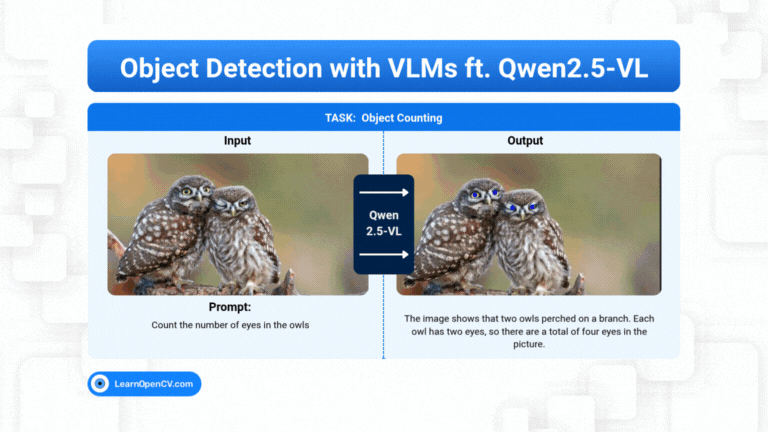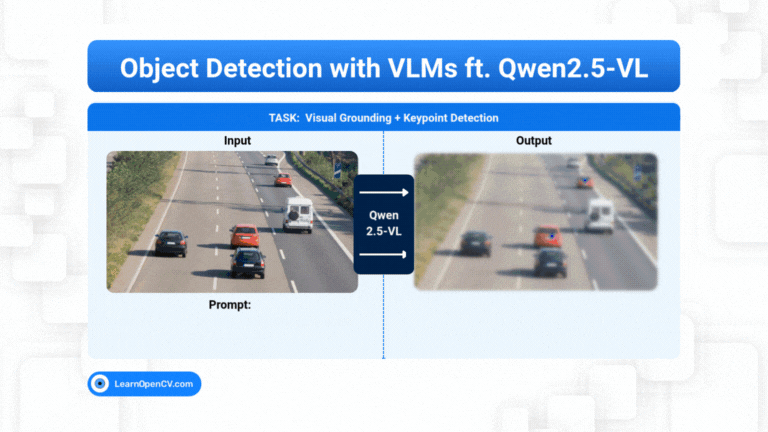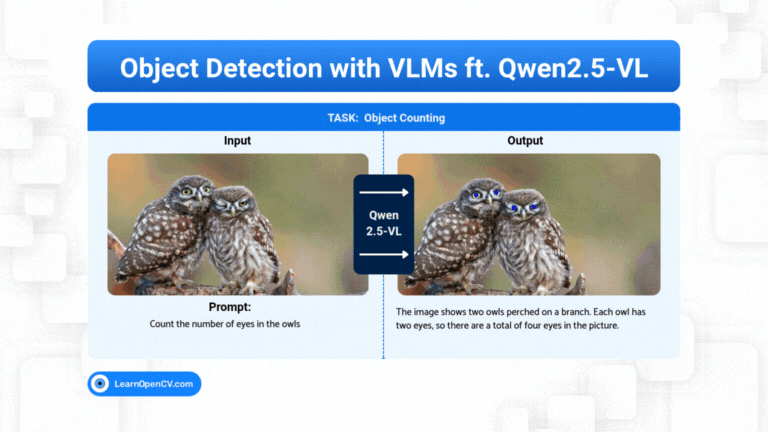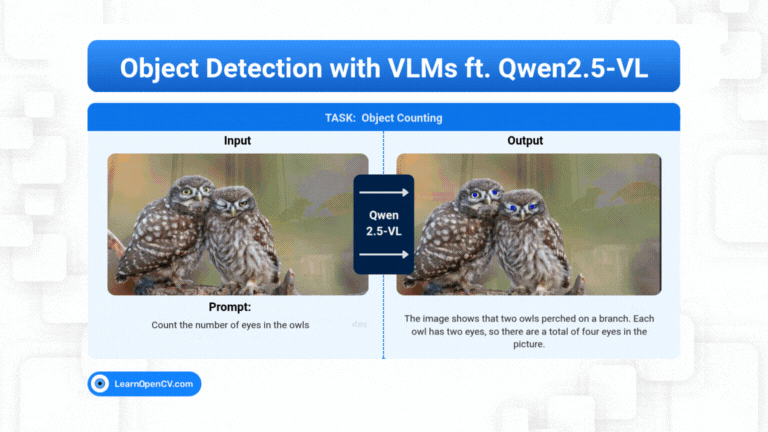
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
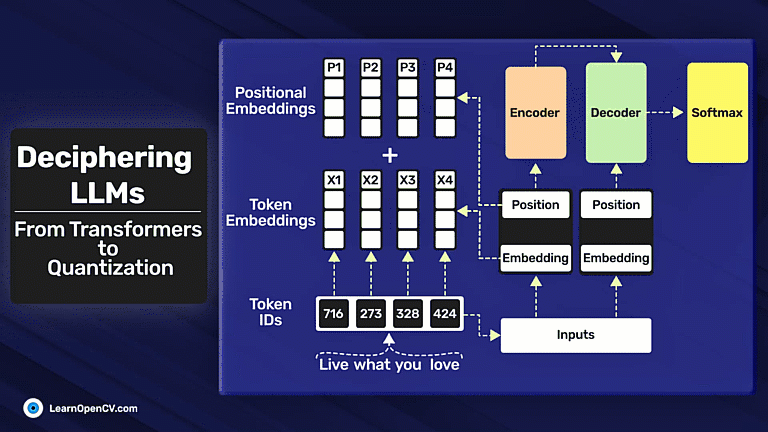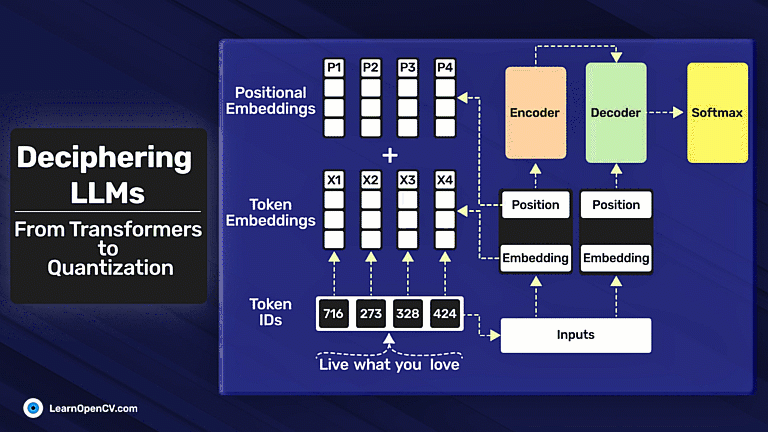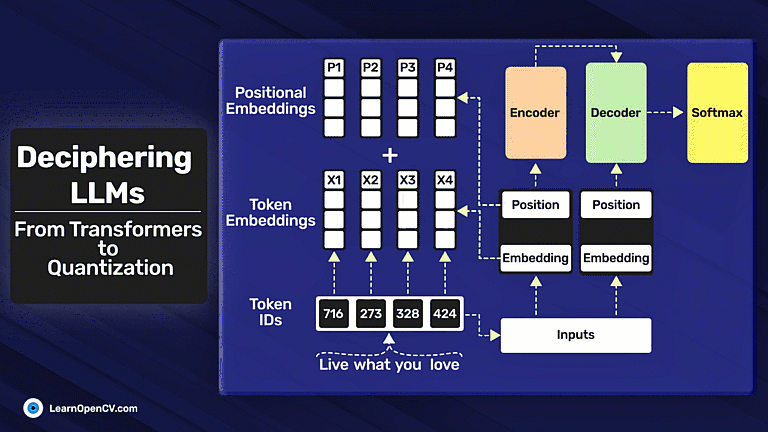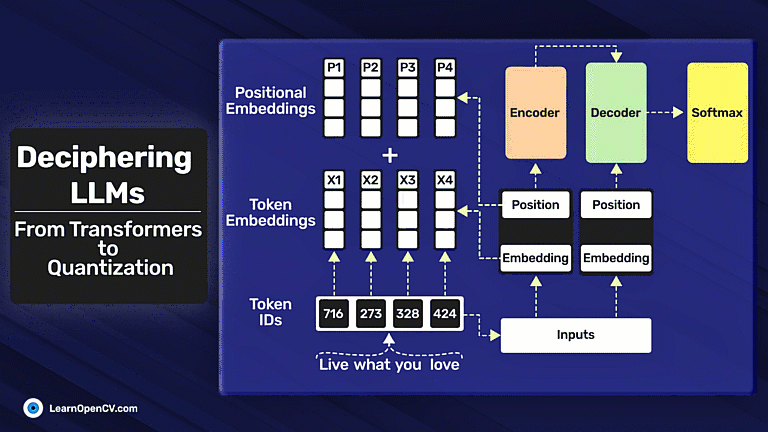
In the groundbreaking 2017 paper “Attention Is All You Need”, Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or convolution. This elegant, non-learned
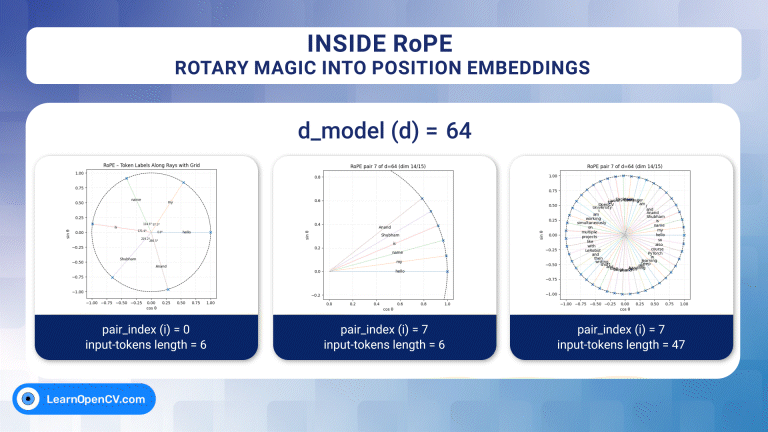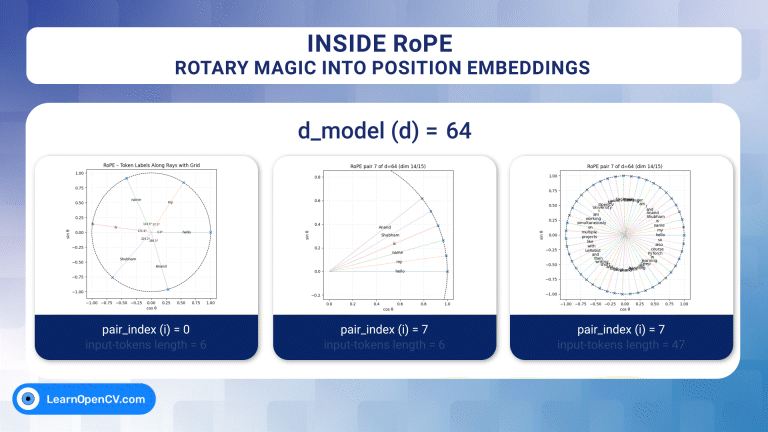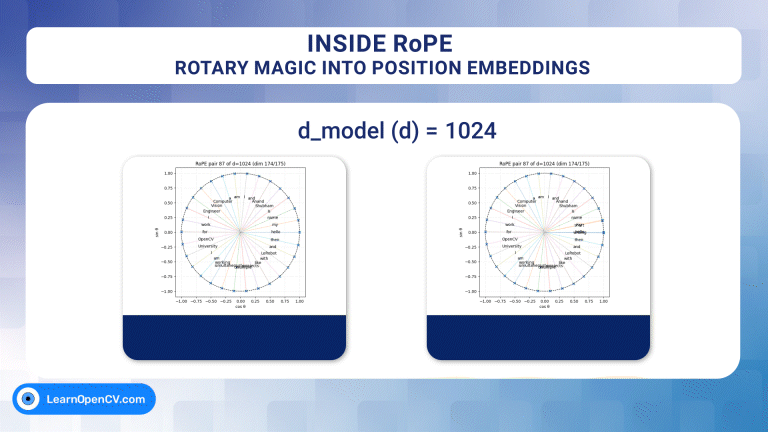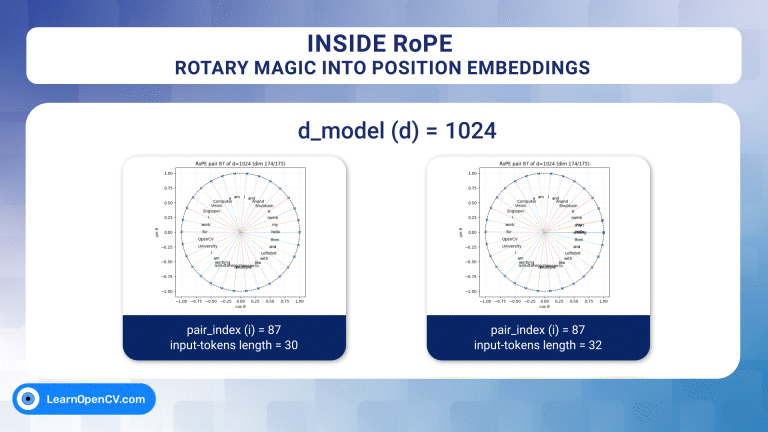
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which
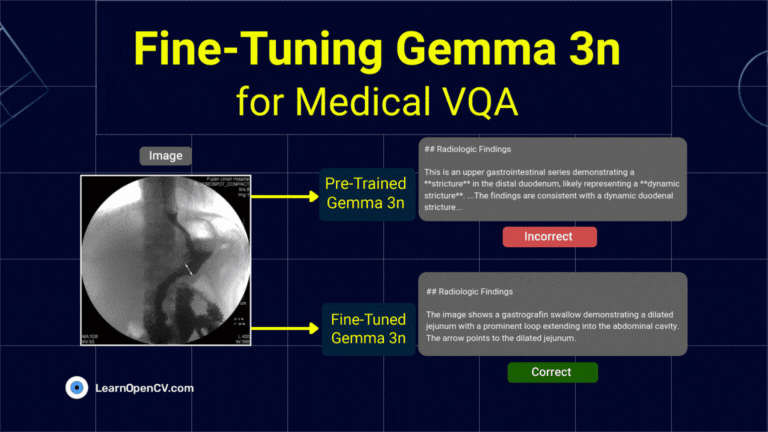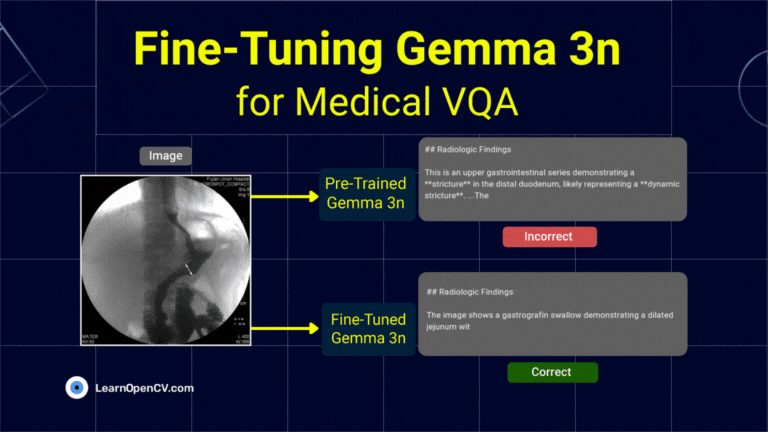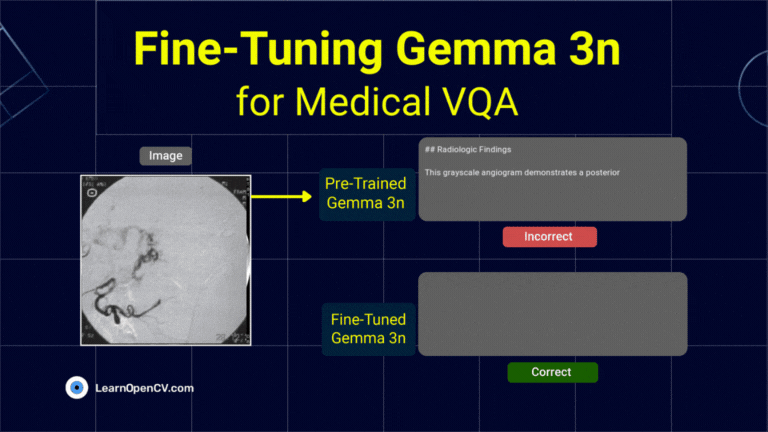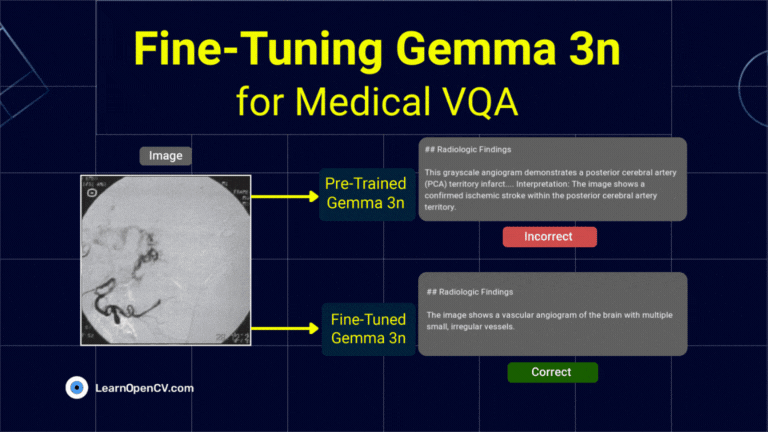
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
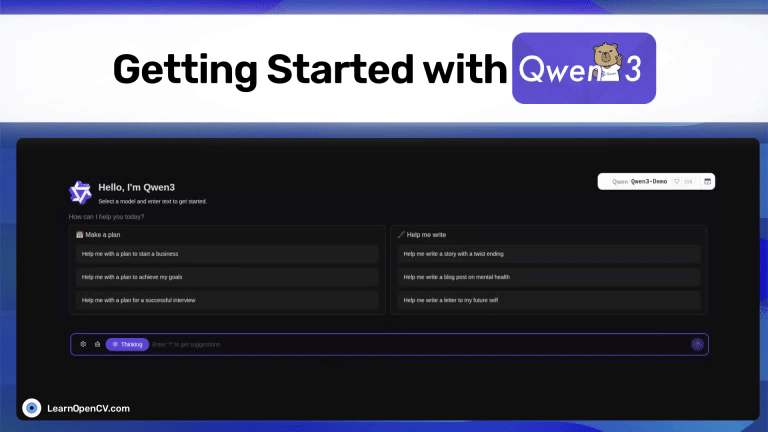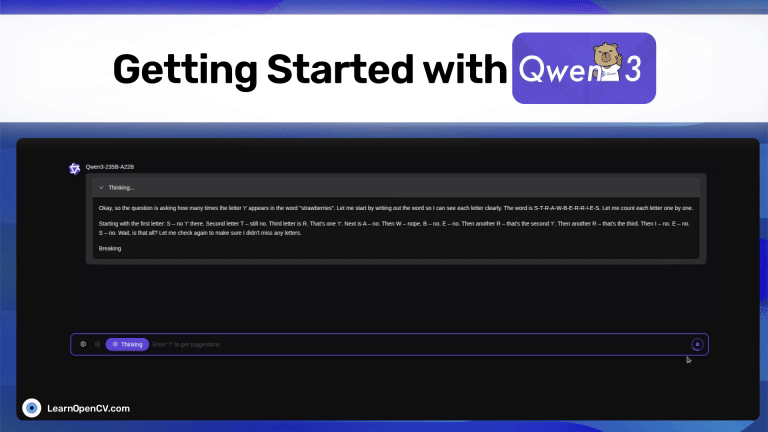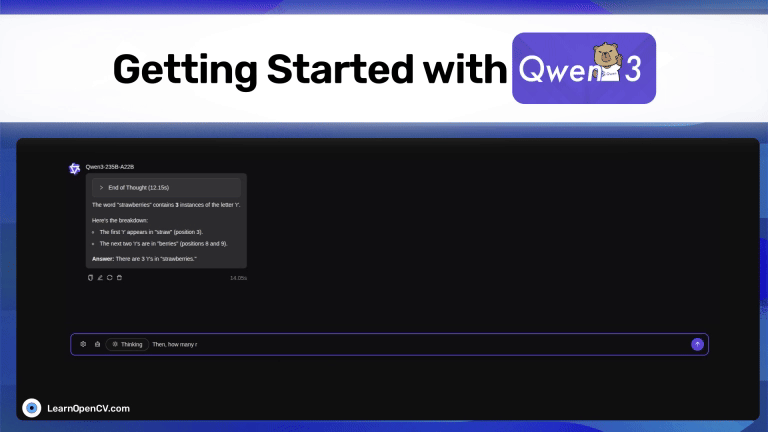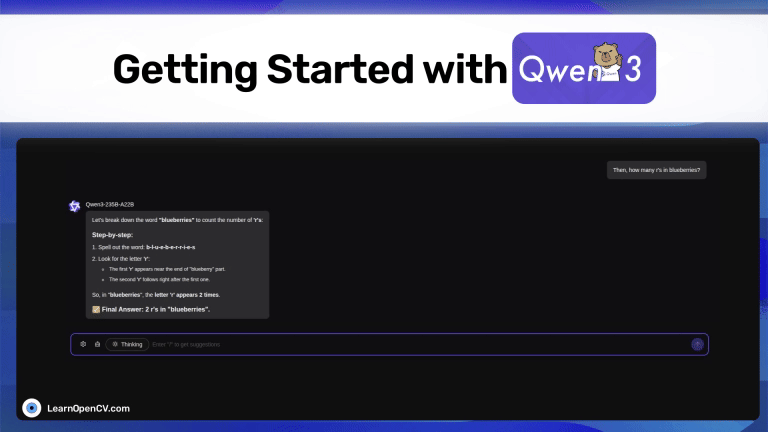
Discover Qwen3, Alibaba’s open-source thinking LLM. Switch between fast replies and chain-of-thought reasoning with 128 K context, and MoE efficiency. Learn how to use and Fine Tune.
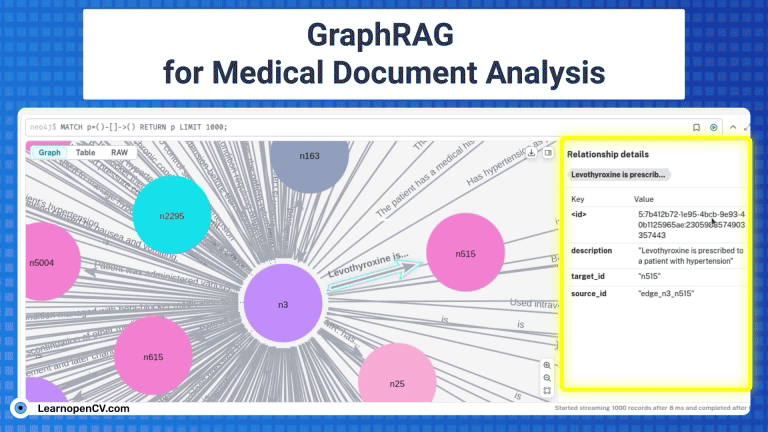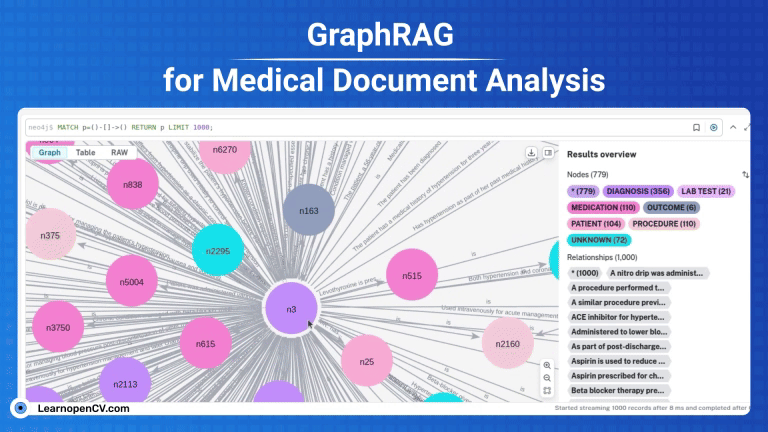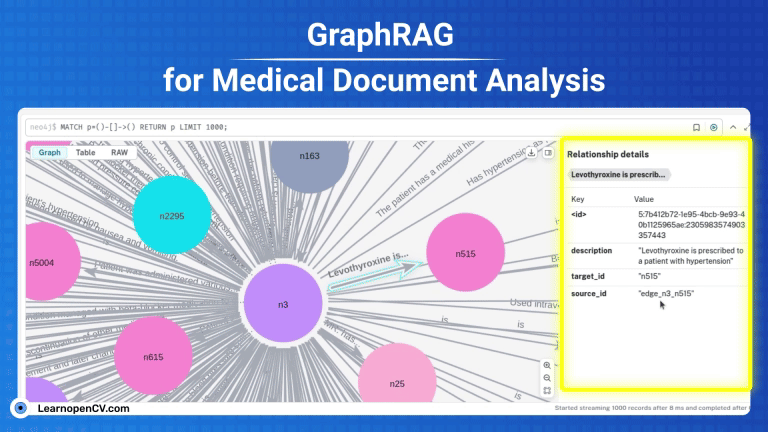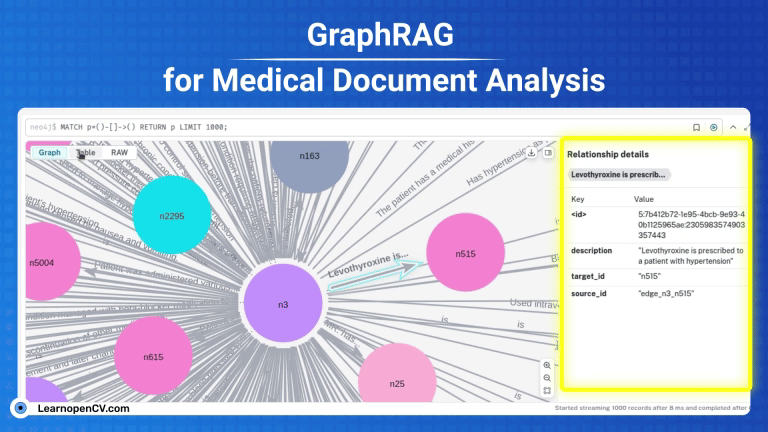
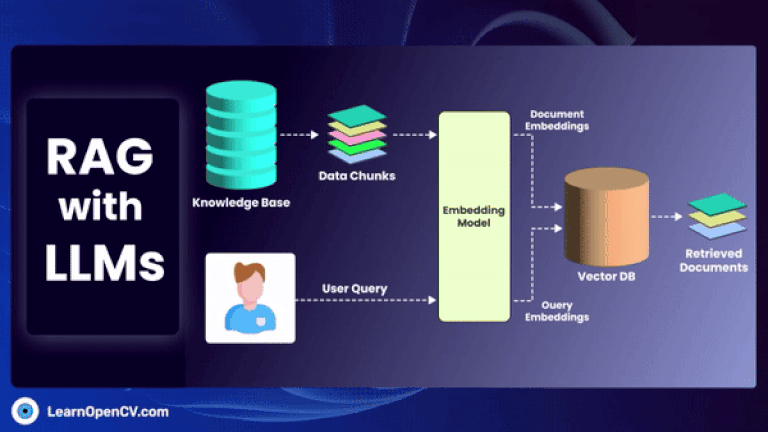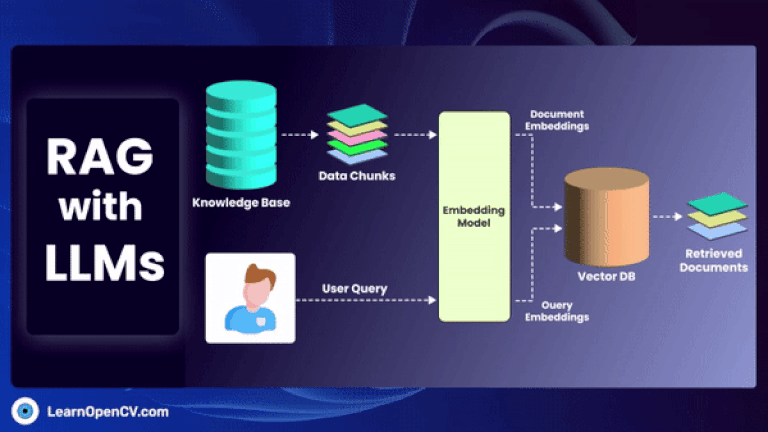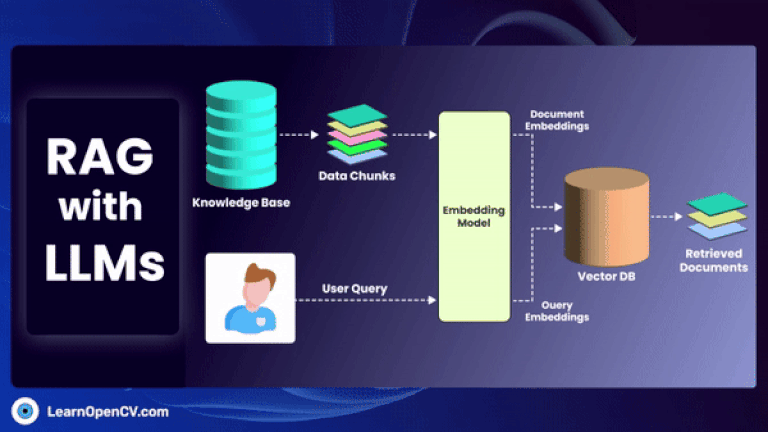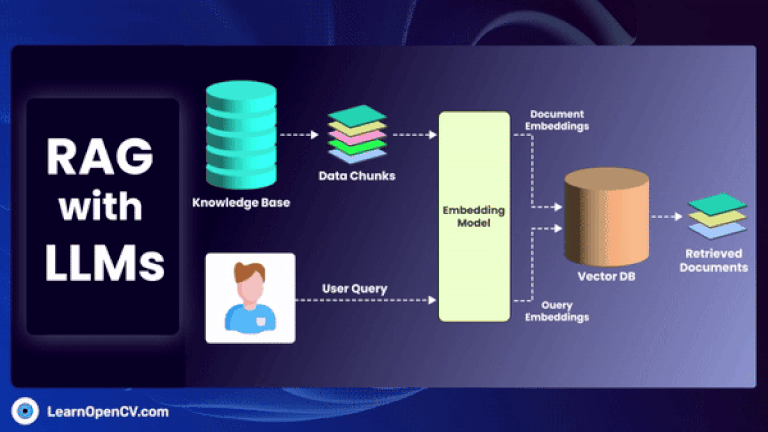
GraphRAG is a pivotal research from Microsoft improving the shortcomings of naive RAG by employing structured Knowledge graph which includes entities, relations, claims etc, for traceability by traversing multi-hop nodes.
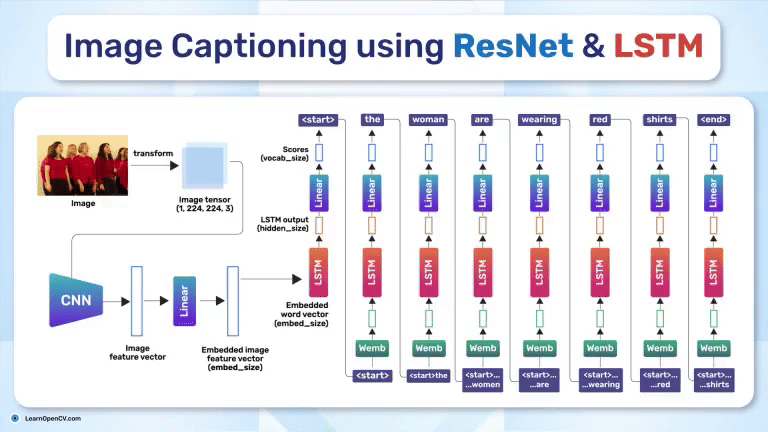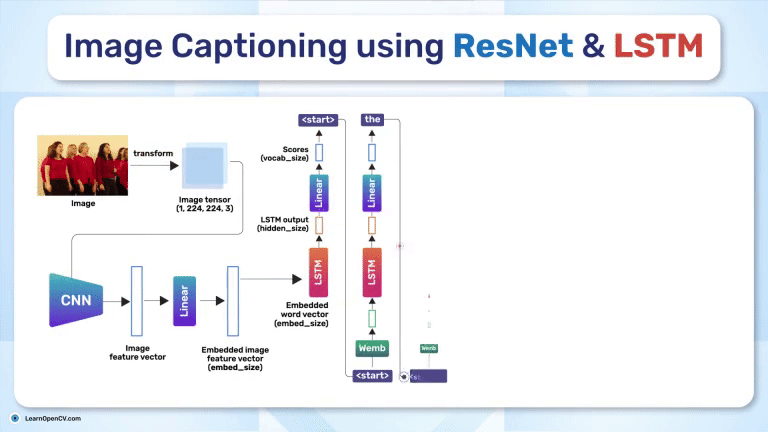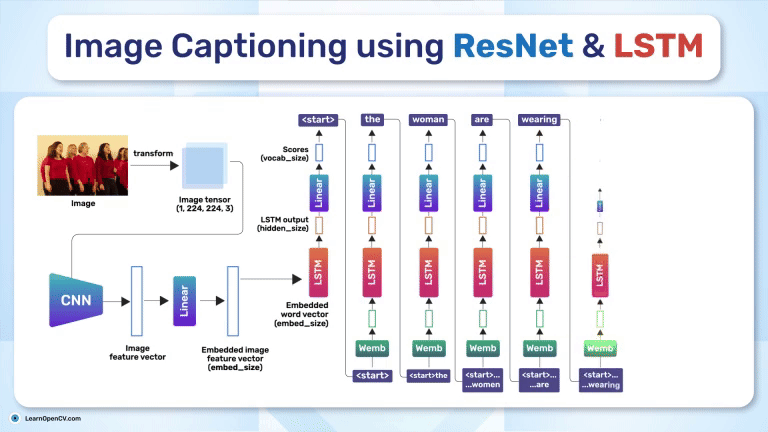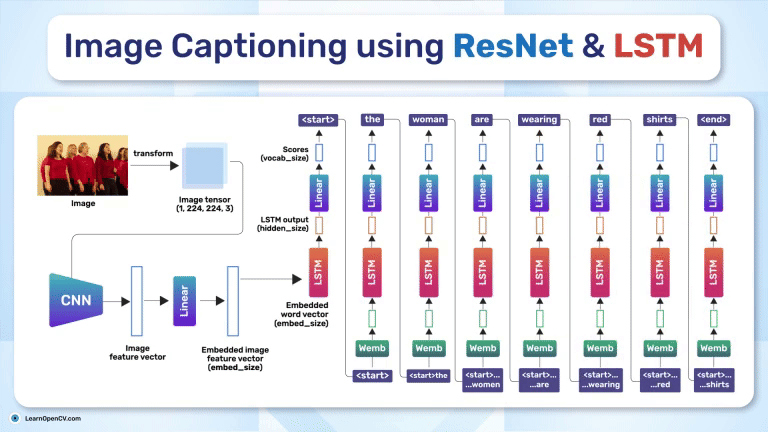
Image Captioning using ResNet and LSTM bridges vision and language, enabling machines to "see" images and "describe" them in text. This model powers applications like accessibility for visually impaired users,
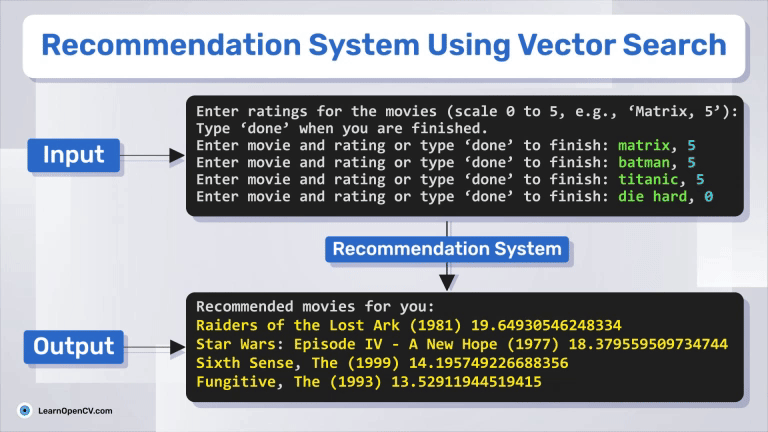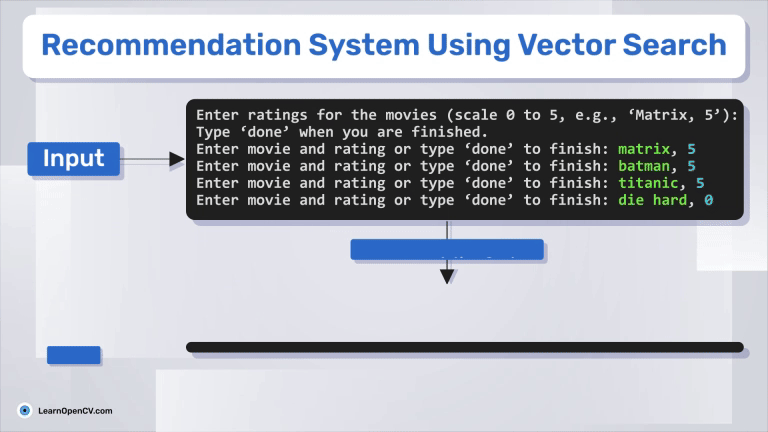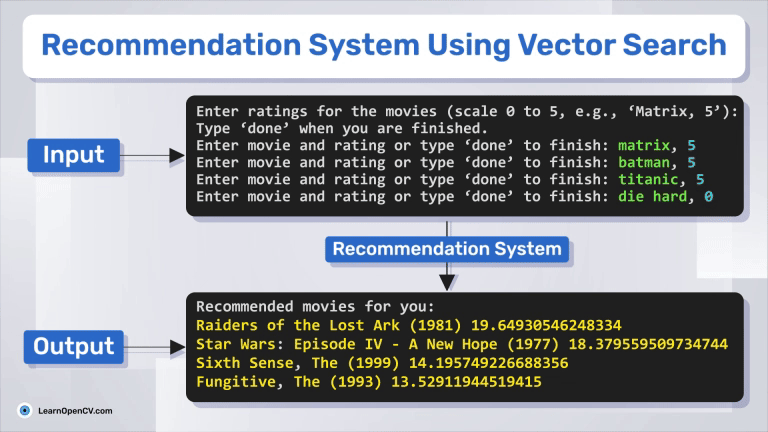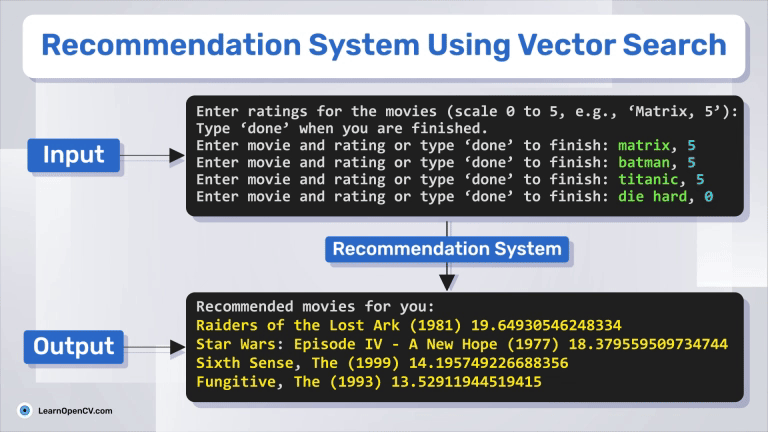
In this article, we explore how to build a movie recommendation system using vector search with Qdrant. You'll learn about vector databases, sparse and dense vectors, and how the Retrieval-Augmented
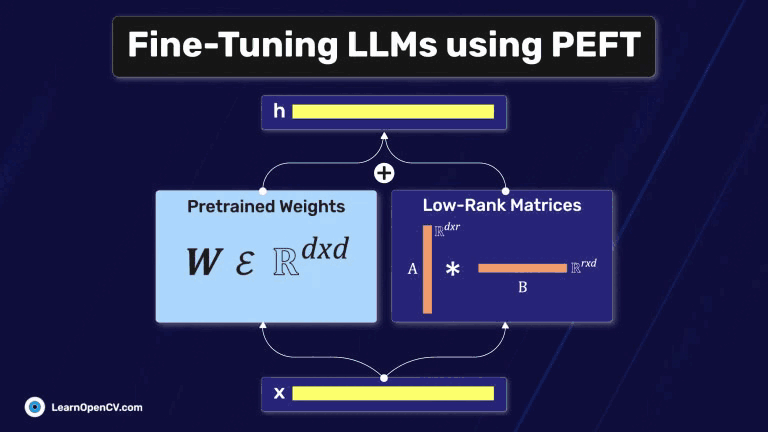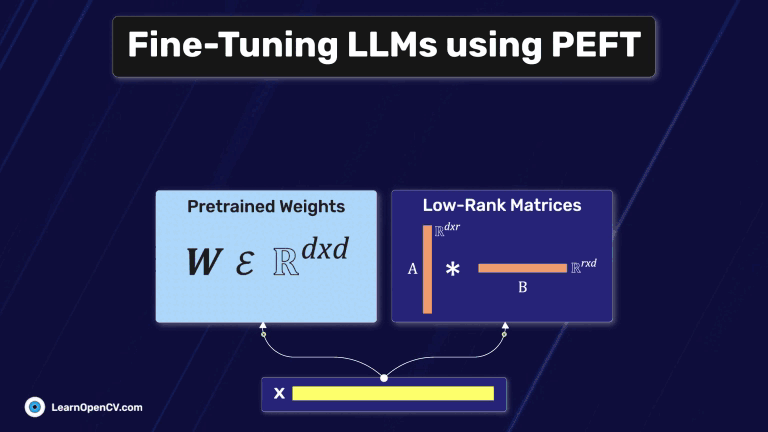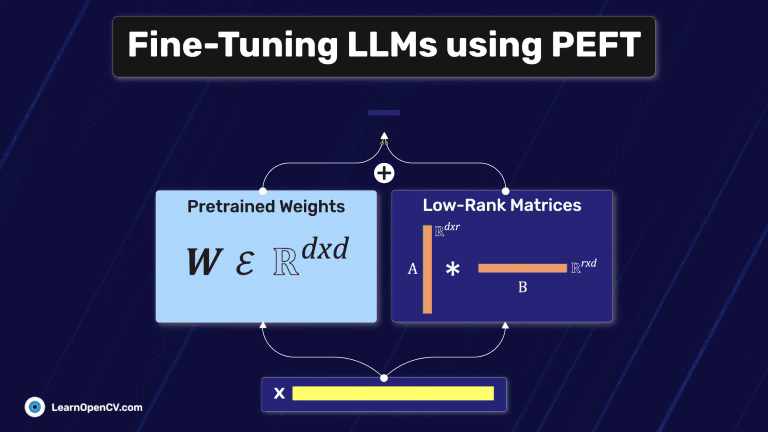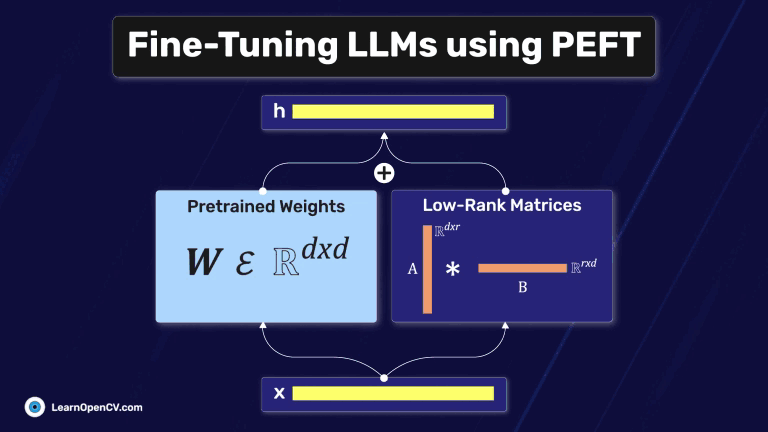
In this article, we explore different fine-tuning techniques for LLMs and fine-tune the FLAN T5 LLM using PEFT with the Hugging Face Transformers library.