

In the groundbreaking paper “Attention is all you need”, Transformers architecture was introduced for sequence to sequence tasks in NLP. Models like Bert, GPT were built on the top of Transformers architecture which became the SOTA in various NLP tasks. Vision transformers introduced in 2020 in the paper titled “An Image is Worth 16×16 Words” used transformers architecture in the Image Recognition task, and this showed the effectiveness of using Transformers architecture for computer vision tasks. Soon after, DETR (Detection Transformer) was introduced in the paper “End-to-End Object Detection with Transformers” by Facebook AI which uses Transformers architecture for Object detection tasks.

- How is DETR different from the previous models in object detection
- Architecture of DETR
- Using Pre-trained Model to Inference on Images
- Predicting on Video dataset
- Conclusion
How is DETR different from the previous models in object detection
- Architecture of models like YOLO (You Only Look Once), Faster R-CNN, SSD typically uses multi Convolutional layers, followed by specialized layers for object detection. DETR also uses CNN in backbone for feature extraction, but these features are then passed to Transformer encoder and decoder layers.
- Previous models required some sort of hand designed priors, like anchor boxes in YOLO, region proposals in R-CNN. DETR eliminates the need for any such hand designed priors.
- The DETR model doesn’t require NMS (Non-maximum suppression) as a post processing technique to remove irrelevant bounding boxes, which was required in CNN based models.

