




Vision-Language Models (VLMs) are powerful and figuring out how well they actually work is a real challenge. There isn’t one single test that covers everything they can do. Instead, we need to use the ...
Search Results for: c
AnomalyCLIP : Harnessing CLIP for Weakly-Supervised Video Anomaly Recognition
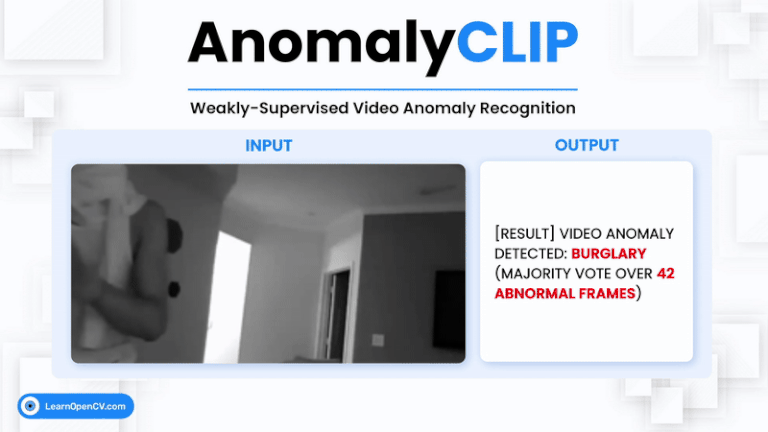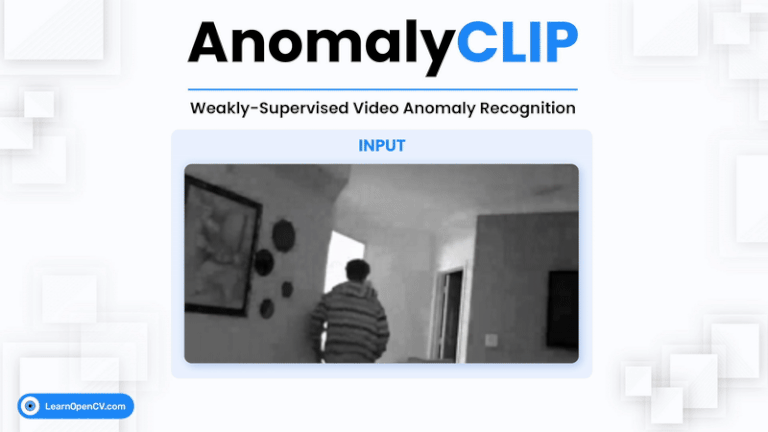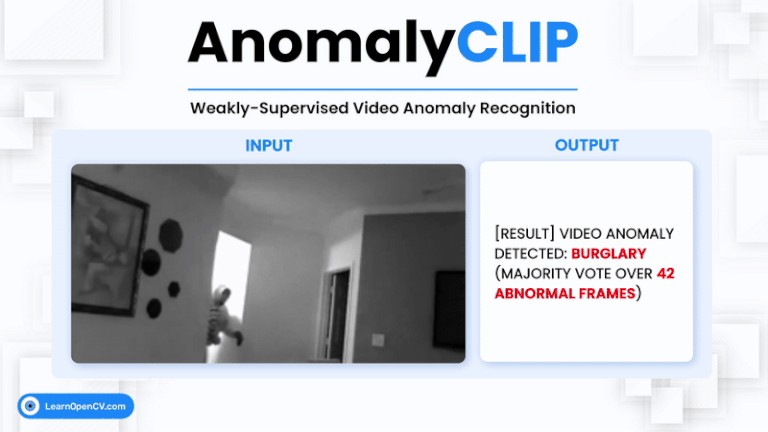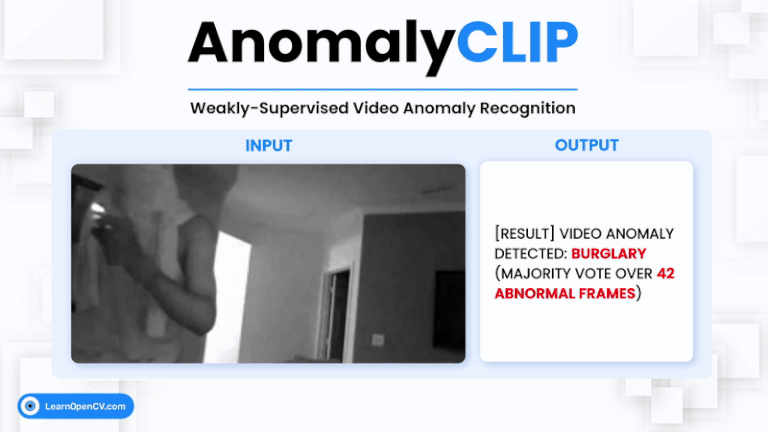
Video Anomaly Detection (VAD) is one of the most challenging problems in computer vision. It involves identifying rare, abnormal events in videos - such as burglary, fighting, or accidents - amidst ...
AI for Video Understanding: From Content Moderation to Summarization
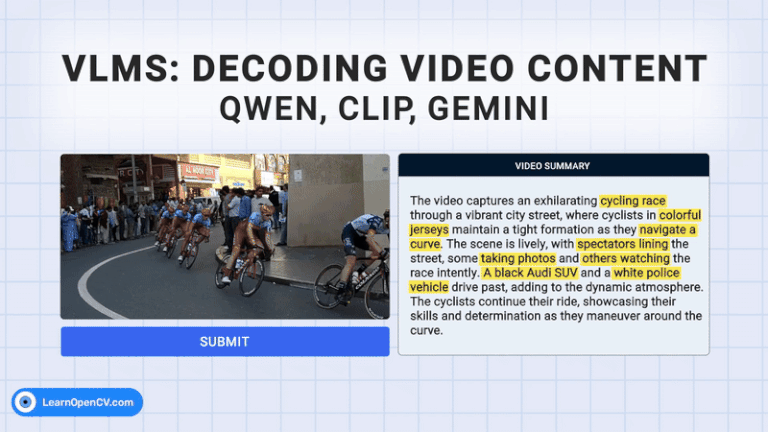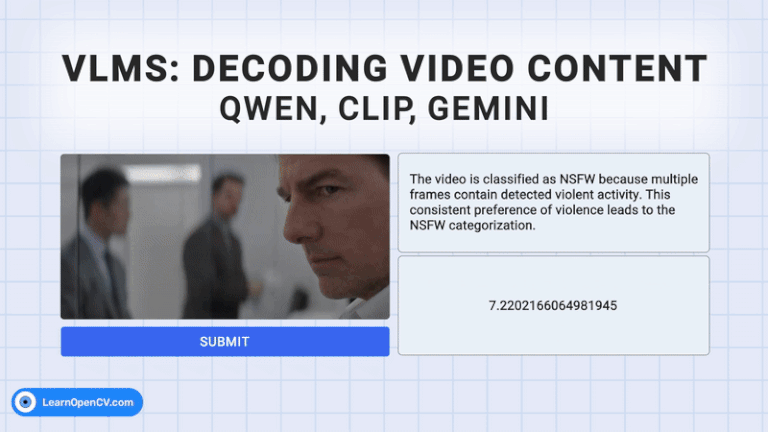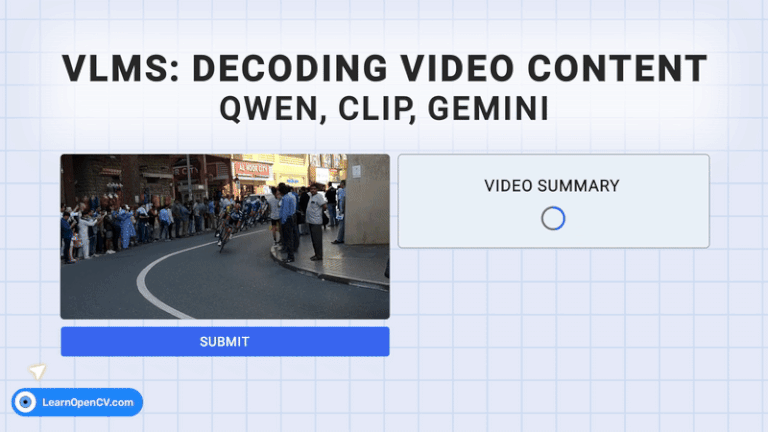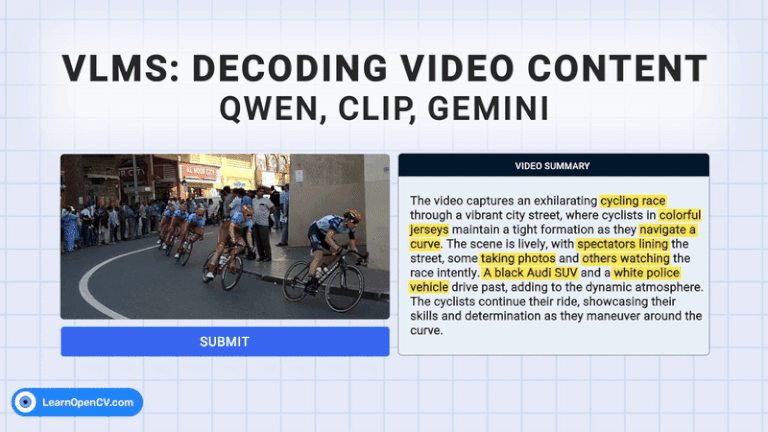
The rapid growth of video content has created a need for advanced systems to process and understand this complex data. Video understanding is a critical field in AI, where the goal is to enable ...
Object Detection and Spatial Understanding with VLMs ft. Qwen2.5-VL
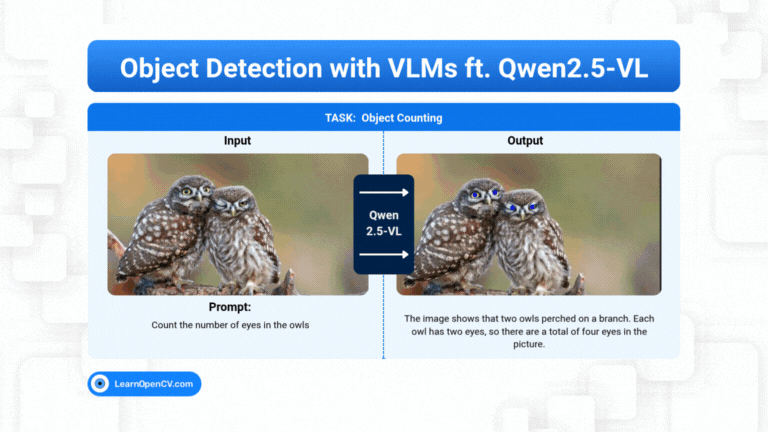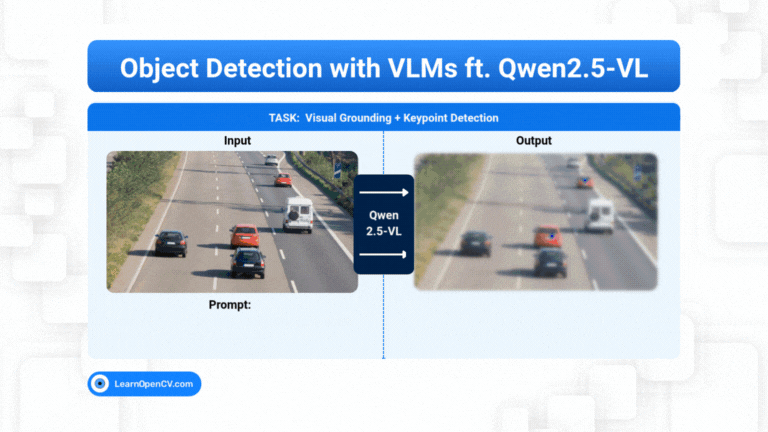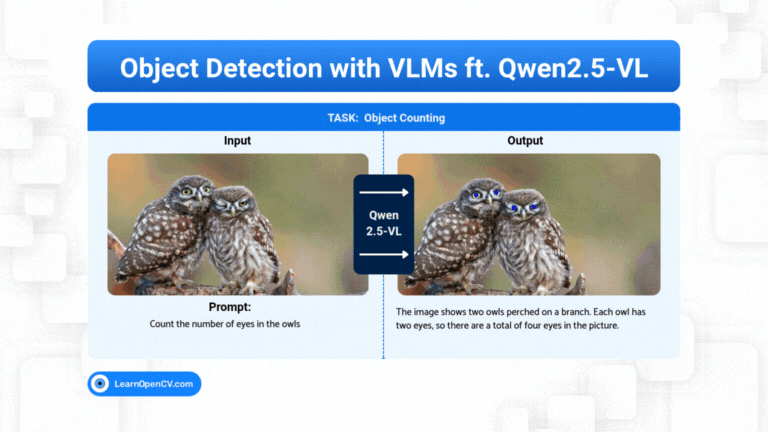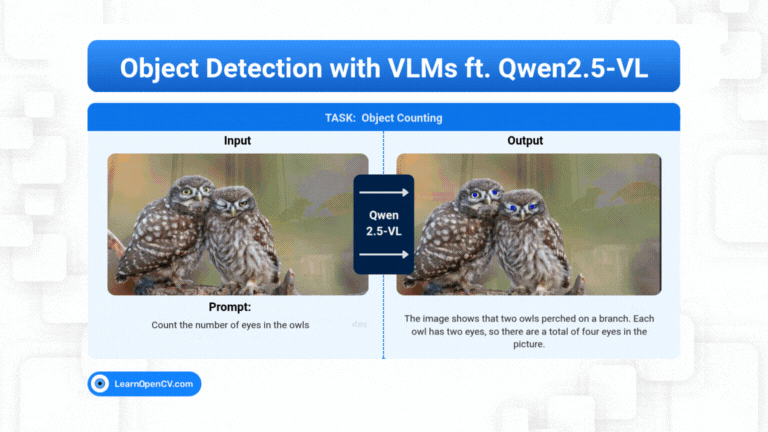
Object Detection is predominantly a vision task where we train a vision model, like YOLO, to predict the location of the object along with its class. But still it depends on the pre-trained classes, ...
LangGraph: Building Self-Correcting RAG Agent for Code Generation

Welcome back to our LangGraph series! In our previous post, we explored the fundamental concepts of LangGraph by building a Visual Web Browser Agent that could navigate, see, scroll, and ...
Inside RoPE: Rotary Magic into Position Embeddings
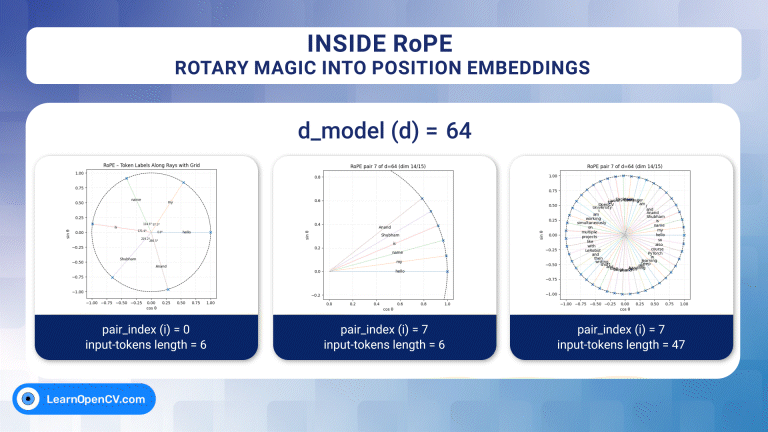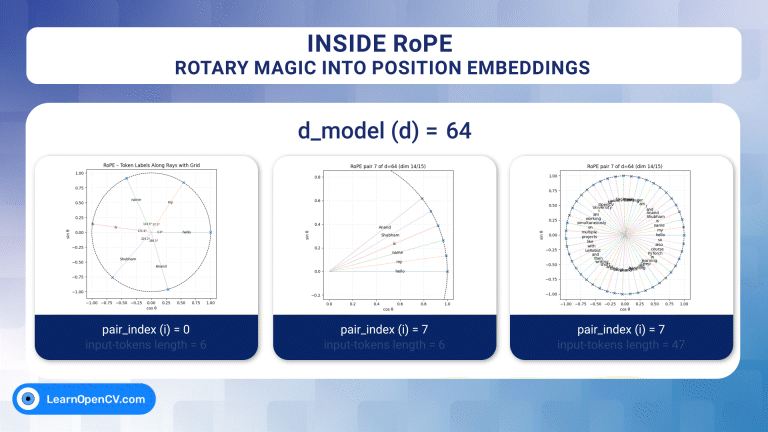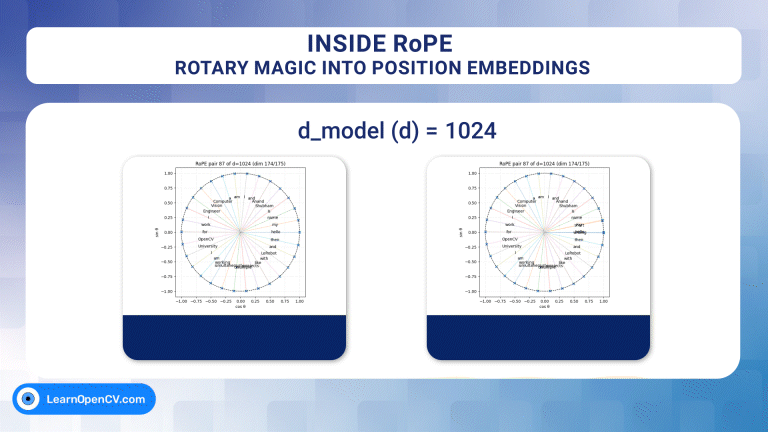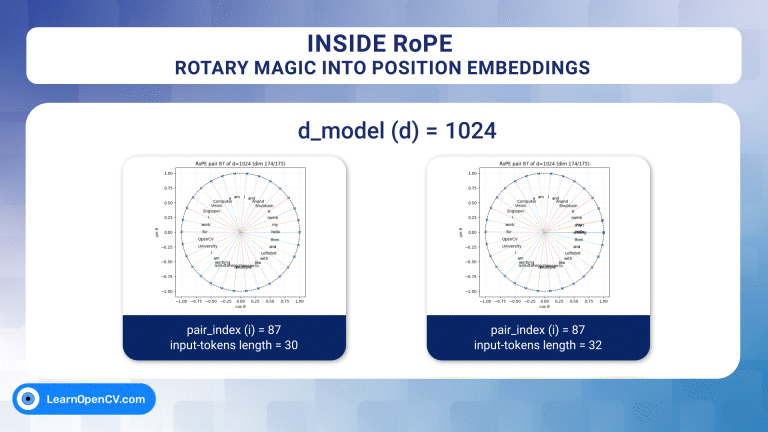
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which ...

