Understanding large GitHub repositories can be time-consuming. Code-Analyser tackles this problem by using an agentic, approach to parse and analyze codebases.
Processing long documents with VLMs or LLMs poses a fundamental challenge: input size exceeds context limits. Even with GPUs, as large as 12 GB can barely process 3-4 pages at
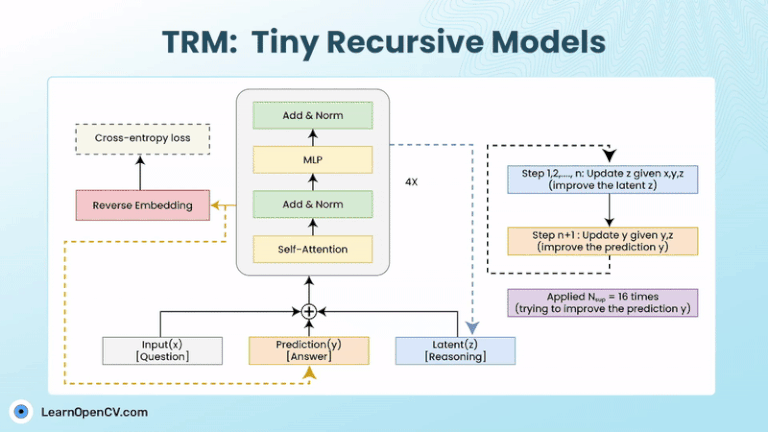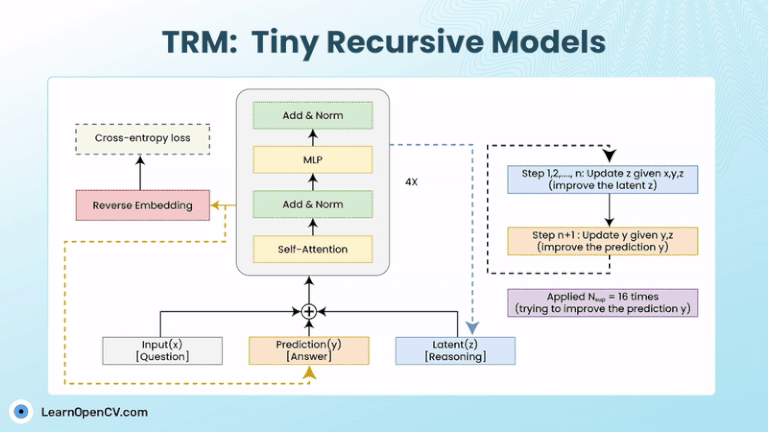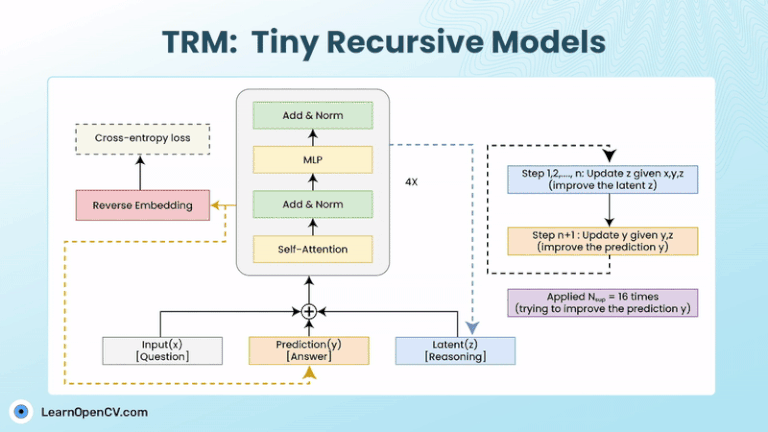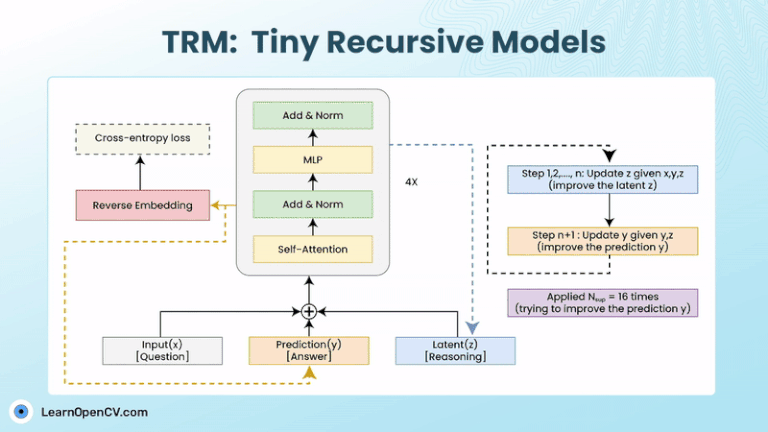
Models with billions, or trillions, of parameters are becoming the norm. These models can write essays, generate code, as well as create art. But they can still get stuck on
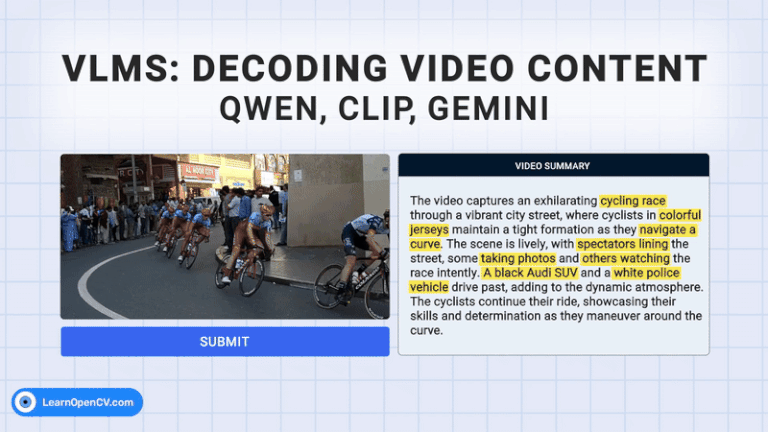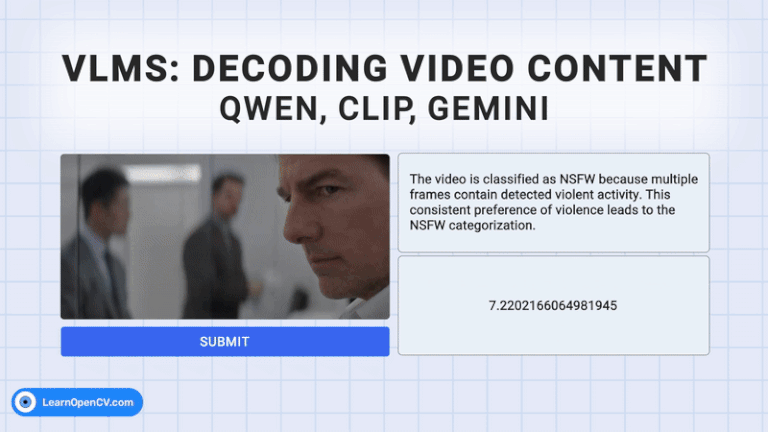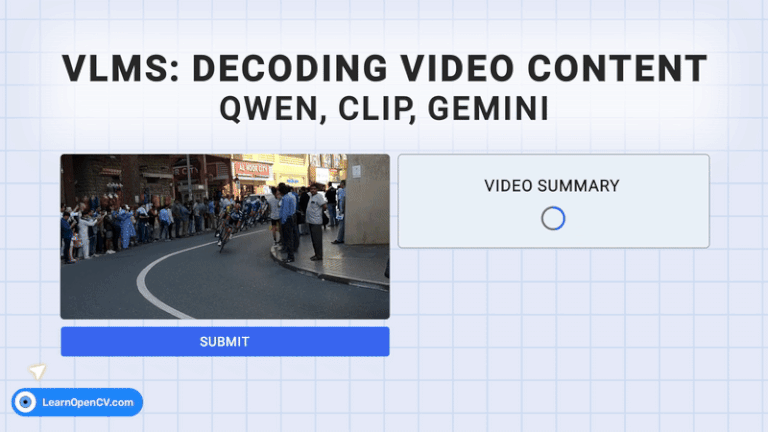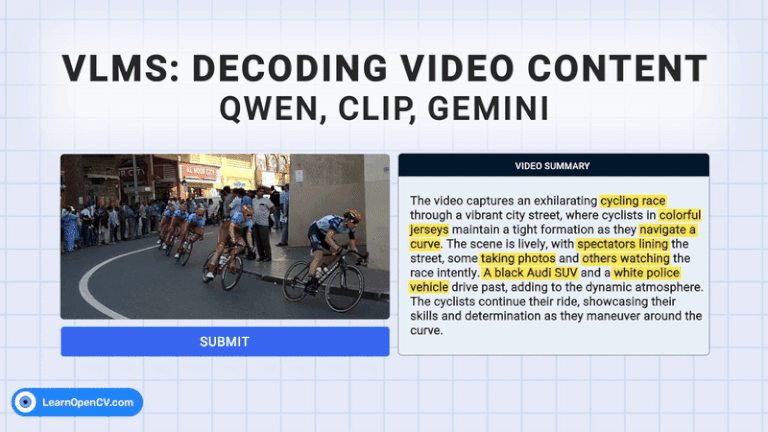
The rapid growth of video content has created a need for advanced systems to process and understand this complex data. Video understanding is a critical field in AI, where the
Welcome back to our LangGraph series! In our previous post, we explored the fundamental concepts of LangGraph by building a Visual Web Browser Agent that could navigate, see, scroll, and summarize
SimLingo is a remarkable model that combines autonomous driving, language understanding, and instruction-aware control—all in one unified, camera-only framework. It not only delivered top rankings on CARLA Leaderboard 2.0 and
Developing intelligent agents, using LLMs like GPT-4o, Gemini, etc., that can perform tasks requiring multiple steps, adapt to changing information, and make decisions is a core challenge in AI development.
SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
The domain of video understanding is rapidly evolving, with models capable of interpreting complex actions and interactions within video streams. Meta AI’s VJEPA-2 (Video Joint Embedding Predictive Architecture) stands out