

NVIDIA’s Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender for video understanding and embodied reasoning is mainly attributed to its dataset and training strategy.
Existing LLMs or VLMs are disembodied intelligent systems trained on web-scale internet data. While they may acquire essential knowledge to reason about real world, but they often struggle to ground that knowledge to real world dynamics and interactions. They lack the spatial, temporal and physical understanding of how actions performed by a physical system affect its environment which humans do instinctively and effortlessly. For e.g., spatial puzzles, object permanence, about arrow of time etc. This makes them less suitable for complex systems such as robots or autonomous vehicles that need to perceive, understand and interact with the physical world.
- Training Dataset
- Multimodal Architecture
- Cosmos Reason1: Training Strategy
- Benchmark Results
- Code Walkthrough of Cosmos Reason1 Inference
- Conclusion
- References
To generate physically grounded responses, Cosmos understands the physical world through the given video input, understands it, with long chain of thought reasoning.
Simply put, understanding how the world works while respecting physical constraints is called physical common sense whereas embodied reasoning refers to how an agent acts or interacts within that world to plan actions that achieve goals.
Let’s take a closer look at them.
Training Dataset
The model was trained on carefully curated ~4M video-text pairs that focuses on,
I. Physical common sense
This part of dataset has 16 subcategories covering:
- Space: Relationship between objects, what’s plausible (can a football fit in a teacup?), what object afford , and understanding different environments.
- Time: The sequence of actions , forward or backward, cause and effect (causality) etc.
- Fundamental Physics: Object Permanence, states, mechanics , thermodynamics. It even includes Anti-Physics to help the model recognize impossible scenarios.

The dataset includes captions for physical understanding, multiple choice questions, and long chain-of-thought reasoning traces. The data preparation is developed as two pipelines.
1. High quality and detailed narratives of videos with human annotators and pre-trained VLMs.
2. Model Distillation from Deepseek-R1 for Physical AI supervised fine-tuning which captures long chain of thought reasoning traces of deepseek and teach Cosmos Reason1 how to think.

II. Embodied reasoning
Understanding the world is one thing, knowing how to act within it as an embodied agent (like a robot or a self-driving car) is another important aspect for intelligent systems. The second part of the dataset was designed around NVIDIA’s 2D embodied reasoning ontology, focusing on four key capabilities for five types of embodied agents.
Types of Embodied agents are,
- Humans
- Animals
- Robot Arms
- Humanoid Robots
- Autonomous vehicles
The data aimed to teach reasoning for,
- Task-completion verification: “Did the robot successfully pick the block?”
- Action affordance: “Is it possible for the car to make this turn safely?”
- Next plausible action prediction: “Given a pedestrian crosses a road, what is the next likely action the car should do?”
Reasoning Embodied AI enables the physical systems to ground their action to intelligently operate in uncertain and dynamic environments.


Multimodal Architecture: Transformers and Mamba MLP
Cosmos VLM uses a vision encoder and an LLM decoder. The vision encoder processes the visual information while the text is tokenized into text tokens. Both the visual and text representations are projected into a common embedding space, concatenated and then passed to the LLM decoder.

The 7B model uses a standard dense Transformer architecture whereas the 56B employs a hybrid Mamba-MLP-Transformer Decoder. This design choice is due to Mamba architecture’s efficient handling of long video sequences where traditional transformers has quadratic complexity processing them.

The following table better represents the configuration details of Cosmos-Reason1 models.

Cosmos Reason1: Training Strategy
The models were trained on two stages:
- Physical AI SFT
- Physical AI RL
I. Supervised Fine-tuning (SFT)
The objective of this stage is to take a pretrained Vision Language Model (Qwen2.5-VL) and specialize it for Physical AI tasks using the curated dataset.
- 1.82M understanding QA pairs
- 1.94M long Chain-of-thought reasoning traces
These models are designed to take a video input along with text prompts, and generate natural language responses. The output responses aren’t just simple answers the can include:
- Explanation: Describing why something is happening?
- Embodied decisions: Suggesting next action to take.
- Reasoning: Going through Long chain-of-thought reasoning (mental steps) to arrive at a conclusion.

II. Reinforcement Learning (RL)
To further enhance the model’s physical common sense and embodied reasoning capabilities in decision making with a simple rule-based rewards: An accuracy reward (did the model pick the correct MCQ option?) and a format reward (did the model correctly use <think> and <answer> tags for its reasoning and final answer?).
The authors used an efficient algorithm GRPO (Generalized Reward Policy Optimization) similarly to the one used in Deepseek R1. This algorithm doesn’t require training a separate critic model and the framework is fully asynchronous.
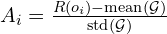
Example 1:
- Before RL: Given a tricky scenario (single lane, parked cars, oncoming traffic, double yellow lines indicating no passing) and asked for next action, the model might incorrectly suggest changing to (non-existent or illegal) left lane.
- After RL: The model is tuned to correctly identify the constraints and suggest “None of provided options” to abide by road rules and ensure safety. This is the interesting part, rather than simply choosing from the given options or guessing a likely one, the model actually reasons through the given environment and intelligently decides to take the appropriate next action.
Example 2:


The authors have also developed a novel, fully asynchronous and robust RL training framework to make highly efficient and fault tolerant fine-tuning.

This two-stage approach, in SFT provides the broad knowledge and chain of though reasoning capabilities followed by RL for refined decision making enabled Cosmos Reason1 to outperform proprietary models like Gemini2.0 Flash, GPT-4o.
Benchmark Results
To evaluate Cosmos on Physical AI capabilities, Physical common sense, and embodied reasoning, NVIDIA developed a suite of benchmarks tailored to evaluate model performance across various task-specific datasets. It consists of
- 604 MCQs for common sense reasoning
- 610 MCQs for embodied reasoning
The benchmark results shows that Cosmos-Reason1-7B was able to double up its scores compared it to the Qwen2.5-VL 7B baseline. The benchmarks also shows the performance gains due to post fine-tuning with RL has given around +5 on average.




Code Walkthrough of Cosmos Reason1 Inference
We have tried the inference on a RTX3080Ti 12GB, official vLLM pipeline for inference and was facing OOM error. The pipeline also doesn’t support 4bit or 8bit quantization. As we know that the Cosmos-Reason1-7B is fine-tuned from Qwen2.5-VL Instruct model. Therefore we decided to use the Qwen2_5_VLForConditionalGeneration to make use of bitsandbytes for 4 bit quantization which occupied close to ~8.1GB VRAM.
Qwen-VL Utils contains a set of helper functions for processing and integrating visual language information with Qwen-VL Series Model.
Installing Dependencies
!pip install transformers==4.51.3 accelerate
!pip install qwen-vl-utils
Next, install bitsandbytes package for model quantization.
!pip install bitsandbytes
Import Packages
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor, BitsAndBytesConfig
from qwen_vl_utils import process_vision_info
import torch
Load the model in 4bit Quantization
We found there was a difference in response quality with quantization, however it was better than the base Qwen2.5-VL Instruct model.
# Model and quantization setup
MODEL_PATH = "nvidia/Cosmos-Reason1-7B"
# MODEL_PATH = "Qwen/Qwen2.5-VL-7B-Instruct"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
)
# Load model
llm = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_PATH,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
The model expects the video inputs as a list of dictionaries with Qwen reasoning (<think>) chat template.
# Message structure
video_messages = [
{"role": "system", "content": (
"You are a helpful assistant. Answer the question in the following format:\n"
"<think>\nyour reasoning\n</think>\n\n<answer>\nyour answer\n</answer>."
)},
{"role": "user", "content": [
{"type": "text", "text": "Is it safe to turn right?"},
{"type": "video", "video": "assets/av_example.mp4", "fps": 4},
]},
]
The processor receives the video message and applies the chat template to match Cosmos Reason1’s expected input structure.
# Processor and inputs
processor = AutoProcessor.from_pretrained(MODEL_PATH)
prompt = processor.apply_chat_template(
video_messages,
tokenize=False,
add_generation_prompt=True,
)
image_inputs, video_inputs, video_kwargs = process_vision_info(video_messages, return_video_kwargs=True)
inputs = processor(
text=[prompt],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to(llm.device)
Finally, the preprocessed input is passed to the LLM decoder to generate the response.
# Generate
generated_ids = llm.generate(
**inputs,
temperature=0.6,
top_p=0.95,
repetition_penalty=1.05,
max_new_tokens=4096,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Inference 1 – Testing Decision Making
Note: The thinking traces of the model is truncated and only the final response (<answer> ) is shown in the following image.


Inference 2: Testing Temporal Spatial Awareness
As a human we can see the following video is playing backward. Initially with only SFT Cosmos Reason1 wasn’t right about the arrow of time based on action and movement in frames. However, with additional post training with RL the model better comprehends the given scenario as the video is playing backward showing its usefulness.
Inference 3: Action Prediction
Place the green snack package into the shopping cart.
Inference 4
The advertisement for Pepsi begins with a dark, mysterious setting where two cans of Pepsi stand prominently against an almost pitch-black backdrop (Frame 0.0). As the scene progresses, one can is moved into focus by a hand, revealing its sleek design and vibrant colors more clearly while maintaining some anonymity due to blurred figures in the background (Frame 3.29).
Next, attention shifts to the opening process as droplets of condensation form on the can's surface when it is opened (Frame 6.63), emphasizing freshness and refreshment. The camera then transitions smoothly to show a glass filled with ice cubes, bubbles rising vigorously within the liquid, highlighting the carbonation and effervescence typical of Pepsi (Frame 9.97).
In subsequent scenes, different settings illustrate various contexts where Pepsi can be enjoyed—such as at casual gatherings like barbecues or movie nights. A can sits unobtrusively amidst plates of food, suggesting convenience during social events (Frame 13.3); another appears alongside popcorn and drinks being held up enthusiastically among friends in what looks like a lively party atmosphere (Frame 16.64 & Frame 23.31).
The visual narrative continues with abstract representations of energy and excitement using dynamic patterns around the iconic logo (Frames 19.98 and 26.65). These abstractions symbolize how Pepsi enhances moments shared with others.
Finally, the campaign culminates in a bold statement about preference ("BETTER WITH"), accompanied by multiple cans arranged diagonally across a stark black canvas, reinforcing the brand's message that Pepsi complements every occasion better than any other soda option (Frame 29.99). This final frame serves as a strong conclusion, leaving viewers with a clear impression of why they should choose Pepsi over competitors.
Conclusion
Reasoning over videos requires excellent understanding about the spatial and temporal context from all the available image sequences of a video. It is one of challenging problem where modern Vision Language Models (VLM) often struggle and fell short in generating accurate responses. Cosmos Reason1 success lies in design choices (Mamba) , dataset curation and two-stage fine-tuning (SFT and RL). Cosmos Reason1 shows a significant leap in Video Understanding, Physical AI and Embodied Reasoning. It’s another gem to the open source community from NVIDIA.
References
- Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
- Cosmos Reason1: Project
- Docscope R1 : HuggingFace Spaces



100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning