, let us know if you have any fresh ideas you’d like to share!
Components of a Speech to Speech Pipeline
As we discussed previously, it has four main components:
- Voice Activity Detection (VAD)
- Speech to Text (STT)
- (Large) Language Model (LLM)
- Text to Speech (TTS)
Let’s understand each component, but before that, we know audio in an analog wave (which contains continuous amplitude values over time) to store a small analog signal, we need a huge memory that we can’t afford. So, we change this analog wave to a digital wave (sequence of discrete amplitude values over time) before passing it to our Speech to Speech pipeline. In audio processing, we start with an analog signal—your voice—a continuous waveform of pressure changes over time. A microphone translates this pressure into an electrical signal, which is then digitized by an Analog-to-Digital Converter (ADC) using:
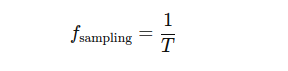
Where T is the sampling interval, for speech processing, typical sample rates are 16 kHz or 44.1 kHz, capturing enough data to represent human speech adequately by the Nyquist theorem, which states that the sampling rate must be at least twice the maximum frequency in the signal to prevent aliasing.
Now, moving forward, let’s understand how the entire pipeline works.
To understand the workflow, we will use a practical and robust implementation project called Speech to Speech, developed by the Hugging Face team. So, let’s understand each component one by one. The basic structure of the codebase follows:
.
├── arguments_classes
├── connections
├── LLM
├── __pycache__
├── STT
├── tmp
├── TTS
├── utils
└── VAD
We will see how each component works in the pipeline.
1. Voice Activity Detection (VAD)
Imagine you’re building a system that listens to audio and responds appropriately. The first challenge is figuring out when someone is speaking. You don’t want your system processing silence or background noise—that’s where Voice Activity Detection (VAD) comes in.
VAD acts like the system’s ears, constantly listening and deciding, “Is someone speaking right now?” It segments the audio stream into speech and non-speech sections.
Here’s how it works:
- Audio Input: The system receives a continuous audio stream, perhaps from a microphone.
- Framing: The audio is split into small chunks or frames, typically around 20 milliseconds each. This is similar to taking snapshots of the audio at rapid intervals.
- Feature Extraction: For each frame, the system computes features that can indicate speech. Common features include:
- Short-Time Energy (STE): Measures the energy in the frame. Speech usually has higher energy than silence.
- Zero-Crossing Rate (ZCR): Counts how often the audio signal crosses the zero amplitude axis, indicating frequency content.
- Classification: The system uses these features to decide whether each frame contains speech. This can be as simple as thresholding (if energy > threshold, it’s speech) or as complex as using a trained neural network model.
- Speech Segmentation: Consecutive frames classified as speech are grouped together to form speech segments.
- Output: The speech segments are then passed on to the next component in the pipeline for further processing.
Codebase Explanation
└── VAD
├── __pycache__
├── vad_handler.py
└── vad_iterator.py
In the code, the VAD functionality is coded within the VADHandler class in vad_handler.py.
setup Method
When the VADHandler is initialized, the setup method is called:
def setup(self, should_listen, thresh=0.3, sample_rate=16000, min_silence_ms=1000,
min_speech_ms=500, max_speech_ms=float('inf'), speech_pad_ms=30, audio_enhancement=False):
self.should_listen = should_listen
self.sample_rate = sample_rate
# Load the Silero VAD model
self.model, _ = torch.hub.load('snakers4/silero-vad', 'silero_vad')
# Initialize the VAD iterator with parameters
self.iterator = VADIterator(
self.model,
threshold=thresh,
sampling_rate=sample_rate,
min_silence_duration_ms=min_silence_ms,
speech_pad_ms=speech_pad_ms,
)
- Model Loading: We use the Silero VAD model, a neural network trained to detect speech. This model is loaded via torch.hub.
- Iterator Initialization: The VADIterator handles the sequential processing of audio frames.
