

In this post, we will compare the performance of various Deep Learning inference frameworks on a few computer vision tasks on the CPU.
Surprisingly, with one exception, the OpenCV port of various deep learning models outperform the original implementation when it comes to performance on a CPU.
In this post, we will compare the CPU speed of the following Deep Learning algorithms :
Testing Machine Configuration
Here is the configuration of the system we used.
- Machine : AWS t2.large instance. This instance has 2 vCPUs and 8 GB of RAM, but no GPU.
- Operating System : Ubuntu 16.04 LTS.
- OpenCV version : 3.4.3 ( installed using a slightly modified version of our OpenCV installation instructions ).
- Testing methodology : 100 cycles of the same test were performed and average time is reported.
Image Classification
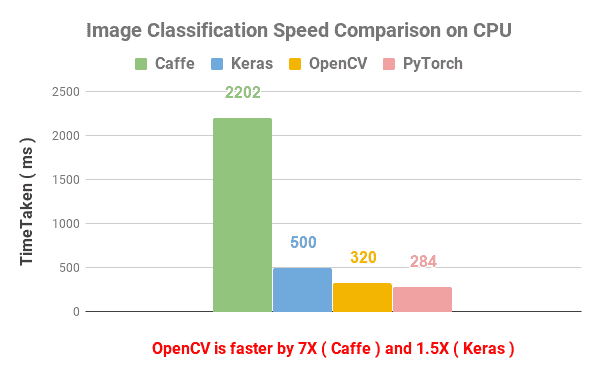
The first application we compared is Image Classification on Caffe 1.0.0 , Keras 2.2.4 with Tensorflow 1.12.0, PyTorch 1.0.0 with torchvision 0.2.1 and OpenCV 3.4.3.
We used the pre-trained model for VGG-16 in all cases.
The results are shown in the Figure below.
PyTorch at 284 ms was slightly better than OpenCV (320ms). Keras came in third at 500 ms, but Caffe was surprisingly slow at 2200 ms.
Object Detection
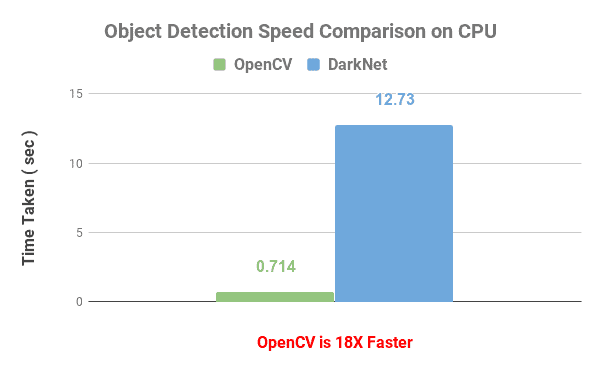
The second application we chose was Object detection using YOLOv3 on Darknet.
The comparison was made by first importing the standard YOLOv3 object detector to OpenCV. If you are not familiar how to do this, please check out our post on Object detection using YOLOv3 and OpenCV
Darknet, when compiled without OpenMP, took 27.832 seconds per frame. Yes, that is not milliseconds, but seconds.
When compiled with OpenMP, Darknet was more than twice as fast with 12.730 seconds per frame.
But OpenCV accomplished the same feat at an astounding 0.714 seconds per frame.
Object Tracking
The third application we tested was Object Tracking. For this, we chose a Deep Learning based object tracker called GOTURN. Now, this is not an apples-to-apples comparison because OpenCV’s GOTURN model is not exactly the same as the one published by the author. They were trained on different datasets. However, the underlying architecture is based on the same paper.
We compared the GOTURN Tracker in OpenCV with the Caffe based reference implementation provided by the authors of the GOTURN paper.
The OpenCV version ran at an impressive 50 ms per frame and was 6x faster than the reference implementation. Remember, these are both CPU implementations.
![]()
Pose Estimation
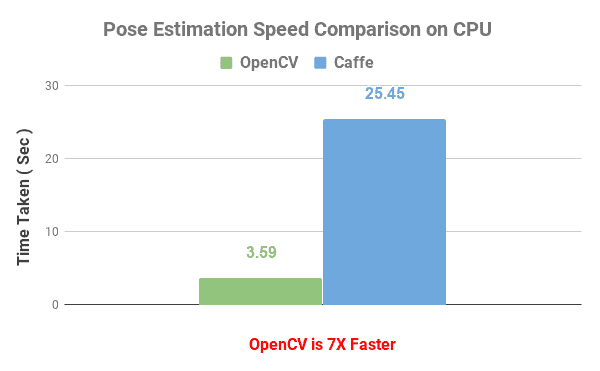
In the problem of Pose Estimation, given a picture of one or more people, you find the stick figure that shows the position of their various body parts.
If you have not read our post about Human Pose Estimation , you should check it out. We show how to import one of the best Pose Estimation libraries called OpenPose into an OpenCV application.
We compared the reference implementation of OpenPose in Caffe with the same model imported to OpenCV 3.4.3.
The reference implementation took 25.45 seconds while the OpenCV version took only 3.598 seconds.
Why is OpenCV’s Deep Learning implementation on the CPU so fast? — The non-technical answer
In corporate America, whenever you see something unusual, you can find an answer to it by following the money.
Let’s start with the GPU story.
Which company is the top GPU seller in the world? Yup, it is NVIDIA. The company was very smart to realize the importance of GPUs in general purpose computing and more recently in Deep Learning.
In 2007, they released CUDA to support general purpose computing and in 2014 they released cuDNN to support Deep Learning on their GPUs. Consequently, the GPU implementation of all Deep Learning frameworks (Tensorflow, Torch, Caffe, Caffe2, Darknet etc.) is based on cuDNN. This has been a huge win for NVIDIA which has benefitted from the AI wave in addition to the cryptocurrency wave.
Now, which company is the top CPU seller in the world? Intel of course.
If you are new to OpenCV, you may not know OpenCV started at Intel Labs and the company has been funding its development for the most part. For a while, an independent company called Itseez was maintaining OpenCV, but recently it was acquired by — no points for guessing — Intel. The core OpenCV team is therefore at Intel.
As far as AI is concerned, Intel is in the inference business. Nobody uses Intel processors to train Deep Learning models, but a lot of people use their CPUs for inference. Therefore, Intel has a huge incentive to make OpenCV DNN run lightning fast on their CPUs.
Finally, the huge speed up also comes from the fact that the core team has deep optimization expertise on Intel CPUs.
OpenCV DNN : Insider’s knowledge
I had a call with Dmitry Kurtaev who is part of the core OpenCV team and has been working on the DNN module for about 2 years. He was kind enough to give me a quick overview of the DNN module. So here is some inside knowledge I acquired from Dmitry.
How it all started
I learned from Dmitry that the DNN module was started as part of Google Summer of Code (GSOC) by an intern Vitaliy Lyudvichenko who worked on it over two summers. Currently, the DNN module supports a few different backends
- Reference C++ implementation (default)
- Halide
- OpenCL
- OpenVINO
All results shown in this post used the reference C++ implementation.
Halide backend and why not to use it
There was an effort to make the DNN module faster using Halide but one fine day Vadim Pisarevsky optimized the reference CPU implementation to
the point that it was much faster than the Halide version! So, we are better off using the reference C++ implementation.
OpenCL backend and when to use it
The DNN module supports Intel GPUs with the OpenCL backend. Quite frankly, I am not impressed by the GPU support. The only silver lining is that OpenCV with OpenCL backend supports 16-bit floating point operations which can be 2x faster when using a GPU compared to the 32-bit version.
OpenVINO Toolkit
Remember, I mentioned how Intel has a huge incentive to make inference faster on CPUs. Well, the fastest DNN speed on Intel CPUs and other platforms like FPGAs and Neural Compute Stick is provided by Intel’s Open Visual Inference and Neural network Optimization ( OpenVINO ) toolkit. This will be covered in our next post.
Subscribe
If you liked this article, please subscribe to our newsletter. You will also receive a free Computer Vision Resource guide. In our newsletter, we share Computer Vision, Machine Learning and AI tutorials written in Python and C++ using OpenCV, Dlib, Keras, Tensorflow, CoreML, and Caffe.