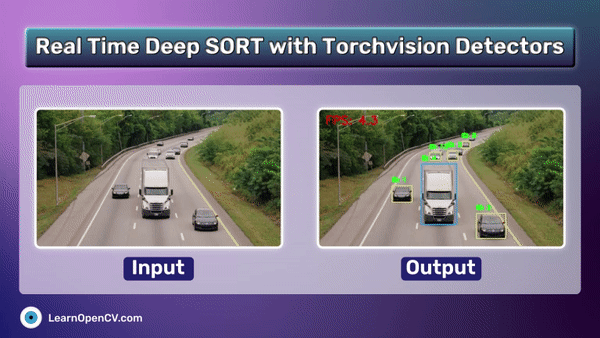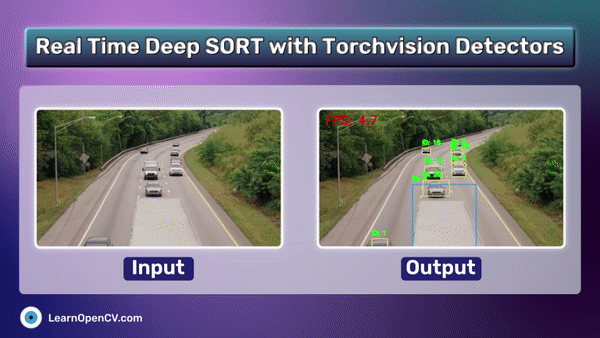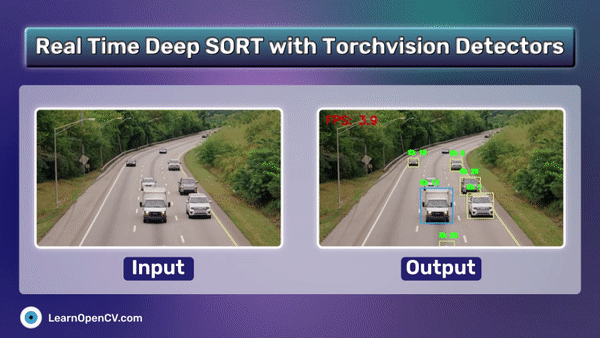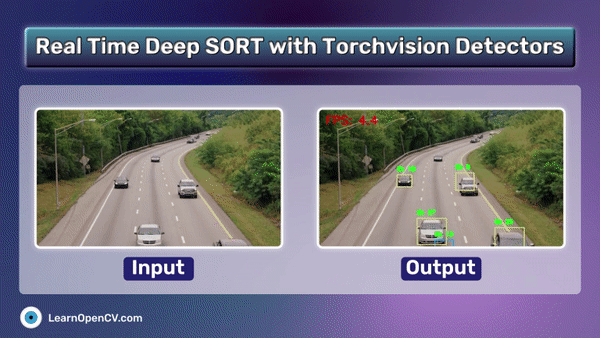
Performing RAG on Unstructured elements that too in complex pdfs like finance, law reports is challenging. ColPali a novel document retrieval approach achieves SOTA results with high quality retrieval. This
Feature matching using deep learning is a game-changer for computer vision tasks like panorama stitching, video stabilization, and face recognition, providing greater accuracy and reliability. Dive into how this technology
YOLOv10 introduces a dual-head architecture for NMS-free training and efficiency-accuracy driven model design. It combines one-to-one and one-to-many label assignments to improve performance without extra computation. YOLOv10 uses lightweight classification
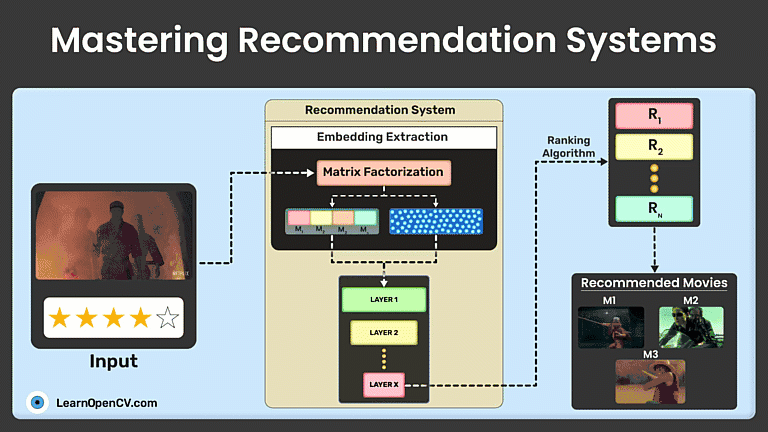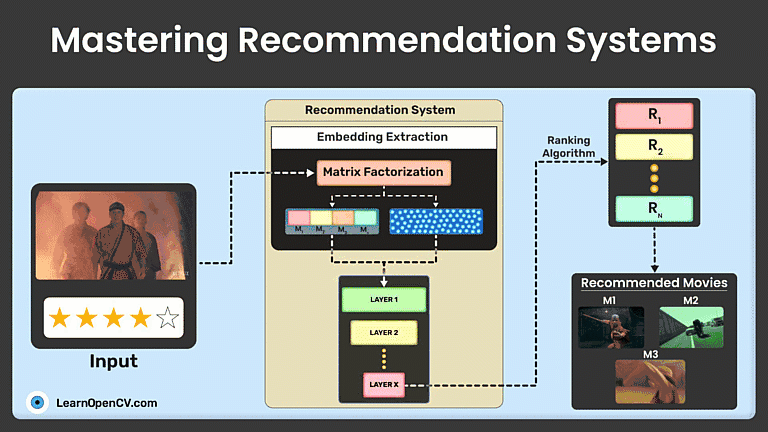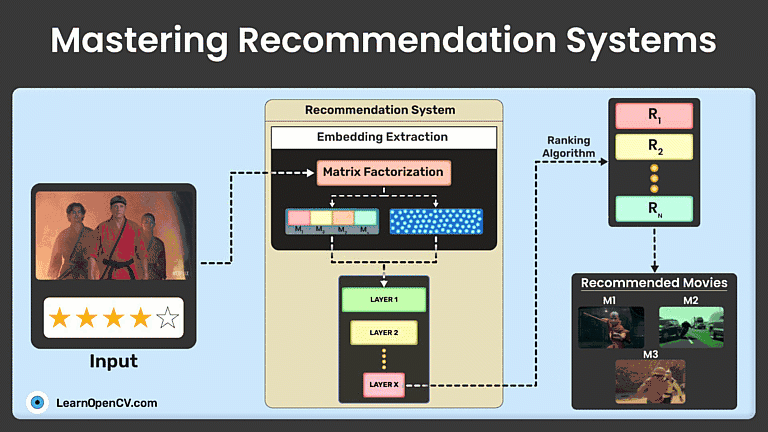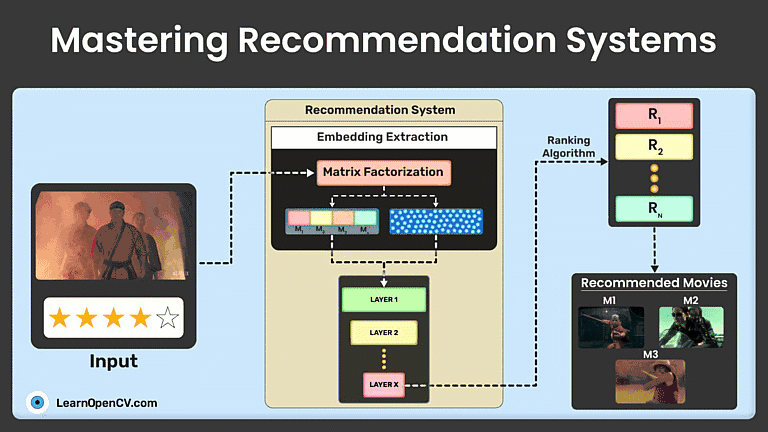
Recommendation systems (recommender systems) suggest content based on user preferences and behaviors. This guide explores their types, traditional ML techniques like matrix factorization, and advanced deep learning methods like neural
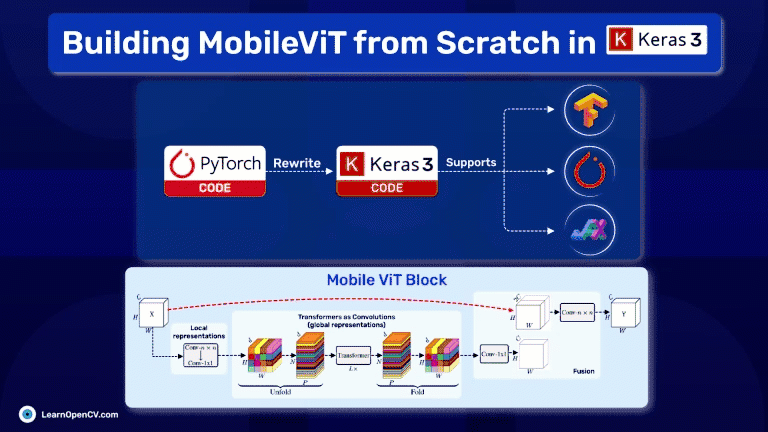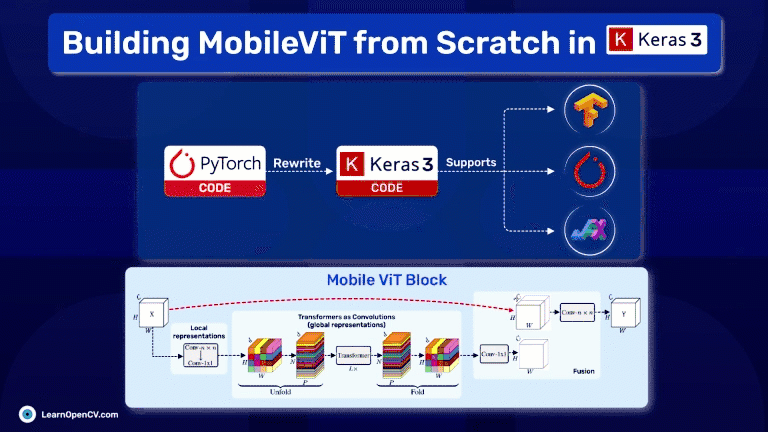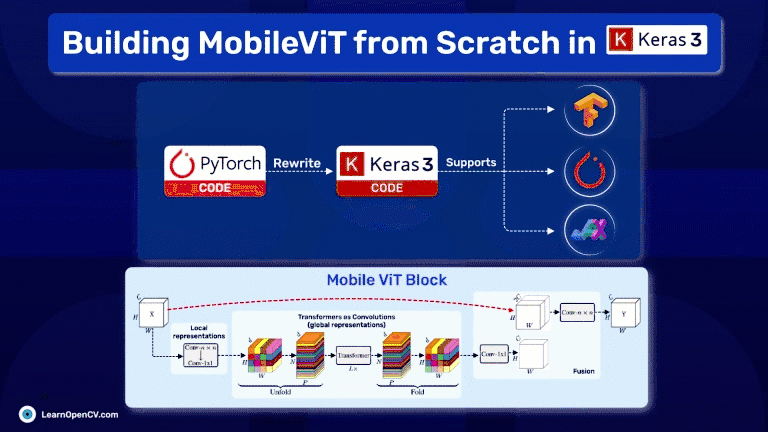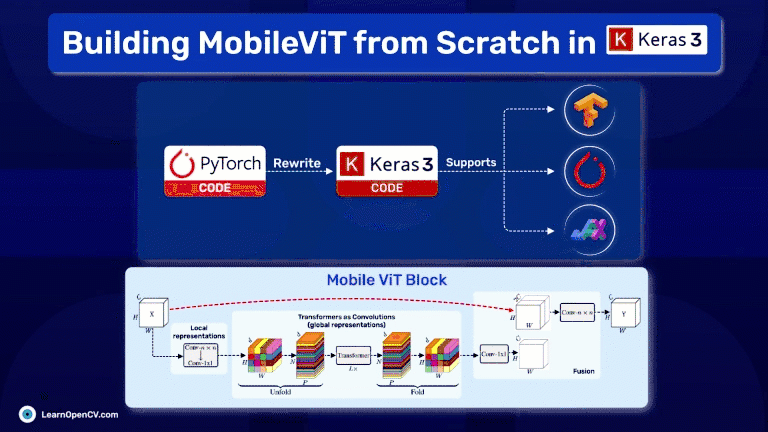
In the rapidly evolving field of deep learning, the challenge often lies not just in designing powerful models but also in making them accessible and efficient for practical use, especially
In the preceding article, YOLO Loss Functions Part 1, we focused exclusively on SIoU and Focal Loss as the primary loss functions used in the YOLO series of models. In
Unveiling a significant breakthrough in computer vision, Deci introduces YOLO-NAS Pose, the latest evolution in Pose Estimation technology. Building on the foundations of the acclaimed YOLO-NAS, this advanced model stands
In this article, we explore the real-time facial emotion recognition using the RFB-320 SSD face detection model and the VGG-13 emotion recognition model.