Welcome back to our LangGraph series! In our previous post, we explored the fundamental concepts of LangGraph by building a Visual Web Browser Agent that could navigate, see, scroll, and summarize
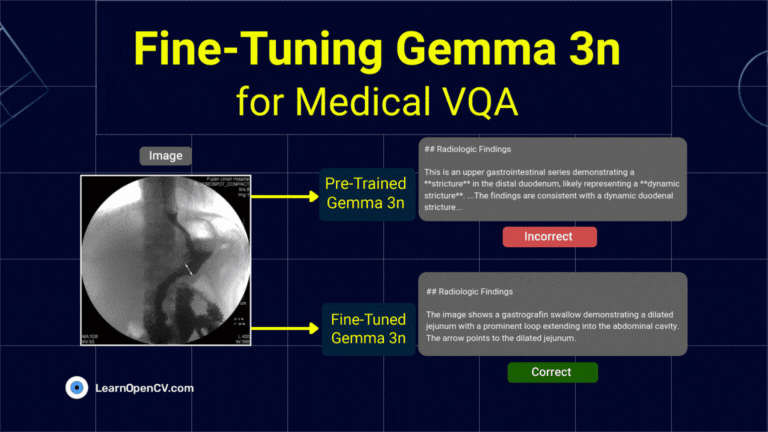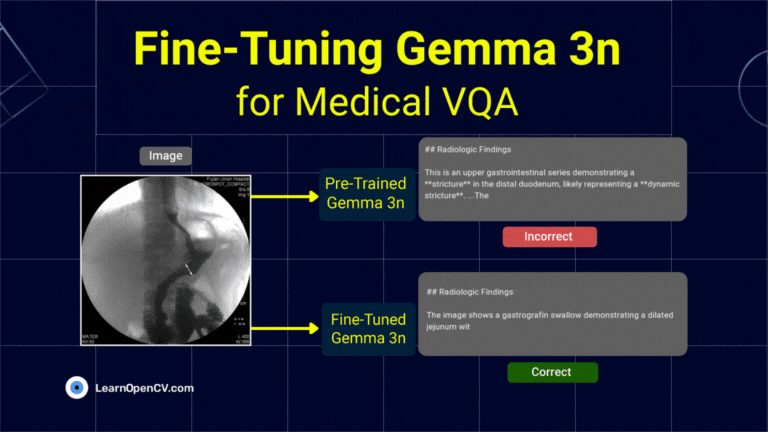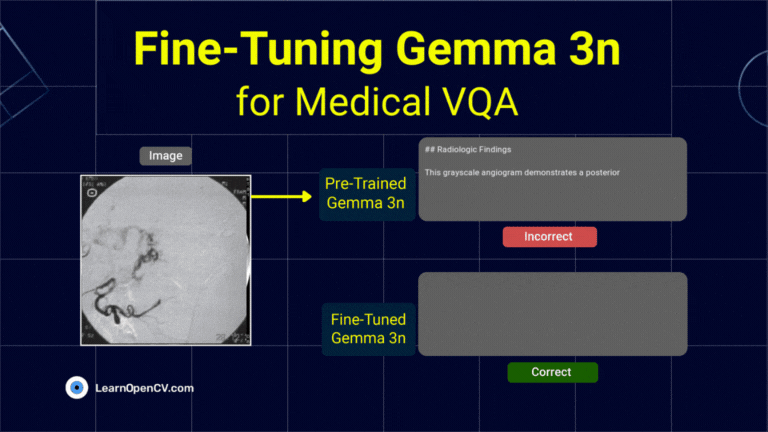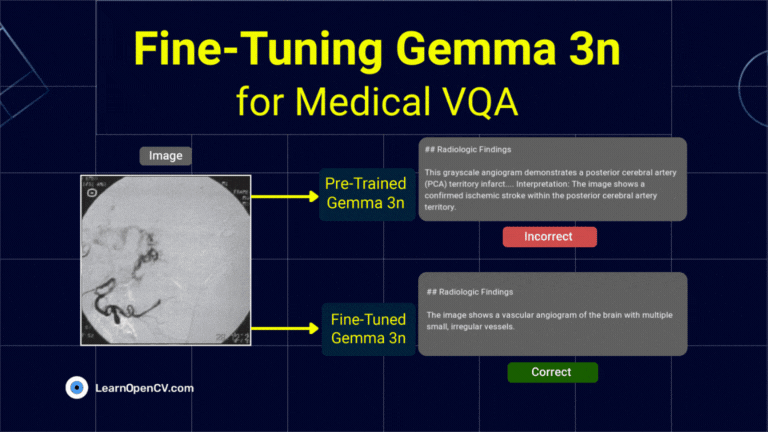
What if a radiologist facing a complex scan in the middle of the night could ask an AI assistant for a second opinion, right from their local workstation? This isn't
The ultimate goal for many in artificial intelligence is to build agents that can perceive, reason, and act in our complex physical world. Meta AI has made a significant stride
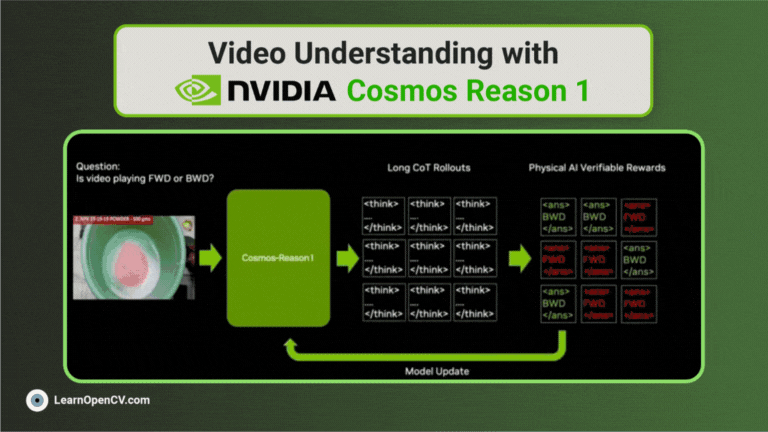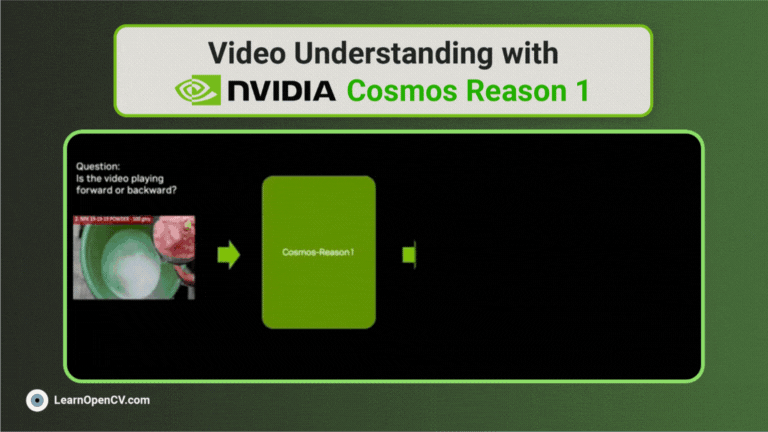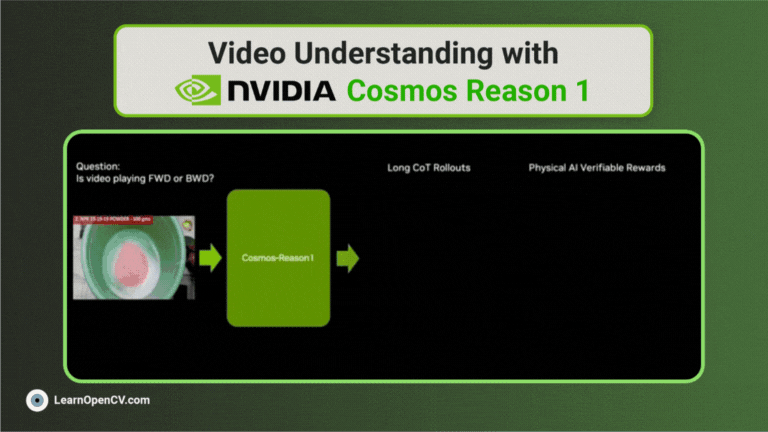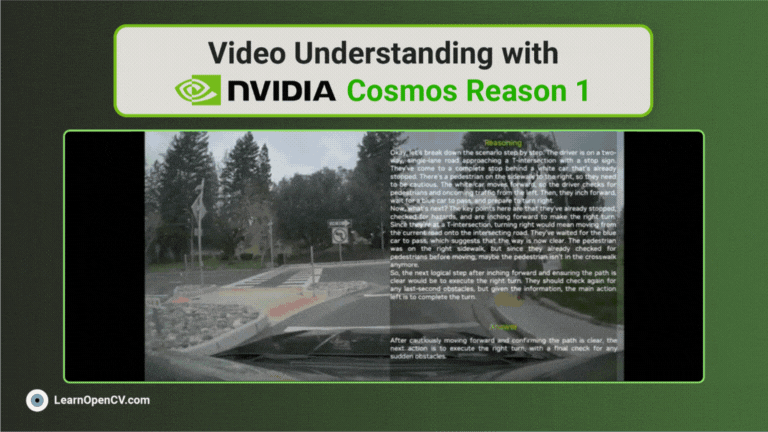
NVIDIA’s Cosmos Reason1 is a family of Vision Language Models trained to understand the physical world and make decisions for embodied reasoning. What makes Cosmos Reason1, as a promising contender
To develop AI systems that are genuinely capable in real-world settings, we need models that can process and integrate both visual and textual information with high precision. This is the
The landscape of Artificial Intelligence is rapidly evolving towards models that can seamlessly understand and generate information across multiple modalities, like text and images. Salesforce AI Research has introduced BLIP3-o,
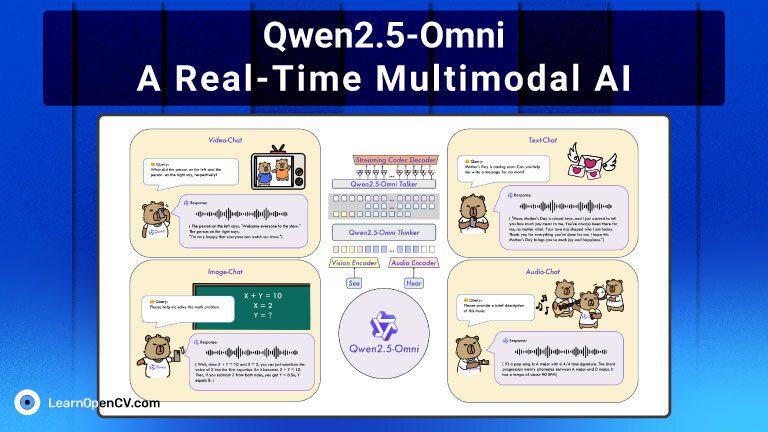
Qwen2.5-Omni is a groundbreaking end-to-end multimodal foundation model developed by Alibaba Qwen Group. In a unified and streaming manner, it’s designed to perceive and generate across multiple modalities – including