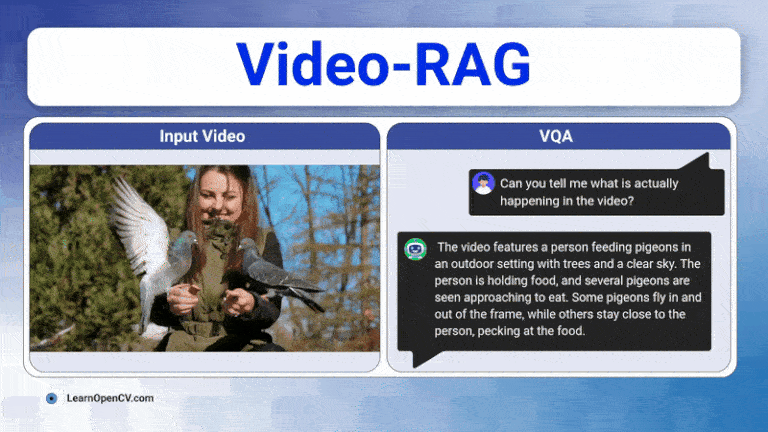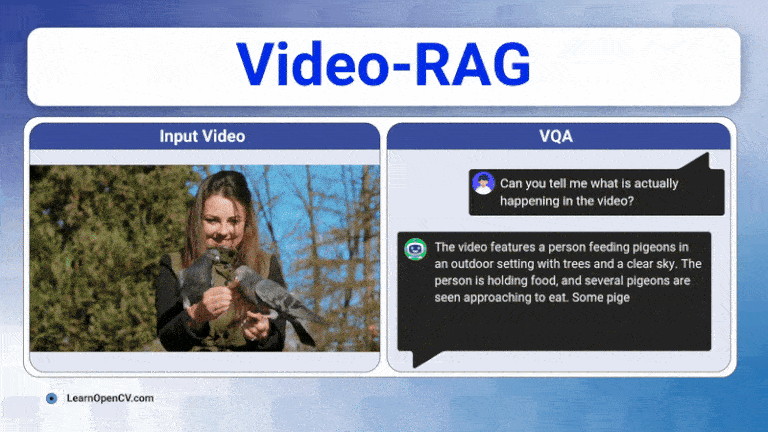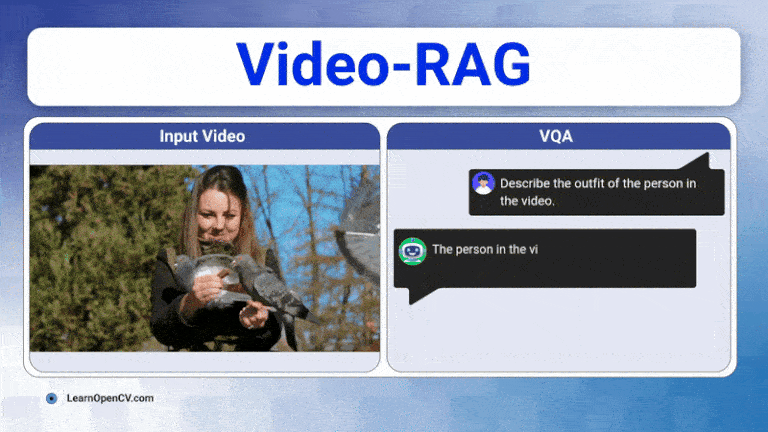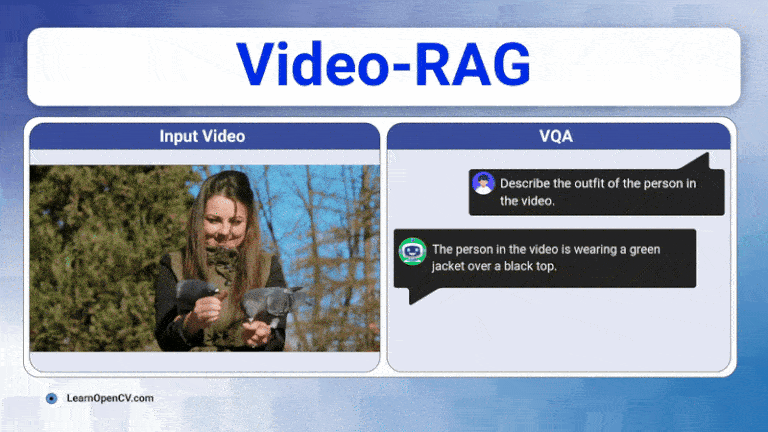
Long videos are brutal for today’s Large Vision-Language Models (LVLMs). A 30-60 minute clip contains thousands of frames, multiple speakers, on-screen text, and objects that appear, disappear, and ...



Long videos are brutal for today’s Large Vision-Language Models (LVLMs). A 30-60 minute clip contains thousands of frames, multiple speakers, on-screen text, and objects that appear, disappear, and ...
PaddleOCR: Reading huge documents can be very tiring and very time taking. You must have seen many software or applications where you just click a picture and get key information from the document. ...
