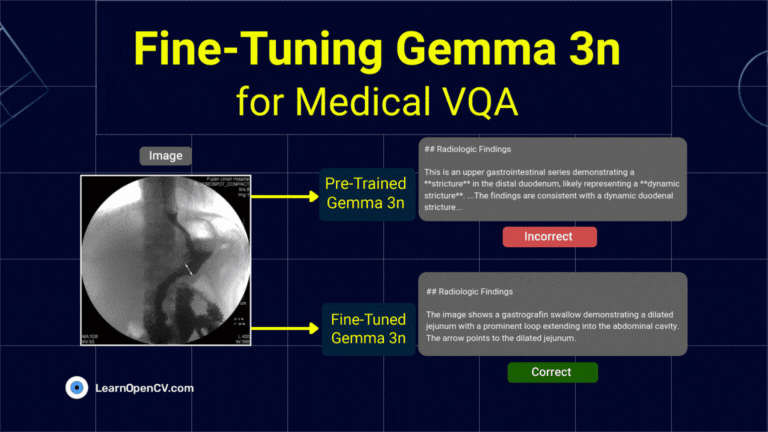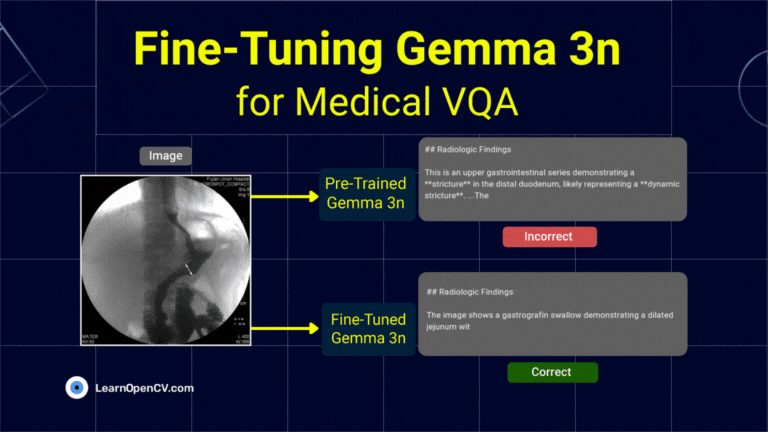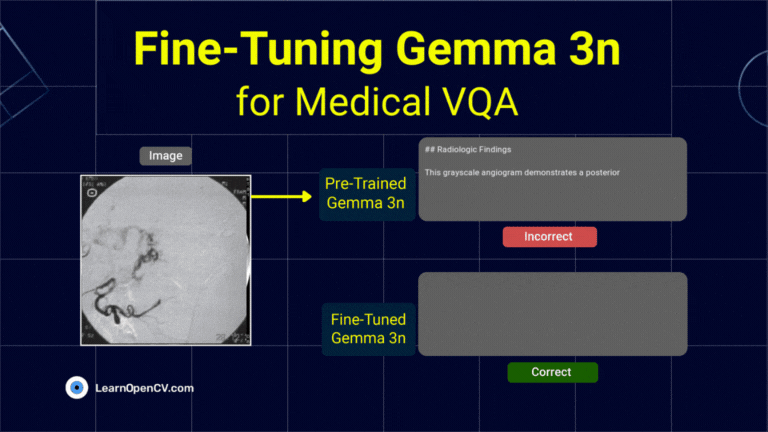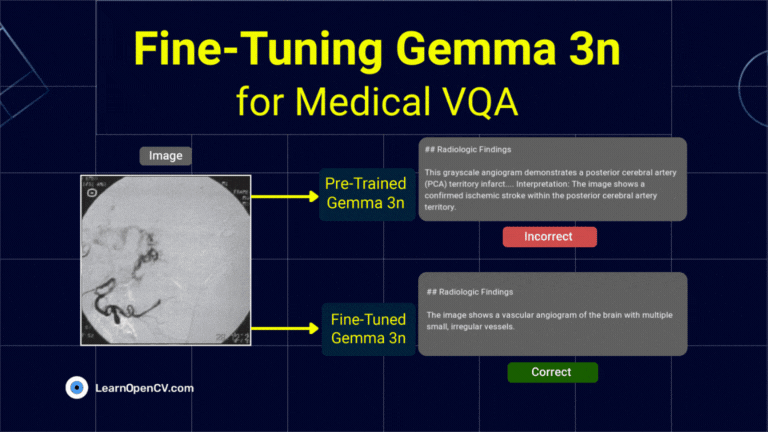
DeepSeek OCR Paper Explanation and Test using Transformers and vLLM Pipeline. Understanding Context Optical Compression and model architecture in depth.
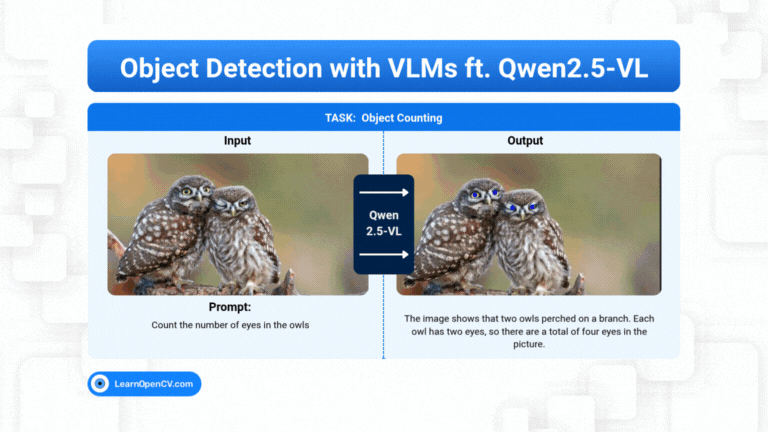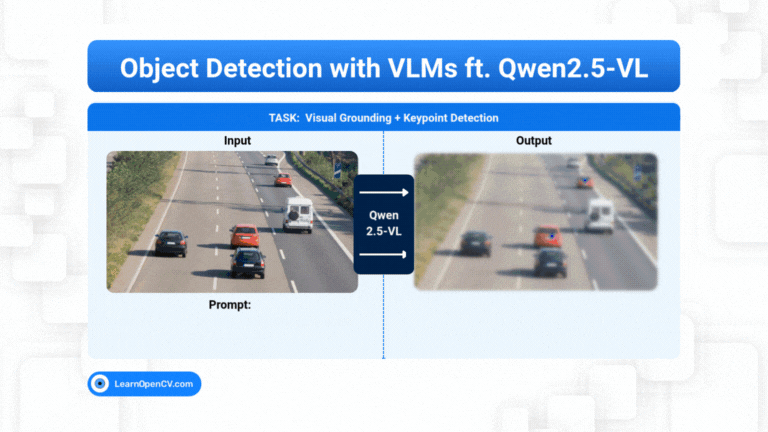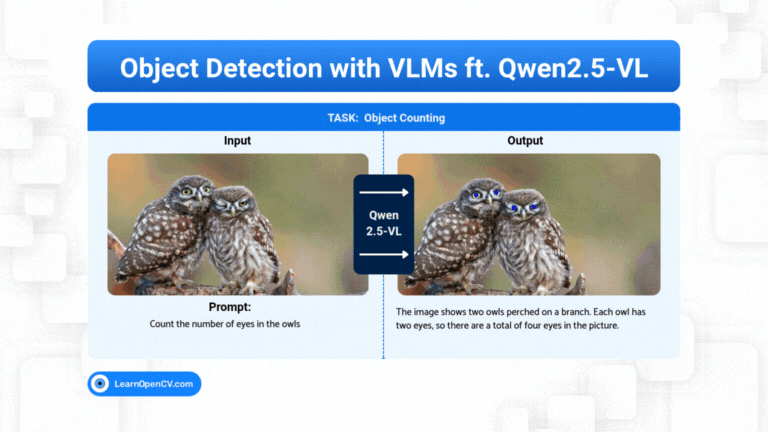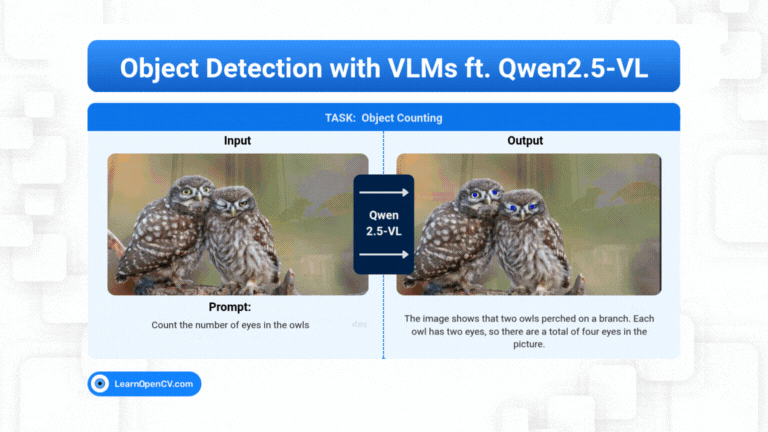
What if object detection wasn't just about drawing boxes, but about having a conversation with an image? Dive deep into the world of Vision Language Models (VLMs) and see how
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
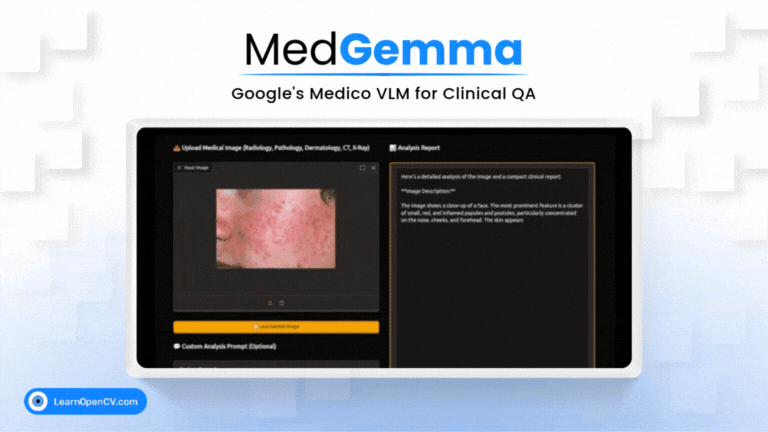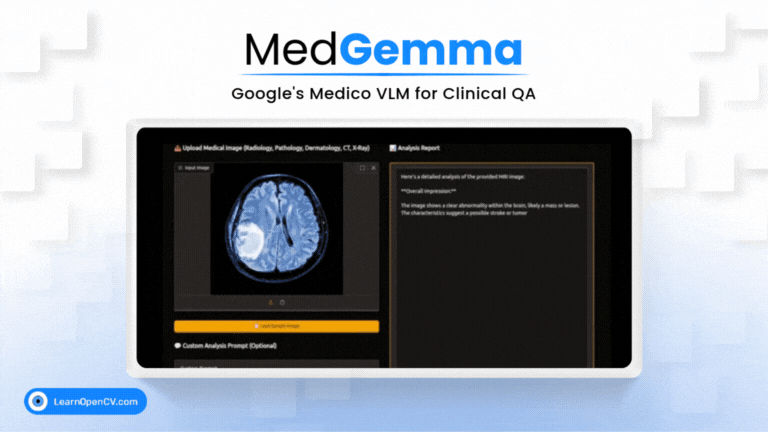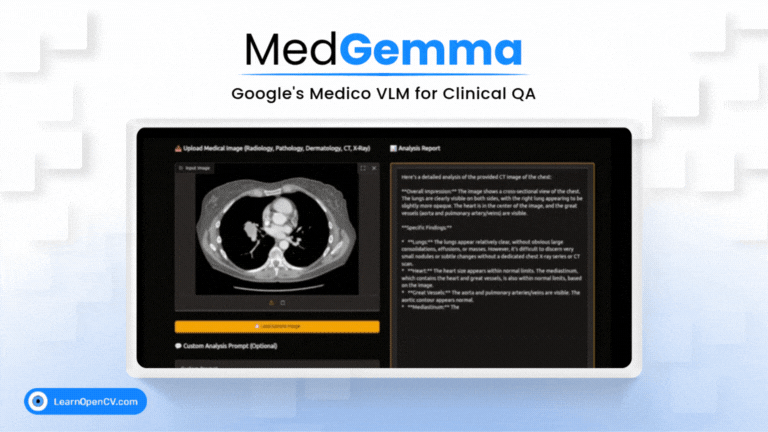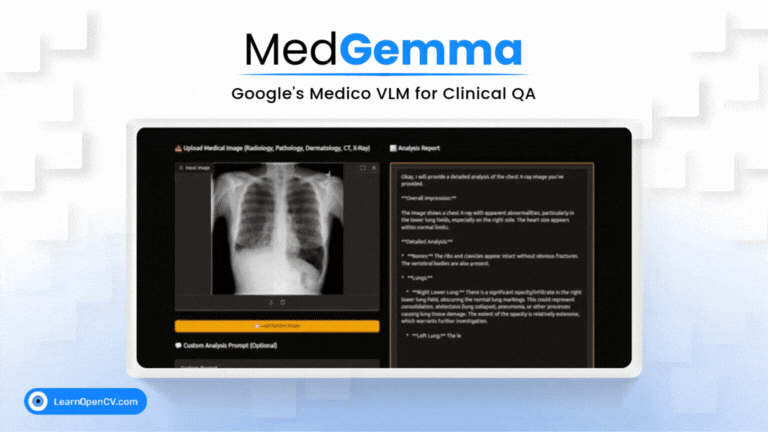
Imagine an AI co-pilot for every clinician, capable of understanding both complex medical images and dense clinical text. That's the promise of MedGemma, Google's new Vision-Language Model specifically trained for
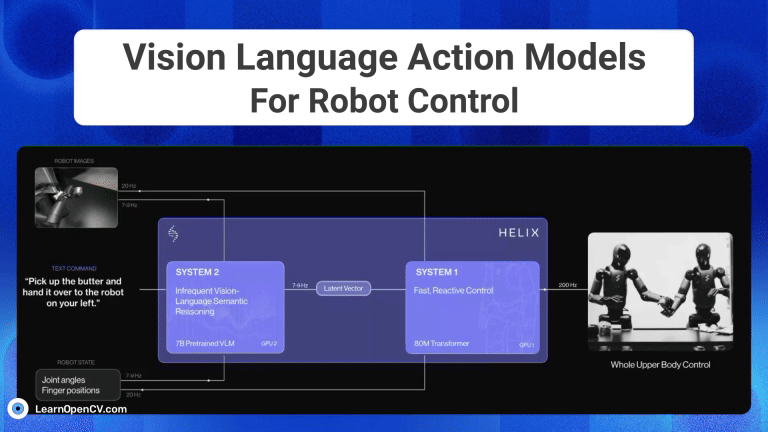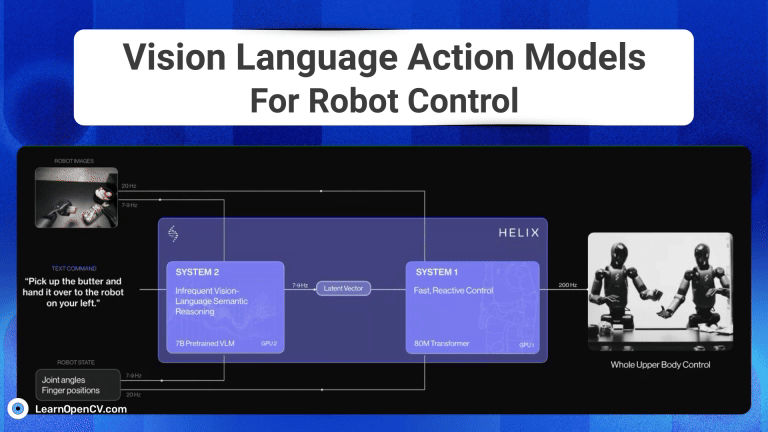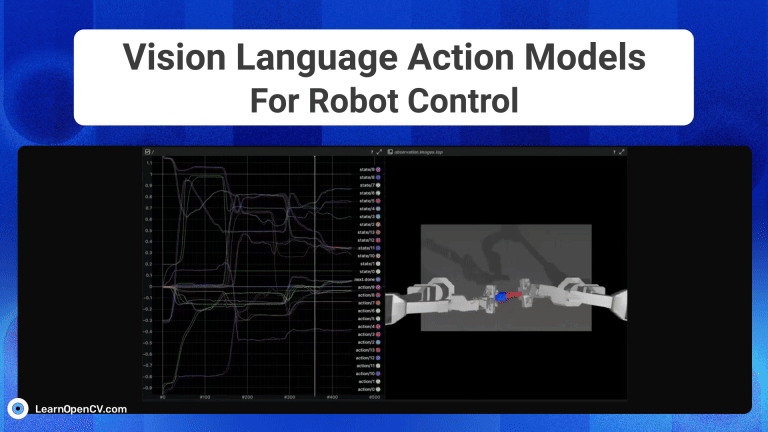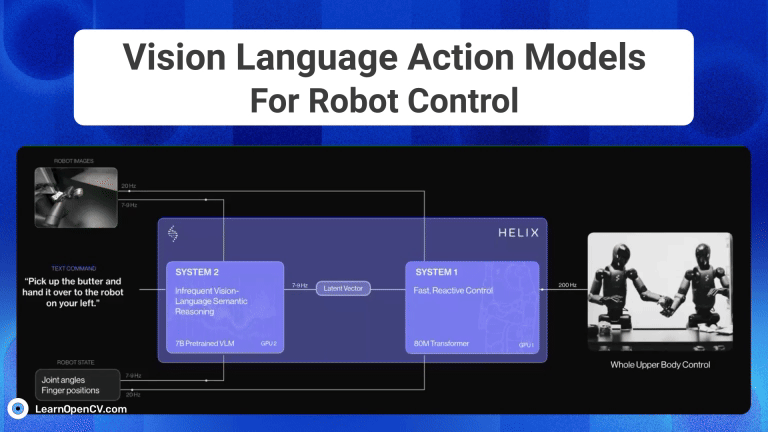
Imagine you’re a robotics enthusiast, a student, or even a seasoned developer, and you’ve been captivated by the idea of robots that can see, understand our language, and then act on that
The advent of Generative AI, has fundamentally transformed robotic intelligence, enabling significant strides in how advanced humanoid robots “perceive, reason and act” in the physical world. This huge progress is