

Video generation models using the diffusion based approach for training are a significant advancement in the domain of Generative AI. Models like SORA and Veo 2 take the idea of creating images and apply them to generating video content, changing how we create and use digital media. They help create videos that show realistic human movements or complex scenes from nature. The technology has made significant strides, starting with the earliest Video Diffusion Models (VDM) and evolving to sophisticated models like Veo 2. This article is designed for those new to video generation but with some understanding of image diffusion models, providing a foundation for how these advanced tools work.

- Diffusion Overview
- From VDM to Veo 2
- Key Takeaways
- Conclusion
- References
Diffusion Overview

Diffusion models generate image, audio, or video from a noise distribution. They have become a hot topic in AI because they can understand the underlying target data distribution using repeated denoising algorithms( as is the case with earliest diffusion paper DDPM).
Training involves two steps: The forward diffusion process involves repeatedly adding noise to the original image until it becomes complete noise. The second process is reverse diffusion, which, as the name suggests, does the opposite of the forward process: repeatedly denoising a noisy image until it represents our original image (before any noise is added).
As we proceed in this article, concepts related to diffusion process will be used, so we recommend you read our previous blog on diffusion models to understand this topic better.
From VDM to Veo 2: Evolution of video generation models
In this section, we will examine the evolution of video generation models, highlighting each model’s significant contributions to the field. By examining these developments, we can appreciate the technical progress and the practical solutions these models provide for improving video quality, resolution, and temporal coherence.
Video Diffusion Models(2022)

Jonathan Ho along with his team at Google, were the first to thoroughly investigate conditional and unconditional video generation using diffusion mechanism in their paper “Video Diffusion Models (VDM),”.
VDM modified the usual diffusion model setup (used in image generation models) to use a specialized 3D U-Net (or sometimes referred to as Video U-Net) instead of the typical 2D U-Net. This change was essential for handling the movement and transition over time in video generation, which we will discuss more in this article.
The team highlighted that diffusion models require multiple upsampling steps to either extend the video length or to enhance the frame rate, crucial for high-quality video generation. This process involves the generation of an extended video sequence that is conditioned on an initial segment:
Mathematically this is expressed as:
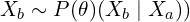
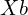 is an autoregressive extension of
is an autoregressive extension of 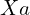 or the missing frames between a video at a low frame rate.
or the missing frames between a video at a low frame rate.
However, the team encountered challenges with this conditional approach. While the frames () generated appeared visually appealing on their own, they often lacked coherence with the preceding frames (), introducing flickering artifacts.
This incoherency issue posed a fundamental problem that the latents are updated in the direction provided by ![\hat{x}_b^\theta(z_t) \approx \mathbb{E}[x_b \mid z_t]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-02963e8780c7a588335633d499746477_l3.png) . At the same time, what is needed instead is
. At the same time, what is needed instead is ![\mathbb{E}[x_b \mid z_t, x_a]](https://learnopencv.com/wp-content/ql-cache/quicklatex.com-5a6e60b8b6a3b7b9e3c90fa92d8d5829_l3.png) .
.
To address this, they introduced a novel reconstruction guidance technique. This method ensures that the sampling of is more effectively conditioned on , enhancing the temporal coherence between the original and generated video segments.
Imagen Video(2022)

Imagen, introduced by Google, is a video generation tool that operates at a resolution of 1280×768 and 24 fps, utilizing an architecture which is composed of eight blocks. These eight blocks comprises of seven diffusion model blocks with a collective 11.6 billion parameters, alongside a frozen text encoder block.
Overview of Imagen’s Architecture:

- Base Model:
- This foundational block produces data at the lowest frame count and spatial resolution.
- It employs temporal attention to maintain consistency across frames and incorporates spatial attention, spatial convolution, and additional temporal attention layers to enhance image quality.

- SSR (Spatial Super Resolution) Model:
- The three SSR blocks are designed to enhance the spatial resolution of all input frames.
- These blocks use the classifier-free guidance (CFG) method for training.
- A bilinear resize upsampling operation is applied prior to concatenating noise data with input data to facilitate CFG.
- The first two SSR blocks incorporate temporal convolution, spatial convolution, and spatial attention layers, while the final SSR block consists solely of fully convolutional layers.
- TSR (Temporal Super Resolution) Model:
- TSR blocks focus on increasing temporal resolution by interpolating additional frames between existing ones.
- Like the SSR blocks, TSR blocks are trained using classifier-free guidance and primarily feature temporal convolution layers.
- T5-XXL:
- This component is a frozen T5 text encoder that generates text embeddings. These embeddings serve as conditioning input, later concatenated with the upsampled input data to perform CFG.
For a more detailed exploration of the Imagen Video model and its capabilities, please visit the link provided below.
Imagen Video
Moving further in our discussion, it is likely that each model we discuss will build upon and refine existing text-to-image (T2I) generation models by incorporating temporal dimensions, extending the limits of AI’s capabilities in video generation.
Make-a-Video(2022)

This video diffusion model leverages the pre-trained T2I (Text-to-Image) diffusion model and disables the need for paired text-video data. In the pioneering paper by Meta, the authors introduced the concept of super-resolution across space and time for the T2I models like Stable Diffusion or Flux.
A central aspect of the Make-a-Video model architecture is the integration of Pseudo-Convolution and Pseudo-Attention Layers, which we will explore in detail.


Pseudo 3D Convolution Layers:
A Pseudo-3D convolution layer combines a 2D convolution layer with a subsequent 1D convolution layer. This approach optimizes the performance by reducing the computational and time complexities associated with traditional 3D convolutions.
Mathematically, it is represented in the following manner:
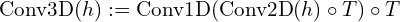
Pseudo-3D Attention Layer:
Similar to the Pseudo-3D Convolution Layer, the Pseudo-3D Attention layer layers a spatial attention mechanism beneath a temporal attention mechanism, effectively approximating a full spatio-temporal attention process.
Mathematically, it is represented in the following manner:
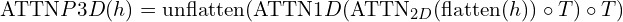
They summarized the final T2V inference scheme in one equation, which is given below:
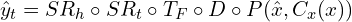
- Generated Video (
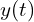 ): Output from the proposed model architecture that involves enhancing spatial and temporal resolution, interpolating frames to smooth motion, and decoding sequences from low to higher resolutions.
): Output from the proposed model architecture that involves enhancing spatial and temporal resolution, interpolating frames to smooth motion, and decoding sequences from low to higher resolutions. - Super-Resolution Networks (
 and
and 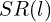 ): Layers performing spatial upsampling using advanced pseudo-3D convolution, ensuring detailed visual output.
): Layers performing spatial upsampling using advanced pseudo-3D convolution, ensuring detailed visual output. - Frame Interpolation (
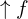 ): This network optimizes frame rate through advanced interpolation, enhancing motion continuity in the video.
): This network optimizes frame rate through advanced interpolation, enhancing motion continuity in the video. - Spatiotemporal Decoder (
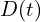 ): A decoder network that generates a sequence of frames from compact initial representations, building the visual sequence block by block.
): A decoder network that generates a sequence of frames from compact initial representations, building the visual sequence block by block. - Prior Model (
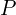 ): This strategy uses textual input to create image contexts, ensuring the video content aligns with textual descriptions.
): This strategy uses textual input to create image contexts, ensuring the video content aligns with textual descriptions. - Text Processing (
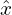 and
and 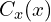 ): Transforms and encodes textual input to synchronize with video content generation.
): Transforms and encodes textual input to synchronize with video content generation.

Figure 8 illustrates the Pseudo Convolution and Pseudo Attention layers used in the Make-a-Video architecture. After initial training on image data, the authors propose adding new temporal layers, initializing them, and subsequently fine-tuning these layers using unlabeled video data.
Video LDM(2023)

In video generation, the Video Latent Diffusion Model (Video LDM) introduces addition of dynamic layers that handle time changes in its architecture. This model builds on the solid foundation of the T2I Latent Diffusion Model (LDM), tweaking it to better handle the specific needs of video content as well as maintaining it’s image generation capabilities. Let’s understand how the Video LDM uses these innovative techniques to improve video quality and make the flow of time in videos smoother.

Encoder-Decoder Architecture of Video LDM
Fig 10, left: During the optimization phase, the core image backbone (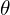 ), taken from T2I image generation model, is held constant, while the parameters (
), taken from T2I image generation model, is held constant, while the parameters (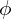 ) of the temporal layers (
) of the temporal layers (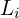 ()) undergo training.
()) undergo training.
Fig 10, right: In the training phase, the base model () processes the input sequence of length T as a batch of individual images. These batches are then reformatted into video sequences for processing by the temporal layers. The outputs from these layers, denoted as z′, are merged with the spatial outputs z using a learned merging parameter (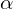 ). During inference, skipping the temporal layers yields the original image generation model.
). During inference, skipping the temporal layers yields the original image generation model.
In practice, two types of temporal mixing layers are implemented: (i) temporal attention and (ii) residual blocks that utilizes 3D convolution function.

A challenge arises from employing the pre-trained T2I LDM model; the decoder, having only been trained on images, tends to produce flickering artifacts when generating temporally coherent video sequences. To address this, additional temporal layers are integrated into the decoder and fine-tuned using video data alongside a patch-wise temporal discriminator constructed from 3D convolutions
It is crucial to note that the encoder remains unchanged, allowing for the reuse of the pre-trained LDM architecture. During the fine-tuning of the temporal decoder, the unaltered encoder processes each video frame independently, ensuring temporally coherent reconstructions across frames with the assistance of a video-aware discriminator.
Stable Video Diffusion (SVD, 2024)

The Stable Video Diffusion paper, authored by the same team behind the Video LDM paper, adopts a similar architectural approach as Video LDM. In their analysis, the authors highlighted two critical conclusions:
- Training Separation Advantage: They demonstrated that separating video model training into distinct stages—video pre training followed by video fine-tuning—significantly benefits the overall performance of the model after the fine-tuning phase.
- Importance of Pre Training Conditions: The conditions under which video pre training occurs are pivotal. Ideally, pretraining should be conducted on a large-scale, well-curated dataset.
“We believe that the significant contribution of data selection is heavily underrepresented in today’s video research landscape despite being well-recognized among practitioners when training video models at scale. Thus, in contrast to previous works, we draw on simple latent video diffusion baselines for which we fix architecture and training scheme and assess the effect of data curation.”
Stable Video Diffusion
Their approach to training a video generation model on large video datasets involves three main stages:
Stage 1: Image Pre Training – The model learns from images, setting a foundation for understanding visual concepts.
Stage 2: Video Pre Training – It starts learning from video data, getting used to the flow and dynamics of moving images.
Stage 3: Video Fine-tuning – The final adjustments that help the model perform well with video data.
Data Curation in Stable Video Diffusion:
The dataset preparation involved the following steps to ensure quality:
- Cut Detection Pipeline: This step helps prevent abrupt cuts and fades from affecting the generated videos.
- Annotation Pipeline: They used three methods to caption the videos, which lead to the creation of Large Video Dataset (LVD), consisting of 580M annotated video clip pairs.
- Additional Annotation: Videos with very low movement, measured by optical flow, are filtered out to maintain dynamic content.
- OCR: To detect clips containing a lot of text and thereby discarding them to focus on visual content.
Their experiments demonstrated that a well-curated, although smaller, dataset could significantly improve the model’s quality, highlighting the importance of the selection process in training effective video models.
Hunyuan video generation model(2024)
“Bridging the gap between closed-source and open-source video foundation models to accelerate community exploration.”
— Hunyuan Foundation Model Team
Let’s begin by outlining the three major sections of their work:
- Data Preprocessing Techniques
- Architectural Overview
- Model Pre-training methods
Data Preprocessing Techniques:
- Data Filtering
- Shot Splitting: Raw videos are first divided into single-shot clips.
- Starting Frame Identification: For each clip, a clear frame is identified to serve as the starting point.
- Embedding Calculation & Deduplication: Embeddings for these clips are computed and used to deduplicate similar clips based on the cosine distance between embeddings.
- Concept Resampling and Balancing: K-means clustering is applied to form approximately 10k concept centroids, which then guide the resampling process to balance the dataset.
- Data Annotation
- In-house Vision-Language Model (VLM): An internally developed VLM generates multi-dimensional descriptive prompts for both images and videos. These prompts are structured in JSON format and include details such as:
- Short description
- Dense description
- Background information
- StyleShot type
- Lighting and atmosphere
- Extended Metadata: The JSON structure is further enriched with metadata which includes tags lik source and quality.
- Camera Movement Annotations: High-confidence predictions on distinct camera movements are also embedded into the captions, enabling the generative model to control camera motion.
- In-house Vision-Language Model (VLM): An internally developed VLM generates multi-dimensional descriptive prompts for both images and videos. These prompts are structured in JSON format and include details such as:
Figure 14 below illustrates the data filtering process used during training.

Architectural Overview
Core Components of the Hunyuan Video Model Architecture:

Causal 3D Variational Autoencoder (VAE)
- Causality: The model processes only past and current tokens while masking future tokens.
- Training from Scratch: Unlike some approaches that use pre-trained VAEs, this model is trained from scratch.
- Compression: The input with shape (T,3,H,W) is compressed to (T/4,16,H/8,W/8)via the encoder part.
- Training Loss Equation:
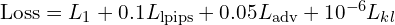
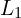 (L1 Loss Function): Pixel-wise accuracy using
(L1 Loss Function): Pixel-wise accuracy using 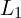 loss.
loss.
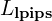 (Perceptual Loss): Perceptual loss that measures differences in high-level feature representations.
(Perceptual Loss): Perceptual loss that measures differences in high-level feature representations.
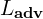 (Adversarial Loss): Adversarial loss encouraging realistic outputs.
(Adversarial Loss): Adversarial loss encouraging realistic outputs.
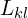 (KL Divergence Loss): KL divergence loss to regularize the latent space.
(KL Divergence Loss): KL divergence loss to regularize the latent space.
- Inference & Tiling: Directly encoding and decoding high-resolution, long videos on a single GPU can lead to memory issues. To address this, a tiling strategy is used during inference. However, since tiling introduces visual artifacts due to training inconsistencies, the model is fine-tuned with a randomly enabled/disabled tiling strategy to maintain compatibility.
Diffusion Transformers (DiT):
- Input Preparation:
The latent outputs from the Causal 3D VAE are patched and unfolded into a 1D sequence of tokens. - Textual Input:
Text is first processed through a Multimodal Large Language Model (MLLM) for fine-grained semantics. CLIP is then used to pool global text representations, which are expanded and combined with timestep embeddings. - Hybrid Design:
A dual-stream block is followed by a single-stream block, capturing complex interactions between visual and textual information. - Positional Encoding:
Rotary Positional Encoding (RoPE) is used to support various resolutions, aspect ratios, and durations.
Text Encoder (MLLM & CLIP):
- The model adopts MLLM over traditional options like T5-XXL for several reasons:
- Better Image-Text Alignment: MLLM achieves improved alignment in feature space.
- Causal Attention: Its causal attention mechanism offers better guidance for latent video diffusion.
- Enhanced Descriptions: MLLM provides richer image details and complex reasoning, complementing CLIP’s global representations.

For those new to AI and enthusiasts alike, I encourage you to download the code file linked in this article. You can start generating your own AI videos by running all the cells in the provided notebook, with no additional configuration needed for your initial tests. As you become more familiar, feel free to experiment with other prompts included in the notebook.

Video generation using Hunyuan Video
To start creating videos similar to the ones showcased above, simply download the code file by clicking the button below. Run all the cells in the notebook as they are—no modifications needed. For your initial experiments, the notebook includes several test prompts that you can use to see how the system performs.
Give them a try and see what amazing videos you can generate
OpenAI Sora(2024)
SORA is a pioneering video diffusion model developed by OpenAI. Limited information is available on its training strategy or architecture, aside from a brief technical report by the development team. This report highlights two main areas: (1) the technique for converting diverse visual data into a unified representation which enables large-scale training of generative models, and (2) a qualitative assessment of SORA’s strengths and weaknesses. However, detailed model specifications and implementation strategies are not disclosed.
Unified Representation for video generation
As can be seen from Fig 18, the training of SORA involves a network that reduces the dimensionality of visual data. This network processes raw video as input and produces a latent representation that is both temporally and spatially compressed. This compressed data is then transformed into spacetime patches, serving as tokens for the Diffusion Transformer (DiT) architecture used as SORA’s primary neural framework for diffusion operations. The specifics of the training workflow, beyond these points, are not elaborated upon in the technical report.

The SORA team has observed that training videos in their native aspect ratios, rather than cropping them to a uniform square format—common in other video generative model training—enhances the composition and framing of the generated content. The comparative visuals below demonstrate the benefits of preserving the original video dimensions:
Fig 19: Result when cropping the input frames
Additionally, the architecture incorporates a highly descriptive captioner model trained to generate textual captions for all videos in the training set, enriching the video content with relevant descriptions
Limitations
Despite its innovative approach, SORA has its constraints as a simulator. For instance, it struggles to accurately model the physics of certain interactions, such as glass shattering, and sometimes fails to represent correct changes in object states during actions like eating. The model also shows inconsistencies in long-duration samples and spontaneous object appearances, highlighting areas for future refinement.
Below is a link to the SORA platform, where you can generate top-notch AI synthetic videos. On SORA, you have the opportunity to build your own library and if your creations stand out, they could be featured in the “Top” section of the platform. This section showcases the best videos generated by users from all around the globe. The platform also offers additional features such as personalized folders and a favorites tab for better organization of your projects.
Get started creating your own videos within minutes and share your results with us here at learnOpenCV in the comment section below. To download the inference script just click on the button given below.
Veo-2(2024)
The latest addition to Google’s video generation technology, the state-of-the-art Veo-2 model, represents a significant advancement over previous models in the Veo lineup. This new model stands out for its exceptional realism and fidelity, along with sophisticated motion capabilities, largely due to its ability to understand physics and its adeptness at following detailed instructions.
In comparative evaluations where human raters assessed the outputs, Veo-2 consistently excelled in overall preference and its precise adherence to prompts, setting a new benchmark in AI-driven video generation as can be seen from the results given in Fig 23.

While Google has not yet released a technical report detailing the Veo-2’s training algorithms, they have launched the VideoFX platform. This platform serves as a creative playground for users to experiment with and generate some of the most lifelike videos achievable with AI to date. However, it’s important to note that access to this platform is currently not available in India.
Let’s explore some examples of Veo-2’s capabilities. Various individuals and major companies across the globe, including Porsche for advertising campaigns, have utilized these generations, showcasing the model’s broad appeal and effectiveness.
Video credit for each video belongs to respective authors.
Key Takeaways
- Technological Evolution: The progression from VDM to OmniHuman-1 illustrates improvements in video quality and resolution and the models’ growing sophistication in handling multi-dimensional data and temporal dynamics.
- Architectural Innovations: Each model introduces novel architectural features, such as 3D U-Nets and cascaded diffusion processes, highlighting the field’s ongoing innovation.
- Broad Applications: Beyond their academic interest, these models have practical implications in various industries, including entertainment, virtual reality, and automated video production, underscoring their broad utility.
- Existing Challenges: Despite their advancements, these models still face significant challenges, such as high computational costs, data inefficiencies, and better temporal coherence in generated videos.
Conclusion
As we look towards the future, video generation models remain a lively research and practical application area. The advancements in this field enhance our ability to generate realistic videos and open new pathways for creative expression and digital interaction. These models are increasingly used in simulations for training and education, in mass media for creating engaging content, and in advertising for eye-catching promotional materials. Each of these applications demonstrates the versatility of video diffusion technology in transforming traditional industries and introducing new possibilities in digital content creation.
References
- Thanks to Lillian Weng for providing such a precise and informative source of information on Video Generation models.
- Also, we thank Joaquin Bengochea for providing a beginner-friendly article on video generation models.
- Sora: A technical report
- Pika AI: Another video generation model. It provides very good results in object inpainting using its latest tool, Pikaddition.
- You can also check out this video on YouTube, which provides Neural Breakdown with AVB, which explains these models in straightforward terms.
Happy Learning 🙂






100K+ Learners
Join Free OpenCV Bootcamp3 Hours of Learning