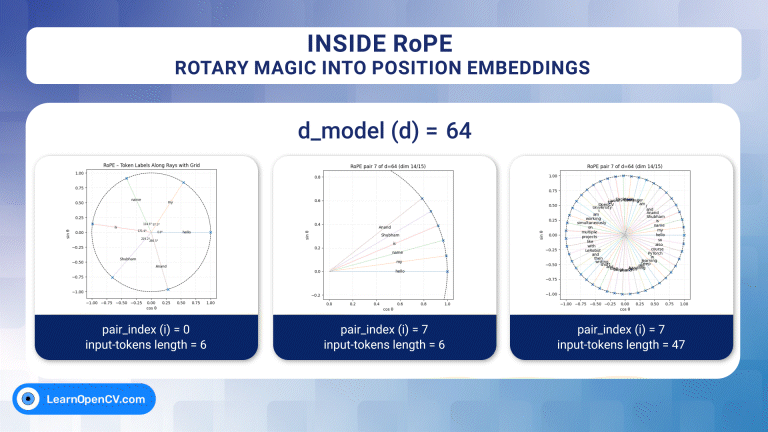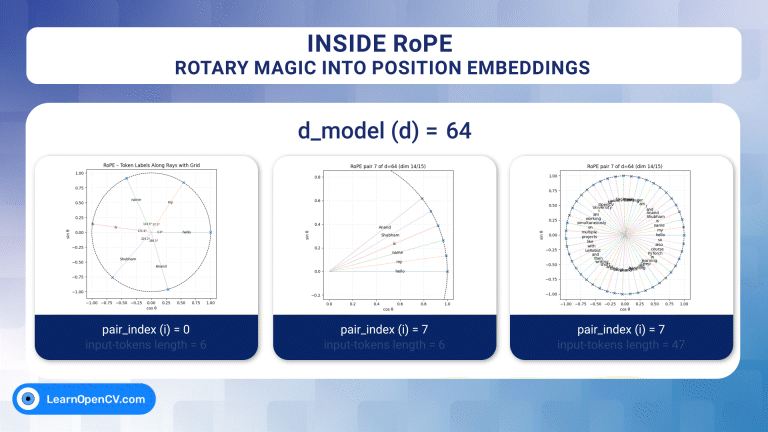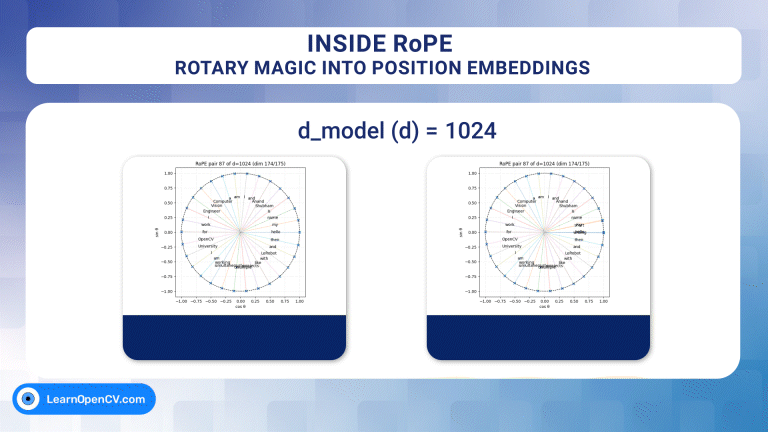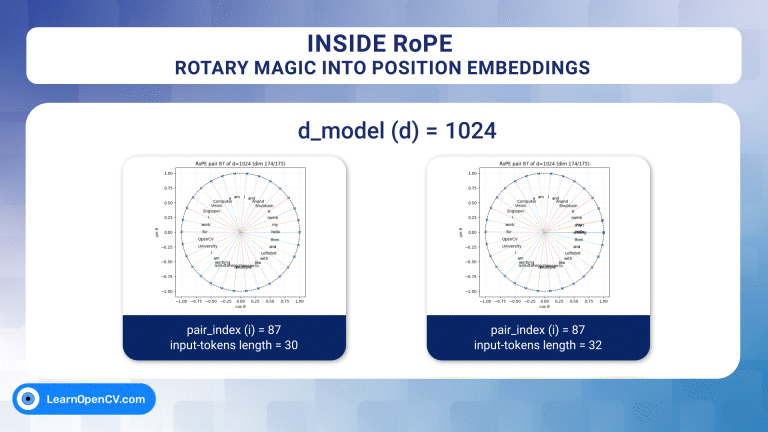
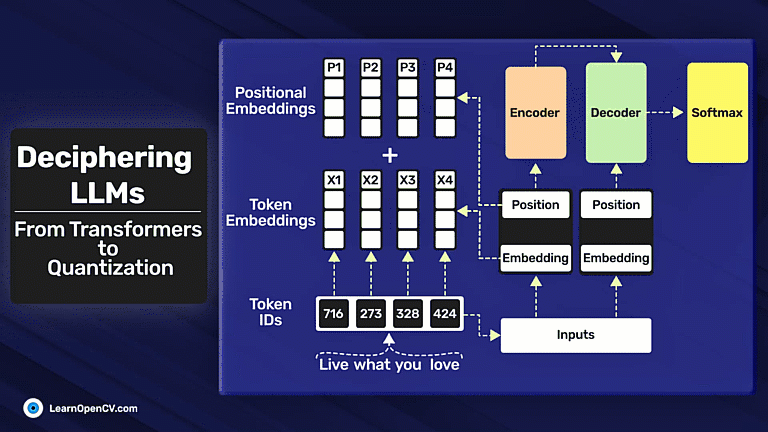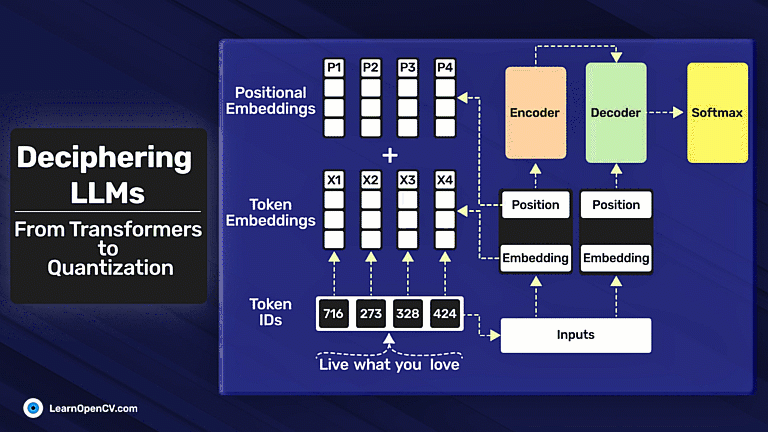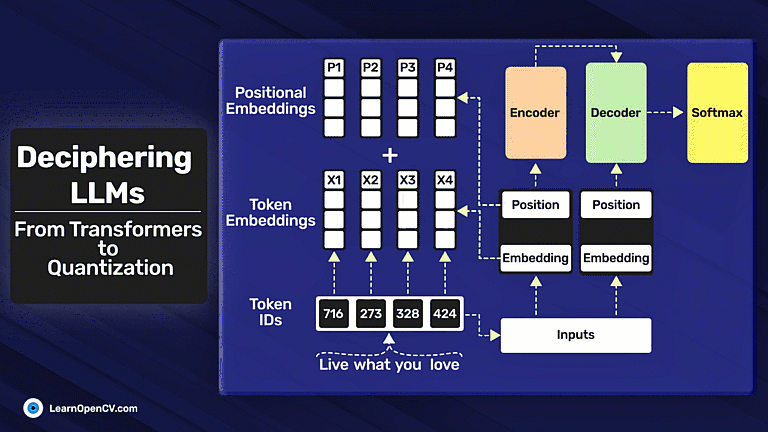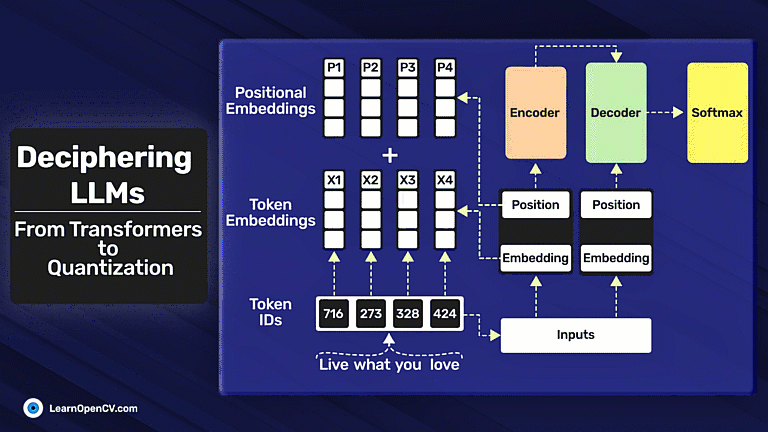
