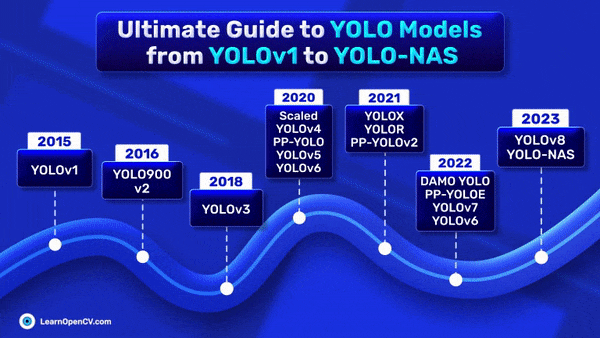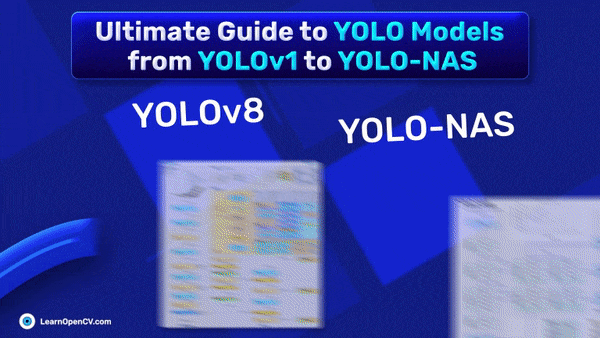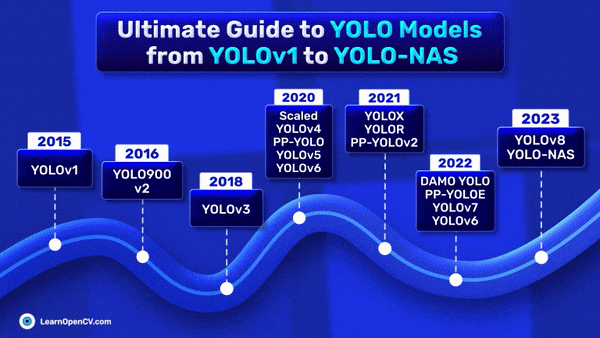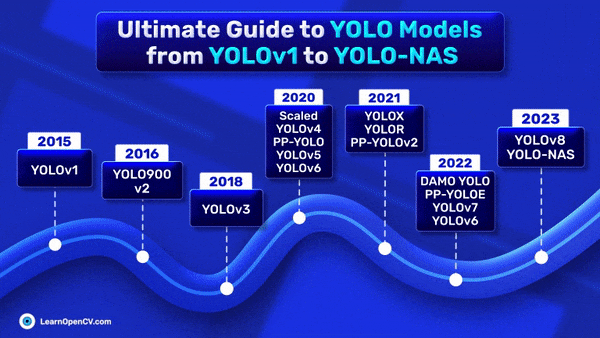
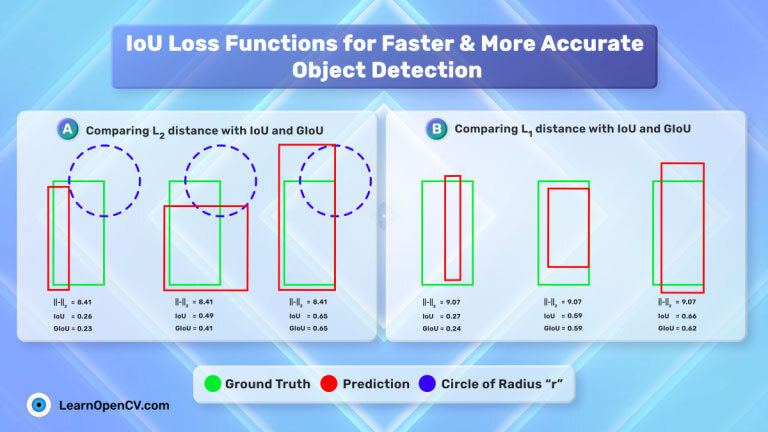
In the preceding article, YOLO Loss Functions Part 1, we focused exclusively on SIoU and Focal Loss as the primary loss functions used in the YOLO series of models. In
The YOLO (You Only Look Once) series of models, renowned for its real-time object detection capabilities, owes much of its effectiveness to its specialized loss functions. In this article, we
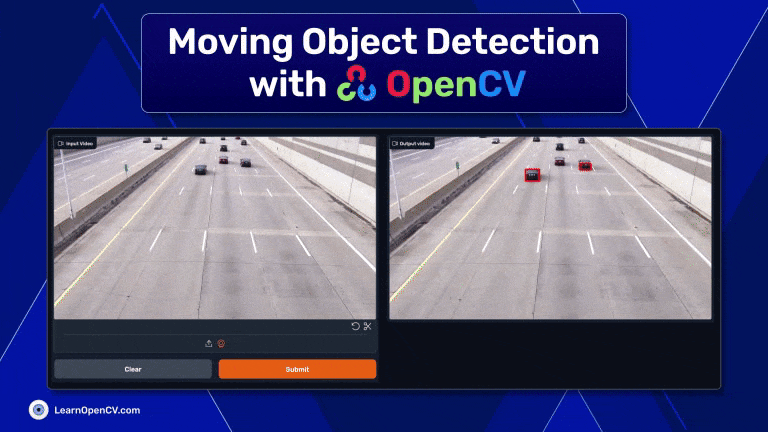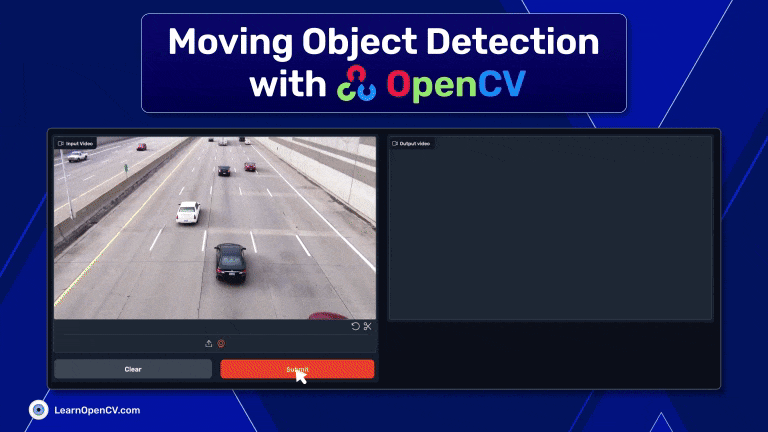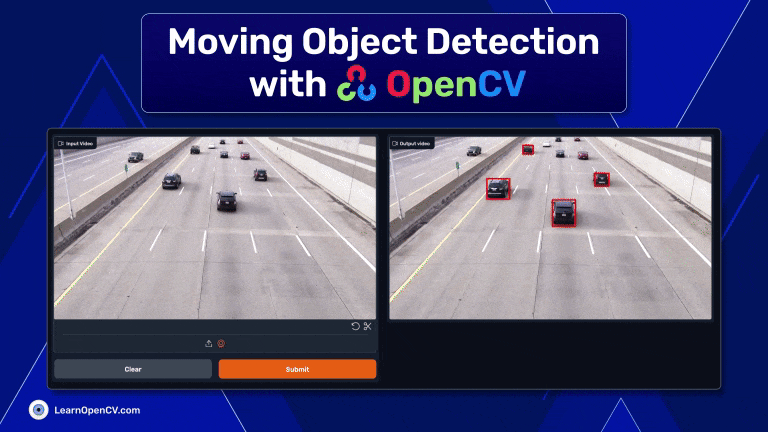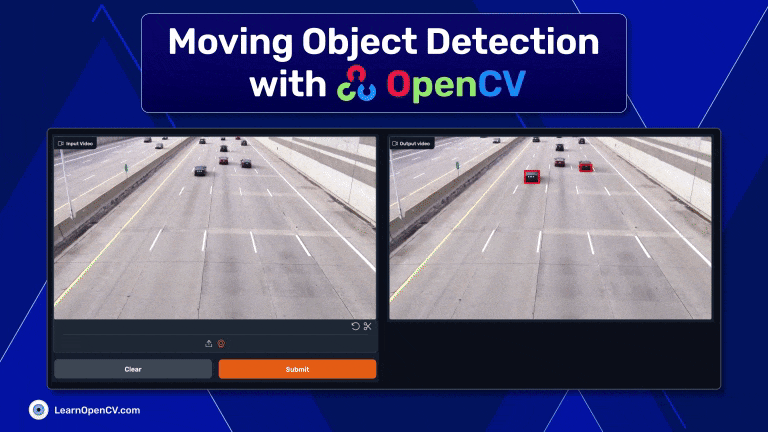
This article has provided a brief overview of moving object detection using OpenCV. We've explored the basics of the library's capabilities like Background Subtraction and Contour Detection and explored how
In this research article, we will fine-tune the ever so famous SegFormer Model from HuggingFace (Enze Xie, Wenhai Wang, Zhiding Yu et al) using the Berkeley Deep Drive dataset to
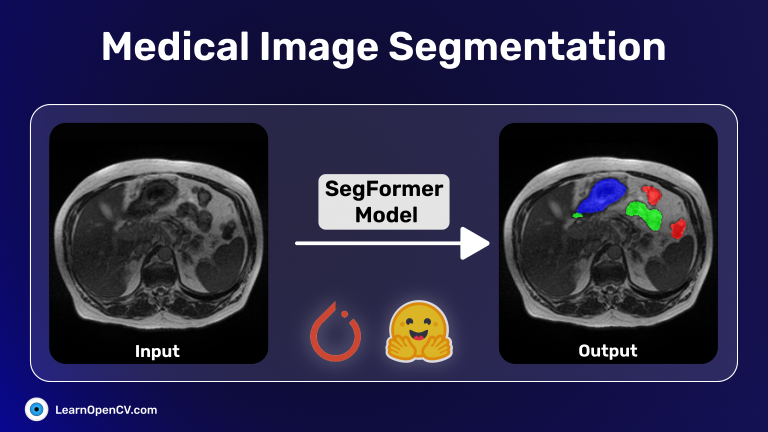
Explore medical image segmentation using the UW-Madison dataset, fine-tune Segformer with PyTorch & HuggingFace transformers, and deploy a Gradio inference app.
PaddlePaddle: Welcome to our guide of machine learning frameworks, where we’ll examine PaddlePaddle, TensorFlow, and PyTorch. Recent benchmark tests have revealed PaddlePaddle as a potential frontrunner, showcasing benchmark speeds that