

The domain of image generation has achieved remarkable milestones, particularly through the advent of diffusion models. However, a persistent challenge has been the computational cost associated with their iterative sampling process, which often requires numerous steps to denoise an initial latent variable into a coherent image. Addressing this critical bottleneck, SANA-Sprint emerges as a novel and highly efficient image generation diffusion model.
Developed through a collaborative effort by researchers from NVIDIA, MIT, Tsinghua University, Hugging Face, and independent contributors, SANA-Sprint is engineered to dramatically reduce inference times while preserving, and in some cases enhancing, image quality. The model is capable of generating 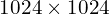 resolution images in as little as 0.1 seconds on an NVIDIA H100 GPU and 0.31 seconds on consumer-grade hardware like the NVIDIA RTX 4090.
resolution images in as little as 0.1 seconds on an NVIDIA H100 GPU and 0.31 seconds on consumer-grade hardware like the NVIDIA RTX 4090.
- Theoretical Underpinnings: Diffusion and Consistency Models
- Core Methodologies of SANA-Sprint
- Experimental Validation and Performance Benchmarks of SANA-Sprint
- Conclusion
- Key References
Theoretical Underpinnings: Diffusion and Consistency Models
Before grasping the methodology behind SANA-Sprint, it is essential to get a brief idea about the foundational generative modeling paradigms it evolves from: Diffusion models and Consistency models.
Diffusion models operate by learning to reverse a stochastic process that gradually adds noise to data. Starting from a clear image (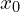 ) and gradually adding noise over time
) and gradually adding noise over time 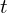 until it becomes pure static (
until it becomes pure static (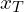 ), diffusion models learn to reverse this, starting from and iteratively removing noise to recover .
), diffusion models learn to reverse this, starting from and iteratively removing noise to recover .

Consistency Models (CMs) were introduced as an approach to reduce the sampling time as encountered with Diffusion models. The core principle of a CM is to learn a function, 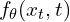 , that can directly map any point
, that can directly map any point 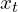 along a solution trajectory of the PF ODE (Probability Flow Ordinary Differential Equations) to the trajectory’s origin, (or a minimally noisy version
along a solution trajectory of the PF ODE (Probability Flow Ordinary Differential Equations) to the trajectory’s origin, (or a minimally noisy version 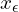 ).
).
The defining characteristic is “self-consistency”: for any two points and 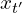 residing on the same ODE trajectory, the model’s output must be consistent, i.e.,
residing on the same ODE trajectory, the model’s output must be consistent, i.e., 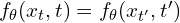 . This property theoretically enables single-step generation via a single evaluation
. This property theoretically enables single-step generation via a single evaluation 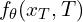 .
.
Continuous-Time Consistency Models (CTCMs), also referred to as sCMs in the SANA-Sprint paper, extend this concept by treating time as a continuous variable, providing a more robust framework.
Core Methodologies of SANA-Sprint
SANA-Sprint’s breakthrough performance is the result of several synergistic innovations designed to optimize both speed and image fidelity. These methodologies address fundamental challenges in model distillation and training stability.
1. Training-Free Transformation to TrigFlow for sCM Distillation
A key architectural choice in SANA-Sprint is its foundation on a pre-trained SANA model, which itself is a Flow Matching model.
sCM simplify continuous-time CMs using the TrigFlow formulation. While this provides an elegant framework, most score based generative models are based on diffusion or flow matching formulations. A possible approach can be to develop separate training algorithms for continuous-time CMs under these formulations, but this requires distinct algorithm designs and hyperparameters tuning, increasing complexity. Another approach is also possible in which we can pre-train a dedicated TrigFlow model , but this significantly increases the computational complexity.
To address these challenges, the authors proposed a simple method to transform a pre-trained flow matching model into a TrigFlow model through straightforward mathematical input and output transformations. This approach eliminates the need for separate algorithm designs while fully leveraging existing pre-trained models. The transformation process for general diffusion models can be carried out in a similar manner.


2. Stabilizing Continuous-Time Distillation
While continuous-time distillation offers theoretical advantages, its practical application can be hampered by training instabilities, particularly when dealing with large models or high-resolution outputs, where gradients can become excessively large.
SANA-Sprint integrates two critical mechanisms to ensure robust and stable training. The first is the implementation of a Dense Time-Embedding. The authors observe that in sCMs, instability can arise from terms related to the time derivative of the time embedding (conceptually, 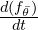 ), especially if the noise coefficient scales rapidly with time (e.g., a previous formulation
), especially if the noise coefficient scales rapidly with time (e.g., a previous formulation 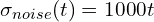 ). SANA-Sprint refines this by adopting a simpler
). SANA-Sprint refines this by adopting a simpler 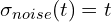 schedule. This modification significantly dampens gradient norm fluctuations (from values
schedule. This modification significantly dampens gradient norm fluctuations (from values 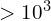 to more stable levels), leading to a more stable training dynamic and faster convergence.
to more stable levels), leading to a more stable training dynamic and faster convergence.
The second stabilization technique is QK-Normalization. As model parameter counts increase (e.g., from 0.6B to 1.6B parameters in SANA-Sprint variants) and output resolutions grow, the attention mechanisms within the Transformer architecture can become a source of instability.
To counteract, SANA-Sprint incorporates Root Mean Square Normalization (RMSNorm) into the Query ( ) and Key (
) and Key (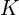 ) projection layers of the teacher model during its fine-tuning phase prior to distillation. This targeted normalization effectively stabilizes the attention computations, preventing issues like training collapse and enabling consistent performance even with larger and more complex model configurations.
) projection layers of the teacher model during its fine-tuning phase prior to distillation. This targeted normalization effectively stabilizes the attention computations, preventing issues like training collapse and enabling consistent performance even with larger and more complex model configurations.

3. Augmenting Continuous-Time Consistency Models with GANs (LADD)
Although sCM excels at aligning the student model with its teacher and preserving output diversity, its inherent dependency on local time intervals for distillation can sometimes lead to slower convergence and may not fully capture global image characteristics for optimal fidelity.
To address this, SANA-Sprint incorporates Latent Adversarial Diffusion Distillation (LADD). This technique introduces a Generative Adversarial Network (GAN) objective to provide direct global supervision across various timesteps.
Instead of operating in the high-dimensional pixel space, LADD employs the frozen, pre-trained teacher model as a feature extractor. A discriminator network, 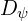 , is then trained in this latent feature space to distinguish between features derived from real noised data,
, is then trained in this latent feature space to distinguish between features derived from real noised data,  , and those from synthetic noised data generated by the SANA-Sprint student model (
, and those from synthetic noised data generated by the SANA-Sprint student model (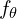 ),
),
Experimental Validation and Performance Benchmarks of SANA-Sprint

The efficacy of SANA-Sprint’s innovations is substantiated by comprehensive experimental results, which highlight its exceptional inference speed, high image quality, and efficient training resource utilization.
SANA-Sprint achieves remarkable inference speeds, generating resolution images in a mere 0.10 to 0.18 seconds when executed on an NVIDIA H100 GPU. When compared against FLUX-Schnell, another prominent step-distilled model, SANA-Sprint (in its 1-step configuration) exhibits a Transformer latency that is 64.7 times faster than Flux Schnell. Even when considering the entire pipeline including VAE and text encoding, SANA-Sprint maintains an approximate 10x speed advantage.

This acceleration does not come at the expense of visual quality. In single-step generation, the 1.6B parameter SANA-Sprint model achieves a Fréchet Inception Distance (FID, the lower the better) of 7.59 and a GenEval score (measuring text-image alignment) of 0.74. These figures surpass those of FLUX-Schnell (7.94 FID / 0.71 GenEval), despite SANA-Sprint’s significantly faster execution.
The smaller 0.6B SANA-Sprint variant also delivers impressive one-step performance with a 7.04 FID and 0.72 GenEval.
Training the 1.6B SANA-Sprint model requires substantially less memory than training a 12B FLUX model, and even less than distilling a 0.9B SDXL model using alternative methods.
A particularly compelling application is its integration with ControlNet, enabling real-time interactive image generation from conditional inputs like sketches, with a latency of only 0.25 seconds on an H100 GPU. This facilitates immediate visual feedback, a crucial feature for dynamic creative workflows.
Conclusion
SANA-Sprint stands out as a major advancement in generative AI, offering a compelling solution to the trade-off between speed and image quality. It generates incredibly detailed images at unprecedented speeds thanks to a carefully crafted methodology. This includes a novel way to adapt existing models without extensive retraining, techniques that keep the training process stable even for large models.
SANA-Sprint empowers creative professionals with tools that offer instant visual feedback, transforming how digital art and designs are made. It opens possibilities for more engaging AI in consumer software, such as the rapid creation of custom avatars or unique visual elements. The open-source release of SANA-Sprint is a crucial step that will likely accelerate innovation, helping developers build even more sophisticated and practical AI-driven creative systems.
Key References
- Chen, J., Xue, S., Zhao, Y., et al. (2025). SANA-Sprint: One-Step Diffusion with Continuous-Time Consistency Distillation. arXiv:2503.09641.
- Xie, E., Chen, J., Chen, J., et al. (2024). SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers. arXiv:2410.10629.
- Lu, C., & Song, Y. (2024). Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models. arXiv:2410.11081.
- Sauer, A., Boesel, F., Dockhorn, T., et al. (2024). Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation. SIGGRAPH Asia 2024 Conference Papers.
- Project Page of SANA-Sprint: https://nvlabs.github.io/Sana/Sprint/



100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning