


Depth Anything represents a groundbreaking advancement in the field of monocular depth perception. This research article outlines the innovative approach taken in designing the Depth Anything model, including its unique architecture and the comprehensive inference pipeline that underpins it.

Not just that, it also demonstrates the model’s practical applications by presenting experimental results obtained from real-world scenarios, showcasing its potential to transform depth perception across diverse applications such as underwater creature depth estimation, human action observation, gesture recognition, wildlife monitoring, terrain mapping, etc .
To see the results, you may SCROLL BELOW to the concluding part of the article or click here to see the experimental results right away.
Monocular Depth Perception
Monocular depth perception is a pivotal aspect of 3D computer vision that enables the estimation of three-dimensional structures from a single two-dimensional image. Unlike stereoscopic techniques, which rely on multiple viewpoints to infer depth, monocular depth perception algorithms must extract depth cues from various image features such as texture gradients, object sizes, shading, and perspective. The challenge lies in translating these inherently ambiguous cues into accurate depth maps, which has seen significant advancements with the advent of deep learning.
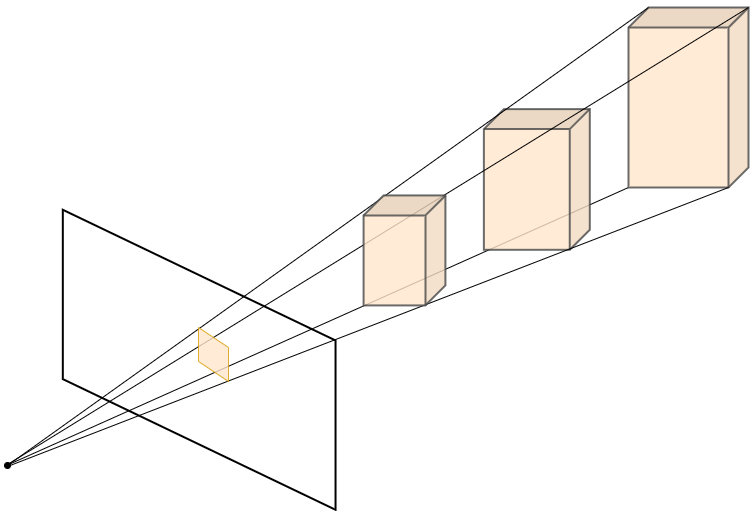
The theoretical foundation of monocular depth perception is rooted in the understanding of how humans perceive depth with a single eye. Psychological studies suggest that the human visual system utilizes a series of cues, including linear perspective, texture gradient, and motion parallax, to gauge depth. Leveraging these insights, computer vision researchers have developed algorithms that mimic this capability, using patterns and inconsistencies within a single image to estimate distances.
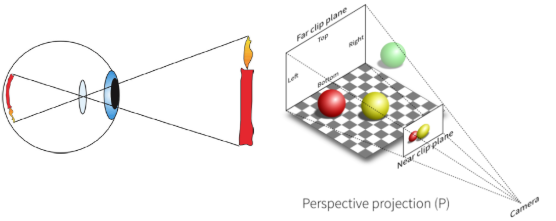
Monocular v/s Stereo Vision
Monocular and stereo vision are two fundamental approaches in computer vision for extracting depth information from images. Each method has its unique principles, advantages, and challenges. Here’s a detailed comparison between the two:
Principles
- Monocular Vision involves interpreting depth from a single image. It relies on cues like texture gradient, object size, perspective, and shadows to infer the three-dimensional structure of the scene.
- Stereo Vision requires two images taken from slightly different viewpoints, similar to human binocular vision. By comparing the displacement (disparity) of objects between these two images, it calculates the distance to various points in the scene.
Accuracy and Depth Resolution
- Monocular Vision can struggle with absolute depth accuracy since it relies on indirect cues and assumptions about the scene. The accuracy of depth perception can vary greatly depending on the algorithms and the presence of recognizable depth cues in the image.
- Stereo Vision generally provides higher accuracy in depth measurements, as the disparity between images offers a direct quantitative basis for calculating depth. However, its effectiveness depends on the baseline distance between cameras and the resolution of the images.
Complexity and Computational Requirements
- Monocular Vision techniques, especially those using deep learning, can be computationally intensive due to the complexity of inferring depth from single images. However, since it requires processing only one image, it may require less computational power than stereo vision in certain applications.
- Stereo Vision involves matching points between two images, which can be computationally demanding. The process of finding correspondences and calculating disparities requires significant processing power, especially for real-time applications.
Hardware Requirements
- Monocular Vision has the advantage of requiring only a single camera, making it more cost-effective and easier to implement in hardware-constrained environments.
- Stereo Vision necessitates two cameras with a fixed spatial relationship and often additional calibration to ensure accurate depth measurements, increasing the complexity and cost of the hardware setup.
Limitations
- Monocular Vision can be less reliable in featureless or texture-less environments where depth cues are minimal. Its performance can also degrade in conditions of poor lighting or when objects are too close or too far away.
- Stereo Vision struggles with occlusions (where an object is visible in one image but not the other) and repetitive patterns (which can confuse point matching). It also faces challenges in environments with dynamic lighting changes.
Traditional Techniques in Monocular Depth Perception
Before the advent of deep learning in monocular depth estimation, the review paper by Yue Ming et al., [1] highlights the various techniques to infer depth information from single images. These methods exploited geometric and photometric cues inherent in images to deduce the three-dimensional structure of a scene. Given below are some of the legacy techniques for monocular depth perception:
- Shape-from Motion: It deduces depth by tracking object movement across multiple images, inferring distance but requiring sequences of images, limiting its use for single snapshots.
- Shape-from-Shading: It estimates depth from lighting and texture variations on surfaces, though its effectiveness is hindered by the need for precise lighting knowledge.
- Shape-from-Vanishing Points: It uses converging lines towards vanishing points to gauge depth, best suited for structured environments but less so for natural scenes.
- Focus / Defocus: This method derives depth from the sharpness or blurriness of areas within an image, necessitating different focus settings and complicating its application for depth estimation.

However, these approaches came with a few limitations:
- Complex and Inefficient: Many of these methods involve complex calculations and assumptions that can be computationally intensive and inefficient for real-time applications.
- Poor Practicality: The need for specific conditions, such as known lighting for Shape-from-Shading or multiple images for Shape-from-Motion, limits the practicality of these methods in dynamic or uncontrolled environments.
- Not Real-Time: The computational complexity and the requirement for extensive preprocessing or multiple images make real-time applications challenging.
- Low Depth of Field: Techniques based on focus and defocus are limited by the camera’s depth of field, restricting their effectiveness for scenes with significant depth variation.
Depth Anything: Pipeline Overview
Let’s explore the overall pipeline of the depth anything model and use mathematical intuition to understand its underlying components:
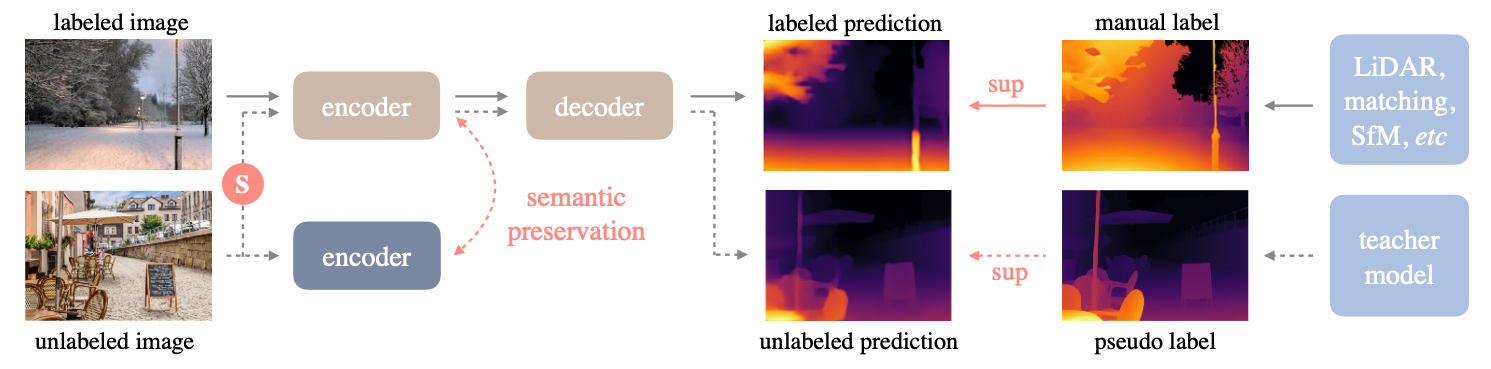
Learning from Labeled Images
The process starts with learning from a labeled dataset  , where
, where  represents the input image, and
represents the input image, and  denotes the corresponding depth map. The depth values are first transformed into disparity space via
denotes the corresponding depth map. The depth values are first transformed into disparity space via  and normalized within the range [0, 1]. To accommodate multi-dataset joint training, the model employs an affine-invariant loss function, which disregards the unknown scale and shifts across samples:
and normalized within the range [0, 1]. To accommodate multi-dataset joint training, the model employs an affine-invariant loss function, which disregards the unknown scale and shifts across samples:
 ,
,
where  and
and  are the predicted and ground truth disparities, respectively. The affine-invariant mean absolute error loss
are the predicted and ground truth disparities, respectively. The affine-invariant mean absolute error loss  is defined as:
is defined as:
 ,
,
with  and
and  being the scaled and shifted versions of the prediction and ground truth. The scaling and shifting are performed to align the prediction and ground truth to a common scale and zero translation, using:
being the scaled and shifted versions of the prediction and ground truth. The scaling and shifting are performed to align the prediction and ground truth to a common scale and zero translation, using:
 ,
,
where  and
and  .
.
Unleashing the Power of Unlabeled Images
The core innovation of “Depth Anything” lies in harnessing the potential of unlabeled images  . The model generates pseudo labels for these images by passing them through a pre-trained MDE model
. The model generates pseudo labels for these images by passing them through a pre-trained MDE model  , resulting in a pseudo-labeled set
, resulting in a pseudo-labeled set  . These pseudo labels, combined with the original labeled dataset, are used to train a student model
. These pseudo labels, combined with the original labeled dataset, are used to train a student model  , enhancing the model’s generalization capability.
, enhancing the model’s generalization capability.
Unlike traditional fine-tuning,  is re-initialized to ensure improved performance, challenging it with a harder optimization target. To enrich the model’s learning from unlabeled data, strong perturbations, such as color distortions and spatial distortions (CutMix), are introduced:
is re-initialized to ensure improved performance, challenging it with a harder optimization target. To enrich the model’s learning from unlabeled data, strong perturbations, such as color distortions and spatial distortions (CutMix), are introduced:
 ,
,
where  is a binary mask, and
is a binary mask, and  is the interpolated image from a random pair of unlabeled images
is the interpolated image from a random pair of unlabeled images  and
and  . The unlabeled loss
. The unlabeled loss  is calculated by applying affine-invariant losses on regions defined by
is calculated by applying affine-invariant losses on regions defined by  and
and  , and then aggregating these losses.
, and then aggregating these losses.
Semantic-Assisted Perception
To further enhance depth estimation, “Depth Anything” incorporates semantic segmentation as an auxiliary task, leveraging the semantic-aware capabilities of models like DINOv2. This is achieved through an auxiliary feature alignment loss:
 ,
,
where  and
and  represent the feature vectors extracted by the depth model
represent the feature vectors extracted by the depth model  and a frozen DINOv2 encoder, respectively. This loss encourages the model to align its depth predictions with rich semantic information, facilitating more accurate and robust depth estimation.
and a frozen DINOv2 encoder, respectively. This loss encourages the model to align its depth predictions with rich semantic information, facilitating more accurate and robust depth estimation.
In the illustration below, the overall architecture of the depth anything model has been shown:
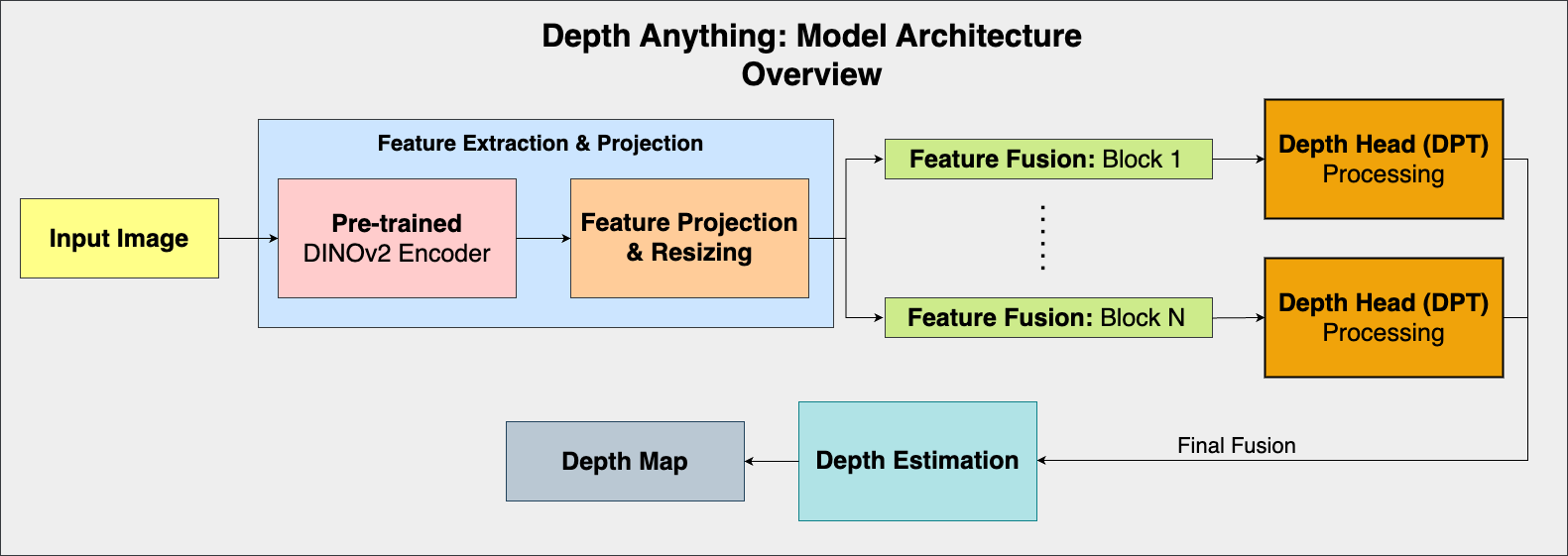
NOTE: Two model implementation files – dpt.py and blocks.py from the depth anything repository [3] were used as references to create FIGURE 4.

Code Walkthrough: Inference Pipeline
In this section, we will explore the inference pipeline for the depth anything model to perform monocular depth perception.
Clone the Depth Anything Repository
The first step is to clone the depth anything repository for monocular depth perception into your local development environment. For this, use the command-line instructions given below:
!git clone https://github.com/LiheYoung/Depth-Anything
cd "Depth-Anything"
pwd
This basically clones the depth anything repository from GitHub to your current working directory, and the directory to the newly created Depth-Anything directory.
Command-line Inference: Usage
There are multiple ways to perform monocular depth perception using the depth anything model. You can either do it directly from the command-line, or also use HuggingFace Transformers. However, in this article, we will be exploring the command-line method as it is more accessible.
Given below are some of the arguments that can be used:
Arguments:
--img-path: you can either point it to an image directory containing all interested images, point it to a single image, or point it to a text file storing all image paths.--pred-only: is set to save the predicted depth map only. Without it, by default, we can visualize both the image and its depth map side by side.--grayscale: is set to save the grayscale depth map. Without it, by default, a color palette to a depth map.
Image Inference – Usage
!python run.py --encoder <vits | vitb | vitl> --img-path <img-directory | single-img | txt-file> --outdir <outdir> [--pred-only] [--grayscale]
Image Inference – Example
!python run.py --encoder vitl --img-path assets/examples --outdir depth_vis
Video Inference – Example
!python run_video.py --encoder vitl --video-path assets/examples_video --outdir video_depth_vis
NOTE: In the command-line instructions mentioned above, the --encoder param can be changed. At the moment, there are three ViT encoder options – vits, vitb and vitl.
Experimental Results: Real-world Applications
It turns out that there are multiple applications in the real-world where monocular depth perception can be really useful. In this section, some of those applications are shown. Another point to note is that, all the three models: vits, vitb and vitl, have been used to perform inference for each application.
Underwater Creature Depth Estimation
Monocular depth perception in underwater environments is crucial for 3D modeling of marine life and seabed topography analysis.



Human Action Observation
In this application the depth anything model can help to perform precise monocular depth perception for 3D body scanning, enabling applications in motion analysis, security surveillance, and advanced ergonomics studies.



Gesture Recognition
Gesture recognition usually uses depth data from time-of-flight (ToF) cameras or stereo vision to accurately interpret human gestures, enhancing user interfaces in AR/VR applications and improving accessibility technologies. But with the depth anything model, monocular depth perception is possible for this application.



Wildlife Monitoring
For animals, depth estimation integrates thermal imaging with stereo vision techniques to track and analyze wildlife movements in their natural habitats, aiding in ecological research and the monitoring of endangered species.
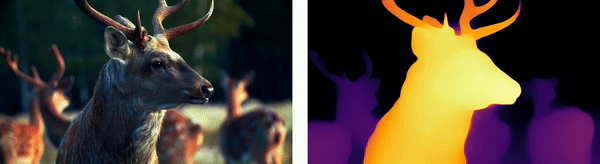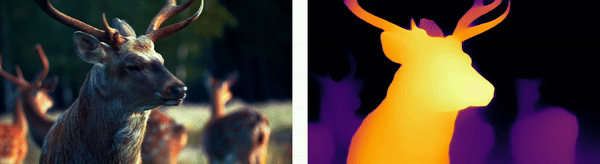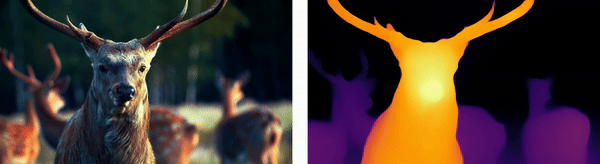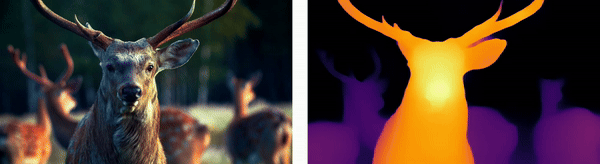

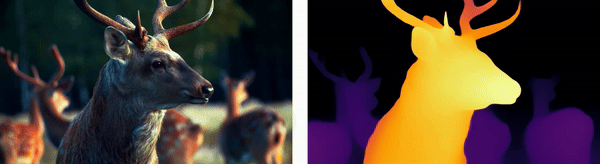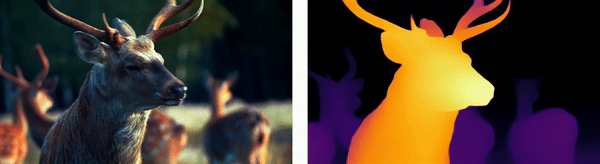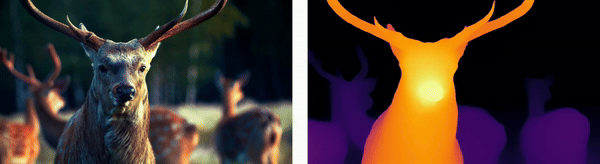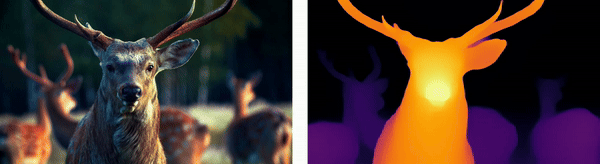
Urban Environments
In urban planning, monocular depth estimation from photogrammetry supports the creation of detailed 3D city models, facilitating infrastructure development, and optimizing traffic flow management.



Terrain Mapping
Monocular depth perception in aerial footage, using drone-mounted cameras provides critical data for agricultural mapping, disaster assessment, and the monitoring of environmental changes over large areas.



Interesting results, right? SCROLL UP or have a look at the code walkthrough section of this research article to explore the intricate fine-tuning procedure.
Key Takeaways: Analyzing Depth Perception Across Model Sizes
When evaluating the performance of depth anything models across different scales—from small to base to large—a series of observations can be made regarding their impact on image quality, inference speed, and overall visual clarity for monocular depth perception. These findings play a critical role in understanding the trade-offs involved in selecting the appropriate model size for specific applications. Here’s a detailed analysis based on the observed outcomes:
- Prominence of Outlines / Edges: As we progress from small-sized models to larger configurations, there’s a noticeable enhancement in the definition of outlines and edges within the images. This improvement in edge delineation is attributed to the increased model capacity, which allows for better capturing of spatial hierarchies and finer details.
- Visibility of Background Subjects: Another key observation is the enhanced visibility of background subjects in models transitioning from small to large. This implies that larger models are more adept at depth discrimination, effectively distinguishing between foreground and background elements. This capability is essential for complex scene understanding and has significant implications for applications requiring precise depth segmentation, such as autonomous navigation and advanced content creation.
- Inference Speeds: With the increase in model size comes a trade-off in terms of inference speed. Larger models, due to their extensive computational requirements, exhibit slower processing times. This aspect is crucial for real-time applications, where latency can be a limiting factor. Developers must therefore carefully consider the inference speed relative to the application’s real-time requirements, potentially optimizing models or leveraging CUDA accelerations to mitigate delays.
- Increase in Sharpness: The increase in sharpness across models from small to large indicates a heightened ability to resolve detail, contributing to more textured and vivid representations of the scene. This sharpness is particularly beneficial for applications requiring high fidelity visual reconstructions, such as digital archiving and precision modeling.
- Need for Fine-tuning: For specific applications such as terrain mapping (shown in Figures 19, 20, 21), the depth perception does not look promising. In this case, custom fine-tuning might be required and this is pretty common. One can’t expect a pre-trained model to be able to work accurately across applications.
Conclusion
In this research article, we explored the depth anything model specifically for monocular depth perception. We also had a look at the inference pipeline for this model, along with few real-world applications where depth estimation can be crucial.
💡 Download our code and dive into practical computer vision experiments. See real results on your screen, enhancing your skills and understanding with every run. Start now for a hands-on approach to learning that delivers.
References
[1] Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular Depth Estimation Using Deep Learning: A Review. Sensors 2022, 22, 5353. https://doi.org/10.3390/s22145353
[2] Yang, Lihe, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. “Depth anything: Unleashing the power of large-scale unlabeled data.” arXiv preprint arXiv:2401.10891 (2024).