Source httpsarxivorgabs200512872


Architecture of DETR
The DETR architecture has 4 main components –
- Backbone
- Transformer Encoder
- Transformer Decoder
- Prediction heads (Feed Forward Networks)
In the following sub-section, we will go through each component in detail.
Backbone
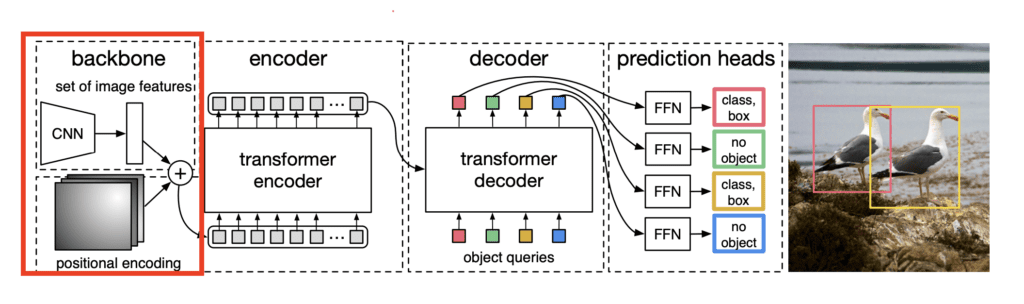
The DETR model begins with a Convolutional Neural Network (CNN) backbone, typically a ResNet architecture. This backbone serves as a feature extractor, processing the raw input image to produce a rich set of visual features. DETR typically uses ResNet-50 or ResNet-101 as its backbone.
Positional encoding:
Before going to Transformer Encoder, we need to explain positional encoding. Along with the output of the backbone network, which are the extracted features from the raw images, we also pass positional encodings to the Transformer Encoder. These encodings inject information about the spatial locations of pixels to help the model retain awareness of position in a 2D image.
Transformer Encoder
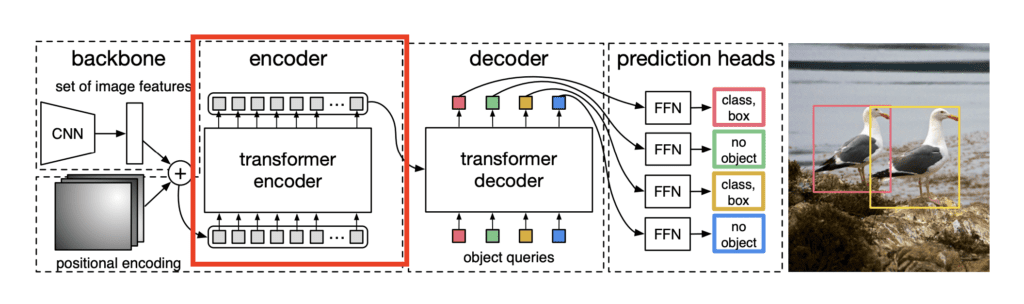
The output of the backbone network, along with the positional encodings are then passed through a series of Transformer Encoders. Each layer of Transformer Encoder contains –
- Multi-Head Self-Attention: Helps in attending to various parts of the image simultaneously, capturing long-range dependencies.
- Feedforward Network: Helps in transforming the attended features.
This helps in learning contextual relationships between objects in different regions of the image.
Transformer Decoder
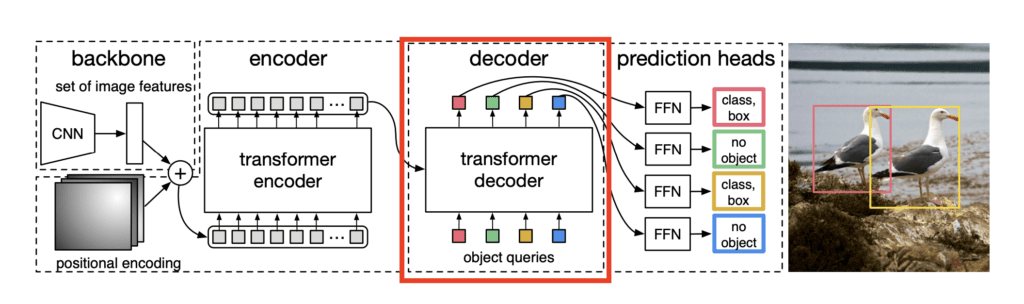
The transformer decoder is a key innovation in DETR, which was not present in Vision Transformers. The transformer decoder takes two inputs, the encoded features from the encoder and a set of learned object queries.
Just like the encoder layer, the decoder layer also has Multi-head self attention and FFN (Feed forward Network). It also has Multi-Head Cross-Attention, also known as Encoder-Decoder Attention. The Multi-Head Cross-Attention allows the object queries to “interact” with the encoded features from the encoder.
The output of a transformer decoder is a set of learned object queries which represents a potential object in the image in the form of an embedding.
Prediction Heads
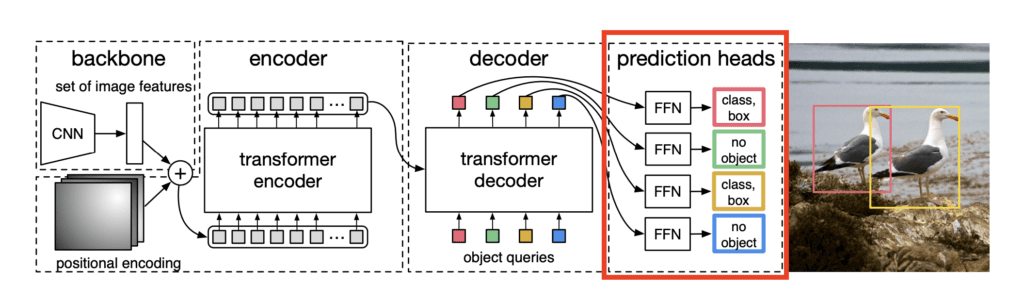
Prediction Heads are the last component of the DETR architecture. The output of the decoder layer is given as input to the prediction heads. The prediction head takes as input the learned object queries and for each object query, it predicts whether there is an object or not, along with the bounding box of the predicted object.
It is in this component of the architecture that we calculate the loss, which is used to train the whole network. The overall loss is the combination of classification loss and bounding box loss.
Benchmark Results
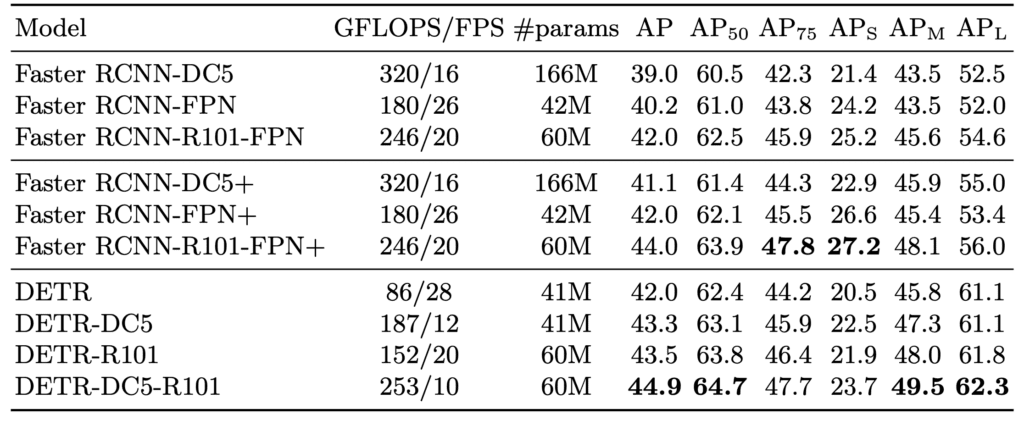
The above table compares the performance of DETR, Faster RCNN and their variants on the COCO 2017 dataset. R101 stands for using ResNet-101 as backbone. DC5 refers to the usage of Dilated Convolution. The DETR-DC5-R101 model uses ResNet-101 backbone along with dilated convolution with a stride of 5.
Using Pre-trained DETR Model for Inference on Images

As we have covered the architectural and theoretical details of DETR, let’s get our hands dirty and do some implementation. We will be using the Hugging Face Transformers library to load the DETR model object detection.
We will be doing the inference on some random images selected from the COCO dataset. The sample images used in the demo can be downloaded using the command. –
!wget "https://www.dropbox.com/scl/fi/ekllt8pwum1cu41ohsddh/inference_data.zip?rlkey=b1iih9q1mct5vcnwiyw98ouup&st=uncr8qho&dl=1" -O inference_data.zip
This will download the zip file and save it by the name inference_data.zip. To unzip the downloaded file, run the following command –
!unzip inference_data.zip
This will give us the 5 images that we will use to test out the DETR model. Here are the 5 images –





Let’s start with importing the DETR classes from transformers library –
from transformers import DetrForObjectDetection, DetrImageProcessor
We would also need some other imports for our program –
import torch
import cv2
import matplotlib.pyplot as plt
import numpy as np
from glob import glob
import os
In next cell, we will initialize the model and image processor. The processor resizes the input images to (800, 1333). –
model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
processor = DetrImageProcessor.from_pretrained("facebook/detr-resnet-50")
To load and preprocess an image, we will use the following block of code –
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
inputs = processor(images=image_rgb, return_tensors="pt")
Here, image_path is the path of the image we want to run the inference on. We use the function cv2.cvtColor to convert BGR image, which is loaded as default by cv2, to RGB image. The function processor is used to preprocess the input image.
In the subsequent code, we will pass this inputs to the model. The line torch.no_grad() ensures that we are not performing back propagation for this step, since it’s just for evaluation.
with torch.no_grad():
outputs = model(**inputs)
The outputs contain the prediction by the model. For each prediction, it gives the score of the prediction, along with its bounding box. The bounding box is present in the format `center_x, center_y, width, height` and we need to convert it to the standard coco format. For that, we use the following block of code –
target_sizes = torch.tensor([image_rgb.shape[:2]]) # Image size (height, width)
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes)[0]
The variable `results` is a list of dictionaries, each dictionary containing the scores, labels and boxes for an image in the batch as predicted by the model.
The model will give n=100 predictions for each image. By default this n is set to 100, and it represents the number of object queries present in the prediction head. Not all of the predictions are needed, and we need to remove the redundant predictions.
# Filter boxes based on confidence score (threshold can be adjusted)
threshold = 0.9
scores = results["scores"].numpy()
keep = scores > threshold
boxes = results["boxes"].numpy()[keep]
labels = results["labels"].numpy()[keep]
scores = scores[keep]
In the above block of code, we are filtering out the predictions which have a score of greater than the threshold value, the threshold is set to 0.9. The line `keep = scores > threshold` will create a binary array containing 1 for the predictions that have scores greater than threshold and 0 for the rest of the predictions.
Once we have the filtered predictions, we can visualize them by plotting the bounding box on the image.
for box, label, score in zip(boxes, labels, scores):
xmin, ymin, xmax, ymax = box
box_width = xmax - xmin
box_height = ymax - ymin
img_width, img_height = image_rgb.shape[:2]
font_scale = calculate_label_size(box_width, box_height, img_width, img_height, max_scale=1)
label_text = f"{model.config.id2label[label]}: {score:.2f}"
(text_width, text_height), baseline = cv2.getTextSize(
label_text,
cv2.FONT_HERSHEY_SIMPLEX,
font_scale,
1
)
# Get the color for this label
color = get_label_color(label)
# Draw rectangle and label with the same color for the same class
cv2.rectangle(image_rgb, (int(xmin), int(ymin)), (int(xmax), int(ymax)), color, max(2, int(font_scale * 3)))
cv2.rectangle(image_rgb, (int(xmin), int(ymin) - text_height - baseline - 5),
(int(xmin) + text_width, int(ymin)), color, -1)
cv2.putText(image_rgb, label_text, (int(xmin), int(ymin) - baseline - 2),
cv2.FONT_HERSHEY_SIMPLEX, font_scale, (0, 0, 0), max(1, int(font_scale * 1.5)), cv2.LINE_AA)
plt.figure(figsize=(10, 10))
plt.imshow(image_rgb)
plt.axis("off") # Hide axes
plt.show()
In the code block above, we will be iterating over the filtered predictions and plot it on the image, along with the label of the bounding box. The functions get_label_color and calculate_label_size are helper functions that helps choose the color of the bounding box and relative size of the label text.
We have put all the above code blocks in a single function. This takes input the image path and performs all the processes that we have discussed above.
# Function to predict and plot bounding boxes
def predict_and_plot_boxes(image_path, threshold=0.9):
# Step 1: Load and preprocess the image
image = cv2.imread(image_path)
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
inputs = processor(images=image_rgb, return_tensors="pt")
# Step 2: Run inference
with torch.no_grad():
outputs = model(**inputs)
# Step 3: Post-process the results
# Convert the outputs (logits) into bounding boxes and labels
target_sizes = torch.tensor([image_rgb.shape[:2]]) # Image size (height, width)
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes)[0]
# Filter boxes based on confidence score (threshold can be adjusted)
scores = results["scores"].numpy()
keep = scores > threshold
boxes = results["boxes"].numpy()[keep]
labels = results["labels"].numpy()[keep]
scores = scores[keep]
for box, label, score in zip(boxes, labels, scores):
xmin, ymin, xmax, ymax = box
box_width = xmax - xmin
box_height = ymax - ymin
img_width, img_height = image_rgb.shape[:2]
font_scale = calculate_label_size(box_width, box_height, img_width, img_height, max_scale=1)
label_text = f"{model.config.id2label[label]}: {score:.2f}"
(text_width, text_height), baseline = cv2.getTextSize(
label_text,
cv2.FONT_HERSHEY_SIMPLEX,
font_scale,
1
)
# Get the color for this label
color = get_label_color(label)
# Draw rectangle and label with the same color for the same class
cv2.rectangle(image_rgb, (int(xmin), int(ymin)), (int(xmax), int(ymax)), color, max(2, int(font_scale * 3)))
cv2.rectangle(image_rgb, (int(xmin), int(ymin) - text_height - baseline - 5),
(int(xmin) + text_width, int(ymin)), color, -1)
cv2.putText(image_rgb, label_text, (int(xmin), int(ymin) - baseline - 2),
cv2.FONT_HERSHEY_SIMPLEX, font_scale, (0, 0, 0), max(1, int(font_scale * 1.5)), cv2.LINE_AA)
# Step 5: Plot the image with bounding boxes
plt.figure(figsize=(10, 10))
plt.imshow(image_rgb)
plt.axis("off") # Hide axes
plt.show()
The above function can be called as `predict_and_plot_boxes(‘image.jpeg’)`.
We tested DETR model on some images, and this are the results we got –





Inference Result Analysis
Although we are getting almost perfect results in the first 4 images, we can see that in the last image, some bananas are not being detected. This can be improved by reducing the value of confidence threshold. The image below shows the output on the same image, but using a lower value of threshold of 0.85. The following image can be reproduced with this function call –
predict_and_plot_boxes('/inference_data/images/000000052123.jpg', threshold=0.85)

Predicting on Video dataset
We modified the above code to work on videos. This is the function that takes input a video, and predicts the objects and saves the video in given directory –
def process_video(video_path, output_path):
"""
Process a video file using GPU acceleration (if available) for object detection.
"""
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model.to(device)
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
raise ValueError("Error opening video file")
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
out = cv2.VideoWriter(output_path, fourcc, fps, (frame_width, frame_height))
pbar = tqdm(total=total_frames, desc="Processing frames",
unit="frames", dynamic_ncols=True)
frame_count = 0 # To count total frames.
total_fps = 0 # To get the final frames per second.
try:
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Start timing for this frame
start_time = time.time()
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
inputs = processor(images=frame_rgb, return_tensors="pt")
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
target_sizes = torch.tensor([frame_rgb.shape[:2]]).to(device)
results = processor.post_process_object_detection(outputs, target_sizes=target_sizes)[0]
scores = results["scores"].cpu().numpy()
threshold = 0.9
keep = scores > threshold
boxes = results["boxes"].cpu().numpy()[keep]
labels = results["labels"].cpu().numpy()[keep]
scores = scores[keep]
# Draw bounding boxes
for box, label, score in zip(boxes, labels, scores):
xmin, ymin, xmax, ymax = box
box_width = xmax - xmin
box_height = ymax - ymin
font_scale = calculate_label_size(box_width, box_height, frame_width, frame_height)
label_text = f"{model.config.id2label[label]}: {score:.2f}"
(text_width, text_height), baseline = cv2.getTextSize(
label_text,
cv2.FONT_HERSHEY_SIMPLEX,
font_scale,
1
)
cv2.rectangle(frame,
(int(xmin), int(ymin)),
(int(xmax), int(ymax)),
(0, 255, 0),
max(1, int(font_scale * 2)))
cv2.rectangle(frame,
(int(xmin), int(ymin) - text_height - baseline - 5),
(int(xmin) + text_width, int(ymin)),
(0, 255, 0),
-1)
cv2.putText(frame,
label_text,
(int(xmin), int(ymin) - baseline - 2),
cv2.FONT_HERSHEY_SIMPLEX,
font_scale,
(0, 0, 0),
max(1, int(font_scale * 1.5)),
cv2.LINE_AA)
end_time = time.time()
# Get the current fps.
fps = 1 / (end_time - start_time)
# Add `fps` to `total_fps`.
total_fps += fps
# Increment frame count.
frame_count += 1
# Add FPS counter to frame
add_fps_counter(frame, fps, frame_width)
out.write(frame)
pbar.update(1)
if pbar.n % 100 == 0:
torch.cuda.empty_cache()
gc.collect()
except Exception as e:
print(f"An error occurred: {e}")
raise
finally:
pbar.close()
cap.release()
out.release()
cv2.destroyAllWindows()
torch.cuda.empty_cache()
gc.collect()
model.to('cpu')
print("nVideo processing completed!")
We will call this function on the videos present in the downloaded dataset. The inference are done using T4 GPU in Google Colab. Here are the results –
Inference 1
Inference 2
Inference 3
Conclusion
In this article, we went through the architecture of DETR, and also covered some points on how DETR is different from CNN based computer vision models. We also did inference on images and videos, and looked at the results given by the models. Hope this article can be your companion in exploring the DETR model, which shows the effectiveness of using transformer based models for the task of object detection.
References
- End-to-End Object Detection with Transformers
- https://huggingface.co/docs/transformers/en/model_doc/detr






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning