

Ever watched an AI-generated video and wondered how it was made? Or perhaps dreamed of creating your own dynamic scenes, only to be overwhelmed by the complexity or the need for supercomputer-like resources? For a long time, generating truly long, coherent, and high-quality videos with AI felt like a task reserved for massive research labs. Common hurdles like “forgetting” details over time or “drifting” into visual noise halted many attempts.

Meet FramePack. A new neural network architecture which offers a powerful and efficient solution to these long-standing problems. Why should you, as someone interested in the video generation domain, care about FramePack? Because it represents a leap towards:
- Longer, more coherent videos: Overcoming the limitations of short-clip generation.
- Mitigating the drifting effect.
- Enabling impressive results even on consumer-grade hardware, like GPUs with just 6GB of VRAM.
In this blog post we will explore various innovations introduced in the FramePack research paper along with generating some eye-catching video clips locally.
Let’s get started.
- Forgetting and Drifting problems in Video Generation models
- What is FramePack and why do we need it?
- Can a Video Diffusion model generate 30fps 60-second video within 6GB VRAM?
- Base Model and Implementation Details
- Generated examples and code walkthrough
- Limitations of FramePack
- Conclusion
- References
Forgetting and Drifting problems in Video Generation models
Making long, good-looking videos with video diffusion, especially using next-frame prediction models, is tricky due to two core challenges: forgetting and drifting.
Forgetting occurs when the model fails to maintain long-range temporal consistency, losing details from earlier in the video.
Drifting, also known as exposure bias, is the gradual degradation of visual quality as initial errors in one frame propagate and accumulate across subsequent frames.
The tricky part—a fundamental dilemma—is that solutions for one often rile the other.
Boosting memory mechanisms to combat forgetting can inadvertently accelerate error propagation, making drifting worse. Conversely, trying to interrupt error propagation (perhaps by re-noising history) can weaken temporal dependencies and thus exacerbate forgetting.
Simply feeding more frames into powerful transformer models to improve memory isn’t a great fix either; their quadratic attention complexity makes this computationally explosive and inefficient, especially given the significant temporal redundancy in video frames. This paradoxical relationship highlights the need for more innovative memory management and error correction approaches in video generation.
What is FramePack and why do we need it?
FramePack is a Neural Network structure that introduces a novel anti-forgetting memory structure alongside sophisticated anti-drifting sampling methods to address the persistent challenges of forgetting and drifting in video synthesis. This combination provides a more robust and computationally tractable path towards high-quality, long-form video generation.
The central idea of FramePack’s approach to the forgetting problem is progressive compression of input frames based on their relative importance. The architecture ensures that the total transformer context length converges to a fixed upper bound, irrespective of the video’s duration. This pivotal feature allows the model to encode substantially more historical context without an escalating computational bottleneck, facilitating anti-forgetting directly.
FramePack incorporates innovative anti-drifting sampling methods that deviate from causal prediction chains by leveraging bi-directional context.

Strategies visualized in the above image such as establishing endpoint frames before filling intermediate frames(Anti-drifting approach, part b in Fig 1), or employing an inverted temporal sampling approach where frames are generated in reverse order(Inverted anti-drifting, part c in Fig 1) towards a known high-quality target (e.g., an input frame in image-to-video tasks), demonstrably reduce error occurrence and mitigate their propagation. The practical implications of FramePack are particularly compelling, especially concerning training efficiency.
For instance, even with the substantial 13B parameter HunyuanVideo model, FramePack achieves a batch size 64 for 480p resolution training on a single 8×A100-80G node. This is accomplished without resorting to standard image-based training techniques like community LoRAs, placing its training batch efficiency on par with large image diffusion models like the 12B Flux. Such efficiency makes FramePack viable for personal training and experimentation.
This efficiency also supports the generation of high-fidelity outputs, such as 30fps videos potentially extending to 60 seconds, even on consumer-grade GPUs with constrained VRAM (e.g., 6GB).
Furthermore, FramePack’s next-frame prediction paradigm inherently generates smaller 3D tensors per inference step compared to full-video diffusion approaches. This characteristic permits training with much lower flow shift values. The authors leverage Flux’s dynamic flow shift methodology, finding that these less aggressive schedulers contribute to sharper, cleaner visual results that emulate real video dynamics more closely.
Importantly, FramePack is designed for integration, allowing existing pretrained video diffusion models such as HunyuanVideo and Wan to be fine-tuned with its structure, unlocking further performance gains and adaptability.
Our LearnOpenCV website features another blog post that delves into the architectures and impressive results generated by prominent video diffusion models, such as SORA and VEO2. If you are interested in understanding the working principles of HunyuanVideo, or exploring the evolution of video diffusion models—from their initial introduction to the emergence of sophisticated systems like VEO2—we invite you to visit our detailed article by clicking the following link: Video Diffusion
Can a Video Diffusion model generate 30fps 60-second video within 6GB VRAM?
Generating videos using video diffusion can now be achieved within 6GB VRAM due to the innovative compression and sampling methodologies introduced by FramePack.
FramePack system is built around Diffusion Transformers (DiTs) that generate a section of S unknown video frames, conditioned on T preceding input frames.
Achieving Fixed-Length Context:
The Achilles’ heel of many video models is the “context length explosion.” FramePack elegantly avoids this by ensuring the total context length converges to a fixed upper bound, regardless of the video’s duration.

Input & Initial Encoding:
As shown in the diagram( the Input History Processing block ), the process begins with Input Video Frames (History), 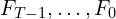 .
.
These raw frames are first passed through a VAE Encoder Block to obtain their Latent History Frames (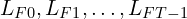 ). This is a standard practice for working in a more compressed and manageable latent space.
). This is a standard practice for working in a more compressed and manageable latent space.
The Core Idea:
This module operates on the principle that not all past frames are equally important.The most recent latent frame (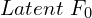 ) has been passed to Patch Projection Layer
) has been passed to Patch Projection Layer 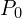 . This layer converts the latent frame into tokens. For this most essential frame, the compression factor
. This layer converts the latent frame into tokens. For this most essential frame, the compression factor 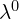 means it retains its complete designated token count,
means it retains its complete designated token count, 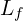 (e.g., ~1560 tokens for a 480p frame in HunyuanVideo/Wan/Flux).
(e.g., ~1560 tokens for a 480p frame in HunyuanVideo/Wan/Flux).
For older frames like Latent F_1, a different Patch Projection Layer 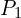 is used. This layer is configured (e.g., with larger kernel/stride settings) to apply a compression of
is used. This layer is configured (e.g., with larger kernel/stride settings) to apply a compression of 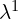 . Thus, it outputs fewer tokens, specifically
. Thus, it outputs fewer tokens, specifically 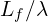 .
.
This pattern continues for Latent 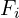 with
with Patch_Proj_i applying compression 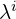 , resulting in
, resulting in 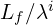 tokens. The paper primarily discusses
tokens. The paper primarily discusses 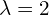 , meaning each progressively older frame effectively contributes half the number of tokens as the one after it.
, meaning each progressively older frame effectively contributes half the number of tokens as the one after it.
Optimizing GPU memory layout:
The FramePack paper illustrates several clever variants of frame compression, as can be seen from the image provided below and taken from FramePack research paper.

- Top Timeline: This shows the general setup: a “Next-frame-section Prediction Model” takes a series of input frames (from
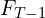 oldest, to
oldest, to 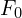 most recent) to predict unknown frames (
most recent) to predict unknown frames (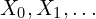 ).
). - GPU Memory Layout (Context Length Proportion): The core of the visualization. Each large rectangle represents the total context budget in the GPU’s memory allocated to the input frames. The smaller boxes inside show how different past frames (,
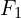 ,
, 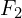 , etc.) occupy proportionally different amounts of this context space.
, etc.) occupy proportionally different amounts of this context space.
- (the most recent input frame) consistently gets the largest share, indicating it’s least compressed.
- As frames get older (e.g., , ,
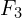 ,
,  ), their corresponding boxes are smaller, signifying they are more aggressively compressed and contribute fewer tokens to the model.
), their corresponding boxes are smaller, signifying they are more aggressively compressed and contribute fewer tokens to the model.
- Compression Rate (Relative): This shows the token reduction factor. A rate of
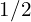 means half the tokens of the base,
means half the tokens of the base, 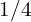 means a quarter, and so on.
means a quarter, and so on. - Pachify Kernel: These are examples of 3D kernel sizes (temporal, height, width) used by the transformer’s input layer to achieve the specified compression for each frame. Larger kernel dimensions for a given frame lead to more compression (fewer tokens).
Bounded Context Length:
The beauty of this geometric compression is that the total token contribution from all historical frames converges. The final concatenated token sequence is fed to the DiT, which has a total context length of L given by:
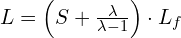
( is the number of tokens from the Target Frame Processing Block, which handles the generated S frames). For , this simplifies to
is the number of tokens from the Target Frame Processing Block, which handles the generated S frames). For , this simplifies to 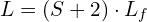 . This fixed upper bound, clearly indicated in the diagram’s Diffusion Model Core Block, makes FramePack computationally stable for long videos.
. This fixed upper bound, clearly indicated in the diagram’s Diffusion Model Core Block, makes FramePack computationally stable for long videos.

Anti-Drifting Sampling: Beyond Causal Prediction:
While the provided diagram focuses on the data flow for a single generation step, FramePack employs anti-drifting sampling methods over multiple such steps. These methods break the causal chain by incorporating bi-directional context. The below given sampling strategies ensure that the Diffusion Model Core Block often receives context from both “past” and “future” (relative to the segment being generated in that particular iteration).
Endpoint Anchoring & Infilling:
In the first generation step, the model would generate the Latent History Frames for the start and end of a clip. The Target Frame Processing would then focus on these two distinct sections (initial and final frames). Subsequent iterations would use these as context to fill in the gaps.
Inverted Temporal Sampling:
Similarly, the Target Frame Processing would aim to generate the frame before a known high-quality end frame for this method.
Handling the “Tail”: Options for Very Old Frames:
For ancient frames that, after extreme compression, would yield minimal tokens (e.g., …Tokens ()… where is very large), FramePack offers practical solutions like deletion, minimal token contribution, or global average pooling. These are not explicitly detailed in the diagram’s token flow but are a consideration for the FramePack Compression Module when i becomes very large.
RoPE Alignment:
After each Patch Projection Layer produces tokens (e.g., Tokens for , Tokens for ), the diagram shows an Apply RoPE step. For the compressed frames (, , etc.), this RoPE application is “Aligned.” This refers to the paper’s method of downsampling the RoPE phases to match the reduced number of tokens. This ensures that all tokens receive consistent positional information before concatenation, regardless of their frame’s compression level. The Target Frame Processing block also applies RoPE to its tokens.
Final Steps in the Diagram:
- Feature Concatenation Operation: All positionally encoded tokens (from history and target) are combined.
- Diffusion Model Core Block: The DiT Block processes this fixed-length sequence to produce Predicted Denoised Latents for Target Frames X.
- Output Generation Block: Finally, a VAE Decoder Block converts these denoised latents into the Generated
SVideo Frames.
By visualizing the FramePack architecture this way, we can see how each component, from initial VAE encoding through specialized patch projections and RoPE alignment, contributes to the system’s ability to manage long-term context efficiently and enable advanced sampling for high-quality video generation.


Base Model and Implementation Details
While the architectural innovations of FramePack are central to its success, understanding the base models it integrates with and a comparison with other video generation models provides valuable context for its capabilities and how it was developed.
FramePack is designed to enhance and extend the capabilities of existing state-of-the-art video generation models. The researchers implemented FramePack primarily with two notable base models: the official Wan2.1 model and an improved iteration of official HunyuanVideo models. This enhanced HunyuanVideo was specifically modified to align with Wan2.1’s capabilities, incorporating the SigLip-Vision model for vision encoding, removing reliance on proprietary MLLMs( as the one used in HunyuanVideo model ), streamlining text processing by freezing Llama3.1 as a pure text model, and undergoing continued training on high-quality datasets.
The paper clarifies that direct performance comparisons between their FramePack-enhanced Wan and HunyuanVideo results aren’t the primary focus due to similar computational budgets during training (though Wan’s larger inherent size meant it received comparatively fewer resources like smaller batch sizes). Both models, when augmented with FramePack, demonstrated comparable quality post-training. However, HunyuanVideo is recommended by the authors as the default configuration for achieving more efficient training and faster inference speeds. Crucially, FramePack seamlessly supports both text-to-video and image-to-video generation modalities, as its next-frame-section prediction nature inherently accommodates these tasks without requiring fundamental architectural changes to the base models.
The quality and diversity of training data are paramount for any high-performing generative model. For FramePack, the researchers adhered to the dataset collection pipeline guidelines established by LTXVideo. This involved gathering video data across multiple resolutions and quality tiers, followed by rigorous filtering using quality measurements and motion scores to ensure a high-quality and diverse distribution for training.
To efficiently handle various video shapes during multi-resolution training, aspect ratio bucketing was employed, grouping videos of similar aspect ratios with a minimum unit size of 32 pixels. The paper provides examples of buckets for 480p resolution, such as (416, 960), (512, 768), and (960, 416), illustrating the breadth of aspect ratios managed.
To rigorously evaluate FramePack’s effectiveness, the researchers compared its proposed configuration against several relevant alternative architectures and strategies commonly used to enable longer video generation or reduce computational bottlenecks. These alternatives were implemented on top of the HunyuanVideo default architecture (using 33 latent frames) with a simple sliding window approach (half context length for history). The comparison methods included:
Repeating image-to-video: A baseline approach involving direct repetition of image-to-video inference for longer sequences.
Anchor frames (resembling StreamingT2V): Utilizing an image as an anchor to mitigate drifting.
Causal attention (resembling CausVid): Fine-tuning full attention to causal attention for potential KV cache benefits and faster inference.
Noisy history (resembling DiffusionForcing): Introducing noise to history latents to interrupt error accumulation, at the risk of increased forgetting.
History guidance (resembling HistoryGuidance): A more nuanced approach involving noisy history on the unconditional side of CFG guidance, aiming to balance the forgetting-drifting trade-off.

The results, summarized in Table provided above, are compelling.
Across a suite of Global Metrics (where higher is better, such as Clarity, Aesthetic, Motion, Dynamic, Semantic, Anatomy, and Identity), FramePack demonstrated strong all-around performance.
However, FramePack truly shines when examining the Drifting Metrics (where lower is better, indicating less drift). The proposed method achieved the best (lowest) scores across all measured drifting aspects.
This decisively shows its superior capability in maintaining consistency and quality over time compared to the alternatives.
Furthermore, these quantitative findings are strongly corroborated by Human Evaluation. FramePack achieved the highest ELO score (1221) and the best Rank (1), indicating a clear human preference for the videos it generated.
These implementation and comparative details provide a transparent look into how FramePack was developed, validated, and how it positions itself as a leading solution by effectively addressing the core challenges in video generation.
Generated examples and code walkthrough
In this section we will look at some of the samples generated using FramePack Gradio GUI.
First let’s look at the code implementation provided by the author:
git clone https://github.com/lllyasviel/FramePack.git
#create a virtual environment, to get rid of dependency issues, using python 3.10 is recommended by the author
conda create -n "environment_name" python=3.10
conda activate "environment_name"
#install package requirements
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt
#finally run the below command to enter into the gradio UI to generate videos from images
python demo_gradio.py

The above interface is the gradio demo provided by the author of FramePack, as a place to experiment our ideas with. All the parameters shown above are given a default value and can be changed based on the individual’s requirements. The parameter setting that we used is provided below:
- Video Length: 3sec
- Timesteps: 30
- Sage/Flash Attention: Not enabled
- Teacache: Not enabled (generates videos in less time, but quality degrades. Tradeoff between time and quality)
- Prompt: A man dancing
- Rest of the parameters are kept same as the one provided default by the author
The above video was generated using the below image:


Important Values to look into:
GPU consumption: Nearly 10GB (remember this value is without using sage/flash attention as well as Teacache)
Generation Time: 15-20 minutes
Video FPS: 30
Limitations of FramePack
Videos generated using FramePack exhibit certain discrepancies, particularly in scenarios with unstable camera movement or the absence of a still camera. Furthermore, FramePack has a tendency to render detailed human subjects with an undesirable smooth, plasticky, or even somewhat cartoonish texture.
A significant limitation is FramePack’s inefficiency in generating convincing human movements. For instance, in applications requiring talking avatars, Wan 2.1 delivers markedly superior quality, despite its slower processing speed. While post-production tasks such as upscaling low-quality video or interpolating frame rates (e.g., from 16fps to 30fps) can be addressed manually by a video editor, rectifying flawed motion after the rendering process is considerably more challenging and, in many scenarios, unfeasible.
Conclusion
- Addresses the Forgetting-Drifting Dilemma: Directly tackles the core trade-off between Forgetting and Drifting.
- Fixed Upper Bound on Context Length: This is achieved via progressive compression and manipulating patchy kernel sizes. It is a foundational improvement for handling long videos, enabling longer video generation with unchanged computational bottlenecks.
- Supports Anti-Drifting Sampling Methods (Bi-directional Context): This is a key mechanism for enhancing quality and consistency.
- Improved Model Responsiveness and Visual Quality in Inference.
- Allows for Higher Batch Sizes in Training.
References
- Github Repo
- FramePack Project Page






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning