

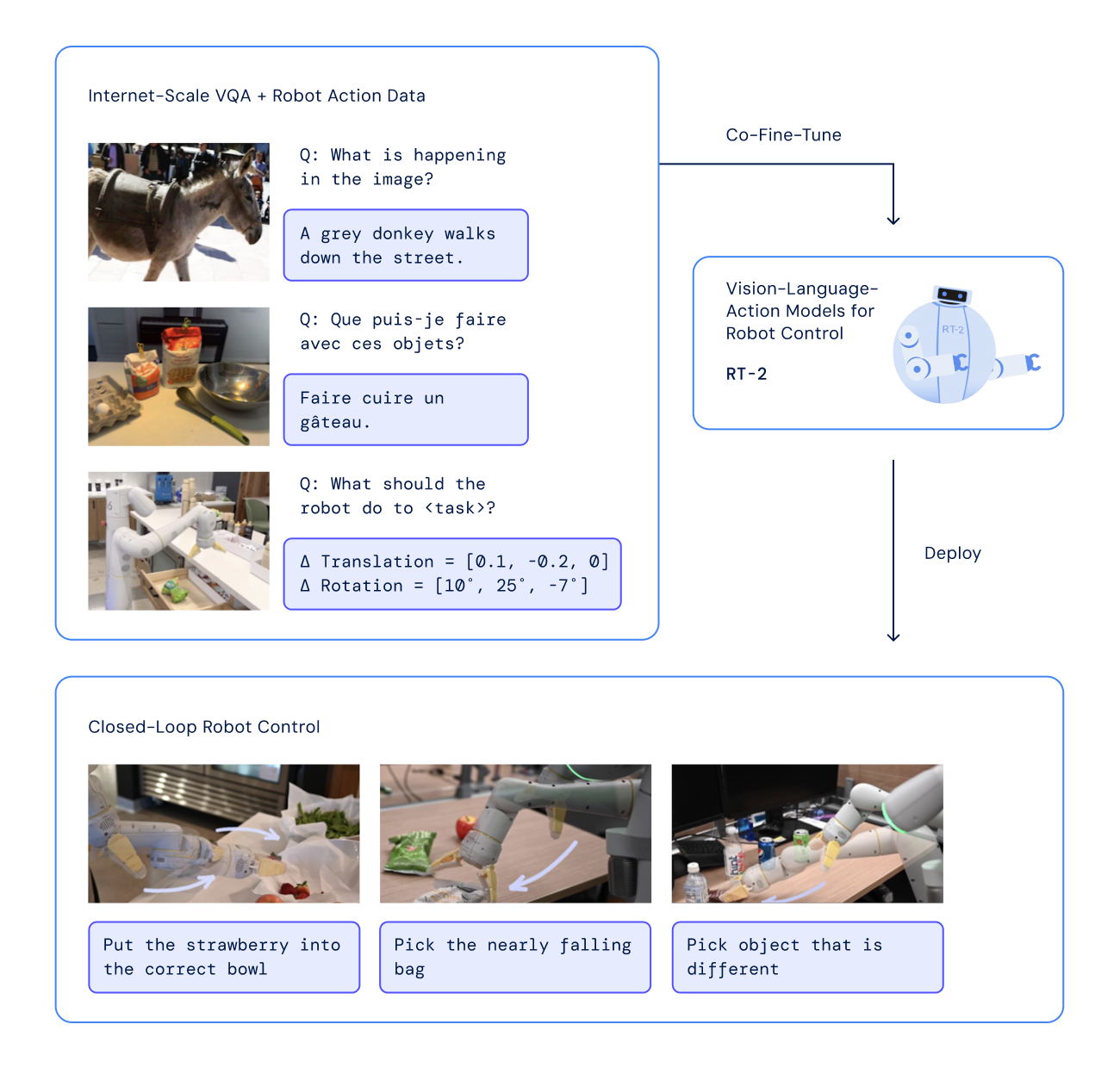
The advent of Generative AI, has fundamentally transformed robotic intelligence, enabling significant strides in how advanced humanoid robots “perceive, reason and act” in the physical world. This huge progress is primarily attributed in terms of decision making, thanks to LLM and VLMs generalization due to their large scale pre-training. Instead of relying on traditional complex policies which has to be carefully handcrafted for individual low level tasks for fine grained actions, VLA allows robotic control combining vision and language knowledge for better reasoning.
Embodied AI refers to the intelligent systems (VLM) integrated into physical entities, mainly robots. Similar to how humans learn from their experiences, surroundings and environments that they are exposed to, embodied AI learns through their interactions and from visual cues of a observed scene enabling them to handle dynamic scenarios effectively in real-world mirroring the human brain.

As of Apr 2025, the SOTA Vision Language Action Models (VLA’s ) employ either a dual level expert systems, combining a VLM and a diffusion decoders notably Nvidia Groot N1 and FigureAI’s Helix or foundational generalist policy like in π0 (Pi-Zero) by Physical Intelligence.
- System 2 (“thinking slow“): Here, the Vision Language Model (VLM) takes in vision and text as context, to make methodological decision about complex scenarios and intermediate tasks it sees. This guides the overall robot’s behavior because of their excellent understanding about the robot’s world. They acts as high level planner to achieve their main goals by dividing into multiple intermediate subtasks and reason over the multi-modal inputs and generate trajectories.
- System 1 (“thinking fast“): Then a transformer decoder or a diffusion model acts as an action expert for low level control and dexterous locomotion. We knew that diffusion models has rich image priors, the system leverages its superior semantic scene relationships which translates and executes the system 1’s guided path or instructions to perform agile and fine-grained motor actions.
Together these systems mimic the dual process theory by Daniel Kahneman combining high level planner with low-level rapid execution.

In this article, we will go in-depth discussing how VLAs have evolved post GPT era with compelling policy demo’s using LeRobot framework.
- What are Policies in Robots?
- Why we need VLA?
- RT-2 from Google
- Octo from UC Berkeley
- OpenVLA from Stanford
- QUAR-VLA: Quadruped Robots from MiLAB
- ALOHA from Google Deepmind
- π0: Physical Intelligence
- Helix by Figure AI
- GR00T N1 from Nvidia
- Gemini Robotics
- Conclusion
- References
This is seventh article in our series of blogs on Robotics. Be sure to check out other articles
- Introduction to Robotics: A Beginners Guide
- Introduction to ROS 2 (Robot Operating System 2)
- ROS 2 and Carla Setup Guide for Ubuntu 22.04
- Building Autonomous Vehicle in Carla: Path Following with PID Control & ROS 2
- Understanding Visual SLAM for Robotics Perception
- Introduction to LiDAR SLAM: LOAM and LeGO-LOAM : ROS 2 Implementation
What are Policies in Robots?
In robotics, policies are set of rules that guides a robot’s action in a given environment based on current state to achieve a target objective.
Majorly there are two types of policies:
- Deterministic: Maps specific action to each state of the environment.
- Stochastic: For each state, probability distribution over all possible actions.
The robot may go through a single episode or multiple depending upon its final goal to be achieved. An episode refers to a sequence of interactions of a robotic agent with its surrounding from initial state to the terminal state. This involves a series of steps such as
- State (s)
- Action (a)
- Reward (r)
- Next State (s’).
These agents are usually trained with reinforcement learning methods given an start and end point by maximizing the reward over time in a episode. By this the model learns optimal behavior from trial and errors.
These robotic policies exhibit behavioral cloning or imitation learning where, given the trajectories of observation and action pairs, the goal is to train mode that predict correct actions.
Traditionally, individual policies or complex heuristics are created for each low level tasks and for specific robotic hardware configuration. But real world data is complex and training plethora of these policies are costly, time consuming and requires lot of data. What if we could leverage LLMs and make systems that can generalize across dynamic scenarios? This means robots can see their surroundings, understand spoken or written instructions, and perform real-world tasks independently exhibiting generalization.
Generalist Robot Policies (GRP)
A generalist policy in robotics refers to a single, unified model capable of solving multiple downstream tasks or adapt to new tasks without task specific fine-tuning. Unlike traditional policies which has to be trained for multiple subtasks or for specific platforms or hardware, a generalist policy as the name suggests the model develops emergent behaviors to generalize across unseen tasks, novel scenarios or even in any hardware setups. For example, models like RT-2, π0 (Pi-Zero) and Groot N1. These GRP aren’t just stuck up with the pre-programmed or hard coded instructions rather self explore and navigate through tasks or problems with intermediate goals with their “Observe Understand and Action” nature.
Why we need VLA?
Though LLM performs great for text-based tasks, but they lack or limited by their understanding about physical constraints of environments in which robots operate upon. Also they generate infeasible subgoals because text alone cannot fully explain the end desired goal and a LLM doesn’t always describe delicate low level behaviors. However image or video can create fine-grained policies and behaviors.
“An image is worth 1000 words”
– Fred R. Barnard
Vision Language Model has excellent generalization as they were trained on large multi-modal datasets of images and videos. For effective robotic control and manipulation having just VLM representations is not enough, action data matters. VLA extends VLM with an additional action and observation state tokens.
State: It is a single token and represents robots observations such as sensor values, gripper positions and angles etc.
Action: This token represent the sequence of motor commands to be performed to follow along the trajectory with precise control.
The term VLA was first coined in Google RT-2 paper which uses PaLI-X and PaLM-E to act as backbones which transforms “Pixels to Actions“.
Types of VLAs:
Type-1: Use VLM/LLM as a high level planner and low level controls are handled by individual policies eg: SayCan, PaLM-EType-2: Uses an Image or Video Generation model as a high level planner eg: Berkeley’s SuSIEType-3: Hybrid approach combining both Type-1 and Type-2 to plan about intermediate tasks.
eg: HybridVLAType-4: Use a single VLM for end-to-end control for perception, planning and controlType-5: VLM’s for high level planning and diffusion models to execute these instructions
eg: Groot N1 , Octo


1. RT-2 from Google
Robotic Transformer (RT-2) is a closed source, novel vision language action model developed by Google Deepmind Robotics team. The model doesn’t just memorize-it understands the context and employs a chain of thought reasoning enabling it to adapt learned concepts to new situations.
It comprises pretrained PaLI-X (55B) as vision model and PaLM-E (12B) embodied models as backbones, co-trained with vision data and upweighted robotics action data. It takes in a robot’s camera input (image) and an NLP query, and outputs discrete action tokens, which are then detokenized to generate code-based instructions that can control a robot similar to text responses from an LLM.
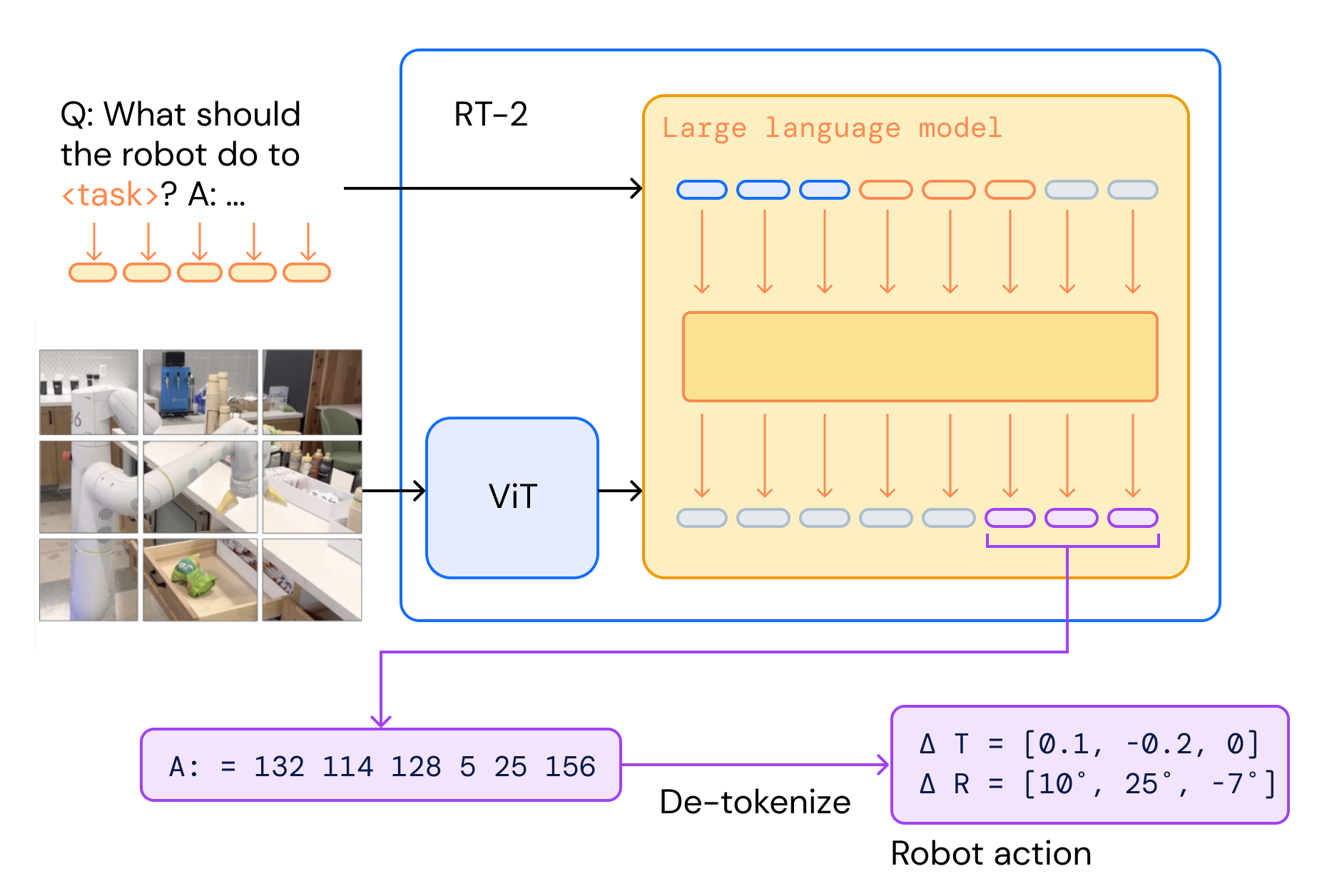
The output is a sequence of action tokens as a string that describe the position and orientation of the robot’s end effector for manipulation, forming a closed loop control.

It was found that the model learned emergent properties, solving novel tasks that the model wasn’t trained for such as human recognition, symbol understanding and reasoning. This level of generalization capabilities was the first of its kind all thanks to its training with web scale data. As the model directly executes actionable behavior, while getting rid of task-specific policies. This was a major breakthrough in the field of Embodied AI.

2. Octo from UC Berkeley
Octo (93M) is an open source transformer based generalist policy trained on 800,000 robot demonstrations from OpenX-Embodiment Dataset and it performs on par with behemoth models like RT-2 (55B). All of the robotic data is taken, converted into a sequence of input tokens, and passed through the Octo transformer.

At first the input instructions are passed as task tokens to the language encoder, along with a patched image passed to a CNN encoder as observation tokens. Then, the embeddings of the Octo transformer are decoded to output action tokens using a diffusion head. The authors report that, unlike discrete action tokens, diffusion based decoders works best.
A unique attribute of Octo is its flexible and adaptable to different observation input such as wrist and third-person camera view.To adapt Octo to our robot configuration or action spaces, we will need to simply finetune it on a small demonstration dataset.
Octo has three variants:
- Octo-Tiny
- Octo-Small
- Octo-Base (~93M)
The original example notebook for inference has quite a lot errors to work and breaking, we have fixed it to work without any issues. To access the updated notebook hit the download code button.

Code Walkthrough of Octo Inference
# Download repo
!git clone https://github.com/octo-models/octo.git
%cd octo
# Install repo
!pip3 install -e .
!pip3 install -r requirements.txt
# Fix: https://docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.linalg.tril.html
!pip install scipy==1.11.0
# Fix: jaxlib and jax version mismatch
# !pip install jaxlib==0.4.20
Loading pre-trained checkpoint from Hugging Face
from octo.model.octo_model import OctoModel
model = OctoModel.load_pretrained("hf://rail-berkeley/octo-small")
print(model.get_pretty_spec())
This model is trained with a window size of 2, predicting 7 dimensional actions 4 steps into the future.
Observations and tasks conform to the following spec:
Observations: {
image_primary: ('batch', 'history_window', 256, 256, 3),
image_wrist: ('batch', 'history_window', 128, 128, 3),
}
Tasks: {
image_primary: ('batch', 256, 256, 3),
image_wrist: ('batch', 128, 128, 3),
language_instruction: {
attention_mask: ('batch', 16),
input_ids: ('batch', 16),
},
}
At inference, you may pass in any subset of these observation and task keys, with a history window up to 2 timesteps.
Load Dataset
Next, we will load a trajectory from the bridge dataset for testing the model. This uses the Open X-Embodiment dataset.
# create RLDS dataset builder
builder = tfds.builder_from_directory(builder_dir='gs://gresearch/robotics/bridge/0.1.0/')
ds = builder.as_dataset(split='train[:1]')
# sample episode + resize to 256x256 (default third-person cam resolution)
episode = next(iter(ds))
print(episode)
steps = list(episode['steps'])
images = [cv2.resize(np.array(step['observation']['image']), (256, 256)) for step in steps]
# extract goal image & language instruction
goal_image = images[-1]
language_instruction = steps[0]['observation']['natural_language_instruction'].numpy().decode()
# visualize episode
print(f'Instruction: {language_instruction}')
media.show_video(images, fps=10)
"""{'steps': <_VariantDataset element_spec={'action': {'open_gripper': TensorSpec(shape=(), dtype=tf.bool, name=None), 'rotation_delta': TensorSpec(shape=(3,), dtype=tf.float32, name=None), 'terminate_episode': TensorSpec(shape=(), dtype=tf.float32, name=None), 'world_vector': TensorSpec(shape=(3,), dtype=tf.float32, name=None)}, 'is_first': TensorSpec(shape=(), dtype=tf.bool, name=None), 'is_last': TensorSpec(shape=(), dtype=tf.bool, name=None), 'is_terminal': TensorSpec(shape=(), dtype=tf.bool, name=None), 'observation': {'image': TensorSpec(shape=(480, 640, 3), dtype=tf.uint8, name=None), 'natural_language_embedding': TensorSpec(shape=(512,), dtype=tf.float32, name=None), 'natural_language_instruction': TensorSpec(shape=(), dtype=tf.string, name=None), 'state': TensorSpec(shape=(7,), dtype=tf.float32, name=None)}, 'reward': TensorSpec(shape=(), dtype=tf.float32, name=None)}>}
Instruction: Place the can to the left of the pot."""
Run Inference on Full Trajectories
Now, its time to run inference over the images in the episode using the model loaded. For this demo we will provide both goal-conditioned and language conditioned training.
WINDOW_SIZE = 2
# create `task` dict
task = model.create_tasks(goals={"image_primary": goal_image[None]}) # for goal-conditioned
task = model.create_tasks(texts=[language_instruction]) # for language conditioned
# run inference loop, this model only uses single image observations for bridge
# collect predicted and true actions
pred_actions, true_actions = [], []
for step in tqdm.tqdm(range(0, len(images) - WINDOW_SIZE + 1)):
input_images = np.stack(images[step : step + WINDOW_SIZE])[None]
observation = {
'image_primary': input_images,
'timestep_pad_mask': np.array([[True, True]]),
}
# this returns *normalized* actions --> we need to unnormalize using the dataset statistics
norm_actions = model.sample_actions(observation, task, rng=jax.random.PRNGKey(0))
norm_actions = norm_actions[0] # remove batch
actions = (
norm_actions * model.dataset_statistics["bridge_dataset"]['action']['std']
+ model.dataset_statistics["bridge_dataset"]['action']['mean']
)
pred_actions.append(actions)
true_actions.append(np.concatenate(
(
steps[step+1]['action']['world_vector'],
steps[step+1]['action']['rotation_delta'],
np.array(steps[step+1]['action']['open_gripper']).astype(np.float32)[None]
), axis=-1
))
"""
{'image_primary': Traced<ShapedArray(uint8[1,2,256,256,3])>with<DynamicJaxprTrace(level=1/0)>, 'timestep_pad_mask': Traced<ShapedArray(bool[1,2])>with<DynamicJaxprTrace(level=1/0)>}
"""
Visualize predictions and ground-truth actions
Finally, let’s compare the predicted actions to the ground truth actions.
import matplotlib.pyplot as plt
ACTION_DIM_LABELS = ['x', 'y', 'z', 'yaw', 'pitch', 'roll', 'grasp']
# build image strip to show above actions
img_strip = np.concatenate(np.array(images[::3]), axis=1)
# set up plt figure
figure_layout = [
['image'] * len(ACTION_DIM_LABELS),
ACTION_DIM_LABELS
]
plt.rcParams.update({'font.size': 12})
fig, axs = plt.subplot_mosaic(figure_layout)
fig.set_size_inches([45, 10])
# plot actions
pred_actions = np.array(pred_actions).squeeze()
true_actions = np.array(true_actions).squeeze()
for action_dim, action_label in enumerate(ACTION_DIM_LABELS):
# actions have batch, horizon, dim, in this example we just take the first action for simplicity
axs[action_label].plot(pred_actions[:, 0, action_dim], label='predicted action')
axs[action_label].plot(true_actions[:, action_dim], label='ground truth')
axs[action_label].set_title(action_label)
axs[action_label].set_xlabel('Time in one episode')
axs['image'].imshow(img_strip)
axs['image'].set_xlabel('Time in one episode (subsampled)')
plt.legend()

3. OpenVLA from Stanford
OpenVLA is a open source 7B parameter model trained on 970K episodes of Open X-Embodiment dataset for generalist robotic manipulation tasks.
It consists of three main components:
- Vision Encoder: Uses a dual vision encoder approach with DINOv2 (~300M) and SigLIP (~400M) which takes in an image and creates embeds flattened patches. DINOv2 excels at spatial relationships while SigLIP offers strong language alignment properties. To adapt the vision encoders to new tasks like action prediction it is important to unfreeze and train these model layers as well.
- Projector: Vision embeddings are mapped into a shared embedding space of LLM using an MLP projector.
- LLM: Llama2 7B model takes in an language instruction and is tokenized. The vision embeddings and text tokens together is passed as a sequence to LLM to generate actions such as changes in position, rotation and gripper state which can be directly used as continuous signals to control robots end effector.
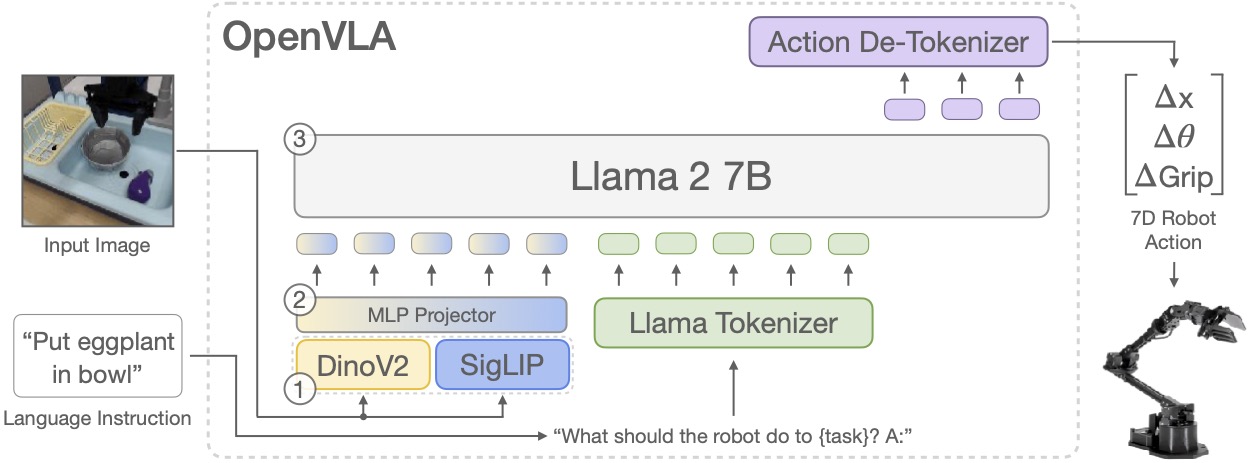
Franka Emika Panda 7-DoF robot arm is used as test bed operating at 5Hz for evaluation and benchmarks. The project also added support for parameter efficient fine-tuning techniques like LoRA and experimental results shows these PEFT models perform on par with the original model.
Interestingly the authors suggest that we can train VLAs just like LLM , via next token prediction with cross entropy loss. All we need is only 255 action tokens to represent entire action space of a robot given the visual observation and language instruction.
Experimental studies shows that OpenVLA outperforms RT-2-X(55B) despite having 7 times fewer parameters. However OpenVLA natively doesn’t perform well on Out of Distribution (unseen) dataset compared to RT-2 as it wasn’t trained on web data unlike RT-2. Therefore fine-tuning on unseen data distribution helps the model to quickly adapt to the novel episodes.
Code Walkthrough of OpenVLA
!git clone https://github.com/openvla/openvla.git
%cd openvla
!pip install -e .
!pip install packaging ninja
!ninja --version; echo $? # Verify Ninja --> should return exit code "0"
!pip install -r https://raw.githubusercontent.com/openvla/openvla/main/requirements-min.txt
# Install minimal dependencies (`torch`, `transformers`, `timm`, `tokenizers`, ...)
# > pip install -r https://raw.githubusercontent.com/openvla/openvla/main/requirements-min.txt
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
import torch
# Load Processor & VLA
processor = AutoProcessor.from_pretrained("openvla/openvla-7b", trust_remote_code=True)
vla = AutoModelForVision2Seq.from_pretrained(
"openvla/openvla-7b",
# attn_implementation="flash_attention_2", # [Optional] Requires `flash_attn`
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to("cuda:0")
# Grab image input & format prompt
image: Image.Image = get_from_camera(...)
prompt = "In: What action should the robot take to {<INSTRUCTION>}?\nOut:"
# Predict Action (7-DoF; un-normalize for BridgeData V2)
inputs = processor(prompt, image).to("cuda:0", dtype=torch.bfloat16)
action = vla.predict_action(**inputs, unnorm_key="bridge_orig", do_sample=False)
# Execute...
robot.act(action, ...)
4. QUAR-VLA: Quadruped Robots from MiLAB
QUAR-VLA, Vision Language Action Model for Quadruped Robots mainly targets four-legged robots to navigate complex terrains and perform various tasks. Legged robots require complex coordination of multiple joints and gait management which is efficiently handled using QUAR-VLA.
QUAR-VLA is trained on dataset containing navigation, locomotion on complex terrain including both real-world and synthetic data.
QUART-2 takes in a set of observation images and language instruction from user. These instructions are tokenized as concatenated and is passed to the pretrained VLM to generate discrete action tokens at 2Hz. The output discretizes the continuous action space of quadruped robots into 255 bins for effective learning and execution.

5. ALOHA from Google Deepmind
ALOHA (A Low-cost Open-source Hardware System for Bimanual Teleoperation) is developed to advance the research of robotic teleoperation at an affordable cost around $20,000. The ALOHA team have completely open sourced the hardware designs, 3D printing instructions etc. for any individual to build their own inhouse replica. It is basically an hardware platform for robotic manipulation tasks using an teleoperation (humans) and the original ALOHA doesn’t have any VLA integrated natively.


However, the research communities used ALOHA as test bed to benchmark and evaluate their VLA models for bimanual manipulation tasks, especially Mobile ALOHA, OpenVLA-OFT, π0, RDT-1B etc.
6. π0: Physical Intelligence
π is a foundational Vision-Language-Action Flow Model for general robot control from Physical Intelligence with two variants π0 (Pi-Zero) and π0 Fast. It comprises of a ~3B pretrained Paligemma VLM model as base backbone and an additional 300M diffusion model as an action expert trained on π Cross-Embodiment Robot dataset. VLAs has additional action and state tokens appended at the end of image and text tokens. The model is pretrained with massive, diverse dataset and

VLM: The VLM uses SigLIP as image encoder an Gemma for language commands. The VLM doesn’t see the future robot state/actions tokens preventing the model from any sort of confusion to interpret visual information from its pre-trained knowledge. By adapting this VLM to also act an action expert is added which tightly works with VLM.
Action Expert: The action expert attends to all the previous vision/language/robot state tokens which represents the full scene to produce context-conditioned actions. Instead of just one action (discrete) token, it generates continuous sequences of action tokens (H = 50) by using conditional flow matching for smooth and realistic movements.
Actions are n-dimensional vectors action representation(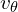 ) with magnitude and direction that can be tokenized. Similar to image generation diffusion models, Flow matching starts from a random noise (
) with magnitude and direction that can be tokenized. Similar to image generation diffusion models, Flow matching starts from a random noise (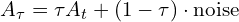 ) and converges to a sequence of meaningful motor actions (that’s close to Target:
) and converges to a sequence of meaningful motor actions (that’s close to Target: 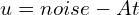 ) iteratively to produce smooth motor actions for dexterous hand movements to fit the observation.
) iteratively to produce smooth motor actions for dexterous hand movements to fit the observation.
New_Action = Old_Action + step_size *
Most existing VLAs use discrete action tokenization, converting continuous actions into discrete tokens generated autoregressively. But they have are inefficient for high-frequency real-time controls such as in π0 at 50Hz. This enables robots to perform a diverse range of tasks with higher efficiency and adaptability.
π0-FAST an extension of π0 which works in autoregressive manner unlike π0, with Frequency-space Action Sequence Tokenization (FAST) introduces a novel time-series compression approach using the Discrete Cosine Transform (DCT). FAST reduces redundancy, improves efficiency, and enhances action fidelity.

Continuous action tokens using DCT is transformed from time domain to frequency domain. The resulting sparse matrix contains a list of low and high frequency coefficients and is flattened where low-frequency are slow and smooth changes whereas high-frequency components are fast and abrupt changes. For realworld scenes, we mostly need the low frequency components containing meaningful information whereas high frequency can be ignored or compressed further.
In benchmarks, even the smaller variant of π0, outperforms existing VLAs by a huge margin in easy to hard tasks.

Code Walkthrough of π0
Clone the LeRobot repository and install dependencies related to pi0.
!git clone https://github.com/huggingface/lerobot.git
%cd lerobot
!pip install -e .
!pip install -e ".[pi0]"
!pip install -e ".[aloha, pusht]"
We will need to login with Hugging Face to access PaliGemma as its a gated repository.
!huggingface-cli login
Inference
from lerobot.common.policies.pi0.modeling_pi0 import PI0Policy
policy = PI0Policy.from_pretrained("lerobot/pi0")
Evaluating pi0 pretrained model on pusht or aloha ,
!python lerobot/scripts/eval.py \
--policy.path=lerobot/pi0 \
--env.type=pusht \
--eval.batch_size=10 \
--eval.n_episodes=10
"""
{'env': {'episode_length': 300,
'features': {'action': {'shape': (2,),
'type': <FeatureType.ACTION: 'ACTION'>},
'agent_pos': {'shape': (2,),
'type': <FeatureType.STATE: 'STATE'>},
'pixels': {'shape': (384, 384, 3),
'type': <FeatureType.VISUAL: 'VISUAL'>}},
'features_map': {'action': 'action',
'agent_pos': 'observation.state',
'environment_state': 'observation.environment_state',
'pixels': 'observation.image'},
'fps': 10,
'obs_type': 'pixels_agent_pos',
'render_mode': 'rgb_array',
'task': 'PushT-v0',
'visualization_height': 384,
'visualization_width': 384},
'eval': {'batch_size': 1, 'n_episodes': 1, 'use_async_envs': False},
'job_name': 'pusht_pi0',
'output_dir': PosixPath('outputs/eval/2025-04-10/18-27-10_pusht_pi0'),
'policy': {'adapt_to_pi_aloha': False,
'attention_implementation': 'eager',
'chunk_size': 50,
'device': 'cuda',
'empty_cameras': 0,
'freeze_vision_encoder': True,
'input_features': {},
'max_action_dim': 32,
'max_state_dim': 32,
'n_action_steps': 50,
'n_obs_steps': 1,
'normalization_mapping': {'ACTION': <NormalizationMode.MEAN_STD: 'MEAN_STD'>,
'STATE': <NormalizationMode.MEAN_STD: 'MEAN_STD'>,
'VISUAL': <NormalizationMode.IDENTITY: 'IDENTITY'>},
'num_steps': 10,
'optimizer_betas': (0.9, 0.95),
'optimizer_eps': 1e-08,
'optimizer_lr': 2.5e-05,
'optimizer_weight_decay': 1e-10,
'output_features': {},
'proj_width': 1024,
'resize_imgs_with_padding': (224, 224),
'scheduler_decay_lr': 2.5e-06,
'scheduler_decay_steps': 30000,
'scheduler_warmup_steps': 1000,
'tokenizer_max_length': 48,
'train_expert_only': False,
'train_state_proj': True,
'use_amp': False,
'use_cache': True,
'use_delta_joint_actions_aloha': False},
'seed': 1000}"""
Fine-tuning on custom dataset,
!python lerobot/scripts/train.py \
--policy.path=lerobot/pi0 \
--dataset.repo_id=danaaubakirova/koch_test
7. Helix by Figure AI
Helix is a closed source generalist VLA model for Humanoid Control developed by FigureAI trained on ~500 hours of high-quality, multi-robot dataset in supervised fashion. It proposes a first-of-its-kind decoupled dual system architecture similar to open source Groot N1 with System-2 manages high level planning and System-1 for handling high frequency low level tasks.
While Helix doesn’t have any publicly available research paper, FigureAI’s announcement blog post gives us an idea about how helix is integrated into Figure F02 Humanoid Robot. As F02 has Human bi pedal form factor which naturally allows the robot to open doors, use tools, climb stairs and lift boxes.
Initially Figure Robots were powered by GPT-4o however, running such a large model isn’t a feasible option, so the team decided to end partnership with OpenAI and came up their own inhouse VLA model.
One neural network: Unlike prior approaches, Helix uses a single set of neural network weights to learn all behaviors—picking and placing items, using drawers and refrigerators, and cross-robot interaction—without any task-specific fine-tuning.
From Helix Announcement Post
“””The system comprises two main component namely, S2, a VLM backbone, and S1, a latent-conditional visuomotor transformer. S1 is fast model operating at 200Hz capable of quickly adapting to real-time actions of partner robot, whereas S2 is a slower thinking model that process visual cues and semantic objectuves of a scene.
- S2 is built on a 7B-parameter open-source, open-weight VLM pretrained on internet-scale data. It processes monocular robot images and robot state information (consisting of wrist pose and finger positions) after projecting them into vision-language embedding space. Combined with natural language commands specifying desired behaviors, S2 distills all semantic task-relevant information into a single continuous latent vector, passed to S1 to condition its low-level actions.
- S1, an 80M parameter cross-attention encoder-decoder transformer, handles low-level control. It relies on a fully convolutional, multi-scale vision backbone for visual processing, initialized from pretraining done entirely in simulation. While S1 receives the same image and state inputs as S2, it processes them at a higher frequency to enable more responsive closed-loop control. The latent vector from S2 is projected into S1’s token space and concatenated with visual features from S1’s vision backbone along the sequence dimension, providing task conditioning. “””
Helix is trained in a manner that it maps raw-pixels of the visual scene and text commands to produce continuous actions with a standard regression loss.
Highlights of Helix:
- Advanced VLA models like Helix allows multiple robots to work collaboratively and seamless real time coordination with precise dexterous actions compare to any other prior VLA models.
- Helix is the first VLA model capable of controling the entire humanoid’s upper body including head gaze, wrists, torso posture and individual fingers at high rate.
- Helix performs exceptionally well even for out bound scenarios with any task specific fine-tuning.
- It runs entirely onboard consuming less power and is commercially deployed at factories like BMW.
8. GR00T N1 from Nvidia
Following the same architectural and design principles of Helix, Nvidia released GR00T N1, an open foundational model for generalist humanoid reasoning and control. N1 is a 2B parameter model (eagle2_hg_model backbone) trained on massive set of both synthetic from Omniverse and Cosmos along with real captured data of humanoid robot dataset. Pretrained policies can be seamlessly adapted to cross embodied systems.
Observation, language instruction and robot state are encoded as tokens and is passed to System 2 and System 1 to predict action tokens that can directly control the robots.
System 2: VLM that interprets phsical world with vision and language instructions by reasoning over to plan the right actions.
System 1: A Diffusion Transformer that follows the instructions of System 2 by denoising to produce meaningful smooth and precise motor actions at 120Hz.

Code Walkthrough of GR00T N1 Inference
To get started, clone the repository and install the necessary dependencies
git clone https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T
conda create -n gr00t python=3.10
conda activate gr00t
pip install --upgrade setuptools
pip install -e .
pip install --no-build-isolation flash-attn==2.7.1.post4
Load the nvidia/GR00T-N1-2B model to GPU.
import os
import torch
import gr00t
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.model.policy import Gr00tPolicy
# change the following paths
MODEL_PATH = "nvidia/GR00T-N1-2B"
# REPO_PATH is the path of the pip install gr00t repo and one level up
REPO_PATH = os.path.dirname(os.path.dirname(gr00t.__file__))
DATASET_PATH = os.path.join(REPO_PATH, "demo_data/robot_sim.PickNPlace")
EMBODIMENT_TAG = "gr1"
device = "cuda" if torch.cuda.is_available() else "cpu"
Load the pretrained policy for gr1_arms_only configuration with gr embodiment.
from gr00t.experiment.data_config import DATA_CONFIG_MAP
data_config = DATA_CONFIG_MAP["gr1_arms_only"]
modality_config = data_config.modality_config()
modality_transform = data_config.transform()
policy = Gr00tPolicy(
model_path=MODEL_PATH,
embodiment_tag=EMBODIMENT_TAG,
modality_config=modality_config,
modality_transform=modality_transform,
device=device,
)
# print out the policy model architecture
print(policy.model)
GR00T_N1(
(backbone): EagleBackbone(
(model): Eagle2ChatModel(
(vision_model): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipFlashAttention2(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(head): Identity()
)
)
(language_model): LlamaForCausalLM(
(model): LlamaModel(
(embed_tokens): Embedding(49164, 2048, padding_idx=2)
(layers): ModuleList(
(0-11): 12 x LlamaDecoderLayer(
(self_attn): LlamaFlashAttention2(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=2048, bias=False)
(v_proj): Linear(in_features=2048, out_features=2048, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): LlamaMLP(
(gate_proj): Linear(in_features=2048, out_features=8192, bias=False)
(up_proj): Linear(in_features=2048, out_features=8192, bias=False)
(down_proj): Linear(in_features=8192, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): LlamaRMSNorm((2048,), eps=1e-05)
(post_attention_layernorm): LlamaRMSNorm((2048,), eps=1e-05)
)
)
(norm): LlamaRMSNorm((2048,), eps=1e-05)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Identity()
)
(mlp1): Sequential(
(0): LayerNorm((4608,), eps=1e-05, elementwise_affine=True)
(1): Linear(in_features=4608, out_features=2048, bias=True)
(2): GELU(approximate='none')
(3): Linear(in_features=2048, out_features=2048, bias=True)
)
)
(linear): Linear(in_features=2048, out_features=1536, bias=True)
)
(action_head): FlowmatchingActionHead(
(model): DiT(
(timestep_encoder): TimestepEncoder(
(time_proj): Timesteps()
(timestep_embedder): TimestepEmbedding(
(linear_1): Linear(in_features=256, out_features=1536, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=1536, out_features=1536, bias=True)
)
)
(transformer_blocks): ModuleList(
(0-15): 16 x BasicTransformerBlock(
(norm1): AdaLayerNorm(
(silu): SiLU()
(linear): Linear(in_features=1536, out_features=3072, bias=True)
(norm): LayerNorm((1536,), eps=1e-05, elementwise_affine=False)
)
(attn1): Attention(
(to_q): Linear(in_features=1536, out_features=1536, bias=True)
(to_k): Linear(in_features=1536, out_features=1536, bias=True)
(to_v): Linear(in_features=1536, out_features=1536, bias=True)
(to_out): ModuleList(
(0): Linear(in_features=1536, out_features=1536, bias=True)
(1): Dropout(p=0.2, inplace=False)
)
)
(norm3): LayerNorm((1536,), eps=1e-05, elementwise_affine=False)
(ff): FeedForward(
(net): ModuleList(
(0): GELU(
(proj): Linear(in_features=1536, out_features=6144, bias=True)
)
(1): Dropout(p=0.2, inplace=False)
(2): Linear(in_features=6144, out_features=1536, bias=True)
(3): Dropout(p=0.2, inplace=False)
)
)
(final_dropout): Dropout(p=0.2, inplace=False)
)
)
(norm_out): LayerNorm((1536,), eps=1e-06, elementwise_affine=False)
(proj_out_1): Linear(in_features=1536, out_features=3072, bias=True)
(proj_out_2): Linear(in_features=1536, out_features=1024, bias=True)
)
(state_encoder): CategorySpecificMLP(
(layer1): CategorySpecificLinear()
(layer2): CategorySpecificLinear()
)
(action_encoder): MultiEmbodimentActionEncoder(
(W1): CategorySpecificLinear()
(W2): CategorySpecificLinear()
(W3): CategorySpecificLinear()
(pos_encoding): SinusoidalPositionalEncoding()
)
(action_decoder): CategorySpecificMLP(
(layer1): CategorySpecificLinear()
(layer2): CategorySpecificLinear()
)
(position_embedding): Embedding(1024, 1536)
)
)
import numpy as np
modality_config = policy.modality_config
print(modality_config.keys())
for key, value in modality_config.items():
if isinstance(value, np.ndarray):
print(key, value.shape)
else:
print(key, value)
"""
dict_keys(['video', 'state', 'action', 'language'])
video delta_indices=[0] modality_keys=['video.ego_view']
state delta_indices=[0] modality_keys=['state.left_arm', 'state.right_arm', 'state.left_hand', 'state.right_hand']
action delta_indices=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15] modality_keys=['action.left_arm', 'action.right_arm', 'action.left_hand', 'action.right_hand']
language delta_indices=[0] modality_keys=['annotation.human.action.task_description']
"""
Load the dataset in LeRobot compatible data schema
# Create the dataset
dataset = LeRobotSingleDataset(
dataset_path=DATASET_PATH,
modality_configs=modality_config,
video_backend="decord",
video_backend_kwargs=None,
transforms=None, # We'll handle transforms separately through the policy
embodiment_tag=EMBODIMENT_TAG,
)
"""Initialized dataset robot_sim.PickNPlace with gr1
"""
import numpy as np
step_data = dataset[0]
print(step_data)
print("\n\n ====================================")
for key, value in step_data.items():
if isinstance(value, np.ndarray):
print(key, value.shape)
else:
print(key, value)
"""
# step_data.items():
video.ego_view (1, 256, 256, 3)
state.left_arm (1, 7)
state.right_arm (1, 7)
state.left_hand (1, 6)
state.right_hand (1, 6)
action.left_arm (16, 7)
action.right_arm (16, 7)
action.left_hand (16, 6)
action.right_hand (16, 6)
annotation.human.action.task_description ['pick the squash from the counter and place it in the plate']
"""
import matplotlib.pyplot as plt
traj_id = 0
max_steps = 150
state_joints_across_time = []
gt_action_joints_across_time = []
images = []
sample_images = 6
for step_count in range(max_steps):
data_point = dataset.get_step_data(traj_id, step_count)
state_joints = data_point["state.right_arm"][0]
gt_action_joints = data_point["action.right_arm"][0]
state_joints_across_time.append(state_joints)
gt_action_joints_across_time.append(gt_action_joints)
# We can also get the image data
if step_count % (max_steps // sample_images) == 0:
image = data_point["video.ego_view"][0]
images.append(image)
# Size is (max_steps, num_joints == 7)
state_joints_across_time = np.array(state_joints_across_time)
gt_action_joints_across_time = np.array(gt_action_joints_across_time)
# Plot the joint angles across time
fig, axes = plt.subplots(nrows=7, ncols=1, figsize=(8, 2*7))
for i, ax in enumerate(axes):
ax.plot(state_joints_across_time[:, i], label="state joints")
ax.plot(gt_action_joints_across_time[:, i], label="gt action joints")
ax.set_title(f"Joint {i}")
ax.legend()
plt.tight_layout()
plt.show()
# Plot the images in a row
fig, axes = plt.subplots(nrows=1, ncols=sample_images, figsize=(16, 4))
for i, ax in enumerate(axes):
ax.imshow(images[i])
ax.axis("off")


predicted_action = policy.get_action(step_data)
for key, value in predicted_action.items():
print(key, value.shape)
"""
action.left_arm (16, 7)
action.right_arm (16, 7)
action.left_hand (16, 6)
action.right_hand (16, 6)
### Understanding the Action Output
Each joint in the action output has a shape of (16, N) where N is the degree of freedom for the joint.
- 16 represents the action horizon (predictions for timesteps t, t+1, t+2, ..., t+15)
For each arm (left and right):
- 7 arm joints:
- Shoulder pitch
- Shoulder roll
- Shoulder yaw
- Elbow pitch
- Wrist yaw
- Wrist roll
- Wrist pitch
For each hand (left and right):
- 6 finger joints:
- Little finger
- Ring finger
- Middle finger
- Index finger
- Thumb rotation
- Thumb bending
For the waist
- 3 joints:
- torso waist yaw
- torso waist pitch
- torso waist roll
"""
9. Gemini Robotics
Google Deepmind introduced Gemini Robotics which is powered by powerful Gemini 2.0 multimodal. This enables to perform high frequency motor control at 20Hz, dexterous tasks and perform complex daily tasks precisely.
The family consists of two primary models:
- Gemini Robotics-ER (Embodied Reasoning): This uses native Gemini 2.0 without fine-tuning on any robot action data. It purely dependent on the superior spatial-relationship and vast internet pretrained knowledge about robot concepts.
- Gemini Robotcs: Extending Gemini Robotics-ER by fine-tuning on action data for direct robot control. Its is a single unified model that handles perception, reasoning and action generation without separate diffusion.
Traditional Approach: Scene Understanding → Task Planning → Motion Planning → Control
Gemini Robotics Approach: Unified Model Handling Perception, Reasoning, and Action

Architecture: For high level reasoning and perception, a distilled version of Gemini Robotics-ER is hosted in cloud. However to compensate for the network latency and generate low-level action sequences an action decoder runs in robot’s onboard computer.
Gemini generalizes well to novel situations and environments

Conclusion
While LLMs help with digital tasks like answering questions or creating content, VLA models take it further. They enable robots to do things like picking up objects, navigating difficult environments, and assisting with household chores. This blend of digital intelligence and physical action makes VLA models far more impactful than LLMs alone. As we move into a robot-integrated world, it’s important to prepare for how these technologies will fit into our daily lives.
VLA are truly game changers where traditional robots have been confined to specialized tasks in structured environments requiring extensive set of policy training for each task. However models trained for GRP has performed exceptionally well on unseen environments and developed emergent properties which is mainly attributed to leveraging VLM for their excellent generalization and diffusion tokenizers for smooth motion.
The future of Robotics looks promising and thriving !
References
1. Pi Zero TL;DR by shreyasgite
2. Awesome VLAs
4 .OpenVLA: LeRobot Research Presentation




