SANA-Sprint: Get high-quality (1024, 1024) AI images in a single step! Learn about this ultra-fast diffusion model transforming image generation & real-time AI.
Ever watched an AI-generated video and wondered how it was made? Or perhaps dreamed of creating your own dynamic scenes, only to be overwhelmed by the complexity or the need
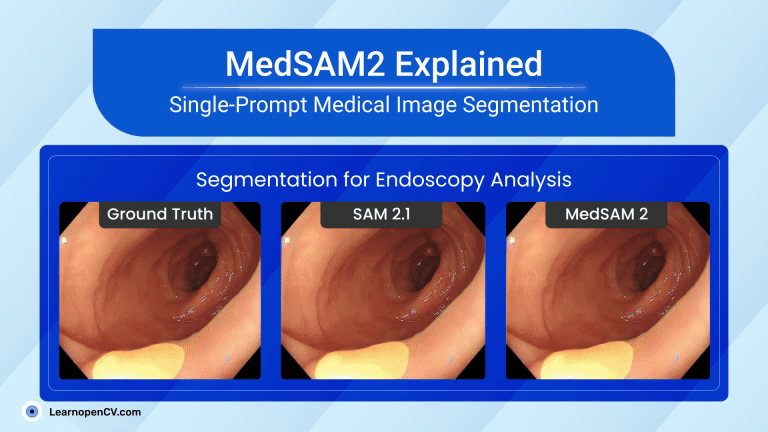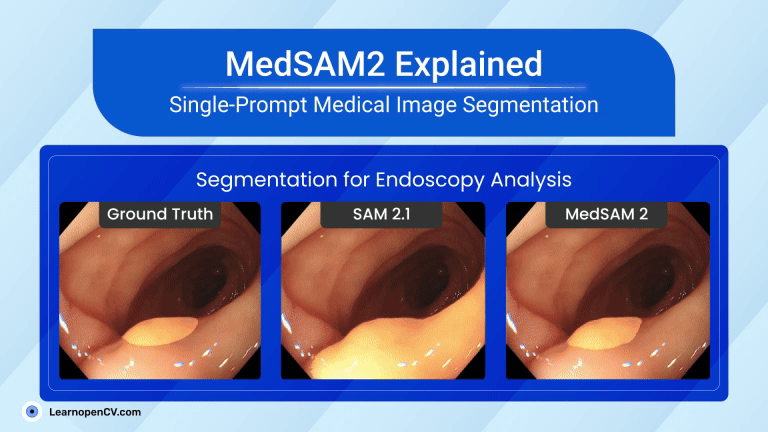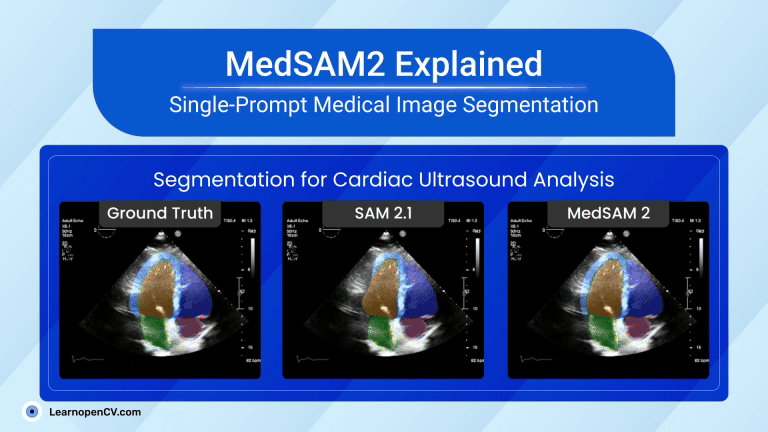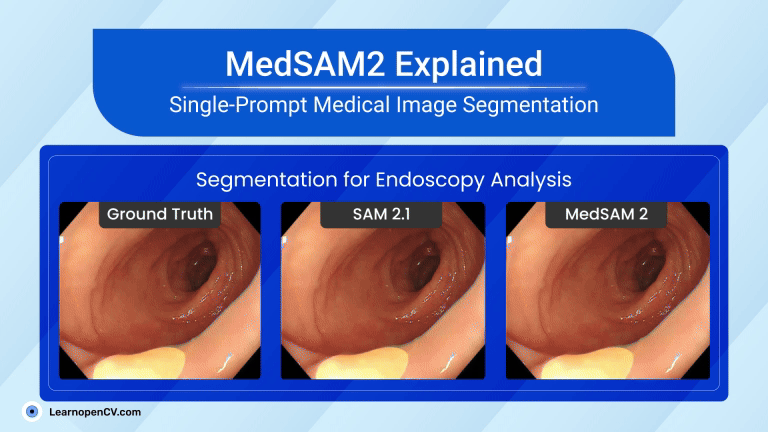
MedSAM2 brings “segment anything” power to healthcare, carving organs, tumours, and even moving heart chambers from CT, MRI, PET, and live ultrasound with a single prompt. Running in < 1
The field of computer vision is fueled by the remarkable progress in self-supervised learning. At the forefront of this revolution is DINOv2, a cutting-edge self-supervised vision transformer developed by Meta
MASt3R-SLAM is a truly plug and play monocular dense SLAM pipeline that operates in-the-wild. It is first of its kind real-time SLAM system that leverages MASt3R’s 3D Reconstruction priors to
The world of generative AI moves at a lightning speed, constantly pushing the boundaries of what is possible. In the vibrant field of text-to-image synthesis, generating stunningly detailed, high-resolution images
Object detection has come a long way, especially with the rise of transformer-based models. RF-DETR, developed by Roboflow, is one such model that offers both speed and accuracy. Using Roboflow’s
Fine-Tuning Gemma 3 allows us to adapt this advanced model to specific tasks, optimizing its performance for domain-specific applications. By leveraging QLoRA (Quantized Low-Rank Adaptation) and Transformers, we can efficiently
ComfyUI – a powerful, node-based graphical user interface (GUI) that offers flexibility and transparency when working with stable diffusion models. This article provides an introduction to ComfyUI, covering installation and
GPT-4o image generation is a game-changer! With native support in ChatGPT, you can now create stunning visuals from text prompts, refine them, and explore styles like Studio Ghibli or photorealism.
Imagine you have multiple warehouses in different places where you don’t have time to monitor everything at a time, and you can’t afford a lot of computes due to their