

Face Recognition is a computer vision technique which enables a computer to predict the identity of a person from an image.
This is a multi-part series on face recognition. This post will give us a 30,000 feet view of how face recognition works. We will not go into the details of any particular algorithm but will understand the essence of Face Recognition in general.
This article is targeted toward absolute beginners. If you have difficulty understanding a concept, I have failed and would be happy to clarify your questions in the comments section and update the post accordingly.
1. Face Recognition vs. Face Verification
Many people think of Face Recognition and Face Verification as different problems, and many think of them as the same. The answer is that idea behind both is the same; just the application area is different.
Face Verification, as the name suggests, tries to authenticate a person. For example, you can unlock your smartphone using your Face, but others can’t. It is a 1:1 comparison.
A Face Recognition system ( a.k.a Face Identification ) looks for a person in a database of known people and tries to predict who the person is. It is a one-to-many comparison. If the person is not present In the database, It means we have never seen this person before. So you may either add them to the database or simply say that he/she is an unknown person. This can be used in applications like Surveillance, Attendance system, etc.

In short, Face Verification answers: Is this PersonX? Whereas, Face Recognition answers: Who is this person?
2. Face Recognition: Basic Intuition and History
How do humans recognize faces? We do not analyze each and every pixel of an image. We try to identify unique features on the face and compare it with someone we already know. For example, we can look at the upper region of the face and tell if it is Donald Trump or not. Isn’t it? If we don’t know the person yet, we try to remember the unique features of the person until next time.

Can a computer do the same? It cannot just compare two image parts. Even sight change in viewpoint or illumination is enough to ruin the comparison result if you compare raw pixel intensities. The computer needs something more meaningful and robust as a comparison metric.
Taking inspiration from the human visual system, Computer Vision researchers have tried to come up with different features to efficiently describe the uniqueness of each person’s face. The simplest of features can be the mean and variance of face pixel intensities, the ratio of height: width of the face, etc. There are hundreds of published papers that propose different features.

Some notable algorithms like Eigen Faces, Fischer Faces, and LBPH try to apply mathematical tricks ( like PCA, LDA, Histograms, etc ) to represent the face in a more compact form by extracting the most useful information ( features ) from the face and getting rid of redundant information. We have a post on Eigen Faces if you wish to know more about that.
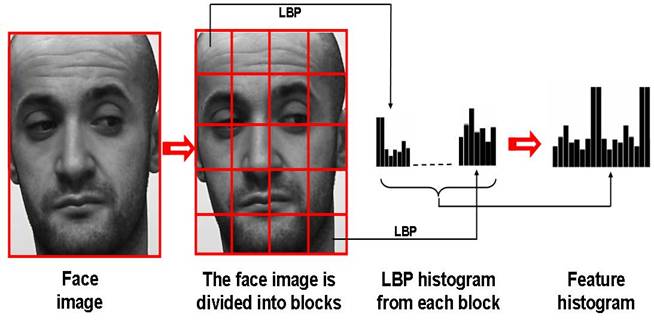
With the advent of Deep Learning, these hand-crafted features have taken a backseat, and researchers have now tasked CNNs with finding the right features for them. We will discuss this approach in more detail in the next sections.
It is all about finding a good set of features to represent the face and then it can be as simple as distinguishing between apples and oranges.
3. Modern Face Recognition using Deep Learning
We need to learn a high-dimensional feature space capable of distinguishing between the faces of different persons. Once we have a trained model, we can generate unique features for each face. Finally, we can compare the features of new faces with that of known faces to identify the person.
In case we want to add a new person to the database of known faces, we generate the features and add it to the database. This process is called Enrolment.
3.1. Training a Face Recognition model
As mentioned above, the most important part in a Face Recognition system is generating a trained model which can differentiate between faces of two different persons. Let’s understand the training process in more detail and discuss the various jargons used in Face Recognition.
Generate Face Representation or Encoding
Convolutional Neural Networks ( CNNs ) are very good feature extractors[1]. They look at small parts of an image and use convolutions over many layers to generate reliable features to distinguish between visually different objects. Please refer to our post on image classification using convolutional neural networks in Keras to know more about CNNs.
The first step is to generate a compact face representation from the input face image. Suppose we have a CNN which takes a face image as input and produces an array of “n” numbers as output. We call this array an Encoding, since the face is now encoded using only this array. We can visualize the case for n=2 as shown below.
The above figure depicts the encodings generated for each image and also shows how they might look in a 2-dimensional feature space ( Generally, n=128 ). The points shown on the graph are called Face Embedding since they are now embedded in a feature space.
For an untrained network, the face embeddings generated for images of the same person ( I1 & I2 ) may or may not be close, as shown in the above figure. It might even be closer to the other person ( J1 ). These embeddings will be generated for each face image in the database.
Learning a Face Embedding Space
The goal of training the model is to learn a nice feature space where the green points are clustered together, close to each other and far from the red points and vice-versa. Thus, all face embeddings of Elon will be close to each other and far from the face embeddings of Mark.

But how does the network learn?
In order to make sense out of anything, we need to tell the network how well it is performing so that it can do better in the next iteration. Thus, we define a Loss metric which acts as an indicator for the network of how well it is able to achieve the task. It is important to note here, what we want to achieve:
- Bring the face embeddings of same person closer.
- Push embeddings of different persons farther.
So, we look at 3 images at a time. Considering our previous example, I1 and J1 are images of different persons with their embeddings as shown. Now, when the network generates the embedding for I2, it comes between I1 and I2. The loss metric should indicate the network to reduce the distance between I1 and I2 and increase the distance between I2 and J1. This is done in the backward pass during training of a Neural Network.

This loss metric is quite rightly termed as the Triplet Loss and is among one of the most widely used loss metric for Face Recognition.
Thus, using CNNs as feature extractor and triplet loss as the loss metric, the network should be able to learn a face embedding space where faces of same person are clustered together and faces of different person are separated.
3.2. Inference – Identify new face images
Once the network is trained and the embeddings are generated for the training images, we can safely use it to predict the identity of a new face.

As seen from the above figure, for a new face image, we get a face embedding using the model. Next, we need to calculate the distance of this face embedding with all other face embeddings in the database. The predicted person will be the one whose embedding is closest to the embedding of the new face.
The most common distance measure used for this comparison is the L2 distance, which is simply the euclidean distance between 2 points in an n-dimensional space.
In this example, we can see that the face embedding generated by the new face image is closer to the red points which belongs to Elon Musk. Thus, we can predict that the new face is also Elon.
3.2a. How to improve Inference time?
There are better ways of doing inference than comparing the new embedding with each one in the database. One can use machine learning techniques to train a model using these face embeddings as input. Let’s briefly discuss two such algorithms.
Support Vector Machines
We can train a multi-class classifier using SVMs with the face embeddings as input. Each class will correspond to a different person. Whenever we want to classify a new face embedding, we can just compare it with the support vectors and predict the class to which the new face belongs.
This will bring down the computation cost to a large extent as you don’t have to compare the new embedding with hundreds or thousands of embeddings in the database. To know more about SVMs, please refer to our post on Support vector machines SVM.
k-Nearest Neighbour (k-NN)
Although the SVM approach is faster, it has a drawback. SVM is a parametric Machine Learning method which means that if a new person is added to the database, the old parameters may not work and thus, we would need to retrain the SVM model. What if there was a non-parametric method? — Yes! The k-NN Algorithm.
The k-nearest neighbor classifier is one of the simplest machine learning algorithms. It does not perform a brute-force computation of distance at inference time. For each new point, it just compares the k- nearest neighbors and employs a majority voting scheme to make a decision.
For example, consider the embeddings as shown below. If we use k = 5, the blue point ( new embedding ) is compared to its neighbors and we take majority voting from 5 of them. 3 of the neighbors vote for the red class and 2 vote for the green class. Thus, the final prediction would be red!

Apart from this, there are extremely fast methods available for k-NN approximation.
3.3. Enrolling a new person
Till now we have seen how the embedding space is generated using the face database. But what happens if we want to add a new person to the database? Do we need to train the model again? — NO. It’s rather simple.
We can just use the same model to create the embeddings for the new person. Since the model is already trained and this is a different person, the embeddings that are generated would be far from that of other persons in the database. We just update the database of known faces accordingly.

Since the database is now updated, we can do inference in the same way as described above.
In our next posts, we will look at state-of-the-art methods for Face Recognition and share code and tutorials. Stay tuned!
References
https://www.researchgate.net/publication/236953573_Face_Recognition_Based_on_Facial_Features
Must Read Articles
| We have crafted the following articles, especially for you. 1. What is Face Detection? – The Ultimate Guide 2. Anti-Spoofing Face Recognition System using OAK-D and DepthAI 3. Face Recognition with ArcFace 4. Face Detection – OpenCV, Dlib and Deep Learning ( C++ / Python ) |