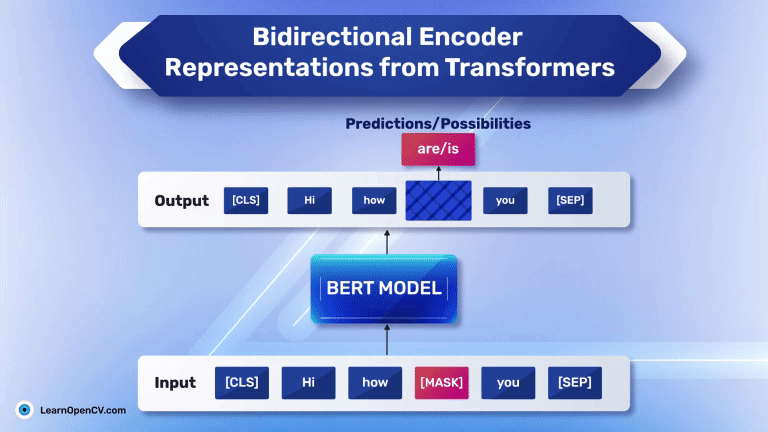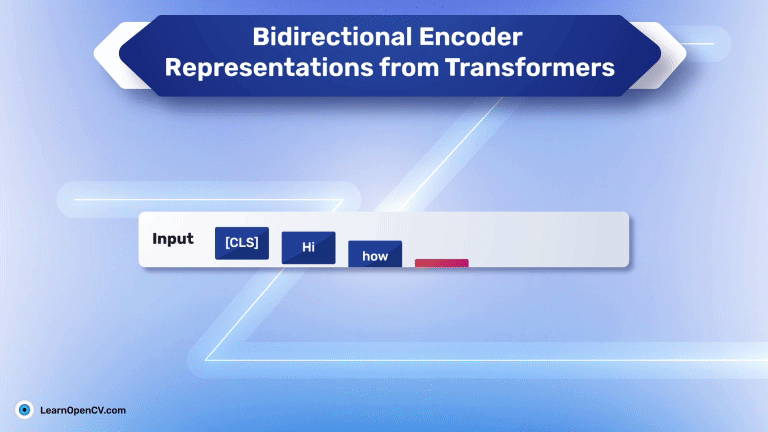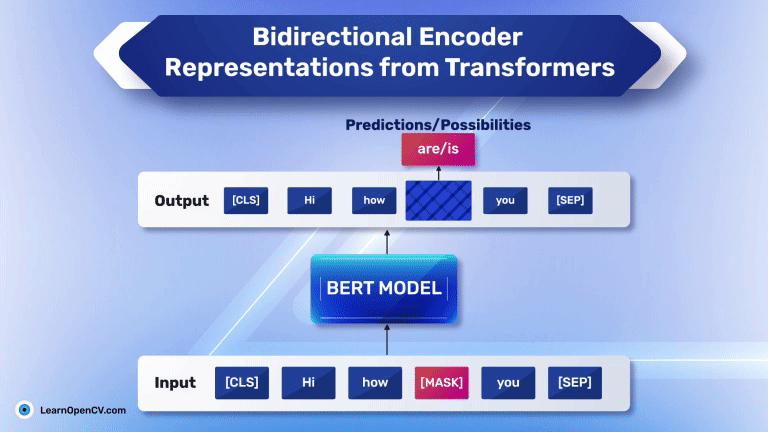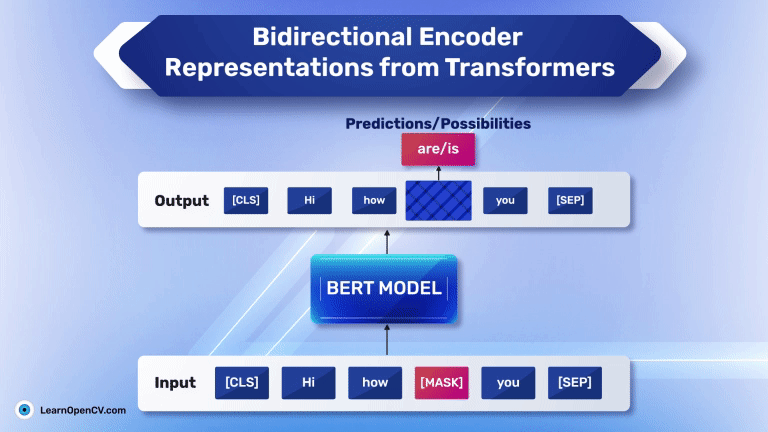
In the groundbreaking 2017 paper “Attention Is All You Need”, Vaswani et al. introduced Sinusoidal Position Embeddings to help Transformers encode positional information, without recurrence or convolution. This elegant, non-learned
Self-attention, the beating heart of Transformer architectures, treats its input as an unordered set. That mathematical elegance is also a curse: without extra signals, the model has no idea which
In the evolving landscape of open-source language models, SmolLM3 emerges as a breakthrough: a 3 billion-parameter, decoder-only transformer that rivals larger 4 billion-parameter peers on many benchmarks, while natively supporting
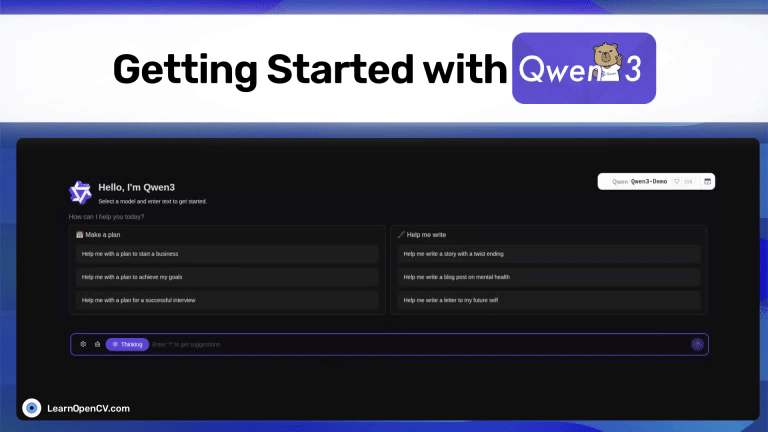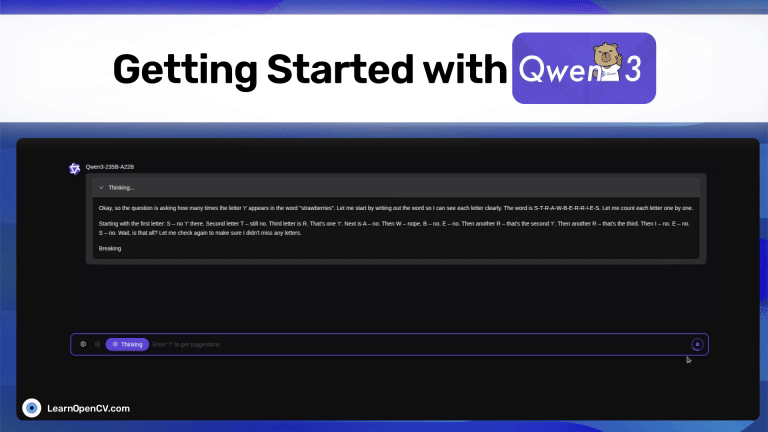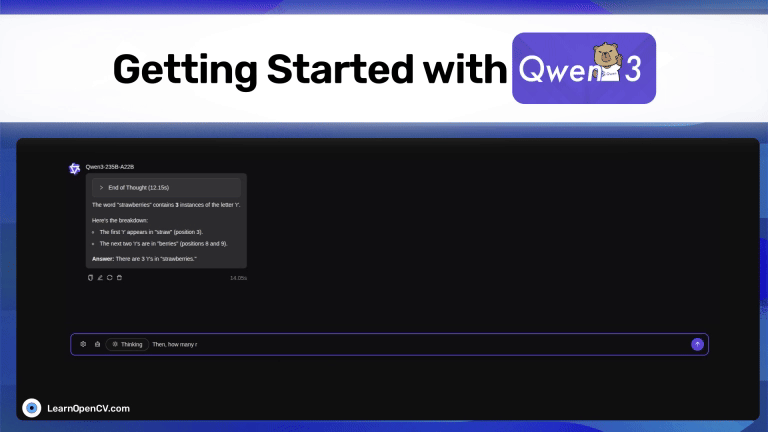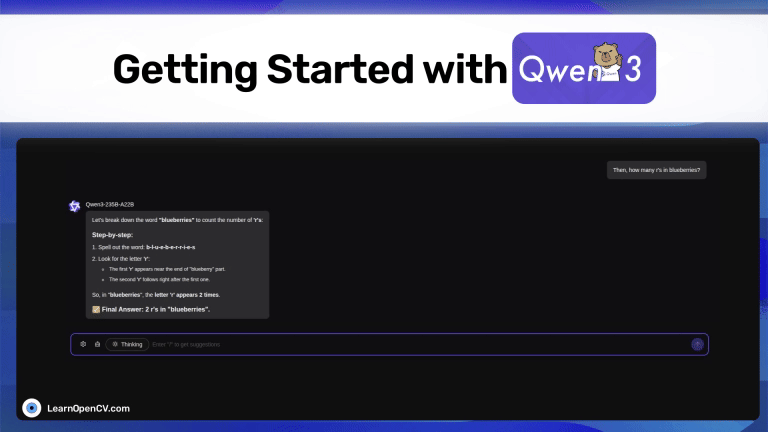
Discover Qwen3, Alibaba’s open-source thinking LLM. Switch between fast replies and chain-of-thought reasoning with 128 K context, and MoE efficiency. Learn how to use and Fine Tune.
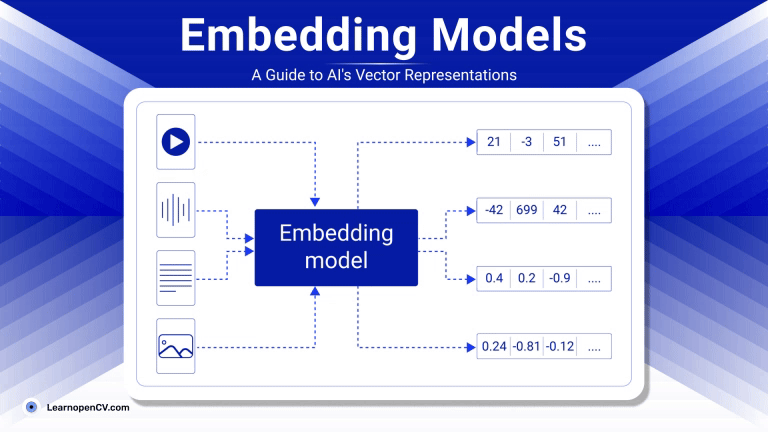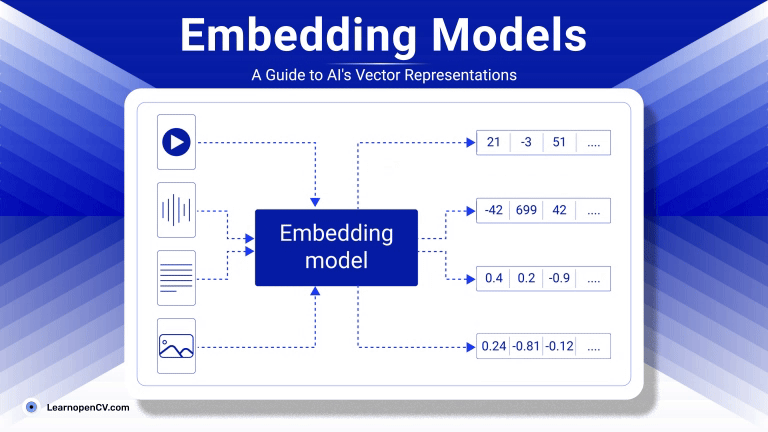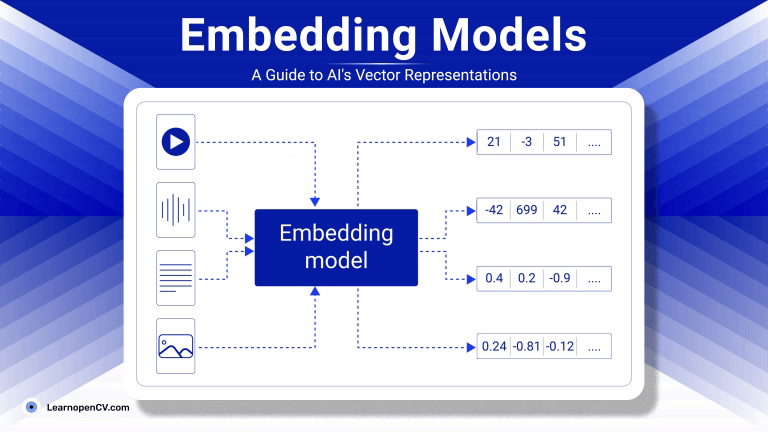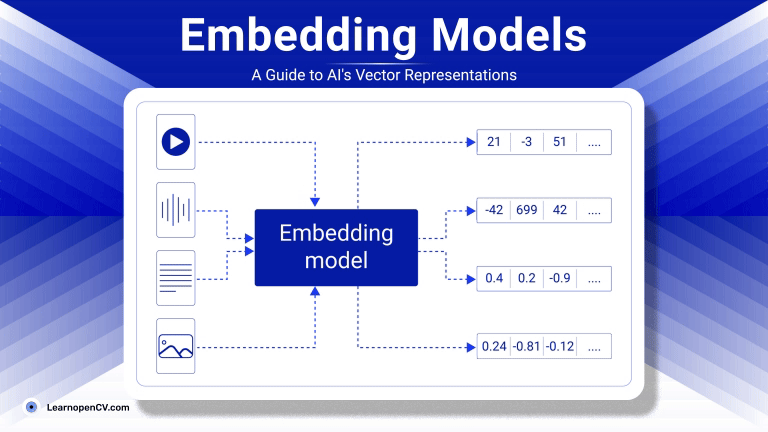
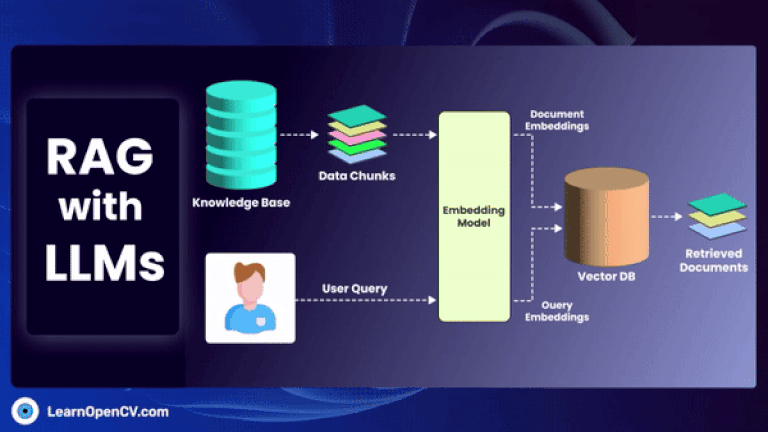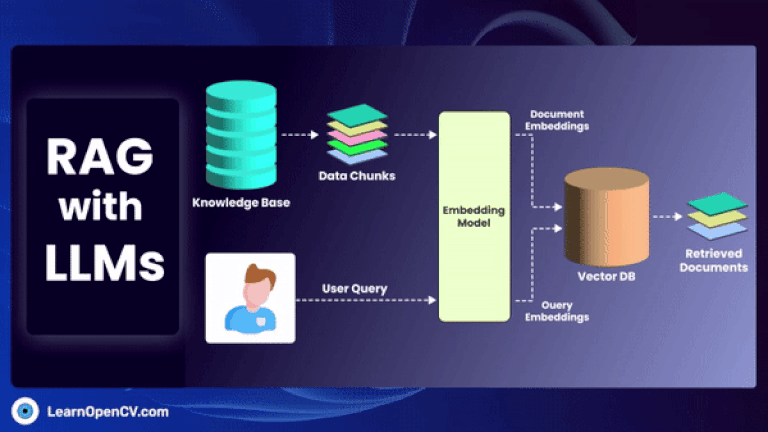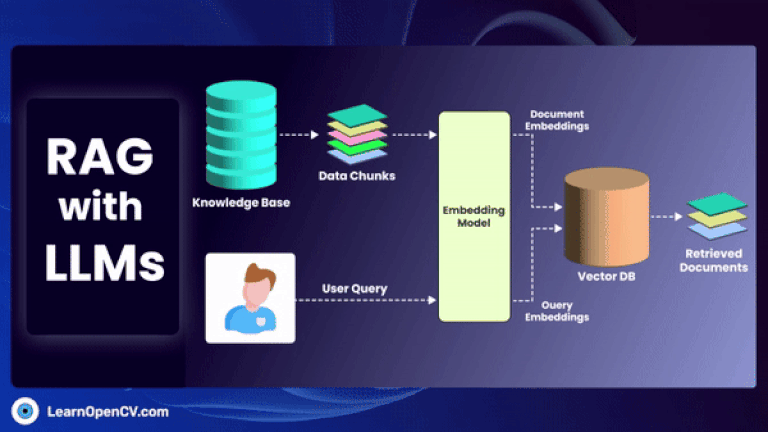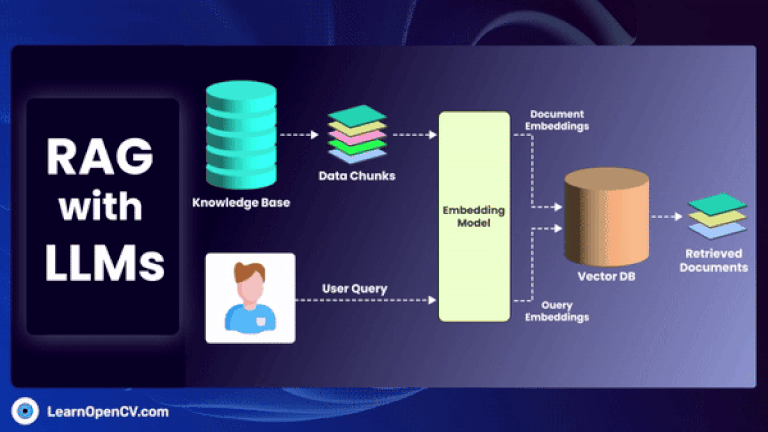
As artificial intelligence continues to advance, Embedding Models have become fundamental to how machines interpret and interact with unstructured data. By translating inputs like text, images, audio, and video into
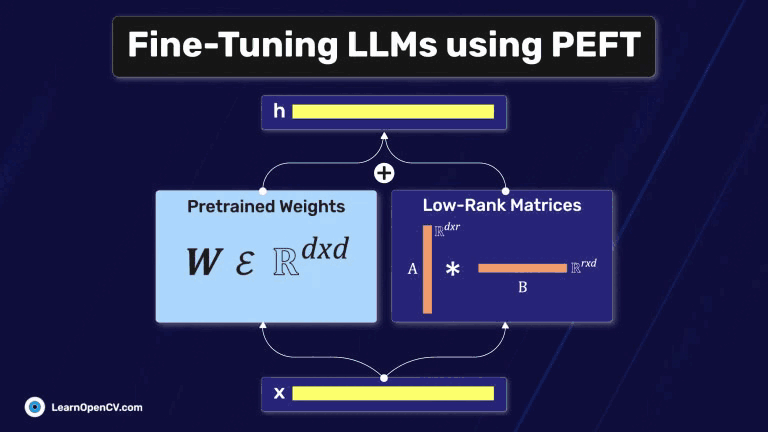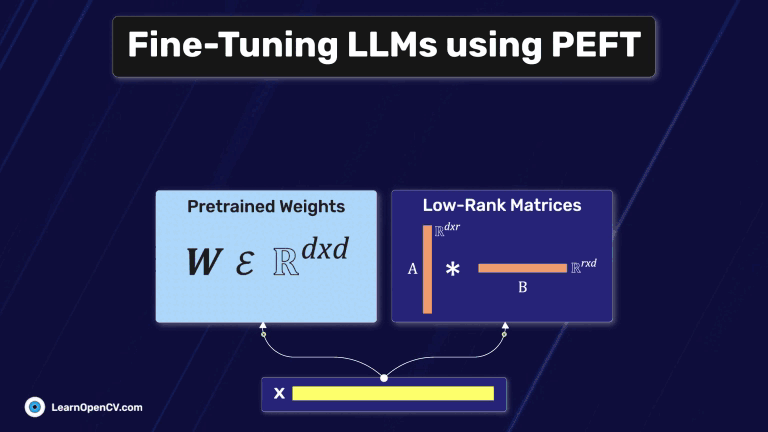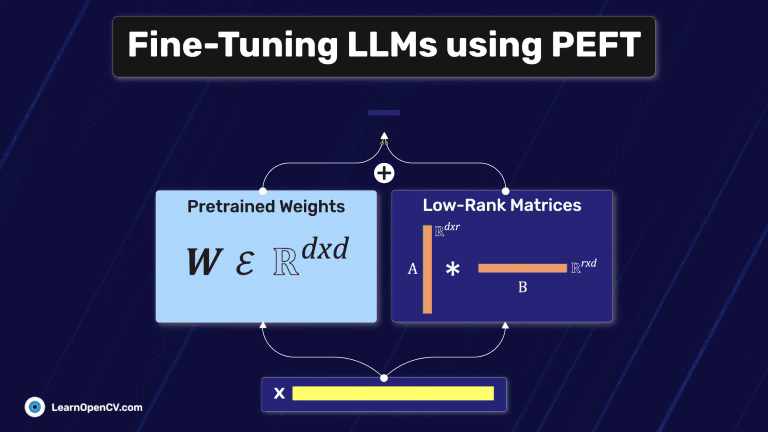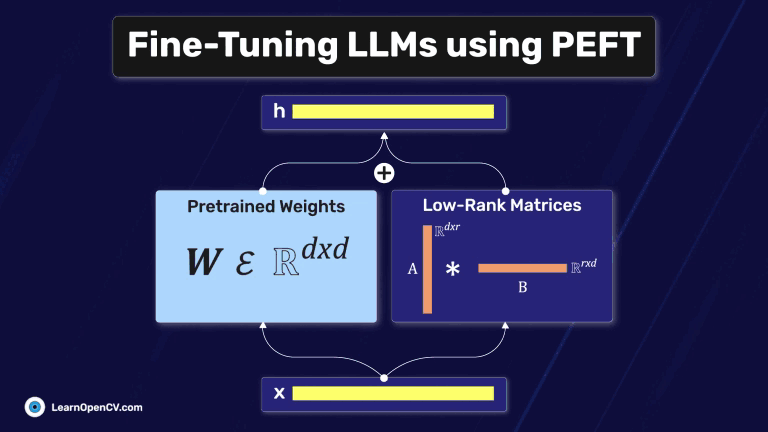
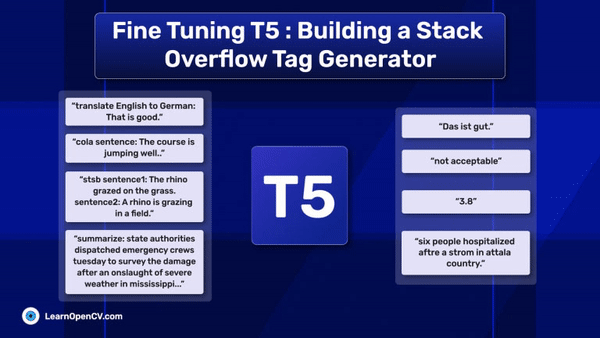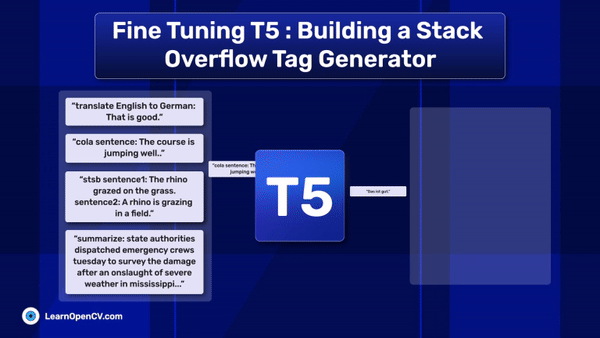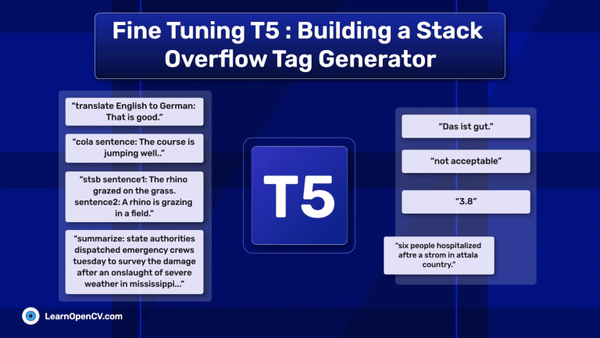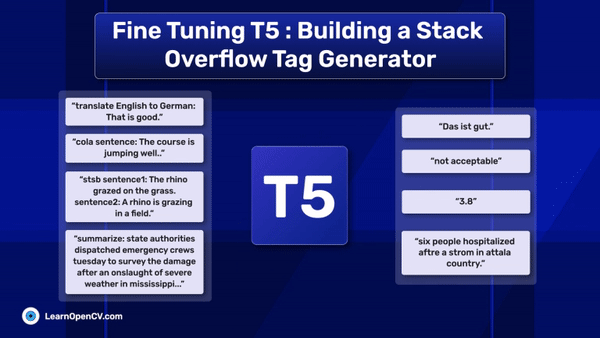
In this article, we explore different fine-tuning techniques for LLMs and fine-tune the FLAN T5 LLM using PEFT with the Hugging Face Transformers library.