SigLIP-2 represents a significant step forward in the development of multilingual vision-language encoders, bringing enhanced semantic understanding, localization, and dense feature extraction capabilities. Built on the foundations of SigLIP, this
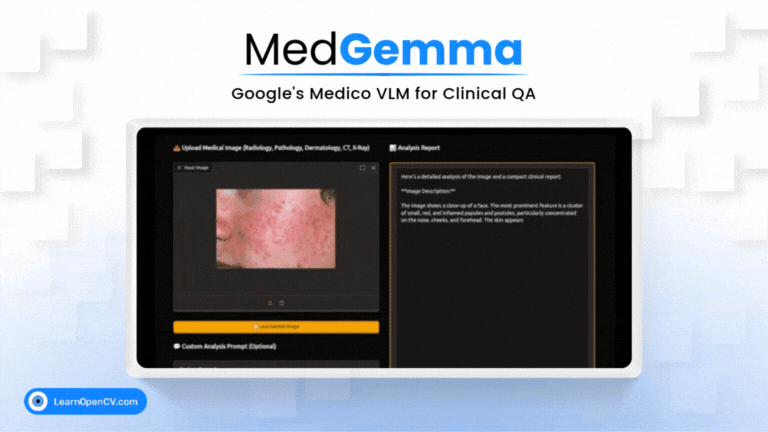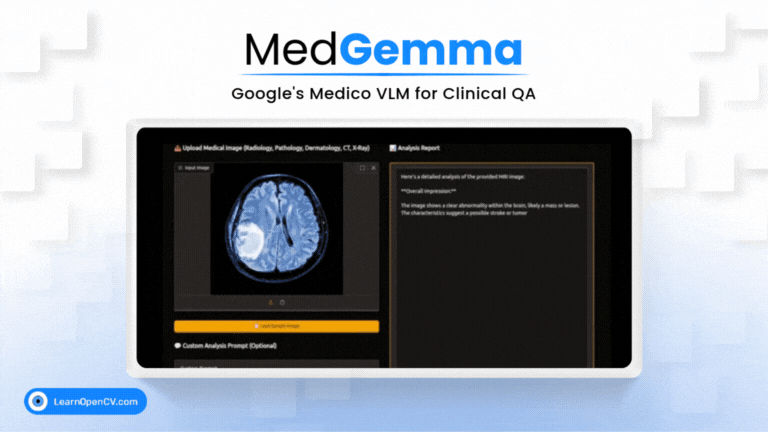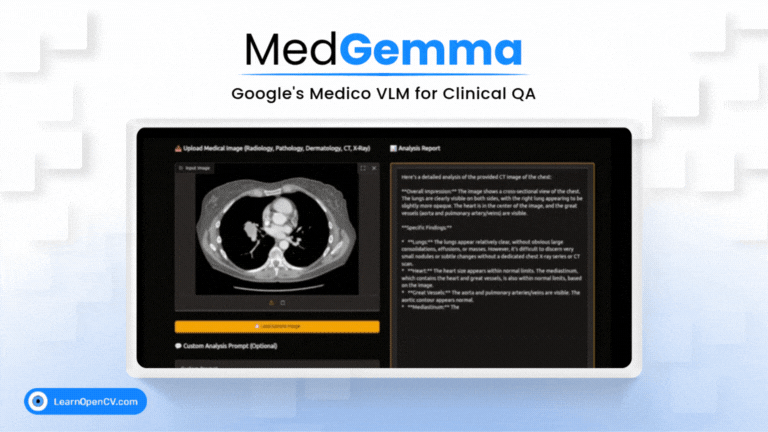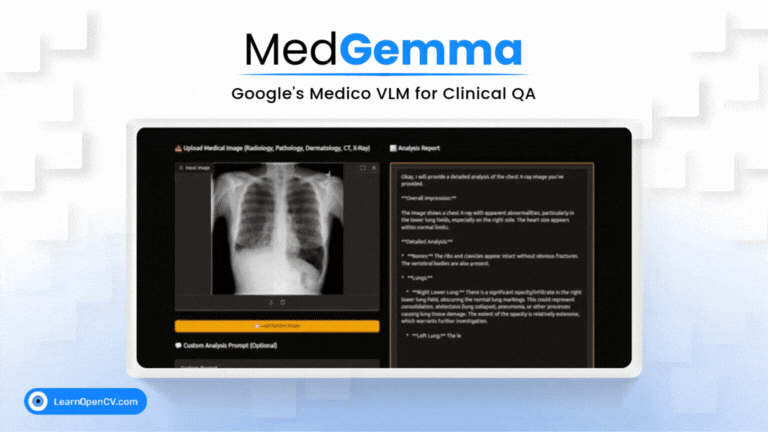
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for
The domain of video understanding is rapidly evolving, with models capable of interpreting complex actions and interactions within video streams. Meta AI’s VJEPA-2 (Video Joint Embedding Predictive Architecture) stands out
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride
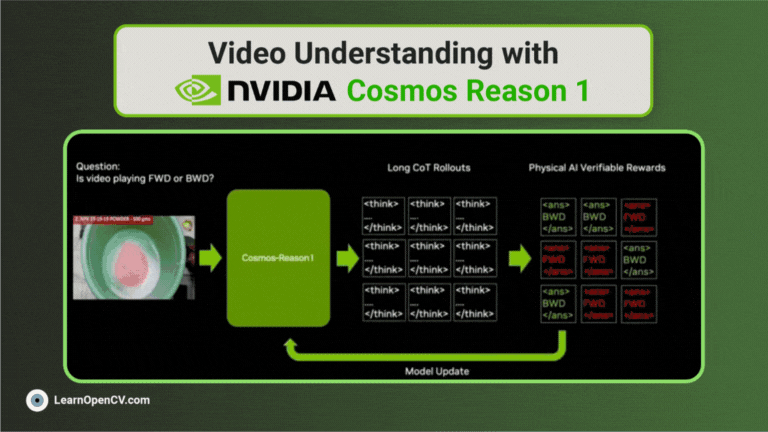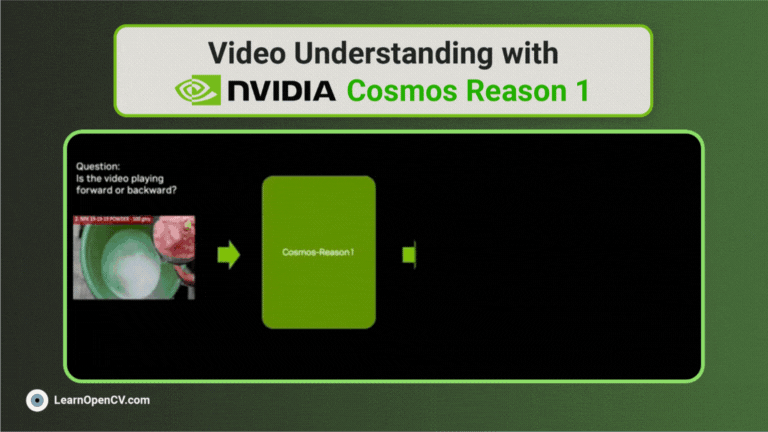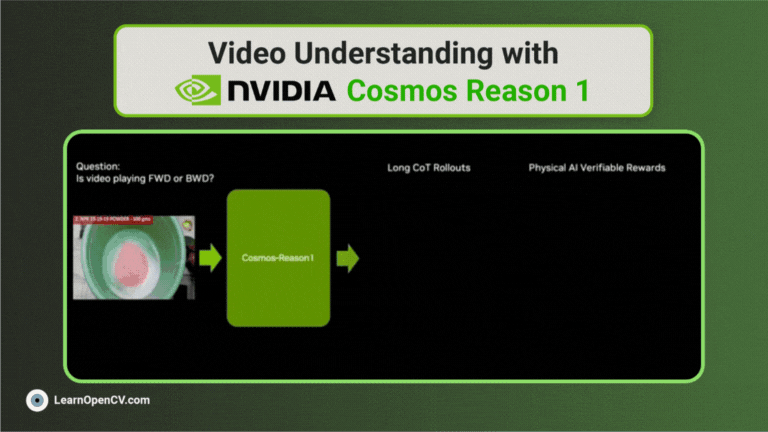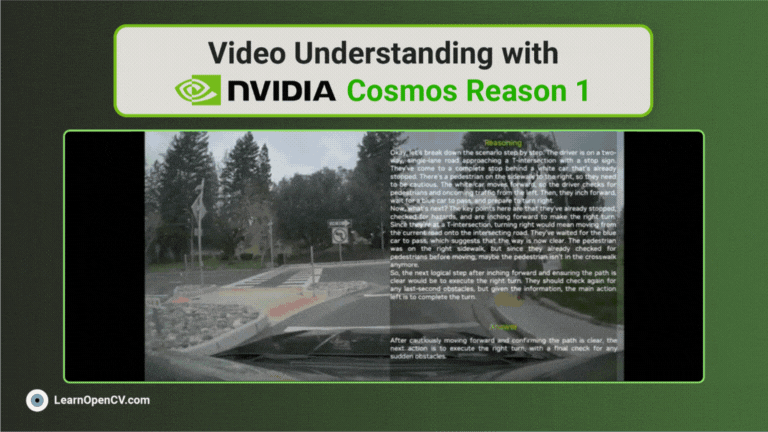
NVIDIA’s Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender
Dive into NVIDIA's GR00T N1.5, a groundbreaking open foundation model poised to revolutionize humanoid robotics! Discover how this advanced Vision-Language-Action (VLA) model, with its smarter architecture and innovative training using
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the
Imagine you’re a robotics enthusiast, a student, or even a seasoned developer, and you’ve been captivated by the idea of robots that can see, understand our language, and then act on that
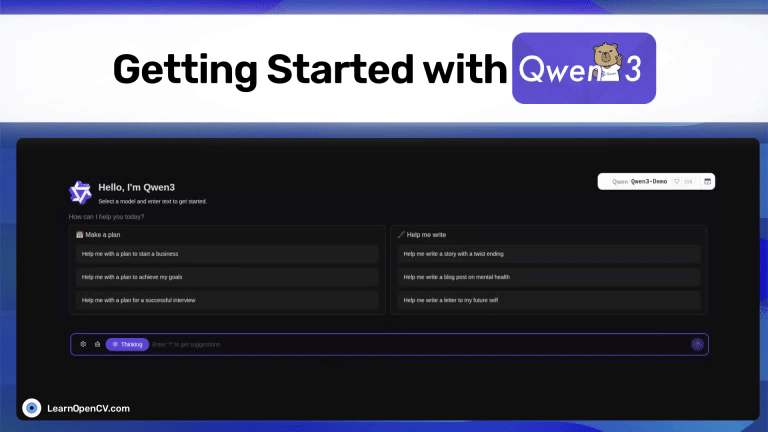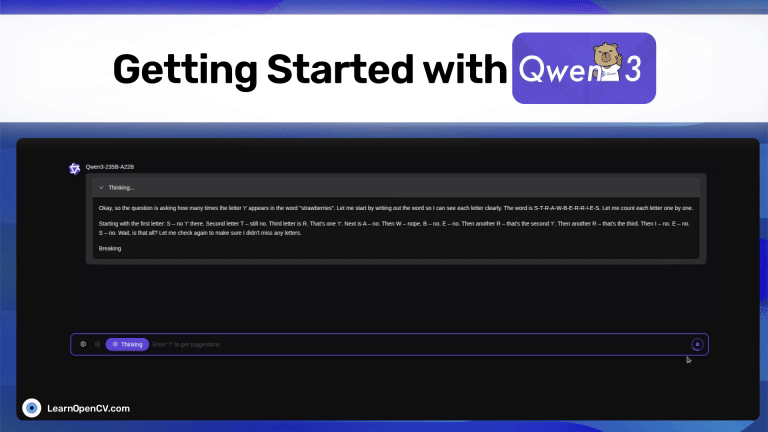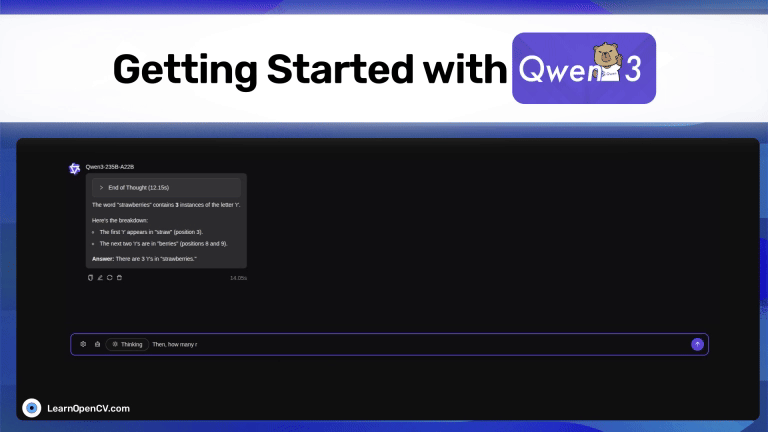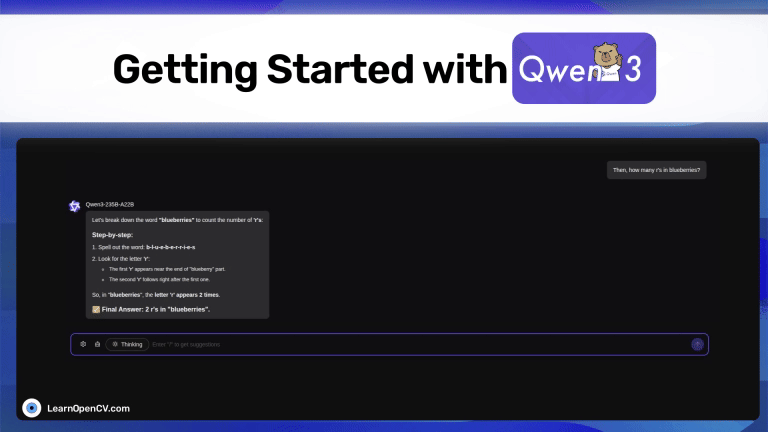
Discover Qwen3, Alibaba’s open-source thinking LLM. Switch between fast replies and chain-of-thought reasoning with 128 K context, and MoE efficiency. Learn how to use and Fine Tune.
SANA-Sprint: Get high-quality (1024, 1024) AI images in a single step! Learn about this ultra-fast diffusion model transforming image generation & real-time AI.
Ever watched an AI-generated video and wondered how it was made? Or perhaps dreamed of creating your own dynamic scenes, only to be overwhelmed by the complexity or the need