LightRAG: Simple and Fast Alternative to GraphRAG for Legal Doc Analysis
This article discusses the architecture of LightRAG from HKU, exploring its in-depth internal workings and comparing it with GraphRAG and NaiveRAG for local document analysis.
LightRAG is an innovative approach based on GraphRAG that combines the attributes of Knowledge Graphs with embedding-based retrieval systems, making it fast as well as performant, achieving SOTA results. It outperforms bothnaive RAG and GraphRAG across various benchmarks.
Let’s say your are a GenAI startup working on B2B or SaaS LLM applications and you recently came across Microsoft GraphRAG project. Impressed by their demo results and you decided to integrate it into your document analysis app (RAG pipeline) to scale it up for various domains and business models. But you’re GPU poor and can’t host your own LLM, so you turned to OpenAI, but your API credit bills are skyrocketing quickly draining your budgets as this approach demands excessive API calls. Well, in such scenarios, where you can’t compromise on retrieval quality but also need cost effective methods, LightRAG can save your wallet and might help you go from RAGs to riches. How? By employing a dual-level retrieval system, it mitigates the computational overhead, slow and time-intensive challenges associated with GraphRAG.
We knew that the legal, finance, and healthcare sectors, in particular, can benefit from SOTA RAG approaches due to their large, complex, and multi-vertical data that demands frequent updates to ensure relevant insights.
If you’re an investment bank or professional services firm, you operate in a ‘zero-error’ environment. You can’t have an LLM hallucinate and give you an unfactual answer when millions of dollars are at stake.
Advanced RAG techniques like GraphRAG and LightRAG are game changers in these areas, offering meaningful improvements and unparalleled precision over naive RAG.
According to the paper, LightRAG performs exceptionally well on legal datasets which is one of its strengths. To validate this, we will use the “Companies Act 2013” and “Constitution of India” PDFs as samples for legal document analysis.
The topics we will be discussing in this article are outlined as follows:
Existing RAG systems have significant limitations, including reliance on flat data representations and inadequate contextual awareness, which can lead to fragmented answers that fail to capture complex inter-dependencies.
Baseline RAGs are found to be inefficient because,
They fail to capture interconnectedness between fragmented information, spread across multiple documents making it challenging to outline comprehensive insights.
Limited contextual understanding arises from a lack of a holistic overview of the retrieved chunks.
Scalability inefficiencies occur when the corpus of data grows, resulting in poor retrieval quality.
To address these, Microsoft introduced a novel approach called GraphRAG which incorporates graph structures into the text indexing and retrieval process.
Note: We will explore nuances in GraphRAG and spend some time here, as it shares attributes and overlapping concepts with LightRAG.
Gentle Intro to GraphRAG by Microsoft
FIG 2 Knowledge Graph Example Contemporary Scenarios in AI
Knowledge Graphs are data structures consisting of a set of nodes that preserve relationships between different entities present across various data points. Structured knowledge graphs enable GraphRAG (Edge et al.) to excel in multi-hop reasoning by connecting dots or contrasting pieces of information.
FIG 3 GraphRAG KG Visualization
For example, from contemporary scenarios a stock analyst might want to ask LLMs: “How will the U.S. election results impact Indian stock market trends?” or How did ChatGPT’s success fuel NVIDIA’s stock surge?
Questions like these are inherently a Query-Focused Summarization (QFS) where query context matters rather than simple retrieval. Baseline RAG often struggles to provide a comprehensive answer, as it lacks full context and fails to aggregate relationships between different nodes across the entire dataset. However GraphRAG shines at QFS to effectively draw conclusions with global understanding (like humans) even when the information needed is not explicitly stated but implied in the basket of sources.
Similar to typical RAG, GraphRAG pipeline also involves Indexing and Querying.
FIG 4 GraphRAG Pipeline
However the indexing process involves 2 stages as follows,
Indexing – GraphRAG
STAGE 1: Knowledge Graph (KG) Creation To construct a incremental structured KG, GraphRAG uses LLM’s to extract entities and relationships from the source documents. This process relies on a meticulously crafted prompt and multi-part gleaning checks.
GRAPH_EXTRACTION_PROMPT = """
-Goal-
Given a text document that is potentially relevant to this activity and a list of entity types, identify all entities of those types from the text and all relationships among the identified entities.
"""
CONTINUE_PROMPT = "MANY entities and relationships were missed in the last extraction. Remember to ONLY emit entities that match any of the previously extracted types. Add them below using the same format:\n"
LOOP_PROMPT = "It appears some entities and relationships may have still been missed. Answer YES | NO if there are still entities or relationships that need to be added.\n""
Step 1: Entities are represented as individual nodes in the KG having information about name, organization or category and a brief description about the entity.
Step 1. Identify all entities. For each identified entity, extract the following information:
- entity_name: Name of the entity, capitalized
- entity_type: One of the following types: [{entity_types}]
- entity_description: Comprehensive description of the entity's attributes and activities
Format each entity as ("entity"{tuple_delimiter}<entity_name>{tuple_delimiter}<entity_type>{tuple_delimiter}<entity_description>)
Step 2: Relationships are represented as edges between different nodes with a source and target entity ID. This defines the relationship between entities and rates them with connection weights aka strengthscores ranging between 1 to 10.
Step 2. From the entities identified in step 1, identify all pairs of (source_entity, target_entity) that are *clearly related* to each other.
For each pair of related entities, extract the following information:
- source_entity: name of the source entity, as identified in step 1
- target_entity: name of the target entity, as identified in step 1
- relationship_description: explanation as to why you think the source entity and the target entity are related to each other
- relationship_strength: a numeric score indicating strength of the relationship between the source entity and target entity
Format each relationship as ("relationship"{tuple_delimiter}<source_entity>{tuple_delimiter}<target_entity>{tuple_delimiter}<relationship_description>{tuple_delimiter}<relationship_strength>)
FIG 5 Example of Entity and Relations in KG Source
STAGE 2 : Semantic Clustering
In the next stage, based on the density of node connections and for scalability, the Leiden algorithm is applied to discover modular communities by grouping closely related nodes into hierarchical clusters
Community detection is used to partition the graph index into groups of elements (nodes, edges, covariates) that the LLM can summarize in parallel at both indexing time and query time.
– GraphRAG, Microsoft 2024
This helps to reduce the search space efficiently navigating the KG by focusing on highly correlated communities rather than the entire graph.
Using LLMs, these communities are summarized with a bottom-up approach which serves as descriptors that have complete coverage of graph index.
Querying – GraphRAG
During the querying phase, when a user asks a question, entities and relationships within the query are identified for QFS. By comparing these elements between questions and the graph index, the most relevant communities are identified.
Then these community summaries are randomly shuffled and intermediate responses at different community levels (local or global level) are generated by LLMs along with a helpfulness score ranging between 0 to 100 . This score indicates the relevance of the generated answer to the user query. The final global answer is generated using a multi stage map reduce approach, aggregating intermediate partial responses ranked descendingly based on helpfulness score as the LLMs context.
Graph RAG supports both local and globalquery workflows. We will learn more about this in the LightRAG methodology which follows a similar approach with a small difference.
Advantages of GraphRAG
GraphRAG handles global or high-level queries exceptionally well and consistently performs better than naive or baseline RAG.
It doesn’t suffer from scalability issues when the dataset is large like naive RAG.
It offers enhanced contextual understanding and greater interpretability by grounding information within the graph index enabling entity or relation source citations.
Disadvantages of GraphRAG
GraphRAG is often painfully slow to run as it requires multiple LLM API calls potentially hitting rate limits.
It is extremely costly. The internet community based on testing suggests with GPT4o, it could cost around $6- $7 to index a simple book like ‘A Christmas Carol by Dickens’ having 32k words.
To incorporate new data into existing graph indexes, we will need to reconstruct the entire KG for previous data as well, which is an inefficient approach.
There are no explicit deduplication steps performed on repeated elements which results in a noisy graph index.
Even though GraphRAG seems promising, it’s not an efficient solution due to its operational cost and computation complexity. So what’s next?
KG-RAG is still in its early stages, and there is no consensus on how to effectively retrieve entities and relationships from KGs or how to integrate vector similarity search with graph structures.
LightRAG Architecture: A Simple, Fast, and Efficient Graph x RAG
FIG 7 Overall architecture of LightRAG Architecture from Paper
LightRAG enhances the retrieval process by segmenting documents into smaller, more manageable chunks Di. This chunking strategy enables quick identification of relevant content without the need to go through the entire document.
Graph Based Text Indexing
To identify the key information needed, an LLM is used to identify entities (e.g., names, dates, locations, and events) and their relations to build an overarching knowledge graph.
This phase can be mathematically formulated as,
Where,
represents the resulting knowledge graph.
Let’s take the following example for better understanding and consider it uses a sentence level chunking mechanism.
Sample text 1:
Chunk 1:
Elon Musk envisions SpaceX‘s Mechazilla tower enhancing booster reusability to support sustainable space exploration.
Chunk 2:
Operated by SpaceX, Mechazilla is designed to catch the Super Heavy booster, reducing disposable components, lowering costs, and minimizing environmental impact.
Sample text 2:
Chunk 1:
“Musk’s commitment to sustainability is also reflected in Tesla, where he drives green energy innovations through electric vehicles and solar solutions. Tesla’s focus on renewable energy technologies complements Musk’s sustainability goals for SpaceX.”
To synthesize KG for the above chunks from two samples, three preprocessing steps are performed,
Step 1: Extracting Entities and Relationships, R(.): As we saw in GraphRAG, similarly here key word extraction prompt is sent to the LLM to obtain the nodes and edges. From the above sample sentence, “Elon Musk envisions SpaceX’s Mechazilla tower enhancing booster reusability”
Step2: LLM Profiling for Key Value Pair Generation P(.): Once the elements are extracted, an LLM empowered profiling function P(.) is employed to create structured entity key-value pairs and relationship KV pair for each entity node in 𝓥 and relation in Ɛ respectively.
A Key (K) is a word or short phrase (e.g., Elon Musk) while Value (V) is a paragraph summarizing relevant chunks. Typically entities will have their name as sole index whereas relations may have multiple index keys to capture broader themes from connected entities. Using these KV pairs an initial knowledge graph is constructed.
This profiling enables efficient retrieval with relevant summaries that support text generation.
An entity KV pair will look like,
Key (K): “Elon Musk”
Value (V): “CEO of SpaceX and Tesla, Elon Musk envisions using the Mechazilla tower to enhance rocket reusability, aiming to reduce space travel costs and advance sustainable space exploration.”
As discussed in the introduction, LightRAG combines graph indexing and standard embedding based approach. To be specific, the value(V) of entities and relations in key-value pairs after LLM profiling are passed to an intermediate step to generate vector embeddings using an embedding model. These KV data structures offer a more precise retrieval than less accurate standard embedding only RAG or inefficient chunk traversal techniques in GraphRAG.
Step 3: Deduplication to Optimize Graph Operation D(.) : For efficient data processing, repetitive entities and relations are merged thereby reducing both overhead and overall graph size.
For e.g., repeated instances of entities like SpaceX and Mechazilla will be merged into the same node, allowing for different edges to represent distinct relationships.
After deduplication we get a final optimized version of the initial KG.
Aided by Graph Based Text Indexing, LightRAG pipeline employs a dual level retrieval strategy. This approach identifies low level and high level keys from multi hop subgraphs within the KG to answer a diverse set of queries.
Low level Retrieval: Targets specific, granular information from individual nodes and edges to handle local queries, such as “What is Mechazilla?” At this level it provides detailed node-level insights.
High Level Retrieval: Aggregates information from multiple entities from different documents to answer global queries that require broader themes or abstractions such as “How does Elon Musk’s vision promote sustainability across his ventures?”
FIG 10 Dual level Retrieval and Generation
How does LightRAG utilize knowledge graphs?
For a given query, LightRAG’s retrieval algorithm extracts both local k(l) and global query keywords k(g). Then using vector similarity relevant entities are matched to local query with low level keys and global query keywords with high level concepts.
By gathering one-hop neighboring nodes in local subgraphs, LightRAG integrates an additional layer of context, improving the relevance of results with edges within the graph index. This dual-level retrieval structure combines keyword matching with relevant structural information induced from the constructed KG.
FIG 11 Retrieved Entities Relations and Contexts
The retrieved content is the output of the LLM profiling stage which contains names, descriptions of entities and relations and short summaries from the original text.
Computation Cost of LightRAG framework
In the era of GenAI, the business wealth you can create with LLM or RAG applications depends on how much API credits you have and $X per 1M input tokens.
Here, an LLM is called both during indexing and querying phases similar to GraphRAG.
During querying, LLM extracts keywords from the query to retrieve relevant entities and relations rather than entire chunks which reduces retrieval input tokens overhead compared to standard RAG.
In the retrieval phase, LightRAG requires less than 100 tokens and a single API call, whereas in GraphRAG requires `no.of communities x avg no. tokens per community` tokens, demanding excessive API calls that could potentially hit rate limits.
FIG 12 Comparison of Cost in Terms of Tokens and API Calls for GraphRAG and LightRAG on the Legal Dataset from Paper
For incremental data updates, GraphRAG incurs significantly higher costs due to the need for community restructuring within the KG, whereas LightRAG efficiently manages updates with minimal API calls.
Benchmarks Discussion from the Paper
The benchmark was conducted on the UltraDomain dataset, a collection of textbooks encompassing 18 distinct domains.
The authors selected the Agriculture, CS, Legal and Mix data domains alone for their experiments and they report that LightRAG is the new SOTA across various evaluation metrics like comprehensiveness, diversity, empowerment and overall response quality.
FIG 13 Evaluation Dimensions
All the experiments were conducted using GPT-4o-mini with a chunk size of 1200 for consistency. This is similar to the benchmarking approach discussed in the GraphRAG paper where the LLM (GPT4o-mini) evaluates responses of LightRAG against others like HyDE, NaiveRAG and GraphRAG. The winner is chosen based on the quality of responses specific to local or global queries.
FIG 14 Comparison of LightRAG with existing methods
Legal Document Analysis with LightRAG
Now it’s time to do some hands-on testing. For this, we’ll use two legal documents as the legal domain presents an ideal use case for RAG. Individuals or corporate people need an effective and straightforward system to track the legal aspects of their organization or rights. Legal contexts are highly complex, and even trained legal professionals often struggle to navigate between case files to identify patterns or connect the dots between related case verdicts or judgements. In these scenarios GraphRAG principles become handy providing overarching insights reducing the cumbersome manual search which provides contextually grounded citations as nodes and edges in KG.
If you’re working in integrating GenAI in legal space, you may find valuable in going through this [Link] insightful post discussing the effectiveness of graph based approaches in legal contexts.
Our Legal Document Analysis with LightRAG workflow will look as follows,
VIDEO 1: LightRAG – Legal Doc Analysis Workflow – Illustration
Download Code
To easily follow along this tutorial, please download code by clicking on the button below. It's FREE!
To set up LightRAG, you can either clone the repository or install it via PyPI.
Installing Dependencies:
!pip install lightrag-hku
!pip install pdfplumber
or
!git clone https://github.com/HKUDS/LightRAG.git
cd LightRAG
!pip install -e .
The following set of code is mostly adapted from LightRAG repo,
examples/lightrag_ollama_demo.py
Setup Ollama locally in your system and download the model from the Ollama model hub.
ollama pull llama3.1:latest
Before running the script it’s recommended to run ollama serve in a separate terminal so that we can monitor real-time logs and interactions with local LLM API endpoints during indexing and querying.
Import Dependencies
logging – to enable structured logging
pdfplumber – to easily extract text and data from PDFs
import os
import logging
from lightrag import LightRAG, QueryParam
from lightrag.llm import ollama_model_complete, ollama_embedding
from lightrag.utils import EmbeddingFunc
import pdfplumber
All the indexing files will be saved under the specified WORKING_DIR, including vector embeddings in the Vector DB storage and a JSON KV Storage for retrieval of key-value pairs.
WORKING_DIR = "./Legal_Documents"
logging.basicConfig(format="%(levelname)s:%(message)s", level=logging.INFO)
if not os.path.exists(WORKING_DIR):
os.mkdir(WORKING_DIR)
This is the main step where the LightRAG instance is configured with necessary parameters. We are using the llama3.1 8b Q4 model as the LLM, with a context length of 32K tokens. As discussed in the benchmark section, we are sticking to a chunk size of 1200 to divide the pdf_text as manageable chunks for processing through the LLM. LightRAG’s function definitions are designed to natively integrate asynchronous methods within its pipeline enabling efficient resource utilization with minimal idle time.
By default, Ollama models connect to a local server at localhost:11434 which we will use to access model endpoints to get responses. The llm_model_max_async=4 setting allows handling 4 concurrent async requests.
For embedding the raw text chunks, nomic-embed-text is used which is a robust embedding model at its param size with an embedding dimension of 768.
FIG 15 LightRAG Indexing Flowchart adapted from README
Using pdfplumber the PDF is read and its contents are saved as a single string in the pdf_text variable.
pdf_path = "../Companies_Act_2013.pdf" # Constitution_of_India.pdf
pdf_text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
pdf_text += page.extract_text() + "\n"
rag.insert(pdf_text)
1. The kv_store_text_chunks.json stores doc text chunks with associated metadata such as chunk_size (tokens), actual content, chunk index, parent doc id etc.
{
"chunk-263060580cb96b108229f04084bd7145": {
"tokens": 1200,
"content": "THE COMPANIES ACT, 2013\n__________________\nARRANGEMENT OF SECTIONS\n__________________\nCHAPTER I\nPRELIMINARY\nSECTIONS\n1. Short title, extent,
. . .
n103. Qu",
"chunk_order_index": 0,
"full_doc_id": "doc-5e59746a8a12e3cef24972ccaed37d8b"
},
2. The kv_store_llm_response.json holds the LLM generated summaries about the entity and relations. It uses a caching mechanism to prevent redundant indexing of identical ids.
{ "0fee776f1c75f801f4eef2b697796294": {
"return": "**##(\"entity\"<|>\"company\"<|>\"organization\"<|>\"The company is the subject of various laws and regulations related to its operations and management.\")##(\"relationship\"<|>\"Central Government\"<|>\"Tribunal\"<|>\"The Central Government plays a significant role in governing companies and appointing Tribunals to oversee their activities).",
"model": "llama3.1:latest"
},
3. Next, vdb_entities.jsoncontains vector embeddings of entities extracted from the text chunks with unique id, entity name etc.
4. Similarly, the vdb_relationship.json file stores relationships between entities linking source and target entities by their IDs to represent connections.
5. Finally the graph index constructed is saved as graph_chunk_entity_relation.graphml, which we will utilize later to visualize the KG in Neo4j.
Incremental Indexing
To index new files, simply change the pdf_path. This will automatically update the LLM responses in kv_store_llm_response.json to include any new entities and relationships without any conflicts or redundancies with existing data.
The following is an example of an updated response.
{"bffc33a2cdad86ce6b44ca8b0445a6d2": {
"return": "Here is the updated output with additional entities:\n\n(\"entity\"<|>\"company\ed accountant\"<|>\"person\"<|>\"A chartered accountant is a type of auditor who is certified to conduct audits.\")##
- - - #Response Truncated - - -
"model": "llama3.1:latest"
},
On an RTX 3080 GPU with 12GB VRAM and an intel i7 13th Gen CPU, it took about an hour to index the 288-page Companies Act PDF which had 190 total chunks and an additional 70 minutes for updating the Constitution of India PDF. Based on our testing, the llama3.1:8b model works well without many issues; however when the qwen2.5:7b or llama3.2:1b family of models is used, we encounter several issues in the indexing process like slowdowns or halts. While the reason remains unclear we appreciate sharing any insights you may have in the comments.
Querying
Depending on the query mode such as naive, local, global and hybrid, relevant keywords are extracted from the query and are compared with the KV store and Nano vector DB to retrieve the candidate entities and relationships based on cosine similarity.
The querying phase of LightRAG is outlined in the following flowchart.
FIG 16 LightRAG Retrieval and Querying Flowchart adapted from README
We will save the LLM output responses for different query approaches in an output_response.txt file for referencing outputs anytime.
os.makedirs(
os.path.join(WORKING_DIR, "../outputs/"),
exist_ok=True,
)
output_file = os.path.join(WORKING_DIR, "../outputs/output_response.txt")
# Function to write results to file
def write_to_file(output_text):
with open(output_file, "a", encoding="utf-8") as file:
file.write(output_text + "\n")
Naive RAG
This is a standard RAG setup retrieving top_k = 60 chunks.
# Perform searches and save results
write_to_file(
rag.query(
"What does companies act mean?",
param=QueryParam(mode="naive"),
)
)
Local Query – LightRAG
By default the pipeline retrieves top_k = 60 candidate entities for local query mode.
write_to_file(
rag.query(
"What does companies act mean?",
param=QueryParam(mode="local"),
)
)
Global Query – LightRAG
For the global query model, LightRAG pipeline retrieves top_k = 60 candidate relations.
write_to_file(
rag.query(
"What does companies act mean?",
param=QueryParam(mode="global"),
)
)
Hybrid Query – LightRAG
The hybrid mode combines the high level and low level context to generate better responses targeted at both local entities and global relations.
write_to_file(
rag.query(
"What does companies act mean?",
param=QueryParam(mode="hybrid"),
)
)
VIDEO 2: LightRAG Querying – Gradio Demo
To evaluate the win rate of responses to different queries targeting local entities and global relationships, we can follow a similar process discussed in both the GraphRAG and LightRAG papers, where GPT-4o was used as a judge. Additionally, we will manually review the responses to derive further insights.
Response Comparison 1: Targeted at Local Entity
To prevent OOM error the following query was inferred with {"num_ctx": 16000}
Query: “What are the requirements for an independent director in Section 149?”
Note: The original page from the text was added from the PDF for reference and is independent of LightRAG pipeline
FIG 17 Page 277 of Companies Act 2013 PDF
Naive RAG
------------------------------------------Naive-------------------------------------------------------
According to the knowledge I have, Section 149 does not explicitly state the requirements for an independent director. However, Section 150 provides some information on the manner of selection of independent directors and maintenance of a databank of independent directors.
To answer your question accurately, I would need more information or clarification from the provided text.
Local Query – LightRAG Response
------------------------------------------Local------------------------------------------------------
Section 149 of the Companies Act, 2013 sets out certain requirements for Independent Directors (IDs) of a company. Here are some key requirements:
1. **Independence**: An ID must be "independent" in terms of his or her background, expertise, and experience. This means that they should not have any material pecuniary relationship with the company, its promoters, or its management, nor should they be associated with any other listed company.
2. **Qualification**: The IDs should possess the qualifications prescribed by Schedule IV of the Act, which includes having a bachelor's degree and relevant professional experience.
3. **Appointment**: An ID can be appointed either through a Nomination Committee or Board-level process. The board must inform the ID about their role, responsibilities, and expected time commitment.
4. **Number of Boards**: IDs cannot serve on more than 20 boards of listed companies, including your company. However, this restriction does not apply to non-listed companies.
5. **Familiarization Program**: Before taking charge, an ID must undergo a familiarization program designed to ensure that they are fully aware of the company's business operations and internal policies.
6. **Confirmation by Board**: The board must confirm each year, before the annual general meeting, that all IDs meet the independence criteria specified in Section 149(7) of the Companies Act.
These requirements aim to maintain the independence and integrity of IDS in making decisions for public companies.
Global Query – LightRAG Response
-----------------------------------------Global----------------------------------------------------
According to the provided data, there is no mention of a Section 149 in the Entities table. However, based on the context and related information, I can attempt to provide a general answer.
Unfortunately, without specific reference to a Section 149 or related section in the provided tables, it's challenging for me to accurately determine the requirements for an independent director as per that section.
However, if you are referring to Section 149 of the Companies Act, 2013, which deals with Independent Directors, I can provide some general information. According to the Act, an Independent Director is a non-executive director who does not have any material pecuniary relationship or transaction with the company or its promoters, directors, and their relatives.
In that case, the requirements for an independent director as per Section 149 are:
* The Independent Director shall hold office for a term of five years but shall be eligible for reappointment.
* No person who is a promoter or director of the company or of any of its associated companies, or who is in the employment of such company or body corporate, shall be appointed as an independent director.
Please note that this information might not be specific to Section 149, and you may want to consult the actual Companies Act, 2013, for detailed information.
Hybrid (Local + Global) Query – LightRAG Response
------------------------------------------Hybrid------------------------------------------------
Section 149 of the Companies Act, 2013 requires that a company have at least one third (1/3) of its total directors as Independent Directors. This means that if a company has 7 directors, it must have at least 2 independent directors. The requirements for an independent director are specified in Section 149(6).
To be considered an independent director under Section 149, the following conditions must be met:
1. **Not related to Promoters or Management**: The Independent Director should not have any material pecuniary relationship with the company, its holding or subsidiary companies, or their promoters or directors.
2. **No Shareholding**: There should be no transaction between the independent director and the company, its holdings, subsidiaries, or associate companies that would give him a material benefit.
3. **Not having any direct or indirect financial interest in or being an official of any other business activity or profession which may interfere with his ability to function as an independent director."
4. **No Family Relationship**: They cannot be related to promoters or directors, either by blood, marriage, or a family relationship that might conflict with their independence.
5. **No Material Personal Interest**: The Independent Director must not have any material pecuniary interest in the company or its businesses, whether directly or indirectly.
6. **Not holding a Significant Position**: They should not hold more than two directorships of listed companies and not hold any office or position in the NSE, BSE, or their subsidiaries.
7. **Being Qualified**: The Independent Director must have suitable expertise or experience to be able to contribute positively to the Board's discussions.
These requirements are designed to ensure that independent directors bring an objective perspective to the company's governance and decision-making processes.
GPT-4o review about the response and ratings is as follows:
Overall Rating Summary by GPT-4o:
Naive: 4/10
Local: 9/10
Global: 6/10
Hybrid: 8.5/10
The Local Response is the most effective, with the Hybrid Response following closely. Both responses address the query well, with Local Response being particularly concise and informative.
Response Comparison 2: Targeted at Global Relations
{"num_ctx": 16000}
Query: “How are workers’ rights protected across both constitutional and corporate legal frameworks in India?”
Naive RAG Response
------------------------------------------Naive-------------------------------------------------------
In India, workers' rights are protected through a combination of constitutional and corporate legal frameworks. The Constitution of India provides several provisions that safeguard the rights of workers, while corporate laws and regulations also play a crucial role in protecting their interests.
The Indian Constitution, specifically Articles 14, 15, 16, and 21, guarantees fundamental rights to all citizens, including workers. Article 14 prohibits discrimination on grounds of religion, race, caste, sex, or place of birth, while Article 15(3) allows the state to make special provisions for women and children, which includes protection from exploitation in the workplace.
Article 16 provides equal opportunity for employment, while Article 21 protects the right to life and liberty. The Constitution also guarantees the right to form unions and collective bargaining (Articles 19 and 11), which is essential for workers' rights.
At the corporate level, the Indian government has enacted several laws that protect workers' rights. The Industrial Disputes Act, 1947, and the Trade Unions Act, 1926, regulate industrial disputes and trade union activities, respectively. The Mines Act, 1952, and the Factories Act, 1948, provide safety standards for workers in mines and factories.
The Employment Exchanges (Compulsory Notification of Vacancies) Central Rules, 1974, ensure that employers notify vacancies to employment exchanges, facilitating job placement for workers. The Equal Remuneration Act, 2017, prohibits wage disparity between men and women performing the same work.
The National Labour Policy aims to promote the creation of an environment of mutual trust and confidence between employees and employers, and the Code on Wages, 2019, provides a comprehensive framework for regulating wages across various sectors. The Ministry of Labor and Employment has also initiated programs like the Apprenticeship Training Scheme and the Pradhan Mantri Shram-Yogi Maan-Dhan (PMSYM) Yojana to protect workers' rights.
However, despite these provisions and regulations, workers in India continue to face several challenges, such as exploitation, unfair labor practices, and lack of social security. Therefore, there is still a need for strengthening the legal frameworks to better protect workers' rights.
In conclusion, the protection of workers' rights across both constitutional and corporate legal frameworks in India is multifaceted. The Constitution provides fundamental rights to all citizens, including workers, while corporate laws and regulations aim to safeguard their interests. However, more needs to be done to address existing challenges and strengthen the legal frameworks to ensure better protection for workers.
It is worth noting that the Indian government has taken steps to strengthen labor laws in recent years, such as the passage of the Code on Wages, 2019, and the amendment of the Industrial Disputes Act, 1947. However, more needs to be done to address existing challenges and ensure better protection for workers.
In terms of specific answers to questions related to workers' rights in India, here are some possible responses:
* Q: What is the minimum wage law in India?
A: The Code on Wages, 2019, provides a comprehensive framework for regulating wages across various sectors.
* Q: How do Indian laws protect workers from exploitation?
A: Laws such as the Industrial Disputes Act, 1947, and the Trade Unions Act, 1926, regulate industrial disputes and trade union activities.
* Q: What is the National Labour Policy in India?
A: The policy aims to promote an environment of mutual trust and confidence between employees and employers.
Please note that these answers are based on a limited analysis of the provided knowledge, and there may be more information available on this topic.
Local Query – LightRAG Response
------------------------------------------Local------------------------------------------------------
# Protection of Workers' Rights in India
India's constitutional framework provides a robust foundation for protecting workers' rights, while its corporate laws offer additional layers of protection. This section delves into the nuances of these frameworks and their intersections.
### Constitutional Framework
**The Constitution of India**
Article 16(4) of the Indian Constitution states that no government employee can be dismissed from service without being given a hearing by an inquiry as per regulations made in this behalf. This ensures that government employees are safeguarded against arbitrary dismissals.
Article 19(1)(g) grants citizens the right to form associations and unions, promoting collective bargaining and workers' rights advocacy.
Article 21 protects life and personal liberty, encompassing workers' rights to a safe working environment and dignity in employment.
**Constitutional Amendments**
The Constitution (Sixty-fourth Amendment) Act, 1990, inserted Article 16(4A), which prohibits direct recruitment of persons on contract for any permanent post, ensuring that government jobs are not outsourced without proper authorization.
The Constitution (Seventh Amendment) Act, 1956, introduced changes related to court jurisdiction in disputes over water resources. Although seemingly unrelated, this amendment has implications for workers' rights in industries like irrigation and hydroelectric power generation.
**Intersections with Corporate Laws**
### Company Law
The **Companies Act**, particularly Chapter VI, deals with the appointment and powers of directors, officers, and employees of a company. This includes provisions for:
* **Protection against Unfair Labor Practices**: Companies are prohibited from engaging in unfair labor practices, such as interfering with union organizing or retaliating against employees who exercise their rights.
* **Right to Collective Bargaining**: Employees have the right to engage in collective bargaining and form unions.
**Securities and Exchange Board of India Act, 1992**
The SEBI Act regulates securities markets and has provisions related to corporate governance, which indirectly affects workers' rights. For instance:
* **Disclosure Requirements**: Companies must disclose certain information about their employees, such as the number of women in senior positions or the proportion of employees covered by a collective bargaining agreement.
* **Corporate Governance Standards**: The Act sets standards for corporate governance, including provisions related to employee representation on the board and executive compensation.
**Industrial Disputes Act, 1947**
The IDA provides a framework for resolving industrial disputes through conciliation, mediation, and arbitration. This includes:
* **Strike and Lockout Provisions**: The Act regulates strikes and lockouts, ensuring that workers' rights to collective action are balanced against the need for companies to maintain production.
* **Wage Boards and Industrial Tribunals**: Wage boards and industrial tribunals are established to determine minimum wages and resolve disputes over wages and working conditions.
### Conclusion
India's constitutional framework and corporate laws provide a comprehensive protection of workers' rights. While there may be areas for improvement, the country has made significant strides in safeguarding the interests of employees.
In conclusion, workers’ rights are protected across both constitutional and corporate legal frameworks in India through provisions such as Article 16(4) of the Constitution, which safeguards government employees against arbitrary dismissals; Article 19(1)(g), which grants citizens the right to form associations and unions; Article 21, which protects life and personal liberty; and Chapter VI of the Companies Act, which deals with the appointment and powers of directors, officers, and employees of a company.
Additional laws like the Industrial Disputes Act, 1947, provide a framework for resolving industrial disputes through conciliation, mediation, and arbitration. The Securities and Exchange Board of India Act, 1992, regulates securities markets and has provisions related to corporate governance that indirectly affects workers' rights.
The intersections between these frameworks ensure that workers’ rights are safeguarded across various domains in Indian law.
Global Query – LightRAG Response
------------------------------------------Global----------------------------------------------------
Workers' rights are an essential aspect of any economy, ensuring that individuals have fair treatment and protection from exploitation. In India, workers' rights are safeguarded through both constitutional and corporate legal frameworks.
**Constitutional Framework**
The Indian Constitution provides a comprehensive framework for protecting workers' rights under Article 14 (Right to Equality), Article 21 (Protection of Life and Personal Liberty), and Article 39 (Directive Principles of State Policy). These provisions ensure that all workers, regardless of their occupation or industry, have the following rights:
* **Equal pay for equal work**: The Constitution ensures that all workers are paid equally for the same work, eliminating wage disparities.
* **Right to safe working conditions**: Workers have a right to a safe and healthy work environment, free from hazards and risks.
* **Freedom of association**: Workers can form unions or associations to negotiate with employers and protect their interests.
* **Protection against exploitation**: The Constitution prohibits forced labor, child labor, and other forms of exploitation.
**Corporate Legal Framework**
The Companies Act, 2013, and the Industrial Disputes Act, 1947, are key corporate laws that safeguard workers' rights in India. These laws ensure:
* **Regulation of working hours**: Employers must adhere to specific working hour regulations, protecting workers from excessive workloads.
* **Payment of wages**: Employers are required to pay workers their due wages on time, eliminating delays and arrears.
* **Provident fund contributions**: Employers must contribute to the Employees' Provident Fund (EPF) for their employees, ensuring a retirement benefit for them.
* **Regulation of layoffs**: The Industrial Disputes Act provides a framework for regulating layoffs, ensuring that employers follow due process before terminating workers.
**Relationship between Constitutional and Corporate Legal Frameworks**
The constitutional framework sets the broader principles and standards for protecting workers' rights, while the corporate legal framework operationalizes these principles through specific regulations. In other words:
* **Constitutional provisions guide corporate laws**: The Constitution's provisions on workers' rights are reflected in the Companies Act and the Industrial Disputes Act.
* **Corporate laws enforce constitutional provisions**: Corporate laws ensure that employers comply with the constitutional standards for protecting workers' rights.
**Additional Protection through Tribunals**
In addition to these frameworks, the Industrial Tribunal has jurisdiction over industrial disputes, including those related to workers' rights. The tribunal's decisions can influence corporate practices and set precedents for future cases.
**Conclusion**
Workers' rights in India are protected through a combination of constitutional and corporate legal frameworks. These laws ensure that employers respect the rights of their employees, providing a fair and safe work environment. By understanding these frameworks, stakeholders can promote worker welfare and contribute to a more equitable society.
Hybrid (Local + Global) Query – LightRAG Response
------------------------------------------Hybrid------------------------------------------------
In India, workers' rights are protected through a combination of constitutional and corporate legal frameworks. Here's an overview:
**Constitutional Framework:**
The Indian Constitution provides a robust framework for protecting workers' rights. The following provisions are particularly relevant:
1. **Article 14**: This article ensures equality before the law, which includes equal protection to all workers regardless of their occupation.
2. **Article 21**: This article guarantees life and personal liberty, including the right to livelihood. It has been interpreted by courts to include the right to work and social security.
3. **Article 39(e)**: This article directs the state to promote the welfare of workers by securing for them a living wage, safe conditions of work, and reasonable leisure time.
**Corporate Legal Framework:**
India's corporate legal framework is governed by various laws, regulations, and court decisions that protect workers' rights:
1. **Industrial Disputes Act, 1947**: This act provides mechanisms for resolving industrial disputes between employers and employees.
2. **The Trade Unions Act, 1926**: This act regulates trade unions, including their registration, funds, and activities.
3. **Factories Act, 1948**: This act sets standards for working conditions, safety, and health in factories.
4. **The Employees Provident Funds and Miscellaneous Provisions Act, 1952**: This act mandates employers to contribute to a provident fund for employees' benefit.
5. **The Mines Act, 1952**: This act regulates working conditions, safety, and health in mines.
6. **The Shops and Establishments Act, 1953 (varies by state)**: These acts regulate working conditions, wages, and hours of work for retail, shopping, and other establishments.
**Key Protections:**
Some key protections provided to workers under these frameworks include:
1. **Right to collective bargaining**: Workers have the right to engage in collective bargaining with their employers.
2. **Right to safe working conditions**: Employers are responsible for ensuring a safe work environment.
3. **Minimum wages and hours of work**: Laws regulate minimum wages, overtime pay, and working hours for various industries.
4. **Social security benefits**: Employees are entitled to social security benefits like provident fund, pension, and gratuity.
5. **Regulation of employment contracts**: Employment contracts must comply with laws and regulations regarding termination, notice periods, and other terms.
**Challenges:**
While India's constitutional and corporate legal frameworks provide significant protections for workers' rights, there are still challenges to be addressed:
1. **Enforcement**: Compliance and enforcement of these laws often vary between states and industries.
2. **Labor inspections**: Inadequate labor inspections and monitoring by government agencies contribute to non-compliance.
3. **Trade unionism**: Trade unions face obstacles in registration, functioning, and collective bargaining due to various state laws and regulations.
**Reform Efforts:**
In recent years, there have been efforts to strengthen workers' rights in India:
1. **National Policy on Labour, 2017-2025**: This policy aims to promote social security, health, and safety for all workers.
2. **Amendments to the Factories Act, 1948**: Recent amendments aim to improve working conditions and safety standards in factories.
3. **Increased emphasis on labor inspections**: The government has increased efforts to monitor compliance with labor laws.
In summary, India's constitutional and corporate legal frameworks provide a robust foundation for protecting workers' rights. However, enforcement, monitoring, and reform efforts are necessary to ensure that these protections are effectively realized across the country.
Overall Ratings Summary by GPT-4o:
Naive: 7/10
Local: 8.5/10
Global: 8/10
Hybrid: 9/10
The Hybrid Response is the most effective, combining detailed information on protections, challenges, and reform efforts, followed closely by the Local Response for its in-depth and structured approach. Both responses effectively address the query from a global perspective.
Even upon manual review we see that hybrid responses in both sections were better in most cases. Hybrid retrieval is one of the key strengths of the LightRAG framework.
Knowledge Graph Visualization with Neo4j
Uploading the .graphml to Neo4j cloud is straightforward, you can find the code for this in the repository. Simply personalize the credentials with your specific details by signing up for a free Neo4J AuraDB account. After upserting into the Neo4j instance, for those two PDF contents we had Nodes: 3,352 and Relationships: 4,752.
from neo4j import GraphDatabase
# Constants
WORKING_DIR = "./Legal_Documents"
BATCH_SIZE_NODES = 500
BATCH_SIZE_EDGES = 100
# Neo4j connection credentials
#Get your instance URI from AuraDB
NEO4J_URI = "neo4j+s://cc9c7209.databases.neo4j.io"
NEO4J_USERNAME = "neo4j" #default
NEO4J_PASSWORD = "Your_Instance_Password"
Sample Cypher Query in Neo4J Console:
MATCH p=()-[]->() RETURN p LIMIT 25;
where, () represents nodes (or entities), while [] represents relationships between them.
VIDEO 3: Neo4j Node Visualization
Reproduce Benchmarks
To reproduce the benchmarks results, the team has also released evaluation scripts. If you are interested, simply download the UltraDomain dataset and follow the instructions outlined in the README file.
Takeaways
As expected, LightRAG’s Graph Indexing and dual-level retrieval yielded promising results as rightly outlined in the paper. In our comparison, when querying a specific entity, the local query response was the most desirable, followed by the hybrid approach. In a second comparison focused on global relationships, the global and hybrid modes produced the most preferred summaries.
At times, queries targeted at global and local contexts didn’t work as expected, and the naive approach performed better, while other responses simply stated, “Sorry, I can’t answer this question as I don’t have enough information.” . However, subject to further experiments optimal querying strategy is to be found.
While LightRAG is a promising project, its high level of abstraction can make it challenging to follow through logs alone. The community has suggested adding more intermediate logging, and the authors have acknowledged this feedback. If you are getting started with LightRAG, it is highly recommended to review the internal codebase, the workflow image in the README, and both the GraphRAG and LightRAG papers for a better understanding.
Based on our experiments, we find LightRAG to be a promising and effective RAG framework. The legal domain, by nature, poses challenging queries that demand accurate insights without hallucinations, and we observed that LightRAG demonstrates strong potential in meeting these demands.
Although still in its early stages, there is still room for further enhancements. The authors are actively maintaining the repository, continuously implementing updates and addressing issues. Kudos to the team at HKU for releasing this as an open-source project under the MIT license.
If you liked this article and would like to download code (C++ and Python) and example images used in this post, please click here. Alternately, sign up to receive a free Computer Vision Resource Guide. In our newsletter, we share OpenCV tutorials and examples written in C++/Python, and Computer Vision and Machine Learning algorithms and news.
Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.












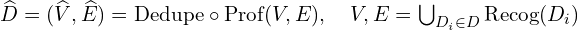
 represents the resulting knowledge graph.
represents the resulting knowledge graph.















100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning