


The just concluded 2022 was an incredible year for many advances in artificial intelligence. Most of the recently celebrated landmarks in AI have been driven by a particular class of models called transformers, be it the incredible advances by chatGPT, which took the world by storm, or stable diffusion, which brought science fiction-like capabilities to your smartphone. Even Tesla’s self-driving software stack, perhaps the world’s most widely deployed deep learning system, uses transformer models under the hood (pun intended). The “neural attention mechanism” is the secret sauce that makes transformers so successful on a wide variety of tasks and datasets.
This is the first in a series of posts about vision transformers (ViTs). In this article, we will understand the attention mechanism and review the evolution of ideas that led to it. Next, we will understand it intuitively. We will solidify the intuitive understanding with mathematical details and finally translate this understanding into code by implementing the attention mechanism in the PyTorch framework from scratch. Although we will specialize in vision transformers towards the end of the article, much of the discussion is equally applicable to large language models (LLMs) such as GPT-3 and the recently released chatGPT model.
- Introduction to Neural Attention
- Intuitive Explanation of Neural Self Attention Mechanism
- Multi Headed Self Attention
- Mathematical Formulation of Self Attention Mechanism
- PyTorch Implementation of Self Attention
- Summary
Introduction To Neural Attention
To get the best intuitive understanding of self-attention, we need to quickly review the landscape of natural language processing(NLP) architectures over the last decade. We will keep this discussion self-contained, and no familiarity with the field of NLP will be required. Our main focus here is the evolution of ideas rather than the exact mathematical details of each architecture. With this in mind, let us review the flow of ideas in NLP.
Recurrent Neural Networks
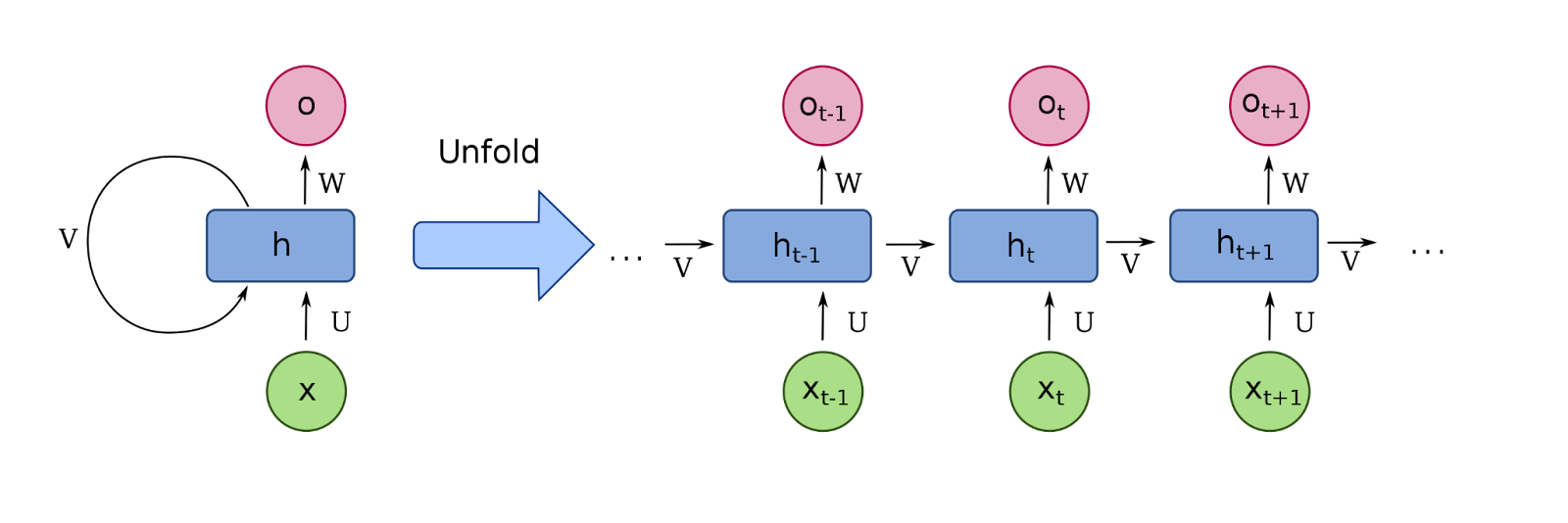
It has been well appreciated in machine learning literature that sentences in natural language are sequences, and thus models that can work with sequences are better suited to NLP tasks than ‘stateless’ models such as the vanilla fully connected deep neural network. Therefore, the recurrent block was proposed, whose schematic is shown in figure 1. The basic idea is that sentences can be processed in the deep neural network, word by word such that a representation of the previous word is injected into the hidden layers of the current word. This allows RNNs to explicitly incorporate the temporal nature of the data into the model.
Although the motivating idea behind RNNs was quite profound, their mathematical formulation was such that they could not model long sequences. RNNs model sequences as multiplicative interactions between hidden representations of words. Thus, trying to model long sequences led to exploding and vanishing gradients. A modification in the design of RNN was required to stabilize training.
Long Short Term Memory Networks

Long short term memory networks or LSTMs modified the architecture of vanilla RNNs to stabilize training. Professor Schmidhuber with his colleagues proposed LSTMs by specifically studying the shortcomings of RNNs. Conceptually, the key innovation in LSTMs was to replace multiplicative interactions from RNNs with additive interactions. Thus, the gradient values are not attenuated during backpropagation since they are distributed additively rather than multiplicatively.
Therefore, in LSTMs the magnitude of gradients does not explode or vanish, and as a result, long sequences can be modeled. As experts in computer vision, you may have noticed that the same idea of additive interactions was used by He et al. for designing ResNets, which were called residual blocks. Here, we see the first evidence of the same idea being used to improve NLP and computer vision models. This trend got a definitive boost with the design of vision transformers, as we will see in the next article of this series.
Although LSTMs improved upon RNNs, the problem of modeling very long sequences remained. Further, LSTMs just like vanilla RNNs, process words sequentially i.e. one after the other. Thus, inference on long sequences is slow.
Neural Self Attention Mechanism
While LSTMs are designed to solve the mathematical deficiencies of RNNs, the neural self attention mechanism (or simply attention mechanism) goes back to the drawing board and rethinks the motivation behind RNNs from the beginning. While it is true that sentences are sequences of words, humans don’t process words sequentially, one after the other, but rather in chunks. Further, some words are highly relevant for predicting the next word, but most are not.
An LSTM is forced to process all words sequentially regardless of their relevance, which restricts what the model can learn. Is there a mechanism by which we can allow the model to incorporate the relevance of specific words within itself?
In other words, which previous words should we pay attention to when predicting the next word? This is the motivating question behind the origin of the attention mechanism. It turns out that the answer is not only relevant for language models but also led to the development of ViTs.
Intuitive Explanation of Neural Self Attention Mechanism
Rather than sequences, the attention mechanism processes inputs as chunks without any explicit temporal connection. Let us see how it works step by step in the context of modeling the next word in a sentence.

Step 1, Query, key value: Much like RNNs, each word in the sentence ‘emits’ a hidden representation of itself. To allow the mechanism to model relevance, we let each word ask questions and receive answers.
When the question asked by a word matches the answer sent by another word, we will interpret this as the two words having high relevance for each other. A word asks the same question to all words in the sequence using the ‘query’ vector. Similarly, it provides the same answer to all words using the ‘key’ vector.
In the most commonly used variant of the attention mechanism, a separate ‘value’ vector is also used to allow the model to combine the outputs of query and key vectors non-linearly. This increases the expressivity of the model. All three types of vectors are outputs of their separate dense layers, and all three types have the same size, say, d. To summarize, in step 1 of the attention mechanism, as shown in figure 3, each word in the sentence emits three separate representations of itself, called the query Q, key K, and value V vectors using three separate dense layers.

Step 2, Computing the Attention Matrix: If we are modeling a sentence with N words, then after step 1, we have N query, N key and N value vectors. So, how exactly does a word ask questions and get answers? This is done by the attention matrix, which is the core of the attention mechanism. We take the dot product of all the N query vectors with all the N key vectors, as shown in figure 4. Since the dot product of two vectors (no matter how large) is just a number, the result of these NxN dot products is an NxN matrix 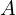 , whose each element
, whose each element 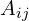 is the dot product of the i-th query vector with the j-th key vector. There are three important things to note here:
is the dot product of the i-th query vector with the j-th key vector. There are three important things to note here:
- Firstly, since each word interacts with every other word while computing the attention matrix, there is no temporal ordering to the inputs. Thus, the vanilla attention mechanism does not consider the sequential nature of inputs.
- Second, the computational complexity of calculating the attention matrix is
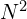 . Thus, if we want to model a sentence with twice the number of words, it will take 4x the computational resources. This will become important in the next part of this series when we build the vision transformer model.
. Thus, if we want to model a sentence with twice the number of words, it will take 4x the computational resources. This will become important in the next part of this series when we build the vision transformer model. - Thirdly, we note that the ‘self’ in self attention refers to the fact that we also take the dot product of a given word’s query with its own key vector. There are some early variants of the attention mechanism which skip computing self relevance, resulting in output with NxN – N elements (all the diagonal elements of the matrix are missing). However, the self attention variant works best and is highly parallelizable on modern GPUs. This is where this mechanism gets the name self attention.
Step 3, Normalization And Attention Scores: The attention matrix, as computed above, will contain some large and some small numbers. We will interpret the large numbers as representing high relevance and the small relevance as low relevance.
At this point there are several ways in which we could use this matrix. We could pick out the maximum element in each row using the max pooling operation and use them for further processing. However, this throws away most of the information. Moreover, sometimes a given word may need context from multiple previous words to correctly model the data. Thus, we should maintain expressivity as much as possible. Another important requirement is that however, we choose to use the attention matrix, it should maintain the differentiability of the model since the model needs to be trainable with back propagation.
All these requirements are met by the softmax layer. Thus, we take a row-wise softmax of the attention matrix, resulting in an NxN matrix whose each row is a probability distribution. A small implementation detail here is that before taking the softmax, we divide the attention matrix by the square root of the dimension of each query vector. This acts as a suitable scaling factor to ‘soften’ the resulting probability distribution.
After scaling, the differences between large and small probability values are reduced and gradients can flow relatively equally into multiple word positions. This is similar to how knowledge distillation algorithms incorporate ‘temperature’ into the logits from the teacher model. Just like in the domain of knowledge distillation, scaling the input to softmax by the temperature factor improves gradient flow and allows faster training. We will see in the next post that this is one of the key reasons behind the success of vision transformers.
Step 4, Attend: We take the dot product of the normalized attention scores obtained in the previous step with the value vectors. Mathematically, this is represented as

Since the value vector V was obtained for each word using a dense layer, the output of the attention mechanism has N vectors, the same as the number of input words. Finally, to obtain the output of the self attention layer, we transform the h vector into the same size as the input with a dense layer. In the above equation, the circular symbol represents the dot product, not the matrix multiplication. In terms of matrix multiplication, the operation could depend on how the query and key vectors are shaped. We will make the notation more concrete in the coming section.
Multi Headed Self Attention
You are likely quite familiar with convolutional networks. The convolution operation is the fundamental building block of CNNs. Similarly, the self attention mechanism introduced above is the fundamental building block of all transformer models, both large language models, and vision transformers.
Continuing with the analogy, one would never design a convolutional layer with just one convolution filter since one filter is insufficient to model the complexity in natural images. Indeed it is quite common to see convents with >500 convolutional filters in one layer. Similarly, one single attention layer, as described above is insufficient to model all the complexities of natural language.
Therefore, we apply multiple attention blocks, called ‘heads’ in parallel to the same sequence. The resulting layer is called Multi Headed Self Attention (MHSA). The difference from convolutions is that one attention head is much more expressive than a single convolution filter. Thus, we don’t need to use ~500 attention heads, but just a few dozen would do. Some common choices for the number of attention heads in ViTs are 12, 24, and 32. Another difference from convolutions is that in CNNs the number of filters increases in each subsequent layer, while the number of attention heads in the most popular ViTs is usually constant, say 12.
To summarize, the self attention mechanism goes beyond dense layers, convolutional layers and LSTM cells and proposes an entirely new general computing mechanism to model relationships in the data. In NLP, the data has a sequential nature but in computer vision, it may not. Yet, in the next part of this series, we will see that vision transformers built using the attention mechanism work quite well for computer vision applications.
Some notes: Our goal in this series of posts is to introduce vision transformers. So far, we have used examples from natural language processing to motivate the introduction of the self attention mechanism. However, from now on, we will depart from NLP and specialize to vision transformers. There are subtle differences in how MHSA is used in computer vision (CV) v/s NLP. In particular, two notable differences at this stage are:
- Vision transformer models do not generally use masked attention (except for self supervised learning)
- Vision transformer models do not use cross attention (except for object detection models like DETR)
We will introduce these variations at appropriate times as we progress through this series, but for now, please be aware that there are variants out there and the rest of this blog post will only cover the most commonly used version of MHSA used in vision transformers.
Mathematical Formulation of Self Attention Mechanism
Let us formulate the single headed attention mechanism in mathematical terms.
Consider an image that has (somehow) been split up into a sequence of patches 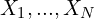 , where each
, where each 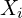 is a flattened vector of dimension
is a flattened vector of dimension  . The exact method of splitting the image into patches is not important here. Let us construct the matrix
. The exact method of splitting the image into patches is not important here. Let us construct the matrix 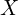 such that the first dimension is the length N and the second dimension is . As explained earlier, we will use dense layers to get the query, key, and value representations. However, these dense layers will be used without any bias term and no activation function, so that the dense layers are just simple matrix multiplications. The parameters for the three layers are then WQ , WK, WV for query, key, and value, respectively such that WQ, WK, WV
such that the first dimension is the length N and the second dimension is . As explained earlier, we will use dense layers to get the query, key, and value representations. However, these dense layers will be used without any bias term and no activation function, so that the dense layers are just simple matrix multiplications. The parameters for the three layers are then WQ , WK, WV for query, key, and value, respectively such that WQ, WK, WV 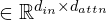 . Another dense layer with weights
. Another dense layer with weights  and bias
and bias  are also used. Let us perform the computation as explained intuitively in the previous section.
are also used. Let us perform the computation as explained intuitively in the previous section.
Step 1: The query, key and value matrices (these are matrices because we compute the vectors for all words in the sequence in one step) are computed as:
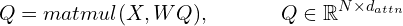
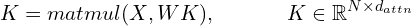
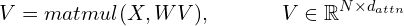
Here, 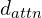 is a hyperparameter which is the dimension of the key, query, and value vectors. Typically, is much smaller than .
is a hyperparameter which is the dimension of the key, query, and value vectors. Typically, is much smaller than .
Step 2: The attention matrix is computed as
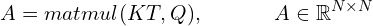
Note that the single matmul operation computes the attention matrix for all words, including the dot product of keys with queries of the same word. Thus, it fully implements the self attention mechanism.
Step 3: The scaling and softmax is implemented as
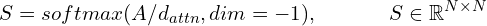
Here, dim=-1 denotes that the softmax is taken across rows and not columns (which wouldn’t be meaningful).
Step 4: The output of the attention is calculated as
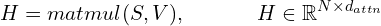
The output of the attention layer is computed as

Thus, the output has the same size as the input.
Although we have formulated only single headed self attention here, the generalization to multi headed version contains multiple independent query, key and value weight matrices and is quite straightforward.
PyTorch Implementation of Self Attention
Now that we have an intuitive and mathematical grasp of the self attention layer, let us implement it in PyTorch. There are a couple of things to note before we start:
- Since a large number of dense layers are used in the self attention mechanism, there is a danger of overfitting. Thus, the dropout layer is generously used in practical implementations of MHSA to avoid overfitting.
- PyTorch has a module called nn.Transformer. This implements the full transformer architecture (encoder and decoder), while we will implement only a part of the model (encoder only).
Einops layers: Einops is a fantastic library for tensor manipulation, reshaping, and resizing. Rather than using torch.reshape, we can use Rearrange layer from einops which has a much nicer API and integrates seamlessly with PyTorch, TensorFlow, JAX, and numpy. We do not have space to introduce einops here, but if you have never seen einops code before, worry not since it is very readable and works exactly as you might guess intuitively.

With this in mind, let us implement the MHSA layer as a subclass of nn.Module.
from torch import nn
from einops.layers.torch import Rearrange
class MultiHeadedSelfAttention(nn.Module):
def __init__(self, indim, adim, nheads, drop):
'''
indim: (int) dimension of input vector
adim: (int) dimensionality of each attention head
nheads: (int) number of heads in MHA layer
drop: (float 0~1) probability of dropping a node
Implements QKV MSA layer
output = softmax(Q*K/sqrt(d))*V
scale= 1/sqrt(d), here, d = adim
'''
super(MultiHeadedSelfAttention, self).__init__()
hdim=adim*nheads
self.scale= hdim** -0.5 #scale in softmax(Q*K*scale)*V
self.key_lyr = self.get_qkv_layer(indim, hdim, nheads)
#nn.Linear(indim, hdim, bias=False)
#there should be nheads layers
self.query_lyr=self.get_qkv_layer(indim, hdim, nheads)
self.value_lyr=self.get_qkv_layer(indim, hdim, nheads)
self.attention_scores=nn.Softmax(dim=-1)
self.dropout=nn.Dropout(drop)
self.out_layer=nn.Sequential(Rearrange('bsize nheads indim hdim -> bsize indim (nheads hdim)'),
nn.Linear(hdim, indim),
nn.Dropout(drop))
def get_qkv_layer(self, indim, hdim, nheads):
'''
returns query, key, value layer (call this function thrice to get all of q, k & v layers)
'''
layer=nn.Sequential(nn.Linear(indim, hdim, bias=False),
Rearrange('bsize indim (nheads hdim) -> bsize nheads indim hdim', nheads=nheads))
return layer
def forward(self, x):
query=self.key_lyr(x)
key=self.query_lyr(x)
value=self.value_lyr(x)
dotp=torch.matmul(query, key.transpose(-1, -2))*self.scale
scores=self.attention_scores(dotp)
scores=self.dropout(scores)
weighted=torch.matmul(scores, value)
out=self.out_layer(weighted)
return out
The constructor takes these arguments:
- The size of each input.
- The size of the attention layers
- The number of attention heads, and
- The probability of dropout
Step 1: The function get_qkv_layer is used to get dense layers for query, key and value vectors for all attention heads simultaneously. Naively, this would be implemented in a for loop with one iteration for each attention head. However, batching multiple matrix multiplication operations into one reduces latency and allows better CUDA occupancy. The Rearrange layer from the einops library reshapes the QKV matrices such that the head dimension is next to batch dimension.
Step 2: The attention matrix is then calculated as a matul of query and key after transposing the key matrix along its last two dimensions, precisely as explained in sections 2 and 3.
Step 3: The attention matrix is scaled by the square root of the attention dimension and subsequently, softmax is taken to get the attention score matrix. The score matrix is followed by a dropout layer to prevent overfitting.
Step 4: The score matrix is used to calculate the weighted sum of the value matrix. Finally, the einops Rearrange layer combines all the attention heads into one and a linear layer is used to transform the output of the attention layer into the same shape as the input. Dropout is applied once again to prevent overfitting.
4.1 Basic Results
The MHSA layer we have introduced is just a building block used in transformer models. We cannot use it to do much except to verify its own working. We pass an input x through an MHSA layer and verify that the output has the same shape as the input. We will use this layer in the next part of this series to build a vision transformer model.

Summary
This blog post lays the foundation of transformer models, particularly vision transformers. Most recent advances in machine learning have transformers at their core and transformers have the multi headed self attention layer at their core. Therefore, understanding the attention mechanism intuitively and mathematically will be critical for your future projects and career.
We started by reviewing the core concepts behind recurrent networks and LSTMs. Their successes and deficiencies allowed us to understand where attention fits and what it does differently from earlier models.
Next, we understood the intuitive mechanism behind the attention layer. We went step by step through the calculation of queries, keys, values, attention matrix, scores, and finally, the output of the attention layer. Having gained an intuitive understanding, we formalized these concepts into concrete mathematical form.
Finally, we translated the mathematical and intuitive understanding into PyTorch code which implements the Multi Headed Self Attention layer.
Now that we have built the foundation, we can easily understand vision transformers in the next part of this series. We hope to see you there.


