The Annotated NeRF – Training on Custom Dataset from Scratch in Pytorch
In recent years, the field of 3D from multi-view has become one of the most popular topics in computer vision conferences, with a high number of submitted papers each year. A groundbreaking paper in this field is the 2020 work titled “NeRF: Representing Scenes as Neural Radiance Fields for View
In recent years, the field of 3D from multi-view has become one of the most popular topics in computer vision conferences, with a high number of submitted papers each year. A groundbreaking paper in this field is the 2020 work titled “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis”, proposing a simple concept of scene parameterization using neural networks. NeRF models are not just capable of synthesizing novel views, it also takes care of View-Dependent scenes and is able to represent the depth map of a scene with complex occlusions. NeRF PyTorch offers an accessible implementation of this powerful model. Instant NGP and Mip-NeRF360 are two robust adaptations of NeRF. For further reading and a deeper understanding, one can refer to these papers.
This article aims to explore the internal workings of the Original NeRF model by Mildenhall et al.,implementing it step-by-step in PyTorch, based on Yen-Chen Lin’s implementation. Additionally, we will cover how to train a NeRF model on a custom dataset using PyTorch. We’ll guide you through the process and provide code and a Colab notebook to kickstart your own NeRF journey.
So, let’s get started! This blog post has been structured in the following way.
The NeRF paper is fairly straightforward to read if you have a background in computer graphics and 3D computer vision. However, if you don’t, don’t worry, we’ll cover the key 3D graphics concepts involved in the paper.
“NeRF can be explained with 3 words, “Neural Volume Rendering”,
Neural means there is a learned Neural Network involved Volumetric implies we are specifically using volume rendering not surface rendering Rendering is the process of generating 2D images of a 3D scene from a specific viewpoint”
Neural Radiance Fields (NeRF) use a neural network to predict the color and volume density at each sampled point along rays projected from the camera frame in 3D space. These predictions are then combined using volume rendering to generate the final image of the scene.
The “Neural” part of NeRF is an MLP (multi-layer perceptron) denoted by . This takes the camera location and viewing direction(, ) and predicts the emitted color from a point along the ray and the volume density () at that point. Volume density represents how much a point in a 3D space absorbs or scatters light, quantifying the opacity of the material at that location. It determines how “thick” or “transparent” the medium is along a ray.
Fig 1 Input and Output of the NeRF Neural Network
Once the color and volume density are predicted, classical volume rendering methods are applied to generate an image. The rendered image is then compared to the ground truth using L2 loss, which guides model optimization. Since volume rendering is inherently differentiable, the model requires only a set of images with known camera poses (position + direction) for training. These camera poses are estimated using COLMAP’s structure-from-motion pipeline. Below is the entire pipeline for NeRF.
Fig 2 NeRF Training Pipeline
This pipeline is capable of rendering novel views, estimate depth maps of the scene (later used to create mesh or point cloud representation), and maintain a View-Dependent appearance (means change of color or appearance of the scene based on the viewpoint). The authors introduced some more concepts for producing better output from NeRF, which are:
Positional encoding
Hierarchical volume sampling
We will be discussing this in greater detail further in the blog post. Let’s start by understanding the fundamentals for Volume Rendering.
Prefer listening? Check out the podcast version of this article.
Introduction to Volume Rendering
In the 1900s, there was a challenge in rendering volumes, like smoke and clouds, that don’t have clear, defined surfaces. Volume rendering emerged as a solution, enabling us to visualize and interact with semi-transparent materials, revealing their internal structures.
Let’s start with image formation or “2D render of a 3D scene”, means projecting the 3D scene in the 2D camera frame, which involves two things,
Computer Vision: Mapping the 3D coordinates of the scene into the 2D coordinates of the camera frame. This generally involves Coordinate Transformation and Perspective Projection. These two topics have been discussed in depth in our Visual SLAM article. Computer vision is also used to create 3D structures from images.
Fig 3 Computer Graphics VS Computer Vision
Computer Graphics: Determines the color and opacity of the pixel corresponding to a 3D point. This is done using Volume Rendering.
Core Equations of Volume Rendering
In volume rendering, we need to compute the color and opacity for each pixel by marching rays through a 3D field (the volume) and accumulating color contributions from various points along these rays. Each of these points has properties that determine how they absorb and emit light.
Fig 4 Ray marching through the volume in Volume Rendering
Rays are cast from each pixel of the view plane toward the scene, and instead of reflecting off surfaces, they travel through the volume. We then sample points along the rays and integrate them to get the final radiance of the ray, which contributes as the pixel color. Radianceis theamount of light traveling along a ray at a given point and in a specific direction. Radiance integrates both emitted and absorbed light as it travels through the medium.
Ray Equations
For each pixel, a ray is cast from the camera through the volume. The ray equation is typically parameterized by:
where:
is the ray origin (camera position),
is the ray direction,
is the distance along the ray.
If the ray travelling through the volume hits a particle at distance along the ray, we return its color .
There is a probabilistic motion to hitting that point/particle, which combines,
Probability of hitting the point
Probability that the ray reaches the point without being blocked
Probabilistic chance that a ray “hits” or interacts with a particle in a small interval around the point along its path is represented as:
Here, is called the volume density at point and is an infinitesimally small length along the ray. It implies that the denser the medium at , the more likely it is for the ray to interact with a particle in that small segment along its path. And the probability of reaching point with being blocked is called transmittance .
Combining these two terms we get the probability of ray travelling to point without getting blocked.
By applying Taylor expansion for , we arrive at,
The above equation gives the probability density function (PDF) that describes the probability, that the ray hits a particular point along its path through the volume.
Integrating the product of the probability density and the color at each point provides the accumulated color contribution along the ray’s path. Here, represents the color field.
In computational implementations (e.g., ray marching in NeRF), we typically evaluate the integral in discrete steps along the ray to approximate the continuous integral. Given a ray that starts from and ends at , is being split in segments with endpoints . We assume the interval between segments as and volume density is constant for each of the segments. Based on these assumptions we can work through the above equation to get below equation,
Fig 5 Sophisticated Weighted Average of the colors of the points along the ray Source
is used as a weight, and the final radiance observed along a ray, , is calculated as a weighted sum of the color of each segment.
NeRF MLP Network
Below is the detailed MLP model architecture used in NeRF. The MLP starts with 8 fully-connected (Linear) layers with a ReLU activation, followed by another fully-connected layer of dimension 256 (the 9-th layer). Finally a fully connected layer with 128 nodes and 3 output dimensions (10-th layer). There is another linear layer after the 8-th layer with a single output channel for volume density prediction (not visible in the diagram but in the code). According to the paper, the last layer is a sigmoid function to keep the RGB values between 0 to 1 (represented with a dashed arrow). But, in code the sigmoid function is not part of the model architecture. Instead it’s being applied separately during post-processing. To prevent over-fitting, a skip connection is included between the first and 5th layers.
Fig 6 MLP Architecture of NeRF
The camera position and direction is not passed to the model together. The position of the camera is passed to the first layer and viewing direction concatenated with the 9-th layer’s feature vector and passed to the 10-th layer.
NeRF Positional Encoding
“deep networks are biased towards learning lower frequency functions”
The idea of introducing positional encoding in NeRF comes from the paper “Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains” by the same authors. Fully-connected deep networks models generally have spectral bias—its tendency to learn low-frequency components earlier in the training process. To improve this, positional encoding (Fourier feature mapping) maps the original low-dimensional input , and into a higher-dimensional feature space by applying periodic functions, sine and cosine:
Positional Encoding might sound familiar for people who have worked on transformer models, but here positional encoding is used to transform the input to a higher dimension, not to encode the position of each pixel.
Fig 7 How Positional Encoding helps to capture high frequency features
The authors experimented with the idea of creating a MLP model to predict the RGB (r,g,b) color, given pixel coordinates as input (an image compression problem). Models trained without positional encoding produced results like the one shown in Fig: 7. In this figure, it is visible that the model is only able to learn the low-frequency features, the high-frequency variations, such as sharp edges or fine textures are absent. To solve that the authors proposed the Positional Encoding method.
Hierarchical Volume Sampling
In volume rendering the ray from the camera travels through the volume, and numbers of points are being sampled along the ray. However, this approach is inefficient, as it samples points in free space and occluded regions that do not contribute to the rendered image. To improve this, the authors introduced Hierarchical volume sampling, taking inspiration from early work in volume rendering [1].
See the below image. White points are the points that are being sampled using stratified sampling (uniform sampling), where each point is equidistant. After using these points for volume rendering we get the weights , which is interpreted as the contribution of the color at point . Based on the weights we can decide where the surface of the volume lies. After we know the surface we sample more points near that region, generally a PDF sampler is used to sample points in that area.
Fig 8 PDF sampling red Vs stratified samplingwhite
The authors proposed two networks, “coarse” and “fine” both having the same architecture as mentioned above. The coarse model takes the uniformly sampled points and predicts the volume density and RGB values, which is being passed to the volume rendering pipeline to get the final image and the weights. These weights are then passed to the PDF sampler to sample more points along the boundary of the surface, which is finally passed to the fine network and the volume renderer to get the final output.
Even though the fine model’s output is used for final rendering, both fine and coarse models are optimized simultaneously using a single loss function. The loss function is described as the combined L2 loss, taking the output of both coarse and fine networks, described as,
: The RGB color predicted by the coarse network for ray .
: The RGB color predicted by the fine network for ray .
: The ground truth RGB color for ray .
A total of 64 points per ray are sampled through the coarse network, and 192 points per ray (64 + 128) through the fine network, resulting in 256 network queries per ray. For a realistic synthetic dataset, each image requires 640k rays, while real scenes require 762k rays per image, resulting in approximately 150 and 200 million network queries per rendered image. The model consists of 560k learnable parameters.
Can’t read right now? You can listen to the podcast version of this article instead.
NeRF Pytorch Code Implementation
Let’s go through the code sequentially. First we will understand how points along the rays are being sampled, then we will understand positional encoding from NeRF point of view, after that we will discuss the model architecture in detail and finally how hierarchical sampling is implement.
Ray Batching
Generally, in vision-based deep learning, models typically take a batch of images and labels as input. However, in NeRF, the model processes a batch of points (represented by the poses of the points) along the rays and predicts their color and volume density. The concept of ray batching can be a bit difficult to digest, but the code below provides an explanation of how it works. The function get_rays_np takes the height (H), width (W), camera intrinsic matrix (K) and transformation matrix of camera w.r.t World (c2w). The output is rays_o and rays_d, which are the position and direction of each point in a ray, both having size of (H, W, 3).
def get_rays_np(H, W, K, c2w):
i, j = np.meshgrid(np.arange(W, dtype=np.float32), np.arange(H, dtype=np.float32), indexing='xy')
dirs = np.stack([(i-K[0][2])/K[0][0],
-(j-K[1][2])/K[1][1],
-np.ones_like(i)], -1)
# Rotate ray directions from camera frame to the world frame
rays_d = np.sum(dirs[..., np.newaxis, :] * c2w[:3,:3], -1) # dot product, equals to: [c2w.dot(dir) for dir in dirs]
# Translate camera frame's origin to the world frame. It is the origin of all rays.
rays_o = np.broadcast_to(c2w[:3,-1], np.shape(rays_d))
return rays_o, rays_d
Let’s say, W=3 and H=3 and focal length is 2, based on this information we create a intrinsic matrix K and camera w.r.t world transformation matrix c2w is a identity matrix. Then, below is how the matrix rays_o (origin of each pixel in 3D) and rays_d (direction in 3D Cartesian) will turn out.
We need to create a ray batch containing the position and direction of the ray from each pixel of the view plane. In the 1st line, np.meshgrid, we create meshgrid for pixel coordinates, i and j, which will have the following values: The direction vectors (dirs) represent the straight paths from the camera’s center to each pixel on the image plane, calculated in the camera’s local coordinate frame using the intrinsic matrix K.
This means that the direction of the pixel at the position of the image is . Here, is added as the homogeneous coordinate, and it is negative because every ray is cast outward from the camera. Now, if we multiply that direction vector with the rotation part of the transformation matrix (c2w[:3,-1]), it will give the direction of that pixel in 3D (rays_d). As the c2w is an identity matrix, so the dirs are equal to rays_d. For the position of pixels in the image (rays_o), we just take the camera position and broadcast it in the shape of rays_d.
Given are the data directory (args.datadir), scaling factor of the image (args.factor), and boolean argument for args.spherify. The spherify argument is quite interesting, if it’s true, then the camera pose (position+direction) captured using COLMAP, are re-centered and re-scaled to fit within a unit sphere stored at poses. The function spherify_poses is also responsible for computing a spherically distributed set of new render_poses around the scene and adjusts the scene bounds – Far and near (bds) accordingly.
# llff data generation
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor, recenter=True, bd_factor=.75, spherify=args.spherify)
# get the intrinsic value
hwf = poses[0,:3,-1]
# actual 3x4 matrix [R|t]
poses = poses[:,:3,:4]
# This code generates, organizes, and shuffles a batch of rays (origin, direction) and their corresponding RGB values for training, using only the training images.
if use_batching:
# Generate rays for all poses: ray origins and directions for each pixel
rays = np.stack([get_rays_np(H, W, K, p) for p in poses[:,:3,:4]], 0) # [N, ro+rd, H, W, 3] -> (335, 2, 640, 360, 3) --> N here are number of images
# Concatenate the RGB values of images to the corresponding rays
rays_rgb = np.concatenate([rays, images[:, None]], 1) # [N, ro+rd+rgb, H, W, 3] --> (335, 3, 640, 360, 3)
# Rearrange dimensions for easy access (N: number of images, H, W: height and width of images)
rays_rgb = np.transpose(rays_rgb, [0, 2, 3, 1, 4]) # [N, H, W, ro+rd+rgb, 3] --> (335, 640, 360, 3, 3)
# Keep rays only from the training images (defined by i_train indices)
rays_rgb = np.stack([rays_rgb[i] for i in i_train], 0) # Train images only(i_train is the trianing img indexes) --> (293, 640, 360, 3, 3)
# Flatten the rays and RGB data into a single array for all pixels in all training images
rays_rgb = np.reshape(rays_rgb, [-1, 3, 3]) # [(N-1)*H*W, ro+rd+rgb, 3] --> (67507200, 3, 3)
# Convert the ray and RGB data to 32-bit floating point for efficient computation
rays_rgb = rays_rgb.astype(np.float32)
# Shuffle the rays and their corresponding RGB values to randomize the training data
print('shuffle rays')
np.random.shuffle(rays_rgb)
The above code carries out three important functions:
Running the get_rays_np to get the ray origin and ray direction for each image (training + test).
In the next line it also incorporates the RGB value associated with each pixel.
Prepare a shuffled training set of ray batch.
“Note for each pixel now we are storing three things,
Origin coordinates in 3D (x,y,z)
Direction vector in 3D (roll, pitch, yaw)
and finally the r,g,b value of the pixel
This is why the initial dimension of rays_rgb is (N, H, W, ro+rd+rgb, 3), here ro+rd+rgb is 3 and each of his ro,rd and rgb has 3 values.“
Positional encoding is like the embedding layer, transforming a low dimensional input (3 dimensional x,y,z and 2 dimensional camera , ) to a high dimensional input. Note that some places in the paper, it says that the model takes the 2 dimensional viewing direction (, , which is according spherical coordinate system) and some place it says it takes 3 dimensional viewing direction (roll, pitch, yaw which is according Cartesian coordinate system). We will consider the viewing direction as represented in the Cartesian coordinate system.
Following is the formula for calculating the positional encoding. The function is applied separately to each of the three coordinate values in , which are normalized to lie within [-1, 1], and to the three components of the Cartesian viewing direction unit vector d, which also lies within [-1, 1] by construction. In our experiments, we set for and for .
The function create_embedding_fn takes the arguments from self.kwargs, and returns a list of functions which is p_fn(x * freq), here freq is coming from freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs), and p_fn is the torch.sin, torch.cos. Here, max_freq is , for position max_freq = 10, for direction max_freq=4.
get_embedder is the function used to call positional embedding class Embedder. The embed_kwargs is passed in the class argument. in embed_kwargs the multires implies , for position its 10, for direction its 4.
# Positional encoding (section 5.1)
class Embedder:
def __init__(self, **kwargs):
self.kwargs = kwargs
self.create_embedding_fn()
def create_embedding_fn(self):
embed_fns = []
d = self.kwargs['input_dims']
out_dim = 0
if self.kwargs['include_input']:
embed_fns.append(lambda x : x)
out_dim += d
max_freq = self.kwargs['max_freq_log2']
N_freqs = self.kwargs['num_freqs']
if self.kwargs['log_sampling']:
freq_bands = 2.**torch.linspace(0., max_freq, steps=N_freqs)
else:
freq_bands = torch.linspace(2.**0., 2.**max_freq, steps=N_freqs)
for freq in freq_bands:
for p_fn in self.kwargs['periodic_fns']:
embed_fns.append(lambda x, p_fn=p_fn, freq=freq : p_fn(x * freq))
out_dim += d
self.embed_fns = embed_fns
self.out_dim = out_dim
def embed(self, inputs):
return torch.cat([fn(inputs) for fn in self.embed_fns], -1)
def get_embedder(multires, i=0):
if i == -1:
return nn.Identity(), 3
embed_kwargs = {
'include_input' : True,
'input_dims' : 3,
'max_freq_log2' : multires-1,
'num_freqs' : multires,
'log_sampling' : True,
'periodic_fns' : [torch.sin, torch.cos],
}
embedder_obj = Embedder(**embed_kwargs)
embed = lambda x, eo=embedder_obj : eo.embed(x)
return embed, embedder_obj.out_dim
The inputs passed in the embed function has the shape of (N_rays * N_samples, 3). Here, N_samples represents the number of points taken along a ray and the last dimension is 3, which represents x,y,z coordinates of the samples. Assuming we are applying positional encoding on the camera position, let’s say we have 10 rays and each ray has 64 samples, having 3 coordinate values (x,y,z).
Below is the model architecture, made of Linear layers and ReLU activation. Input, D is the depth of the network, W is the number of nodes inside the 1st D linear layers. self.input_ch is the number of input channels for the 3D spatial coordinates and self.input_ch_views is the number of input channels for the viewing direction.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchinfo import summary
# Define the NeRF model class
class NeRF(nn.Module):
def __init__(self, D=8, W=256, input_ch=3, input_ch_views=3, output_ch=4, skips=[4], use_viewdirs=False):
super(NeRF, self).__init__()
self.D = D
self.W = W
self.input_ch = input_ch
self.input_ch_views = input_ch_views
self.skips = skips
self.use_viewdirs = use_viewdirs
self.pts_linears = nn.ModuleList(
[nn.Linear(input_ch, W)] +
[nn.Linear(W, W) if i not in self.skips else nn.Linear(W + input_ch, W) for i in range(D-1)]
)
self.views_linears = nn.ModuleList([nn.Linear(input_ch_views + W, W//2)])
if use_viewdirs:
self.feature_linear = nn.Linear(W, W)
self.alpha_linear = nn.Linear(W, 1)
self.rgb_linear = nn.Linear(W//2, 3)
else:
self.output_linear = nn.Linear(W, output_ch)
def forward(self, x):
input_pts, input_views = torch.split(x, [self.input_ch, self.input_ch_views], dim=-1)
h = input_pts
for i, l in enumerate(self.pts_linears):
h = self.pts_linears[i](h)
h = F.relu(h)
if i in self.skips:
h = torch.cat([input_pts, h], -1)
if self.use_viewdirs:
alpha = self.alpha_linear(h)
feature = self.feature_linear(h)
h = torch.cat([feature, input_views], -1)
for i, l in enumerate(self.views_linears):
h = self.views_linears[i](h)
h = F.relu(h)
rgb = self.rgb_linear(h)
outputs = torch.cat([rgb, alpha], -1)
else:
outputs = self.output_linear(h)
return outputs
# Create a sample input tensor for NeRF
batch_size = 4
input_ch = 3
input_ch_views = 3
sample_input = torch.randn(batch_size, input_ch + input_ch_views).cuda() # Random sample input, on GPU
# Initialize the NeRF model
nerf_model = NeRF(use_viewdirs=True).cuda() # Send the model to GPU
# Forward pass
outputs = nerf_model(sample_input)
outputs.shape
# >>
# torch.Size([4, 4])
Figure 10 Model Architecture Side by Side comparison
The first 8 (D) layers are made using Linear layers and ReLU activation, and the 5th layer has a skip connection. The 9th layer (self.alpha_linear(h)) responsible for predicting the volume density. self.pts_linears is the list of layers that process the position (x,y,z) of the points along the ray and the self.views_linears processes the direction metric. self.rgb_linear is responsible for predicting the r,g,b values of the points. Below is the model architecture.
Hierarchical Sampling
The Hierarchical sampling concept states that, to avoid sample points along the ray, which are in the free space or in the the occluded areas, we first figure out which sampled points are near the volume surface, and then do more point sampling near that area.
# Hierarchical sampling (section 5.2)
def sample_pdf(bins, weights, N_samples, det=False, pytest=False):
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
# A zero is prepended to the CDF to handle boundary conditions, ensuring the CDF starts from 0 and ends at 1.
cdf = torch.cat([torch.zeros_like(cdf[...,:1]), cdf], -1) # (batch, len(bins))
# Take uniform samples
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
# Pytest, overwrite u with numpy's fixed random numbers
if pytest:
np.random.seed(0)
new_shape = list(cdf.shape[:-1]) + [N_samples]
if det:
u = np.linspace(0., 1., N_samples)
u = np.broadcast_to(u, new_shape)
else:
u = np.random.rand(*new_shape)
u = torch.Tensor(u)
# Inver CDF
u = u.contiguous() # ensures that `u` has contiguous memory layout
inds = torch.searchsorted(cdf, u, right=True)
below = torch.max(torch.zeros_like(inds-1), inds-1)
above = torch.min((cdf.shape[-1]-1) * torch.ones_like(inds), inds)
inds_g = torch.stack([below, above], -1) # (batch, N_samples, 2)
# cdf_g = tf.gather(cdf, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
# bins_g = tf.gather(bins, inds_g, axis=-1, batch_dims=len(inds_g.shape)-2)
matched_shape = [inds_g.shape[0], inds_g.shape[1], cdf.shape[-1]]
cdf_g = torch.gather(cdf.unsqueeze(1).expand(matched_shape), 2, inds_g)
bins_g = torch.gather(bins.unsqueeze(1).expand(matched_shape), 2, inds_g)
denom = (cdf_g[...,1]-cdf_g[...,0])
denom = torch.where(denom<1e-5, torch.ones_like(denom), denom)
t = (u-cdf_g[...,0])/denom
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
return samples
The sample_pdf function uses the inverse CDF method to find out the points’ location (bins) given the probability values (weights). The weights represent the probabilities under different intervals (bins). In the 2nd line, weights are being normalized to ensure they sum to 1, creating a valid Probability Density Function (PDF). cdf is being calculated as the cumulative sum of pdf.
# Get pdf
weights = weights + 1e-5 # prevent nans
pdf = weights / torch.sum(weights, -1, keepdim=True)
cdf = torch.cumsum(pdf, -1)
As the det = False, only the else is executed. Means that u is a tensor of shape (batch, N_samples), having elements from 0-1. In the Invert CDF part,
# Take uniform samples
if det:
u = torch.linspace(0., 1., steps=N_samples)
u = u.expand(list(cdf.shape[:-1]) + [N_samples])
else:
u = torch.rand(list(cdf.shape[:-1]) + [N_samples])
First, we identify the indices where the value in u should be placed in the sorted cdf. Example: if and , then:
falls in the 2nd bin ().
falls in the 3rd bin ().
# Inver CDF
u = u.contiguous() # ensures that `u` has contiguous memory layout
inds = torch.searchsorted(cdf, u, right=True)
the variable below gives the index of the lower bound of the bin for each u, ensuring the indices do not go below 0. For example, with inds = [2, 3],
the result is below = [1, 2], which refers to the lower edge of the bins.
Variable above gives the index of the upper bound of the bin containing each u. It ensures indices do not exceed the highest valid index (cdf.shape[-1] – 1). Example: For :
Now that we know the upper and lower indices, we use that to retrieve the cdf and bins in the form of cdf_g and bins_g. cdf_g retrieves the CDF values (probabilities) at the lower and upper bounds (specified by inds_g) and bins_g retrieves the bin edges (or corresponding values of the random variable) at the lower and upper bounds (again specified by inds_g).
denom represents the difference between the upper and lower CDF bounds. t is the relative position of u within the CDF bounds. Given: t is the relative position of u within the CDF bounds.
Compute by dividing: represents the relative position of u within the CDF bounds [0.5, 0.8].
samples is the final sample value within the bin bounds, calculated as,
t = (u-cdf_g[...,0])/denom
samples = bins_g[...,0] + t * (bins_g[...,1]-bins_g[...,0])
The following code block shows the usage.
# Sample inputs
bins = torch.linspace(0, 1, steps=11) # 10 intervals (bins)
weights = torch.tensor([0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.3, 0.25, 0.2, 0.1]) # Arbitrary weights
weights = weights / torch.sum(weights) # Normalize to sum to 1
N_samples = 5 # Number of samples to draw
det = False # Random sampling
# Expand the inputs to include a batch dimension
bins = bins.unsqueeze(0) # Shape: [1, 11]
weights = weights.unsqueeze(0) # Shape: [1, 10]
samples = sample_pdf(bins, weights, N_samples, det=det)
Volume Rendering
During inference, first create_nerf is being called for loading the model weight and parameters and initiating the model. After that, the render function is called, which accepts the camera intrinsics, and the desired camera pose for rendering and returns the RGB image and depth map. Internally the render function prepares the ray origin location (rays_o) and viewing direction (rays_d), and calls batchify_rays to render rays in smaller mini batches. The batchify_rays internally calls render_rays. render_rays is the function where the model forward pass takes place and volume rendering happens. This function takes the ray_batch and the model network_fn and some more parameters. The ray_batch is transformed into the points along the ray and stored inside pts shape ([N_rays, N_samples, 3]).z_vals are uniformly distributed depth values along the ray based on volume near and far bounds. these z_vals later used to points along the ray,
pts, viewdirs and network_fn are passed in the network_query_fn, which carries out the inference and gives a raw output. On a side note, viewdirs is the normalized version of rays_d. raw is then passed to the raw2outputs function that does all the rendering. Let’s understand how this works.
def raw2outputs(raw, z_vals, rays_d, raw_noise_std=0, white_bkgd=False, pytest=False):
"""Transforms model's predictions to semantically meaningful values.
Args:
raw: [num_rays, num_samples along ray, 4]. Prediction from model.
z_vals: [num_rays, num_samples along ray]. Integration time.
rays_d: [num_rays, 3]. Direction of each ray.
Returns:
rgb_map: [num_rays, 3]. Estimated RGB color of a ray.
disp_map: [num_rays]. Disparity map. Inverse of depth map.
acc_map: [num_rays]. Sum of weights along each ray.
weights: [num_rays, num_samples]. Weights assigned to each sampled color.
depth_map: [num_rays]. Estimated distance to object.
"""
raw2alpha = lambda raw, dists, act_fn=F.relu: 1.-torch.exp(-act_fn(raw)*dists)
dists = z_vals[...,1:] - z_vals[...,:-1]
dists = torch.cat([dists, torch.Tensor([1e10]).expand(dists[...,:1].shape)], -1) # [N_rays, N_samples]
dists = dists * torch.norm(rays_d[...,None,:], dim=-1)
rgb = torch.sigmoid(raw[...,:3]) # [N_rays, N_samples, 3]
noise = 0.
if raw_noise_std > 0.:
noise = torch.randn(raw[...,3].shape) * raw_noise_std
# Overwrite randomly sampled data if pytest
if pytest:
np.random.seed(0)
noise = np.random.rand(*list(raw[...,3].shape)) * raw_noise_std
noise = torch.Tensor(noise)
alpha = raw2alpha(raw[...,3] + noise, dists) # [N_rays, N_samples]
# weights = alpha * tf.math.cumprod(1.-alpha + 1e-10, -1, exclusive=True)
weights = alpha * torch.cumprod(torch.cat([torch.ones((alpha.shape[0], 1)), 1.-alpha + 1e-10], -1), -1)[:, :-1]
rgb_map = torch.sum(weights[...,None] * rgb, -2) # [N_rays, 3]
depth_map = torch.sum(weights * z_vals, -1)
disp_map = 1./torch.max(1e-10 * torch.ones_like(depth_map), depth_map / torch.sum(weights, -1))
acc_map = torch.sum(weights, -1)
if white_bkgd:
rgb_map = rgb_map + (1.-acc_map[...,None])
return rgb_map, disp_map, acc_map, weights, depth_map
dists stores the distances between consecutive sample points along the ray, adjusted for the ray direction’s magnitude. dists is being multiplied with torch.norm(rays_d[...,None,:], dim=-1) to ensure that the distances (dists) are measured in world space rather than normalized ray space.
The neural network last sigmoid function is applied here as rgb = torch.sigmoid(raw[...,:3]).
This computes , representing the probability of interaction at each sampled point. comes from the model’s raw density output, and is the distance between consecutive samples (dists).
alpha = raw2alpha(raw[...,3] + noise, dists)
: Cumulative product of transmittance up to the -th sample. : Represents how much each sample contributes to the final color.
: Weighted sum of colors () for all samples. weights[…, None] * rgb multiplies the contribution of each sample with its color, and torch.sum accumulates the results over all samples.
rgb_map = torch.sum(weights[...,None] * rgb, -2)
This computes the weighted average of depths () using the weights.
depth_map = torch.sum(weights * z_vals, -1)
Train NeRF on Custom Dataset
This section contains the details for training the NeRF model. Let’s start with data preparation.
Data Preparation
The run_nerf.py script is the training script, it has the ability to process a few different types of data, such as llff, blender, LINEMOD and deepvoxels. But in this article we will be using the llff format of data.
First we need to create a 360 degree video of the scene, keeping a symmetric, monotonic background. After that, we process the video and extract the video frames, which is done using video2imgs.py. Then we pass the extracted frames to the COLMAP (structure from motion pipeline), to get the camera intrinsics, and extrinsics parameters, and finally that’s being converted in the llff format. This process is done using imgs2poses.py script.
After preparing we need to create a config.txt file in the config folder, and mention the dataset path in datadir field. This file also has other important parameters such as, training_iterations, factor (image scaling factor), N_rand(ray batch size) etc. After this, we can simply run the run_nerf.py file to train the model. Training time might vary based on the image size and iteration etc.
Install COLMAP
COLMAP is available as an apt package, so simple apt install works fine. if you get stuck you can install it from source, follow the official documentation.
$ sudo apt install colmap
After this is done you can either clone the official nerf-pytorch or download the code from below. It is suggested to opt for the later option, as it will have all the dataset link, llff format conversion code and any other code required to train the model. We have also added training logging using wandb.
Download Code
To easily follow along this tutorial, please download code by clicking on the button below. It's FREE!
Now, we will run COLMAP and convert the data into llff format. factor can be anything (generally 2-8 based on the original image size). The value of this factor parameter also needs to be updated in the config.txt file.
After preparing the dataset, we will update the config file based on the prepared dataset directory, and factor parameter etc. After that’s done we can directly run below command to start training,
Finally, at the end of training the model weights will be stored in the <expname>/logs folder. To do inference and extract mesh from the model, use the extract_mesh.ipynb notebook.
Experimentation
Based on the experimentation, data curation plays a crucial role in achieving good results. It’s important to ensure that the background of the subject is monotonic and featureless. Additionally, COLMAP may fail when objects lack sufficient features, such as corners or planes. I’ve also observed that the model performs best with a smaller number of images, around 50, achieving lower loss and higher PSNR. Using 100 images still yields decent results, but more than that tends to worsen performance. Below are a few examples where the model performed well and where it struggled with cloudy artifacts.
Key Takeaways
Neural Radiance Fields (NeRF) represent a significant leap forward in the realm of 3D scene representation and view synthesis. By leveraging neural networks, NeRF can create rich, view-dependent representations of complex scenes, opening up new possibilities in various applications. Here are the key takeaways from our deep dive into this revolutionary technique:
Neural Radiance Fields (NeRF): A groundbreaking method for 3D scene representation and view synthesis using neural networks.
Volume Rendering: Essential for visualizing semi-transparent materials by tracing rays and integrating color contributions along their paths.
Positional Encoding: Enhances the model’s ability to capture high-frequency details by transforming low-dimensional inputs into higher-dimensional spaces.
Hierarchical Volume Sampling: Improves efficiency by focusing sampling on regions near the volume surface, avoiding unnecessary computations in free space or occluded areas.
Ray Batching: A unique approach in NeRF where the model processes batches of points along rays, predicting color and volume density for each point.
Applications: NeRF opens up possibilities in augmented reality, virtual reality, robotics, and more, enabling rich, view-dependent 3D scene reconstructions.
Conclusion
In this detailed guide, we explored the revolutionary Neural Radiance Fields (NeRF) technique for 3D scene representation and view synthesis. We covered essential concepts like volume rendering, the architecture of the NeRF model, and key techniques such as positional encoding and hierarchical volume sampling. Through a step-by-step PyTorch implementation, we demonstrated how to train a NeRF model on a custom dataset, emphasizing the importance of ray batching and advanced sampling methods.
By mastering NeRF, we unlock new possibilities for creating rich, view-dependent 3D scenes, with applications spanning augmented reality, virtual reality, robotics, and more. As we continue to advance these techniques, the potential for immersive and interactive 3D experiences will only expand, driving innovation in computer vision and graphics.
References
[1] Levoy, M.: Efficient ray tracing of volume data. ACM Transactions on Graphics (1990)
If you liked this article and would like to download code (C++ and Python) and example images used in this post, please click here. Alternately, sign up to receive a free Computer Vision Resource Guide. In our newsletter, we share OpenCV tutorials and examples written in C++/Python, and Computer Vision and Machine Learning algorithms and news.
Discover VideoRAG, a framework that fuses graph-based reasoning and multi-modal retrieval to enhance LLMs' ability to understand multi-hour videos efficiently.




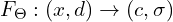 . This takes the camera location
. This takes the camera location 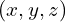 and viewing direction(
and viewing direction(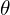 ,
, 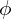 ) and predicts the emitted color
) and predicts the emitted color 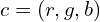 from a point along the ray and the volume density (
from a point along the ray and the volume density (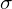 ) at that point. Volume density
) at that point. Volume density 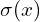 represents how much a point
represents how much a point 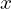 in a 3D space absorbs or scatters light, quantifying the opacity of the material at that location. It determines how “thick” or “transparent” the medium is along a ray.
in a 3D space absorbs or scatters light, quantifying the opacity of the material at that location. It determines how “thick” or “transparent” the medium is along a ray.



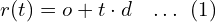
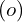 is the ray origin (camera position),
is the ray origin (camera position),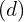 is the ray direction,
is the ray direction,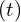 is the distance along the ray.
is the distance along the ray.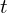 along the ray, we return its color
along the ray, we return its color 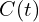 .
.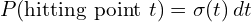
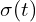 is called the volume density at point
is called the volume density at point 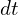 is an infinitesimally small length along the ray. It implies that the denser the medium
is an infinitesimally small length along the ray. It implies that the denser the medium 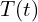 .
.
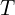 , we arrive at,
, we arrive at,
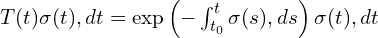
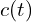 provides the accumulated color contribution along the ray’s path. Here,
provides the accumulated color contribution along the ray’s path. Here, 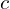 represents the color field.
represents the color field.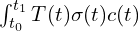
 and ends at
and ends at 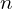 segments with endpoints
segments with endpoints 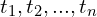 . We assume the interval between segments as
. We assume the interval between segments as 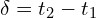 and volume density is constant for each of the segments. Based on these assumptions we can work through the above equation to get below equation,
and volume density is constant for each of the segments. Based on these assumptions we can work through the above equation to get below equation,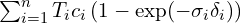

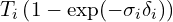 is used as a weight, and the final radiance observed along a ray,
is used as a weight, and the final radiance observed along a ray, 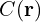 , is calculated as a weighted sum of the color of each segment.
, is calculated as a weighted sum of the color of each segment.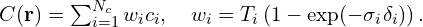

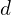 into a higher-dimensional feature space by applying periodic functions, sine and cosine:
into a higher-dimensional feature space by applying periodic functions, sine and cosine:

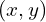 as input (an image compression problem). Models trained without positional encoding produced results like the one shown in Fig: 7. In this figure, it is visible that the model is only able to learn the low-frequency features, the high-frequency variations, such as sharp edges or fine textures are absent. To solve that the authors proposed the Positional Encoding method.
as input (an image compression problem). Models trained without positional encoding produced results like the one shown in Fig: 7. In this figure, it is visible that the model is only able to learn the low-frequency features, the high-frequency variations, such as sharp edges or fine textures are absent. To solve that the authors proposed the Positional Encoding method.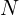 numbers of points are being sampled along the ray. However, this approach is inefficient, as it samples points in free space and occluded regions that do not contribute to the rendered image. To improve this, the authors introduced Hierarchical volume sampling, taking inspiration from early work in volume rendering [1].
numbers of points are being sampled along the ray. However, this approach is inefficient, as it samples points in free space and occluded regions that do not contribute to the rendered image. To improve this, the authors introduced Hierarchical volume sampling, taking inspiration from early work in volume rendering [1].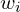 , which is interpreted as the contribution of the color at point
, which is interpreted as the contribution of the color at point  . Based on the weights we can decide where the surface of the volume lies. After we know the surface we sample more points near that region, generally a PDF sampler is used to sample points in that area.
. Based on the weights we can decide where the surface of the volume lies. After we know the surface we sample more points near that region, generally a PDF sampler is used to sample points in that area.


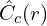 : The RGB color predicted by the coarse network for ray
: The RGB color predicted by the coarse network for ray 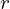 .
.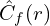 : The RGB color predicted by the fine network for ray
: The RGB color predicted by the fine network for ray 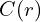 : The ground truth RGB color for ray
: The ground truth RGB color for ray 

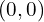 position of the image is
position of the image is ![[-0.5, 0.5, -1]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-6a6102ba3b31c9523ddd2305ecfb7008_l3.png) . Here,
. Here, 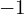 is added as the homogeneous coordinate, and it is negative because every ray is cast outward from the camera. Now, if we multiply that direction vector with the rotation part of the transformation matrix (
is added as the homogeneous coordinate, and it is negative because every ray is cast outward from the camera. Now, if we multiply that direction vector with the rotation part of the transformation matrix (

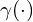 is applied separately to each of the three coordinate values in
is applied separately to each of the three coordinate values in 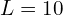 for
for 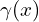 and
and 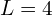 for
for 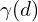 .
.
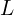 , for position
, for position 
![cdf = [0, 0.1, 0.4, 1.0]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-c876a09acec34eb20088ea9905039117_l3.png) and
and ![u = [0.2, 0.6]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-a0325261d2539b19ab919992fc4e848d_l3.png) , then:
, then:
![u[0] = 0.2](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-9bc787ab933e7816c310c18c3a6a13a2_l3.png) falls in the 2nd bin (
falls in the 2nd bin (![inds[0] = 2](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-06508df90e870832d076ff3e1cfa804c_l3.png) ).
).![u[1] = 0.6](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-ff9e134624ceab47ba5efb2b3ebbb3b4_l3.png) falls in the 3rd bin (
falls in the 3rd bin (![inds[1] = 3](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-2a85da7aea547a8990f5823d7600f20d_l3.png) ).
).![inds = [2, 3]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-2beff24ab69d581bdfa88b0f7a3e406d_l3.png) :
:
![above = [2, 3]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-66862618c19dca53dda3749d41c1cdef_l3.png) , referring to the upper edge of the bins.
, referring to the upper edge of the bins.![below = [1, 2]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-84ac4f9b1e684a75d46115fee9544b2d_l3.png) and
and ![inds_g = [[1, 2], [2, 3]]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-d8c5f97d5d84524b8dc9ef98dc5b6938_l3.png) , representing the bin intervals for each sample.
, representing the bin intervals for each sample.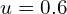 (the uniform random value we are sampling for).
(the uniform random value we are sampling for).![\text{cdf}_{\text{low}} = cdf_g[..., 0] = 0.5](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-6a9ce4e11686f746b403e2c410192872_l3.png) (lower bound CDF value).
(lower bound CDF value).![\text{cdf}_{\text{high}} = cdf_g[..., 1] = 0.8](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-cb258b496f3e2b78e3c243e044c0475c_l3.png) (upper bound CDF value).
(upper bound CDF value).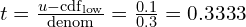
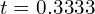 represents the relative position of u within the CDF bounds [0.5, 0.8].
represents the relative position of u within the CDF bounds [0.5, 0.8].
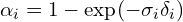 , representing the probability of interaction at each sampled point.
, representing the probability of interaction at each sampled point. 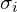 comes from the model’s raw density output, and
comes from the model’s raw density output, and 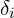 is the distance between consecutive samples (
is the distance between consecutive samples (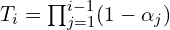 : Cumulative product of transmittance up to the
: Cumulative product of transmittance up to the 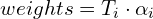 : Represents how much each sample contributes to the final color.
: Represents how much each sample contributes to the final color.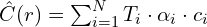 : Weighted sum of colors (
: Weighted sum of colors (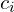 ) for all samples. weights[…, None] * rgb multiplies the contribution of each sample with its color, and torch.sum accumulates the results over all samples.
) for all samples. weights[…, None] * rgb multiplies the contribution of each sample with its color, and torch.sum accumulates the results over all samples. ) using the weights.
) using the weights.





100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning