


Welcome to the last day of Spring GTC 2023. We have been hard at work bringing you the latest announcements and most relevant talks in the field of AI and computer vision. You can find summaries of the first 3 days here:
- Day 1 Highlights: Welcome to the future!
- Day 2 Highlights: Jensen’s keynote & the iPhone moment of AI is here!
- Day 3 Highlights: Digging deeper into Deep Learning, Semiconductors & more!
As a final reminder, if any of these talks interest you, we highly encourage registering for GTC and listening to the presentations.

Here are some of the most interesting talks we found on Day 4.
- Ray Tracing and AI in Unreal Engine [S51851]
- Jetson Orin + Nsight = A match made in heaven [S51230]
- New Features in CUDA C++ [S51225]
- Automated Pipeline Parallelism for PyTorch [S51254]
- SpaceVerse by the US Space Force [S51732]
- Summary
Ray Tracing and AI in Unreal Engine [S51851]
This was a talk for game developers and 3D artists. Unreal Engine is a very popular game development engine. Recently, Unreal is also being adopted by the Robotics community for developing high visual fidelity simulators, beyond what ROS and Gazebo can do. The presenters introduced a new technology called RTXDI or RTX Direct Illumination. This is a technology based on the ReSTIR algorithm developed by NVIDIA researchers in collaboration with Dartmouth College.
RTXDI allows 3D artists to create scenes with thousands of light sources, like a night scene of a ferris wheel with LED strips all across its perimeter. The showcase involved a demo of rendering 4700 different animated light sources with shadows cast by every single source. All of this was rendering on an RTX GPU at 23 FPS, which is quite impressive for a consumer GPU. An interesting feature of RTXDI is that the performance penalty in using it is almost constant no matter the number of light sources. So, once you have budgeted for the performance hit, you can add as many light sources as you want.
RTXDI is available for developers to use via the NvRTX branch for Unreal Engine. Although this particular talk is designed for game developers, we expect the RTXDI technology to help rendering in Omniverse and Isaac Sim. This could improve the visual fidelity of robotics simulations and allow ML engineers to synthesize higher quality data for ML model training.
Jetson Orin + Nsight = A match made in heaven [S51230]
We have introduced the latest Jetson products from NVIDIA in our earlier posts and how the Jetson Orin boards have redefined the compute budget for edge AI applications. In this talk, Sebastien Domino from NVIDIA gave a great overview of the entire architecture of the Orin SoC.
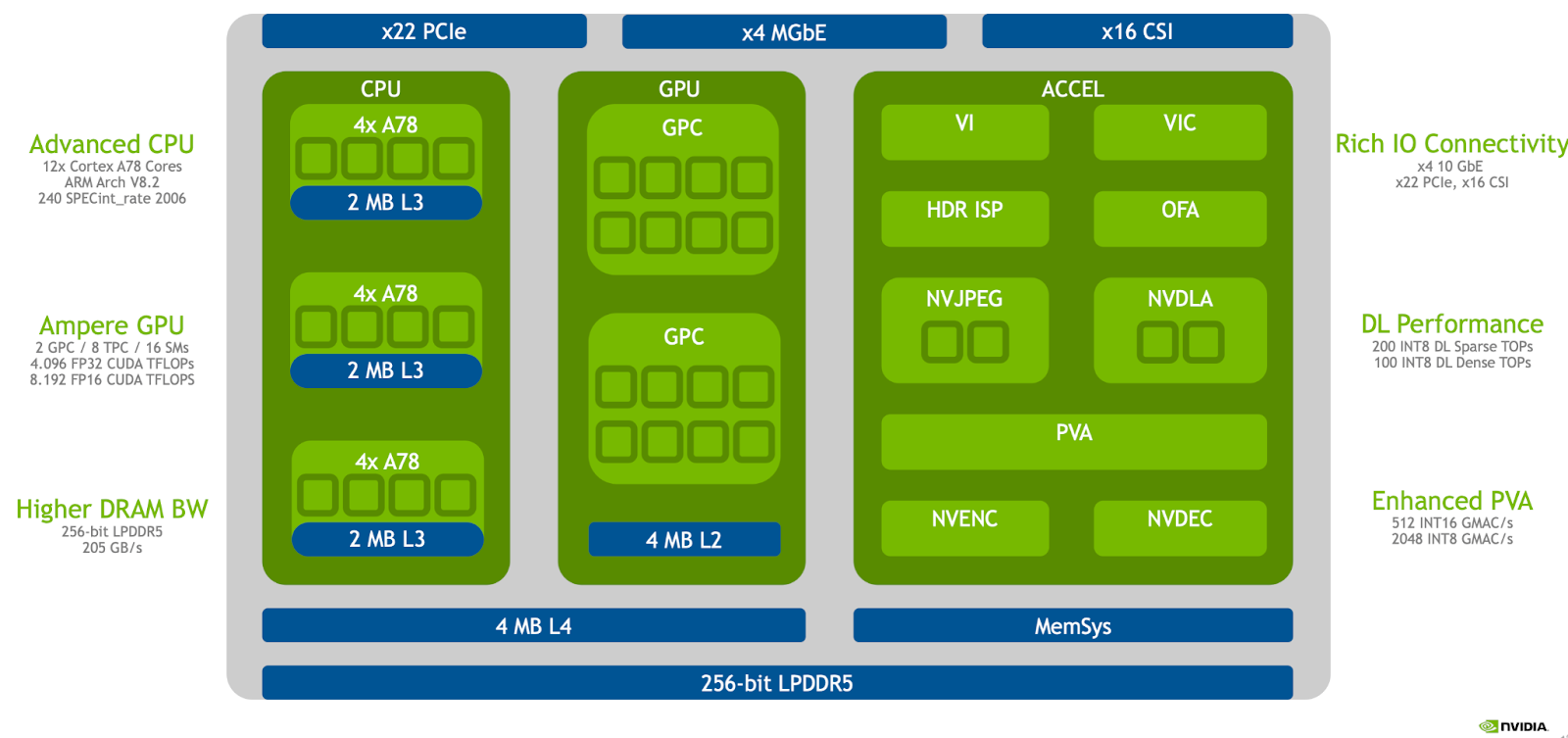
The full SoC (Jetson Orin AGX) consists of
- 3 clusters of 4xA78 CPU cores
- Ampere generation GPU with 2 Graphics Processing Clusters (GPCs). The GPCs contain 8 Texture Processing Clusters and 16 streaming multiprocessors.
- The memory is LPDDR5 with a 256-bit wide bus and bandwidth of 205 GB/sec.
- There are 22 PCIE lanes and 4 lanes of 10 gigabit ethernet.
- 16 CSI lanes allow you to connect several cameras and decode videos on hardware.
- There are several accelerators like:
- second generation Deep Learning Accelerator (DLA)
- Video Image Compositor (VIC) for temporal denoising
- Optical Flow Accelerator for optical flow calculations
- Programmable Vision Accelerator (PVA) for disparity estimation, corner detection etc
- dedicated engines for JPEG encode and decode
- dedicated engines for H264/H265 video encode and decode
- dedicated accelerator for HDR image signal processing
If any of these terms are new to you, we have written extensively about them here:
Nsight systems is a profiler for CUDA developed by NVIDIA. A profiler is a debugging tool that can monitor the performance of a code as it is running on hardware and report runtime statistics. Nsight systems allow you to identify bottlenecks in your code and comprehensively trace system wide software and hardware activity. There is an interesting tool in the Nsight family, called Nsight DL Designer.
Nsight DL designer is an IDE for efficient design and deployment of deep neural networks. It allows you to profile your network performance layer by layer and even design a network using the GUI and export the definition as an ONNX file.
With Nsight tools, developers can get unprecedented insights into the performance of Jetson Orin SoC modules. You can, for example, profile an entire robotics application which may consist of multiple algorithms running on different hardware mentioned above. Everything from CPU, GPU and DLA can be profiled directly inside Nsight tools allowing you to squeeze the maximum performance out of these chips. So, we say that Jetson Orin + Nsight is a match made in heaven.
New Features in CUDA C++ [S51225]
Although the title of this talk is ‘CUDA: New Features and beyond’, most of the talk was not about CUDA but about setting the context. The way computers work is that we create small patterns on finely ground sand (aka computer chips) and inject life into it with text (software). For a long time, these two worlds existed pretty much independent of each other and advances in one domain were independent of advances in the other. Recently, however, the picture is getting more interesting.
In terms of hardware, we have reached the reticle limit offered by the latest EUV tools. What this means in simple terms is that we are already using the maximum size of chips that the latest manufacturing tools can produce. On the other hand the minimum feature size that can be printed on a chip is also stagnating. This is typically what we mean when we say Moore’s law is slowing down (or dead). The combined effect of these two phenomena is that the maximum number of transistors we can pack into a single chip has more or less saturated now. A new strategy is required to keep improving computing performance. In this context, let us see the latest advances in CUDA.
CUDA’s original claim to fame was that it is a programming model for heterogeneous computing. With Moore’s law slowing down and the reticle limit in the rear view mirror, NVIDIA is banking on a multi die heterogeneous computing architecture to keep scaling computing performance. One example of this is the design of the Ada Lovelace SM (RTX 4000 generation of GPUs).

We can see that the Ada die already incorporates multiple specialized engines for ray tracing, texture mapping, AI inference, rasterization and floating point compute. But what if these engines were not on the same chip? This is exactly what happens in GraceHopper ‘superchip’.
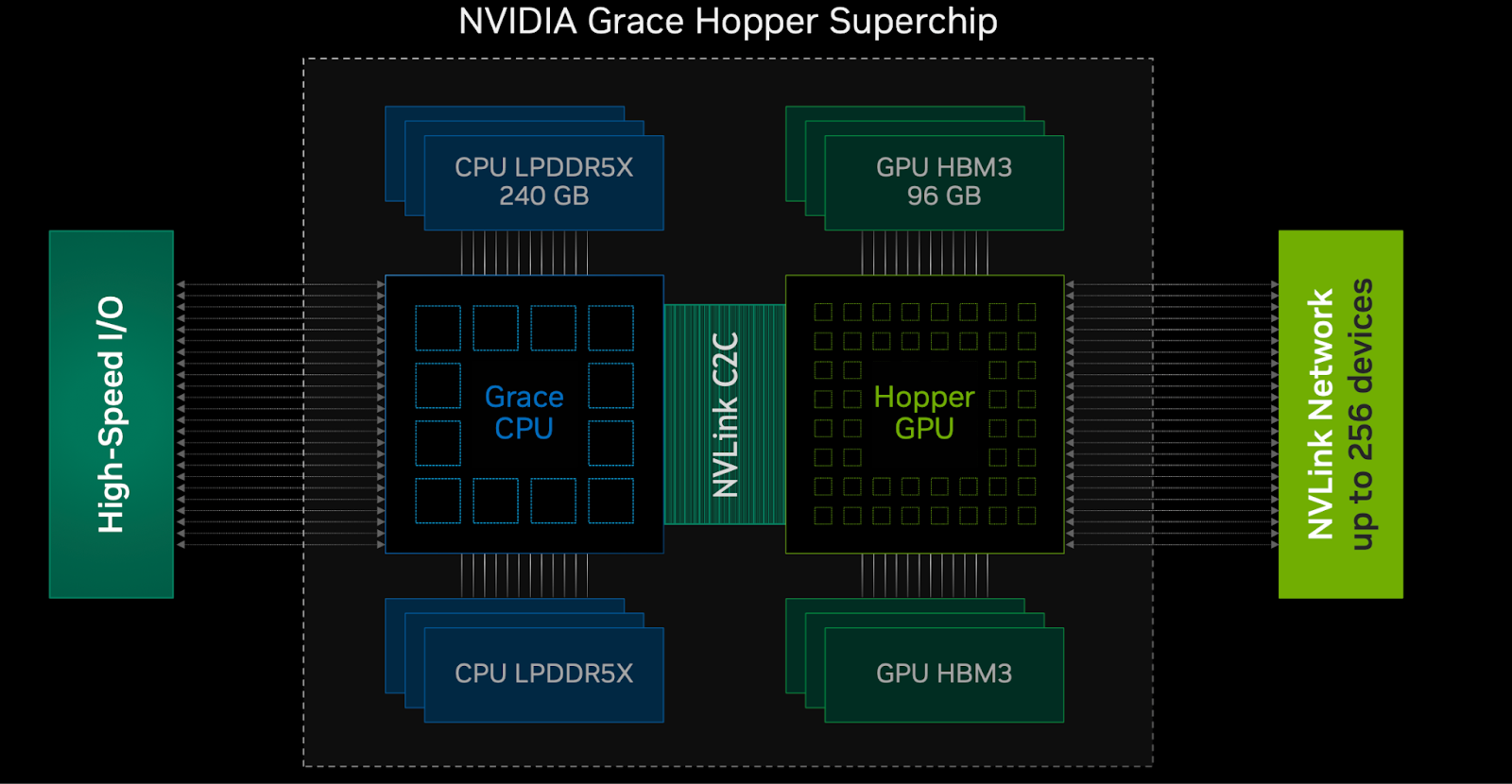
Like Apple M1 and M2 series of processors, the GraceHopper chip combines CPU and GPU on a single die and ties them together with a unified memory (in software). Moreover, a single GraceHopper chip can be connected in a cluster of up to 256 chips which can all talk to each other over the NVLink interconnect. The latest CUDA versions allow multiple GraceHopper chips to see all data globally from every other chip. Crucially, all this data is cache coherent. The new CUDA release and going forward future releases will be aimed at making it easier to develop applications for multi-node systems like GraceHopper chips. NVIDIA is banking on implicit parallelism to make this process smoother for developers. Implicit parallelism makes sure that the programmer does not have to consider all the low level details of the hardware and the software maps directly onto any size of system at compile time.
A library called cuNumeric for implicit parallelism on python numpy arrays is now in beta, which uses CUDA under the hood. If you would like to experience the power of implicit parallelism feel free to try it out and accelerate your numpy workloads today.
Automated Pipeline Parallelism for PyTorch [S51254]
Large Language Models are getting larger every year. The smallest of LLMs are a few billion parameters while the largest ones are hundreds of billions of parameters. At the same time, the memory a single GPU can hold is only enough for a few tens of billion parameters and thus, the largest models cannot be trained on a single GPU.
To train these large models, we need to create their shards and divide them up into different GPUs. Now, all of this is old news. On Day 1 of GTC, we introduced three types of parallelism here.
To recap, pipeline parallelism is an approach where the model is divided up into small blocks containing a few layers and the blocks live on different GPUs. During inference, each GPU calculates only a few layers of the model and passes on its output to the GPU responsible for the next set of layers. Say, a model is divided into 2 GPUs, GPU0 calculates the first half of the model and GPU1 runs the other half. Suppose a mini-batch comes in and is processed by GPU0 and the output is passed to GPU1. While GPU1 is doing its job, typically GPU0 must wait idly for the next batch to come in. Can we give the next batch to GPU0 to process while it is waiting for GPU1? This is called pipeline parallelism. PiPPy is a library written by the PyTorch authors to automate this process. PiPPy performs 3 main functions:
- It automatically splits a model into pipeline stages.
- It automatically distributes these stages across devices and weaves communication channels between them.
- It automatically orchestrates micro-batches through the pipeline to maximize overall system throughput.
Checkout the GitHub repository of PiPPy here and let us know if you find it useful.
SpaceVerse by the US Space Force [S51732]
This one is out there! You have heard of Metaverse. You have heard of Omniverse. Now get ready for SpaceVerse! Militaries around the world use simulators to train personnel. Space is the next frontier and the US Space Force wants to be ready for battles in space someday. However, as you can guess, there are no military personnel present in space as of now (ISS astronauts don’t count since they are deployed for scientific purposes not military). So the question becomes, how do you train people to fight in space when they can’t even go there?
The USSF thinks that at least a part of the answer lies in the metaverse. SpaceVerse is an all encompassing simulation platform that USSF is trying to develop which will integrate with open data providers and in the future help operations teams to coordinate planning and execution of missions. In a proof of concept showcased by the team, the launch data of a rocket provided by Maxar was implemented into an Omniverse scene by a company called Cesium. As shown in the figure below, the SpaceVerse can take the USD asset of the rocket and simulate its current location, trajectory, heading, current stage as well as the ambient weather and clouds.

The term ‘open standards’ was used often in the talk, meaning that in principle anyone can build on top of these tools and contribute data to the space verse ecosystem. Technical details are scarce at the moment, but it is fascinating to see that ray tracing and Omniverse technologies are being applied by the military to potentially shape the future of warfare.
Summary
We hope you have liked the over four days of continuous coverage we have given to GTC. There are more talks than we can possibly cover in these blog posts, so here are some of the other interesting talks we recommend you to checkout:
- How to Write a CUDA Program [S51210]
- Are Generative Models the Key to Achieving Artificial General Intelligence? [S52122]
- Developing Optimal CUDA Kernels on Hopper Tensor Cores [S51413]
- Deep Reinforcement Learning with Real-World Data [S51826]
- Isaac Sim: A Cloud-Enabled Simulation Toolbox for Robotics [S52573]
- Data-Driven AV Safety [S51452]
- Improving Road Safety with AI-Based Stereo Camera Object Detection [S51087]
- Jetson Edge AI Developer Days: Accelerate Edge AI With NVIDIA Jetson Software [SE52433]
Overall we see that the vast array of hardware, software, accelerators, libraries and platforms developed by NVIDIA are slowly converging together into a coherent set of cloud native tools that can be accessed by anyone anywhere. NVIDIA is banking on this strategy to drive the next round of innovation in all fields like AI, robotics, healthcare, agriculture and drug discovery to name a few. We are excited about where this leads to and will continue to keep you updated with the latest advances in these areas. Until next time, happy learning 🙂
Check out the useful resources and detailed session recordings from the GTC.