Process Method
The process method is where the action happens:
def process(self, audio_chunk):
audio_int16 = np.frombuffer(audio_chunk, dtype=np.int16)
audio_float32 = int2float(audio_int16)
# Pass audio to the VAD iterator
vad_output = self.iterator(torch.from_numpy(audio_float32))
if vad_output is not None and len(vad_output) != 0:
array = torch.cat(vad_output).cpu().numpy()
duration_ms = len(array) / self.sample_rate * 1000
# Check if the speech segment meets duration requirements
if duration_ms < self.min_speech_ms or duration_ms > self.max_speech_ms:
# Skip segments that are too short or too long
pass
else:
self.should_listen.clear() # Stop listening
# Yield the processed speech segment
yield array
- Audio Conversion: The raw audio bytes are converted into a NumPy array of int16 and then to float32 for processing and memory efficiency. Floating-point numbers provide more flexibility in representing continuous values between -1 and 1, allowing the model to process the signal more precisely. Also, converting to float32 helps normalize the signal amplitude, which is particularly important for consistent and stable processing by the VAD model.
- VAD Processing: The audio is passed to the VADIterator, which uses the VAD model to detect speech.
- Segment Validation: In the VAD pipeline, segment validation checks whether a detected speech segment falls within a certain duration range. Typically, this means setting a minimum and maximum allowable duration for speech segments (e.g., minimum 500ms, maximum 5 seconds). By setting duration limits, we control the amount of data flowing through the pipeline, which ensures that only the most relevant audio reaches subsequent stages (STT, LLM, TTS).
- Control Signal: self.should_listen.clear() is called to signal that the system should stop listening and process the current speech segment.
- Output: The valid speech segment is yielded for the next stage.
2. Speech to Text (STT)
Once we’ve isolated speech segments, the next step is to convert spoken words into text—this is the job of Speech to Text (STT).
Here’s how STT works:
- Preprocessing: The audio segment is normalized to ensure consistent amplitude levels.
- Feature Extraction: The system computes a Mel Spectrogram from the audio, representing how energy levels vary across different frequencies over time.
- Short-Time Fourier Transform (STFT): The audio is divided into short segments, or “windows,” and each segment is analyzed separately. This captures frequency information for short, manageable chunks of the audio, allowing the system to track how frequencies change over time.
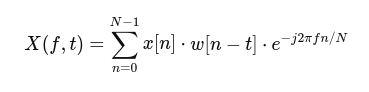
Where w[n] is a window function, before the Fourier transform is applied, each segment is tapered with a window function. This function smooths the edges of each segment to reduce artifacts, ensuring the analysis accurately reflects the signal’s actual frequency content.
- Mel Scale Conversion: Once the spectrogram is computed, it’s mapped to the Mel scale, a frequency scale that aligns with human hearing. We are more sensitive to differences in pitch at lower frequencies than at higher frequencies, and the Mel scale reflects this.
A filter bank of overlapping filters is used to apply the Mel scale. Each filter captures energy in a specific frequency range, with narrower filters at lower frequencies (where human hearing is more sensitive) and broader filters at higher frequencies. This makes the spectrogram more perceptually relevant for the neural network model.
- Model Inference: The spectrogram is fed into a neural network model (like Whisper) that decodes it into a sequence of text tokens.
- Decoding: The sequence of tokens is converted into human-readable text.
- Output: The transcribed text is passed to the next component.
Codebase Explanation
├── STT
├── faster_whisper_handler.py
├── lightning_whisper_mlx_handler.py
├── paraformer_handler.py
├── __pycache__
└── whisper_stt_handler.py
The STT functionality is handled by the WhisperSTTHandler class in whisper_stt_handler.py.
Setup Method
def setup(self, model_name='distil-whisper/distil-large-v3', device='cuda', torch_dtype='float16',
compile_mode=None, language=None, gen_kwargs={}):
self.device = device
self.torch_dtype = getattr(torch, torch_dtype)
self.gen_kwargs = gen_kwargs
# Load the processor and model from Hugging Face
self.processor = AutoProcessor.from_pretrained(model_name)
self.model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_name,
torch_dtype=self.torch_dtype,
).to(device)
self.warmup()
- Model Loading: We load the Whisper model and processor from Hugging Face. The processor handles feature extraction, while the model performs the transcription.
- Device Configuration: The model is moved to the specified device (GPU here).
- Warmup: We run a warmup to prepare the model (useful for performance optimization).
Process Method
def process(self, spoken_prompt):
# Prepare input features from the audio
input_features = self.processor(spoken_prompt, sampling_rate=16000, return_tensors='pt').input_features
input_features = input_features.to(self.device, dtype=self.torch_dtype)
# Generate transcription
pred_ids = self.model.generate(input_features, **self.gen_kwargs)
pred_text = self.processor.batch_decode(pred_ids, skip_special_tokens=True)[0]
# Output the transcribed text
yield (pred_text, language_code)
- Audio Feature Extraction:
- The spoken_prompt (input audio) is passed through self.processor, which converts the audio waveform to input features represented as a Mel Spectrogram. This step captures time-frequency information in a way that the model can interpret.
- Parameters such as sampling_rate=16000 (standard for speech) and return_tensors=’pt’ (returning data in PyTorch tensor format) ensure compatibility with the model’s expected input.
- Model Inference: The processed input features are passed to self.model.generate, where the Whisper model predicts token IDs (representing segments of text) based on the audio. These token IDs encode the content of the spoken prompt.
- Decoding Tokens to Text: The generated token IDs are then decoded into human-readable text using self.processor.batch_decode, with skip_special_tokens=True, ensuring that any model-specific control tokens are omitted from the output.
- Output of Transcribed Text: The method yields the transcribed text along with a language_code (if multilingual), which will be passed to the next component in the pipeline. This allows the STT output to be immediately available for further processing (e.g., by a language model).
We have a detailed article on how Whisper works to do Automatic Speech Recognition (ASR); feel free to check this out!
3. Language Model (LM)
Now that we have the transcribed text, the Language Model (LM) generates a response. This could be answering a question, continuing a conversation, or translating text.
Here’s how it works:
- Tokenization: The input text is broken into tokens (words, subwords, or characters).
- Contextual Understanding: Using mechanisms like self-attention, the model understands the context and relationships between tokens.
- Self-Attention:
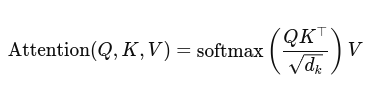
Q, K, and V are the query, key, and value matrices.
- Response Generation: The model predicts the next token in the sequence, one after another, to generate a coherent response.
- Decoding: The sequence of output tokens is converted back into text.
- Output: The generated text is passed on for speech synthesis.
Codebase Explanation
├── LLM
├── chat.py
├── language_model.py
├── mlx_language_model.py
├── openai_api_language_model.py
└── __pycache__
The LLM functionality is handled by the LanguageModelHandler class in language_model.py.
Setup Method
def setup(self, model_name='meta-llama/Llama-3.2-1B-Instruct', device='cuda', torch_dtype='float16', gen_kwargs={}, user_role='user', chat_size=1, init_chat_role=None, init_chat_prompt='You are a helpful AI assistant.'):
self.device = device
self.torch_dtype = getattr(torch, torch_dtype)
# Load tokenizer and model from Hugging Face
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype=torch_dtype, trust_remote_code=True
).to(device)
self.pipe = pipeline(
'text-generation', model=self.model, tokenizer=self.tokenizer, device=device
)
# Initialize chat history
self.chat = Chat(chat_size)
if init_chat_role:
self.chat.init_chat({'role': init_chat_role, 'content': init_chat_prompt})
self.user_role = user_role
self.warmup()
- Model Loading: We load a language model designed for instruction-following tasks.
- Pipeline Creation: A Hugging Face pipeline is set up for text generation.
- Chat Management: We use a Chat class to maintain conversation history, which helps the model generate contextually relevant responses.
- Warmup: Prepares the model for inference.
Process Method
def process(self, prompt):
# Append user input to chat history
self.chat.append({'role': self.user_role, 'content': prompt})
# Start the generation in a separate thread
thread = Thread(
target=self.pipe, args=(self.chat.to_list(),), kwargs=self.gen_kwargs
)
thread.start()
# Stream generated tokens
generated_text = ''
for new_text in self.streamer:
generated_text += new_text
# Optionally yield sentences as they are completed
yield (new_text, language_code)
# Append assistant's response to chat history
self.chat.append({'role': 'assistant', 'content': generated_text})
- Input Handling: The transcribed text is added to the chat history.
- Model Inference: The model generates a response, which is streamed token by token.
- Threading: The generation runs in a separate thread to prevent blocking.
- Chat Update: The generated response is added to the chat history.
- Output: The generated text is yielded for the next component.
4. Text to Speech (TTS)
The final step is to convert the generated text back into speech, so the system can ‘talk‘ back to the user. This is the role of Text to Speech (TTS).
Here’s how it works:
- Text Normalization: The text is processed to handle numbers, abbreviations, and special characters.
- Phoneme Conversion: The normalized text is converted into phonemes, the basic units of sound.
- Prosody Application: The system applies rhythm, stress, and intonation patterns to the phonemes.
- Acoustic Modeling: An acoustic model predicts spectrograms (visual representations of sound) from the phonemes.
- Waveform Synthesis: A vocoder converts the spectrograms into an audio waveform.
- Output: The synthesized speech is output as an audio stream.
We are using the TTS model called Parler TTS, developed by the Hugging Face team. It is a reproduction of work from the paper Natural language guidance of high-fidelity Text to Speech with synthetic annotations by Dan Lyth and Simon King, from Stability AI and Edinburgh University, respectively.
Codebase Explanation
├── TTS
├── chatTTS_handler.py
├── facebookmms_handler.py
├── melo_handler.py
├── parler_handler.py
└── __pycache__
The TTS functionality is handled by the ParlerTTSHandler class in parler_handler.py.
Setup Method
def setup(self, should_listen, model_name='ylacombe/parler-tts-mini-jenny-30H', device='cuda',
torch_dtype='float16', compile_mode=None, gen_kwargs={}, max_prompt_pad_length=8,
description='A female speaker with a slightly low-pitched voice...', play_steps_s=1, blocksize=512):
self.should_listen = should_listen
self.device = device
self.torch_dtype = getattr(torch, torch_dtype)
self.gen_kwargs = gen_kwargs
self.description = description
# Load tokenizer and model
self.description_tokenizer = AutoTokenizer.from_pretrained(model_name)
self.prompt_tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = ParlerTTSForConditionalGeneration.from_pretrained(
model_name, torch_dtype=self.torch_dtype
).to(device)
# Configure audio playback parameters
framerate = self.model.audio_encoder.config.frame_rate
self.play_steps = int(framerate * play_steps_s)
self.blocksize = blocksize
self.warmup()
- Model and Tokenizer Loading: We load the TTS model and tokenizers.
- Speaker Description: A textual description of the desired voice is used to condition the model.
- Playback Configuration: Sets parameters for how the audio will be streamed.
Process Method
def process(self, llm_sentence):
# Prepare model inputs
tts_gen_kwargs = self.prepare_model_inputs(llm_sentence)
# Create a streamer for audio output
streamer = ParlerTTSStreamer(
self.model, device=self.device, play_steps=self.play_steps
)
tts_gen_kwargs = {'streamer': streamer, **tts_gen_kwargs}
# Start TTS generation in a separate thread
thread = Thread(target=self.model.generate, kwargs=tts_gen_kwargs)
thread.start()
# Stream audio chunks
for audio_chunk in streamer:
# Resample and convert audio for playback
audio_chunk = librosa.resample(audio_chunk, orig_sr=44100, target_sr=16000)
audio_chunk = (audio_chunk * 32768).astype(np.int16)
for i in range(0, len(audio_chunk), self.blocksize):
yield np.pad(
audio_chunk[i:i+self.blocksize],
(0, self.blocksize - len(audio_chunk[i:i+self.blocksize]))
)
# Signal that listening can resume
self.should_listen.set()
- Input Preparation: The text is tokenized and prepared for the model.
- Model Inference: The TTS model generates audio frames based on the input text.
- Streaming Audio: Audio is streamed in chunks for real-time playback.
- Resampling and Conversion: Adjust the audio to the correct sample rate and format.
- Control Signal: Signals that the system can resume listening after speaking.
- Output: The audio chunks are yielded to be played back.
This code effectively translates the theoretical steps into practical implementation, using a neural TTS model to synthesize speech from text.
5. Modularity and Pipeline Integration
To build a robust and flexible system, we need to ensure that each component can operate independently and be easily swapped out or updated. This is achieved through modularity.
In our pipeline:
- Clear Interfaces: Each component communicates with others through well-defined interfaces, such as queues or data structures.
- Asynchronous Processing: Components run independently, often in separate threads, allowing for efficient processing.
- Interchangeable Components: Because components adhere to interface contracts, you can replace one model with another without affecting the rest of the system.
- Scalability: The system can be extended by adding new components or upgrading existing ones.
Codebase Explanation
The main pipeline is orchestrated in s2s_pipeline.py.
Main Function
def main():
# Parse arguments for all components
(module_kwargs, socket_receiver_kwargs, ..., facebook_mms_tts_handler_kwargs) = parse_arguments()
# Setup logging
setup_logger(module_kwargs.log_level)
# Prepare arguments for all components
prepare_all_args(
module_kwargs, whisper_stt_handler_kwargs, ..., facebook_mms_tts_handler_kwargs
)
# Initialize queues and events for inter-component communication
queues_and_events = initialize_queues_and_events()
# Build the pipeline by initializing handlers
pipeline_manager = build_pipeline(
module_kwargs, socket_receiver_kwargs, ..., queues_and_events
)
# Start the pipeline
try:
pipeline_manager.start()
except KeyboardInterrupt:
pipeline_manager.stop()
- Argument Parsing: Configures each component based on user input or configuration files.
- Logging: Sets up logging for debugging and monitoring.
- Initialization: Prepares queues and events that allow components to communicate.
- Pipeline Construction: build_pipeline initializes each component and sets up their connections.
- Execution: The ThreadManager starts each component in its own thread.
Handler Classes
Each component extends the BaseHandler class defined in baseHandler.py:
class BaseHandler:
def __init__(self, stop_event, queue_in=None, queue_out=None, setup_args=(), setup_kwargs={}):
self.queue_in = queue_in
self.queue_out = queue_out
self.stop_event = stop_event
self.setup(*setup_args, **setup_kwargs)
def setup(self, *args, **kwargs):
pass
def process(self, *args, **kwargs):
pass
def run(self):
while not self.stop_event.is_set():
# Read from input queue
data = self.queue_in.get()
# Process the data
for output in self.process(data):
# Write to output queue
self.queue_out.put(output)
- Initialization: Sets up the necessary queues and events.
- Run Loop: Continuously processes input data and outputs results.
- Extensibility: By overriding setup and process, each handler can implement its specific functionality.
Thread Management
The ThreadManager in thread_manager.py handles starting and stopping threads:
class ThreadManager:
def __init__(self, handlers):
self.handlers = handlers
self.threads = []
def start(self):
# Start a thread for each handler
for handler in self.handlers:
thread = threading.Thread(target=handler.run)
thread.start()
self.threads.append(thread)
def stop(self):
# Signal all handlers to stop
for handler in self.handlers:
handler.stop_event.set()
# Wait for all threads to finish
for thread in self.threads:
thread.join()
- Start: Initializes and starts all handler threads.
- Stop: Signals all handlers to stop and waits for threads to finish.
Inter-Component Communication
Queues and events are used for communication:
- Queues: Queue objects are used to pass data between components asynchronously.
- Events: Event objects signal state changes, like when to stop listening or when processing is complete.
Modularity in Action
Because each component adheres to a standard interface (input queue, output queue, stop event), you can:
- Swap Components: Replace the STT model with a different one by changing the handler class.
- Add Features: Introduce new processing steps without disrupting existing components.
- Configure Behavior: Adjust settings for each component via configuration files or command-line arguments.
Download the Code Here

Speech to Speech – Inference
Now, the coolest part: let’s play with the codebase and make some detailed observations with inference results. We use Nvidia Geforce RTX 3070 Ti Laptop GPU to run the inference. Let’s start:
First, we need to set up our environment:
We will clone the speech to speech repository:
! git clone https://github.com/huggingface/Speech to Speech.git
Then, go to the project directory:
! cd Speech to Speech
Then, we need to set up the environment using the following command:
! conda create -n s2s python=3.11
! conda activate s2s
We are using miniconda to create the virtual environment. Within the environment, we need to install the UV package. It’s a package installer built on top of pip, more efficient and faster.
pip install uv
Then we install the required packages with requirements.txt:
uv pip install -r requirements.txt
And we are done with the environment setup. The pipeline can be run in two ways:
- Server/Client approach: Models run on a server, and audio input/output is streamed from a client.
- Local approach: Runs locally.
We are going to run it locally within our system. First, we will start the server with s2s_pipeline.py:
python s2s_pipeline.py --recv_host 0.0.0.0 --send_host 0.0.0.0 --lm_model_name meta-llama/Llama-3.2-1B-Instruct --stt_compile_mode reduce-overhead --tts_compile_mode reduce-overhead
We are using the Llama-3.2-1B-Instruct model as LLM and the rest set as default. You can use any available instruct model in the hugging face hub. Also, you can use any other available model for STT or TTS. Check the official readme for all the available models. You can play with the arguments as well, which you can see in the arguments_classes folder.
Next, we start the local client using the listen_and_play.py file;
python listen_and_play.py --localhost
With this, we can speak to our model. Following is the first result we got:
With the above-chosen configuration, the StS pipeline uses nearly 7.2 GBs of V-RAM. Starting from the initial voice input, the system accurately detects and transcribes speech, as displayed in the chat interface. The response generated by the Language Model (LLM) is coherent and contextually appropriate, while the Text-to-Speech (TTS) model delivers a natural, clear, and well-projected voice output.
We also implemented a client-server approach, initiating the client to connect with a remote server:
python listen_and_play.py --your-server-IP-adress
Here, the pipeline also works well without any issues. Even the processing is close to real-time with minimal latency. The pipeline can remember the previous contexts as well.
So, we observed the inference results, and here are a few points:
It generally skips the numbers (like the lifespan over here).
When it’s a long-generated response from LLM, the STT splits the response into small chunks and speaks it. Even in this poem recitation, all the rhymings with proper phonemes are maintained by the pipeline.
This time, the model mispronounced the numbers. However, the answer is logically correct.
Also, one of the edge cases that we found is the pipeline is not capable of pronouncing the shot forms like ‘CV’ or ‘AI.’ Here, you can observe the reply from LLM is correct, but the TTS model is not able to pronounce it properly.
Now, we have an overview of the speech to speech pipeline. Let’s recap what we have learned so far.
The Journey of Speech to Speech – Quick Recap
Understanding Speech to Speech (StS): The article introduces Speech to Speech as a process where machines can interact with humans using natural speech. It involves converting spoken language to text, processing it with a language model, and generating a spoken response.
Applications of StS Technology: StS is widely used in various fields such as virtual assistants (Siri, Alexa), healthcare (hands-free documentation), customer service (automated voice agents), language translation, robotics (humanoids like Tesla Optimus), and autonomous vehicles, enhancing efficiency and accessibility.
Components of the StS Pipeline:
- Voice Activity Detection (VAD): Detects and filters out non-speech segments from the audio input.
- Speech to Text (STT): Transcribes spoken words into text using models like Whisper.
- Language Modeling (LM): Processes the transcribed text to generate appropriate responses using large language models (LLMs).
- Text to Speech (TTS): Converts the generated text back into speech using models like Parler TTS.
Inference and Observations: All the models of the Speech to Speech pipeline work flawlessly. After tuning the parameters, the TTS model can fluently vocalize even lengthy responses generated by the LLM. In some cases, such as with numbers or abbreviations like “AI” or “LLM,” the TTS model struggles to pronounce them accurately.
Conclusion
You’ve now explored the fascinating world of Speech to Speech technology and seen how machines can understand and respond to human speech. From voice detection to language modeling and speech synthesis, each component works together to create seamless interactions. Whether you’re eager to build your own StS system or just curious about the tech behind virtual assistants, we hope this journey has been insightful. The future of human-computer interaction is bright, and you’re at the forefront!
References
Hugging Face Speech to Speech Github
Except for the inference results, all the assets were taken from YouTube and Google Image searches.






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning